
5 musings on various things - library spaces, Project thinking, Microsoft academic and more

How is everybody?
As I write this, we are in day 9 of our "circuit breaker" (which is very like a soft lockdown) here in Singapore.
As an introvert and being pretty adept on the use of technology for communicating, I would have thought that this would be a dream for me.
Don't get me wrong. I appreciate the timing of the "circuit breaker" which fortuitously came into effect just after my paternal leave ran out and I could spend more time at home with my newborn. But I'm surprised how much I miss just walking over to my collegue tables and have a discussion on library related stuff.
In-lieu of this I have been having chats online and spending more time thinking which resulted in this blog post on these 5 assorted items.
A common thread for many of these items is I just finished our library benchmark survey and the results are leading my thoughts down various paths.
None of these are really groundbreaking thoughts and calling them "epiphanies" would be too grandious, but I am hoping some of these random musings might be useful to you.
The importance of library space as an "essential" library service
I recently concluded our Library Benchmarking survey - by Insync. If you are unaware with this, it is basically a benchmarking survey similar to LibQUAL+ , except much simpler for respondents to take.
For each item, they are asked to rate an "importance" and a "performance" score from 1-7.
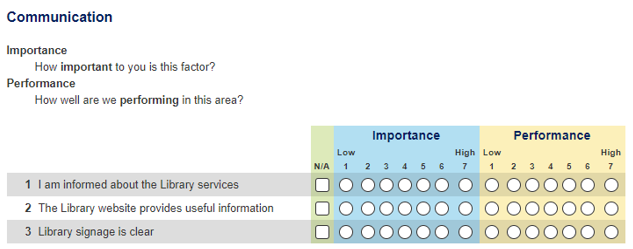
Sample of Library Insync Survey
This is not a blog post comparing Insync with LibQUAL+ (both of which I have run 3 times each), but I will say Insync surveys are usually much easier to complete and hence have a much higher survey completeness rate. I got rates of easily 80% for them , while the times I have ran LibQUAL+ , more than half abandoned the survey without completing it.
The main disadvantage is that INSYNC is generally used mostly by Australian academic libraries with few libraries outside using it (Singapore institutions have used them occasionally), so your benchmarking opportunities are far less than LIBQUAL+ if you want to look outside Australia.
One thing that INSYNC does is that it focuses your attention on the "importance" of each item (that said, you can use a blend of LIBQUAL+ 's "Minimum level of service" and "Desired level of service" scores to proxy an "importance" score. )
Most academic librarians won't be surprised to note, for undergraduate space issues will predominate.
Just as a lark, I was inspired by the meme about Wifi as the lowest level of Maslow's hierachy of needs to do up the following diagram.
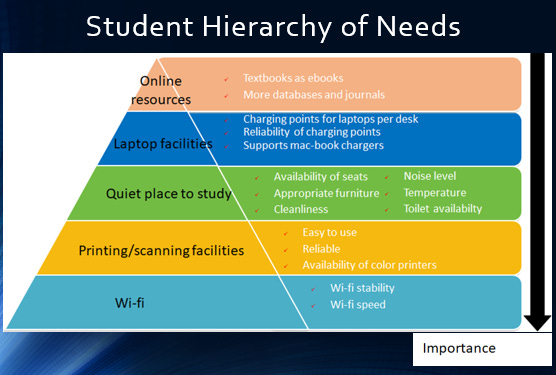

Of course, Maslow's doesnt quite fit, as students can easily want say "Quiet place to study" without needing "Printing/scanning facilities", but I would argue in fact this hierachy of needs typically makes sense.
The importance of Wi-fi is unquestioned.
Even students who don't like to study in the library tend to want to use libraries' printing facilities as in many University Campuses they are the main places to print at a relatively low price.
Next up is a quiet place to study and once you get a seat to study, you would want to be able to charge your laptop and phone.
Only when all these needs are meet do students asking thinking about online resources. So it ties together nicely.
Faculty of course have a totally different list of most important needs, something around the lines of
Availabilty of online resources for research and teaching
Ease of access of resources off-campus
Availability of staff help
Accuracy of staff answers
Search engine usability
But this isn't a post about faculty.
I'm not sure how universal the importance factors I have listed for the students are, but I suspect they might not vary much for most Universities.
In fact to some students here, these library services is almost seen to be an "essential service".
When Singapore announced our "circuit breaker" or what I called soft shutdown, it was announced all work places and business would be closed except for "essential services".
It was somewhat surprising to see students enquire if the library spaces would be open.... Was our services so "essential"?
We were told with all exams online, students were planning to book a room in the library to do their online exams in the library. They also needed to print their notes. Most importantly, they don't have anywhere conductive to study, whether they be local students or foreign. Where else could they study in peace and enjoy 24/7 aircon and unlimited wifi without being asked to buy something first?
Perhaps it is my prior library experience that focused on other aspects of library work (users interaction with online services) that such comments still give me the feel of an "insight". I guess even though I know in my head the value of library spaces, I still don't quite fully get it in my gut.
Still a thought that strikes me is this.
In my institution at least, the four most important factors are generally not managed solely by the library, or rather we do it in collaboration with campus partners like the Campus IT department (Wifi and printing services) or Campus Facilities Management (space related isues like furniture, cleanliness, power sockets). Only the factor student that tell us is the 5th most important, "online resources" is mostly under the control of the library (with some partnership with finance) to a large degree.
I guess libraries differ from each other, but I would hazard a guess for most libraries, the library staff assigned to these 4 areas tend to be in the minority of all the library staff.
Instead most of the staff manpower is devoted to library services like Information Literacy, Technical services etc.
While there might be libraries that devote a lot of time and energy to studying and managing the use of space, I would guess in many places, there would just be one or two who serve as a liason to the campus partners. I would also hazard a guess, most Library School courses would be light if not totally empty of courses in these areas, which leads to people like me, who keeps getting surprised at how much value our library spaces add.
As someone who wonders a lot about whether the library assigns the right amount of manpower resources to different areas (e.g. in the early 2000s, even though budgets were shifting to electronic resource, many places still had far too many staff assigned to handling print compared to electronic content and I'm wondering now if the emerging area of Scholarly communciation is facing the same challenges), I do wonder if we might need some alignment here as this area is what students tell us is important - assuming we can trust the survey of course.
Of course, I'm not saying the library should take over facilities totally. Neither am I saying other areas Technical services, Information Literacy etc isn't important.
For example, tell the people who need access to the print collection now that the library is closed, the print collections service isn't important. :)
It could also be that, these space factors are merely hygenic factors that will hit diminishing returns if we devote even more time and energy to them.
Still mulling over this.
Holistic view of website design
One of the outcomes of the library survey led me to think it might be worth while looking at our library homepage design again.
While some believe it is best practice to make constant small changes to improve as opposed to making a gigantic big revamp projects once every few years, we are currently thinking of the later way of doing things.
The problem of course is you don't want to do library website redesign just for the sake of it. You want to solve a problem. You want to for example help users complete the task they want to do. perhaps they want to explore what services are available to them, or find out how to search for a specific type of resource (e.g. Analyst reports).
But when you think about it, the online presence of libraries today that might help solve these problems is a complicated mix of systems including
Library Homepage + site
Discovery system + link resolver + recommenders
Libguides
FAQs
Reading list system
much much more
Any project those scope is just the library homepage proper is likely to accomplish minimal gains. As my collegue noted while we were deep in discussion, it's all connected! In fact, I wonder if the problen is often each component by itself is optimised fairly well, but it is the hand-offs to the different web properties that the ball is often dropped.
For example, you could have a nice link on your Home page pointing to Libguides, but where exactly should you point it to? What if the optimal landing page for linking to a Libguides system doesn't yet exist? Or perhaps the right way to help users is to optimise Primo Resource Recommenders, pointing to appropriate guides or FAQ, but do they exist?
A siloed approach for a project that only concerned themselves with one web property is going to miss out a lot.
Talking abour projects.....
Project management approach - a common trap?
I would guess many Universities and libraries have adopted a Project Management (PM) approach.
While I like how project management adds rigor and transparency to the process of doing things, I have always been a touch uncomfortable of it but I was not sure why.
Then I came across this article - Product Thinking vs. Project Thinking
Here's how it describes Project Thinking
"The focus of project thinking is delivery. This could be the delivery of specific features or software, or really the delivery of anything. From aircraft to houses. And because the focus is delivery, the primary measurement is on the timeline and schedule. Project management is specifically focused on the output, and is measured by how accurately we were able to estimate the timeline beforehand and then deliver the specified output on that schedule. Success is largely defined as taking the specs of something beforehand, setting up a schedule with milestones all along the way, and then hitting those dates."
In other words, Project thinking tends to focus on hitting the deadlines and typically this means you already decided before hand what you are going to do (that's why you can be sure to hit the deadline!)
On the other hand product thinking is quite different
"Rather than focusing on the output, product thinking is focused on the outcome. This is a significant shift from the mindset of project thinking. Rather than focusing on timelines and dates, we focus on the goal we want to achieve or the job to be done. Because we’re focused on the outcome rather than the output, it is much more difficult to put time constraints around the delivery, at least up front. Primarily because we don’t necessarily know how we’re going to accomplish the goal up front."
To be fair, even I know Project Management when done right is more than just project thinking. And of course a project thinking mindset is perfectly fine for projects which are pretty routine and predictable. For example, for me I have ran so many benchmark surveys such that running a library survey is routine enough that once we have decided the survey instrument to run, the rest is pretty predictable.
On the other hand, some "projects" are far more tricky, for example imagine implementing a discovery service for the first time in 2009 or being the first in the world to launch some new class of software where you are unsure how users will react.
In such situations, it gets a lot more tricky to keep to a timeline since you arent sure what you need to be done to achieve the outcome (e.g. user satisfaction) you want. Trying to estimate appropriate deadlines and resolving to hit it at all costs and something will will have to give , typically the outcome.
The one advantage of RA21 SeamlessCoalition and FTR
I was recently watching ThirdIron's webinar on the new upcoming Libkey Link 2020.
Unlike the older version that worked only in Pubmed, Libkey Link 2020 would allow you to put Libkey Link in all the usual places you would your link resolvers e.g. Google Scholar, Scopus, EndNote etc and it would get the first cut at resolving content and only if it could not, it would pass through to your usual link resolver.
In the webinar, it was called a "Link resolver accelerator" and was not touted as a replacement for link resolver. Despite the fact that it would now produce a landing page similar to link resolvers, it still cannot be considered a replacement for link resolvers due to it's limitations.

Libkey Link's landing page, you can choose to go to the PDF or web link and choose to remember the option for 24 hours. There's is also a small link to go to your usual link resolver
My understanding is Libkey link can only resolve content with DOIs/PMIDs and is known to ThirdIron's knowledge base. That is actually far less than you would think.
While discussing using Libkey Link as a front end, a collegue remarked that in theory, ThirdIron should be able to produce a report that detected issues whenever a PDF was not returned , hinting at errors with entitlement data we provide to ThirdIron.
This led me to think, this is why solutions like SeamlessAccess and applications based on them like GETFTR look so attractive.
Because such systems merely certify to the publishers/vendors where the user is from and entitlements is set and controlled by the publisher/vendor so besides saying time managing the entitlements, there is no room for libraries to make errors.
So is there? While this sounds nice, I realised by doing so, you lead to a situation where the publisher/vendor is in fact almost by definition never wrong with entitlements!
Imagine a situation where a library paid for a certain individual journal title or package but there was a mistake on the publisher/vendor side such that they forgot to include the entitlement for the library.
A user would never know that in fact the publisher/vendor was wrong in not providing access. Even if the library correctly indicated he had access, the user would be rejected at the publisher site.
After all what point is there in "being right" but still not having access?
Does Microsoft academic ever match full text?
Note: What follows is a lot of speculation from me with a tweet reply from Microsoft research.
While initial blog posts were made on very little information - mostly drawn from work done by outside researchers and testing by me, Microsoft Research has began to publish more information on the nuts and bolts on how Microsoft Academic (the interface), Microsoft Academic Graph (the data) work as well as how it uses reinforcement learning and other Machine learning techiques to generate the data and results
If you are curious about Microsoft Academic these are some documents to read (all from the horse's mouth).
A Review of Microsoft Academic Services for Science of Science Studies
A Web-scale system for scientific knowledge exploration - covers generation of Field of Study
I found the first one very technical, while the second while not easy reading by any means, was more comprehensible as it was seemingly targetted at Bibliometricans and not machine learning specialists. I also spent very limited time playing with the free Public API
While things are a lot clearer now (e.g. estimated citations make sense now), one thing still puzzled me. Does queries in Microsoft Academic (the web interface) match full text?
After all we know Google Scholar definitely does and in fact it is their ability to do so and show search snippet in context that makes it superior to most alternatives.
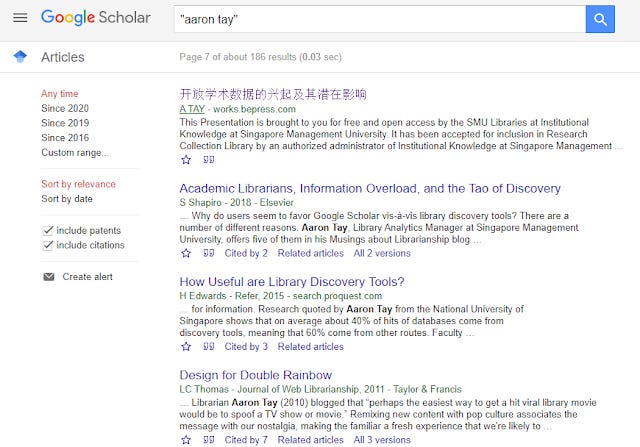
Google Scholar definitely matches full text and even shows snippets of it in context.
Even early on in 2017, I noted that Microsoft academic (web interface), returned far fewer results than Google Scholar and this is despite early studies showing Microsoft Academic was probably the second biggest academic index after Google Scholar.
For example searching for Library Discovery only yielded 173 hits.
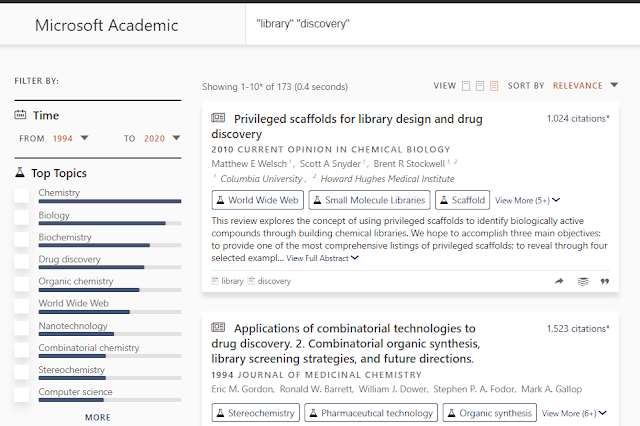
I remember somehow writing it off as some sort of semantic search effect but now I realise while that was and still is true it could also be consistent with the fact that they do not match full text.
Playing with the free restful API for evaluate and interprete helped a bit in understanding why some of the suggestions were given and get a count of number of results. But there are a few reasons why I think Microsoft academic never matches the full text.
Firstly, glancing at the entity attributes, particularly paper, we only see abstract (inverted), title, author, affiliations, publisher, field of study, year of pub etc. Interestingly enough there is citation context though.
We know for sure that sources that use MAG including Lens, Semantic Scholar etc. do not have the full text to match and we are told that Microsoft Academic (website) itself is just one application of the MAG dataset and is nothing special by itself. This would imply there is no full text matching going on in Microsoft academic.
Secondly, this blog post - Changes to Microsoft Academic Services (MAS) During COVID-19 talks about how they are going to allow quotes such as “novel coronavirus” ”china” to turn off semantic search and go back into keyword searching, and "expect such queries will retrieve articles with literal matches in the title or the abstract." Again there is no mention of full text.
Thirdly, doing search for unique text strings found in papers of open access articles (which full-text should definitely be harvested) with quotes yields no results. It's possible of course there is some semantic thing going on that causes it to drop query terms but seems unlikely.
I suspect Microsoft does have the full text as they harvest the web. They do a ton of "Entity Recognition and Disambiguation" and in particular "Concept Detection and Taxonomy Learning" (for field of study), which seems to my uneducated view hard to do if there is no full-text. But it definitely isn't released as part of MAG.
EDIT: 17/4/2020, Microsoft has replied to my question on Twitter.
They do not match full text at the Microsoft academic website as I guessed. Even more surprising to me for full text they only use it to extract references and citation contexts and have not done it for concept detection on full text. As they note below, citation contexts seem to do a lot of the work there.
We're using full text mainly to extract references and citation contexts. We have not conducted concept detection at scale on full text as the results are very noisy. Citation contexts, when used like anchor text for web search, can be really informative.
— Microsoft Academic (@MSFTAcademic) April 17, 2020
In fact reading the technical paper that Microsoft Research has put out on how they extract Field of Study confirms that they only use metadata and not full-text for tagging of field of study.
Roughly speaking, they first embark on a phase of "concept discovery", which generally involves starting off with 2,000 manually reviewed high quality concepts as FOS (field of study/concept) seed (also the first 2 levels of the concept hierachy are manually defined) and go through multiple rounds of a "graph link analysis" (general idea: if an entity neighbours are concepts, it probably is as well) and "an entity type based filtering and enrichment step" (general idea, if an entity is a personal name it probably isn't a concept, if it is a protein it probably is) to identify candiates from 5 million over Wikipedia entities in a internal knowledge base.
Once the candiate concepts are identified they need to figure out for each particular publication if the concept is the right one (tagging stage) This is where they create a vector representing the concept and the publication and calculate a similarity score (cosine similarity) between the two vectors.
But what do you use to create the text vectors?
"During the tagging stage, both textual information and graph structure are considered. The text
from Wikipedia articles and papers’ meta information (e.g., titles, keywords, and abstracts) are used
as the concept’s and publication’s textual representations respectively."
As typical with NLP/ML techniques these days which involve "understanding the meaning of a word by the company it keeps", so you understand the concept of a publication by also taking into account the publication's neighbouring nodes and as such part of the publications' representation also depends on the meta-data of it's neighbours, hence taking into account the graph structure.
Want more detail? Read on. I'll focus only on the text representation of the publication not the concept.
Each entity has two representions a SRT (Simple representing text) and ERT (extended representing text) , where the former is text from the entity itself and the later includes text representation from it's neighbour (taking into account graph structure).
Note : venue in Microsoft Academic speak is equalvant to what we call journal title, or conference title
Then
Publication SRT = "Textual meta data, such as title, keywords, and abstract"
Venue SRT = "A publishing venue’s full name (i.e. the journal name or the conference name)".
Venue ERT = a concatenation of the SRT of a sampled subset of publications from the venue
In other words to get a venue ERT, you sample the publications in the venue and combine the publication SRTs.
Finally the Publication ERT = "SRT from its citations, references and ERT of its linked publishing venue".
There's further technical detail on how they weight to discount neighbour effects and features extracted such as bag-of-words and how they are concatenated to create text vectors but you get the point. It's all working on publication metadata not full text.
It also explains one fact that I was wondering about. We are often told that Google Scholar can't have an API because their agreements with publishers allow their harvesters to harvest full text behind paywalls but in return they are prohibited from releasing the data.
Yet we see Microsoft happily release MAG as open data. That's because I speculate they have designed their system from the scratch to seperate out the full text they can harvest from the metadata (in fact of metadata is generated from the full text they harvest using machine learning in particular citation context, abstracts etc), and they then provide the metadata (MAG) only.
Presumably Google Scholar could of course do the same, but they either aren't setup as easily to make this distinction or they are just not interested in going that route of allowing the data to be open.
All in all, Microsoft academic appears to be much closer to a very advanced state of art A&I index like Scopus than something like Google Scholar, Summon, Primo, Dimensions which matches on full text. This will have implications of course on how you search....
Conclusion
As you can see my "musings" are as usual quite disparate. Perhaps reflecting some of the upheaval and chaos we are all no doubt experiencing during this interesting period of our lives.