
2 Interesting Scholarly Datasets obtained from web scraping - Open Editors & Open Syllabus

One of the themes that I have been blogging about in recent years is the increased availability of open metadata in the academic/Scholarly ecosystem. Article metadata (including citations & Scholarly PIDs - permanent ID) are now becoming widely available due to organizations like Crossref, ORCID, ROR and advocacy organizations like Intitative for Open Citations (I4OC) and Initative for Open Abstracts (I4OA).
All this is of course a great boon for studying different aspects of the Scholarly workflow process.
That said, there are still interesting areas of study where we are still lacking in good open , structured and machine readable data and instead we are forced to resort to difficult web scraping to get the data.
In this blog post, we will discuss two interesting Scholarly communications datasets that are indeed generated from web scraping due to the lack of alternatives.
Open Editors (March 2021)
Open Syllabus (updated to version 2.5 in Feb 2021)
Open Editors - Dataset on Editors for Journals
Authors who submit and publish research have been naturally the focus of a lot of efforts.
PIDs like ORCID, ROR are starting to solve the issue of author ambiguity and adoption of CRediT (Contributor Roles Taxonomy) by journal titles is clarifying the role authors contribute to published work.
However, authors only make up one role in the Scholarly Communication workflow.
Besides authors who contribute work, studying who is doing the peer review is clearly important. Such information is often hard to get at as well, probably because double blind peer review is considered standard (though recent developments seem to be pushing towards more transparent systems), and as such the idea of making public data on who does the peer review wasn't that common of an idea, though systems like Publons (owned by Clarivate) that try to get authors to clam credit for their reviews do exist.
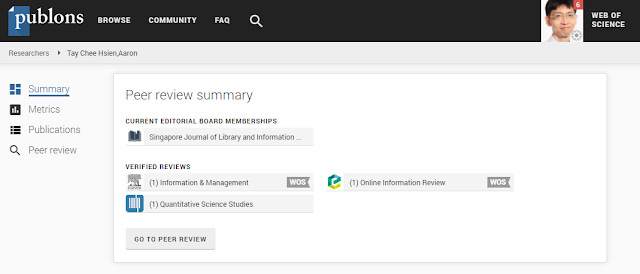
My Publon profiles showing reviews I have done
But leaving aside authors and peer reviewers (who often want to be private), editors of journals & editorial board members surely play an as important if not more important role?
For example, Editors often play a even bigger role on whether a piece of work is even considered for peer review and while some journal editors are paid professionals, many are working academics who work in our institutions and it might be worth to understand their motivations.
And unlike information on peer reviewers, such information is already public on journal webpages and there shouldn't be any reason why we shouldn't have a way to easily obtain such data in bulk in a way that can be easily interpreted and analysed.
How does one obtain editor data?
Unfortunately there does not seem to be any easy and general way to get data on who are editors/sitting on editorial board of a journal title.
While some institutions with RIMS/CRIS systems do track researchers editorial positions, not all institutions do this.
Publons besides trying to track peer reviewers also gives you an option to state that you are an editor of a journal. Idea is to
"get recognition for your editorial contributions by keeping verified editor records of the manuscripts you handle. "
Leaving aside the openness of this system, this currently doesn't seem to have a high uptake.
So the only option is to scrape the data off journal websites and this is what Pacher, Andreas, Tamara Heck and Kerstin Schoch have done and they have generously made the dataset available via CCO
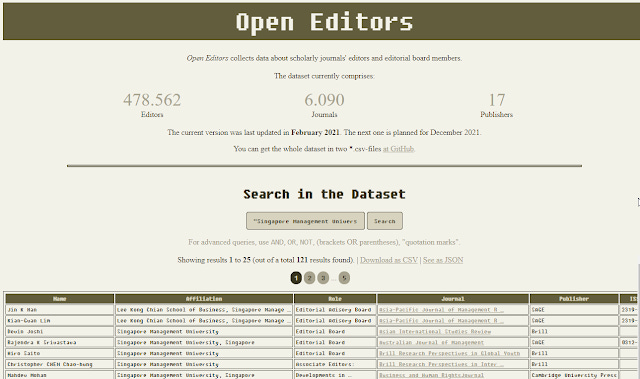
About the Open Editors dataset
The authors of the dataset has also released a preprint describing their work - Open Editors: A Dataset of Scholarly Journals’ Editorial Board Positions. I will quote liberally from it in this blog post.
So what is in the dataset?
Firstly the data is drawn from web scraping (using R) 6,090 journals titles from 17 publishers, amounting to 478, 563 researchers.
Below shows the 17 publishers covered in the dataset

17 Journal publishers included in Open Editors Dataset
The dataset information includes
Name
Affiliation
Role
Journal
Publisher
Date
Besides downloding the whole dataset (which isn't that big anyway), the authors provide a handy website with a search function that you can use to do a keyword search to narrow down to results you are interested for exporting. A common use case I suspect for many is to enter their institution name plus perhaps a subject.
Secondly, we are told the great news that
The data collection will be performed on a regular basis, at least once a year until 2023, through a scripted program whose codes are available in a public repository, and will be donated to Wikidata in order to ensure the dataset’s sustainability.
Now for some bad news.
Firstly, the data extracted are all strings and not PIDs. Still this isn't fatal, but some work should be done matching names to ORCID, institutions to ROR etc.
Update: Bianca Kramer has done work matching institution affiliations to ROR IDs
An interesting finding is that the labels given for the roles are extremely hetrogenous, with over 5,330 labels! Common ones include - “Review Editor”, “Editorial Board”, “Editorial Board Members”, “Guest Associate Editor”, “Associate Editors”, “Associate Editor”, Perhaps some standarisation needed here?
But I think one of the most critical thing to be aware about using this dataset is it unclear how representative the sample is. Of course, with scraping the whole web, you can never be sure what you missed but let's say you restrict yourself to the biggest most well known publishers.
In that case, if you look at the 17 publishers included you may wonder some very big publishers like Springer, Wiley, Taylor & Francis are excluded.
The authors note
The current approach is based on a necessarily incomplete publisher and journal coverage. ..,. Even if one wished to limit oneself to the largest publishers, their heterogeneous way of displaying data about editors inhibits a simple webscraping approach. Examples include Springer, Oxford University Press, Taylor & Francis, and Wiley
In other words, they are excluded because they display data so inconsistently for journals in their stable of titles, the authors of this project are unable to come up with a way to consistently pull the data across all their journals.
What can you use Open Editors for?
Despite the incompletness of the data, this is definitely the largest public source of data on journal editors and you might still wish to consider using it. I'm sure bibliometrics experts must have dozens if not hundreds of ideas in their minds on how to use this data to test their theories but what about for operational use?
1. Advocacy - Need some advocates to pressure publishers? (e.g negotation of journal pricing, openness of metadata etc) , use this dataset to find people to advocate for you
2. Subscription renewals - Besides usage (download and citations), and obviously price taking into account if a faculty from your institution is on the editorial board is probably a good idea to factor in?
3. Unauthorised listing of editors - Predatory journals are known to list unwitting researchers on their editorial board lists. Having such a list would be helpful to warn researchers if it is happening. Note this use isn't possible yet for this dataset (they do not yet scrape predatory journals according to them),
Conclusion
A open structured dataset on editors is clearly of great value.
Not sure if there is an existing commitee that should take the lead on this. COPE (Committee on Publication Ethics) ? Or maybe organizations like DOAJ might start the ball rolling with enforcing such a standard to be listed in them, which might hopefully be taken up by other non-OA journals.
The authors of this dataset suggest a I4OE (initative for open editors) in parallel to the I4OC (intitative for open citations) and I4OA (iniative for open abstracts) groups is a interesting idea.
The cynic in me wonders if it is perceived that there is sufficient demand for this whether a commerical service might emerge (paid service in Ulrich's Periodicals Directory say or some value-add feature in CRIS etc).
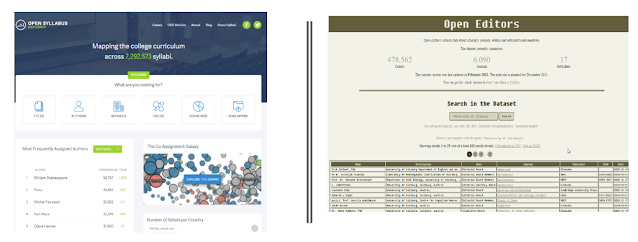
Open Syllabus - an update v2.5
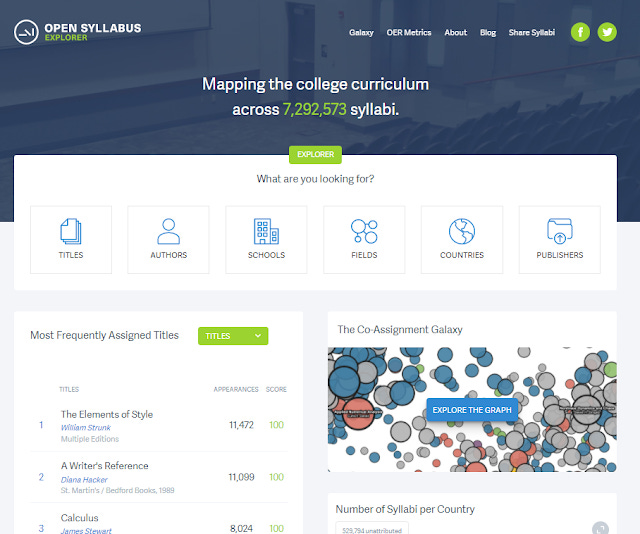
In 2017's "Can we assess library electronic resource usage with citations, altmetrics & more ?", I briefly mentioned Open Syllabus - which allows you to look at the top cited books or articles in syllabus around the world.
This year in Feb 2021, there has been a major update to v2.5. Since, I have not given an in-depth introduction to this interesting project and dataset yet , I will do so here.
What is Open Syllabus by Open Syllabus Project?
The FAQ says it
"is a non-profit research organization that collects and analyzes millions of syllabi to support novel teaching and learning applications. Open Syllabus helps instructors develop classes, libraries manage collections, and presses develop books. It supports students and lifelong learners in their exploration of topics and fields. It creates incentives for faculty to improve teaching materials and to use open licenses. "
As you might expect, the syllabus is obtained mainly by crawling publicly available University websites (faculty contributions are said to be "small but significant portion of the collection") and currently consists of nine million English-language syllabi (deduped to 7 million syllabus) from 140 countries. They estimate this to be "5-6% the US curricular universe over the past several years."
Note that syllabus from certain countries are excluded on purpose because of fears about the lack of academc freedom. This includes countries like Russia, Iraq, Iran. I note with amusement it also includes Singapore.
Also you cannot get the individual Syllabus just the aggregated results. Despite the name "Open" in the project, I can't seem to find a specific license to the data, the terms and policy page doesn't seem to say much either beyond contacting them.
Under the hood
Open Syllabus is able to identify works cited in syllabus that are in Crossref, The Library of Congress, Open Library and the Textbook Library.
The tricky part in this project is to match the citations in syllabus to known works. The FAQ describes the work as such
The Syllabus Explorer identifies citations by looking for title/author name combinations in the raw text of the syllabi. The resulting matches are then run through a neural network trained to distinguish citations from other occurrences of the same words. This process is accurate a bit over 90% of the time when compared to human labeling.
Similar to the Open Editor dataset no linking/matching to PIDs are done (not yet anyway) and the FAQ mentions for author this is problematic if the name is common as "An author search simply returns people who share a particular name". Publisher names are problematic as well but because there are fewer of them it is easier to clean.
Dates are also 90% correct, and 94% of syllabus do resolve to institutions based on analysing URLs and email strings, but fields are a challenge.
Using the Open Syllabus explorer
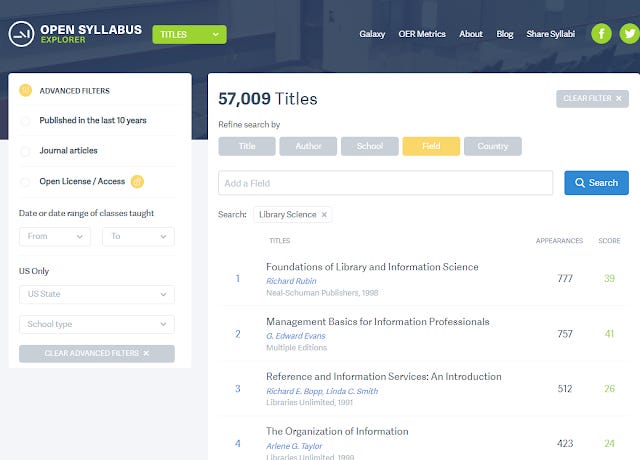
Open Syllabus field search - filtered to Filter of Library Science
The main way of using this dataset is by using the explorer. It's a pretty straight forward interface where you can search by Title, Author, School, Field, Country and Publisher with intuitive filters to use.
Currently, if a title appears multple times on a syllabus it counts as one and the system currently does not distinguish between a reading being listed as primary reading or secondary.
"Score" is basically a percentile ranking of appearance.
V2.5 updates - Open Syllabus Galaxy improves
This new version of Open Syllabus boasts 3 improvements.
The first is an updated "Open Syllabus Galaxy". If you like visualizations this is for you.
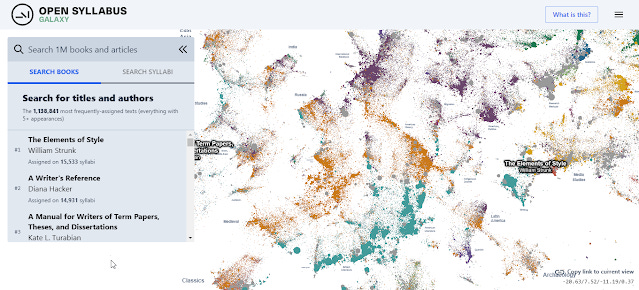
Using the most assigned million works, it creates a
"interactive UMAP plot of graph embeddings of books and articles assigned in the Open Syllabus corpus!" (blog post)
In other words, the technique uses linkages between syllabus and works to do machine learning to produce a visualization such that works that are "similar" (various ways) in terms of being assigned together will tend to be put together in the visualization. Each work is also assigned to a Field if >50% of assignments are in courses from that field.(see very technical discussion here).
Besides browing around or searching by title, this new version adds searching by Syllabus which matches course titles and description paragraphs,
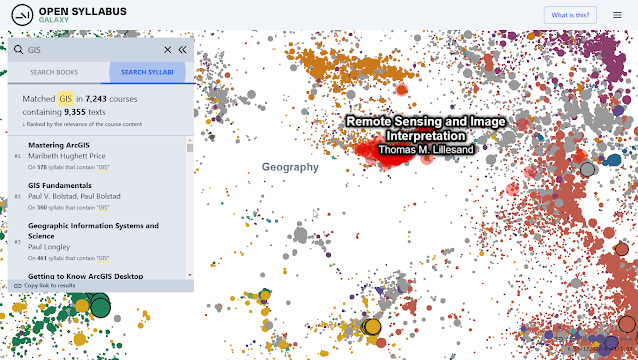
Searching by GIS in Syllabus in Open Syllabus Galaxy
Why such a feature?
The idea here is for some searches it is better to match just certain sections of the syllabus rather than the whole syllabus. This is particularly true when the keyword matches common author names etc.
V2.5 updates - OER metrics
One totally new feature in Open Syllabus is a section on OER
As already mentioned , some of the sources they use to identify works includes Open Textbook Library and the Directory of Open Access Books, this allows them to specially segment out the results to the universe of only OER works and provide seperate metrics for that.
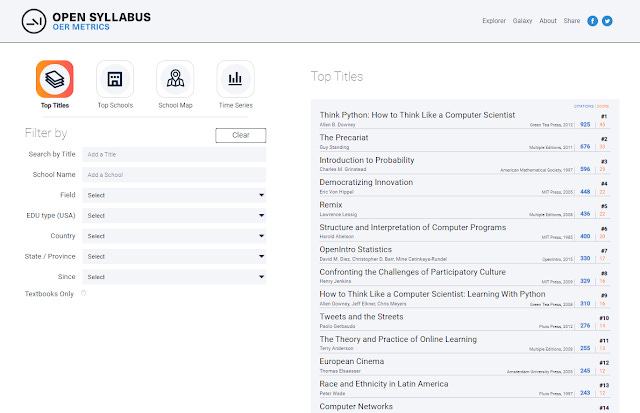
Besides the obvious use of looking for particular OER sources that are commonly used by field, country or even particular school, you can also click on Top schools, to see which schools have syllabus that assign the most OER.
Below for example shows when filtered to US - R1/R2 institutions, the top school is New York University with 218 citations to OER works.
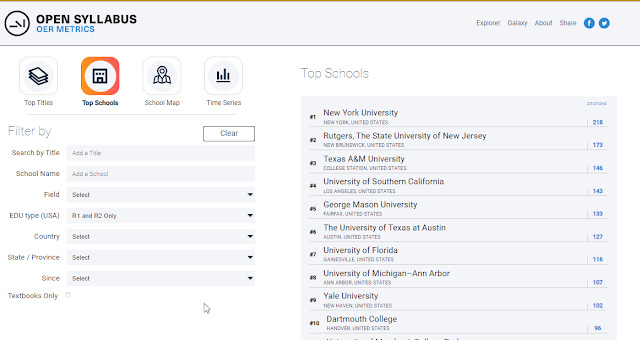
OER metrics - top schools - filtered to US R1 and R2 Only
You also get nice maps and time series visualizations for some OER metrics.
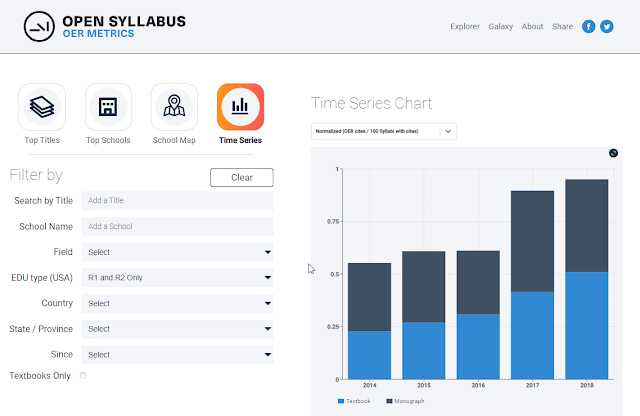
There's some particular interesting analysis tweeted out by their twitter account and in this blog post.
V2.5 updates - Linklabs
The last of the three features in V2.5 update is a experimental feature called Linklabs
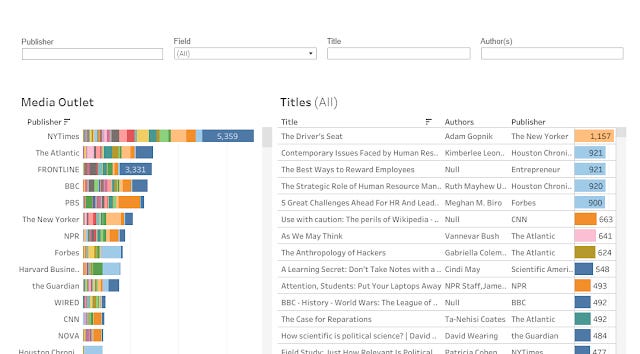
Linklabs - linking to non book, article sources
The idea here is to try to go beyond just tracking citations to books and articles but also to blog posts, news articles, podcast episodes and videos, particular Youtube videos.
By trying to identify readings to sources beyond books and journal articles, we are of course increasing the difficulty significantly, so for now this remains just a "lab" test.
What can you use Open Syllabus for?
Years ago I remember looking at one of the citations identified by Google Scholar that apparently cited my paper and when I looked at it , it turned out to be some web page that was a syllabus that assigned my article as a reading. I remember showing it to researchers as an example on how Google Scholar can be less than reliable and I got a comment that getting your work assigned as a reading showed impact too.
Open Syllabus is basically a citation index that tracks citations from syllabus instead of traditional scholarly sources and indeed the first obvious use that most researchers or librarians will try is to look up their own name or works to see how many times they were assigned.
Instructors might use this tool to look for what people are usually assigning in their area for readings.
The new subset on OER opens even more use cases.
Conclusion
Open Syllabus is indeed a interesting dataset with many use cases. With reading list software on the rise , particular with Exlibris's Leganto, where the data is already readily available in machine readable form and consistently used across various institutons, one wonders if a closed commerical dataset would be next on the horizon (if it is not already here).
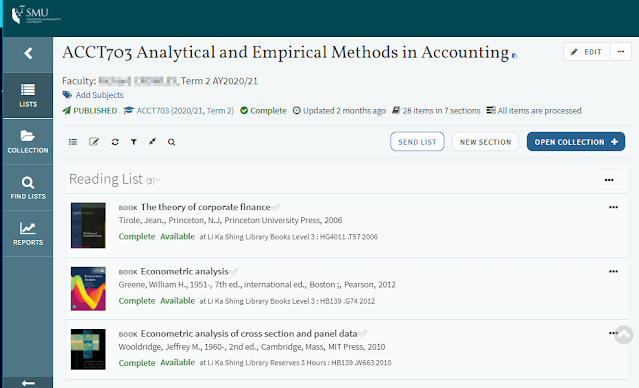
A sample of Exlibris's Leganto reading list software - existing structured data on syllabus
Both Open Editors & Open Syllabus are datasets obtained via web scraping/crawling. Will this always be the only way to get the data, or will standards start to emerge?