


A conceptual view of information retrieval - can we do better with AI?

I've watched with interest, as academic search engines use AI to improve searching.
Elicit is probably currently the leading example of this, using transformer based language models to
improve search relevancy ranking
use RAG (retrieval augmented generation) across multiple documents to generate a paragraph of text to answer the query with citations
extract information to create a research matrix table of papers
More recently, they added the interesting Notebook features, where you can among other things iterate different searches and combine the results.
But despite all these amazing advances, it still strikes me that Elicit and similar tools such as SciSpace, Scite.ai assistance, Consensus.ai (as well as more established databases such as Scopus AI, Dimensions that are adding AI) are still arguably fundmentally following the same paradigm set by conventional search engines like Google Scholar at least in the way relevant documents are retrieved.
What do I mean?
Ad hoc retrieval
In information retrieval, there is the concept of Ad hoc retrieval. It is
Despite the numerous diverse types of retrieval methods from Boolean retrieval, ranked retrieval, vector state model, Probabilistic retrieval models and now neural search/embedding search, they can all be encompassed using one conceptual model shown below.
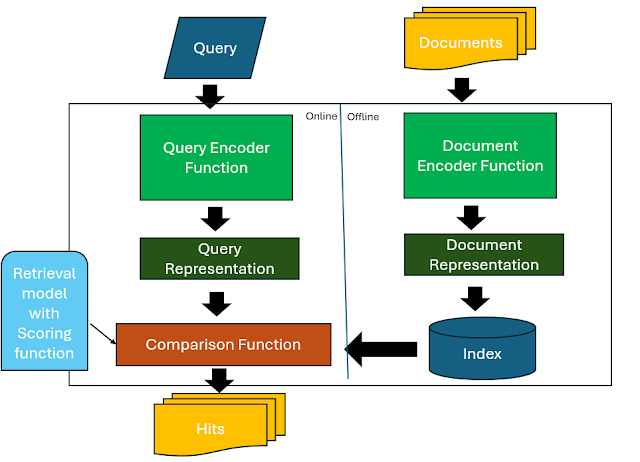
Conceptual model for information retrieval
Essentially the idea here is that regardless of the method used they all involve the following common steps.
Firstly take all the documents and using some function as a document encoder, convert the documents into some sort of representation and store it in a index prior to searching.
Secondly, as queries are entered in real time, the system does the same with another function, the query encoder to convert it to a query representation.
The final step is to compare the query representation with the document represenations with a "comparison function" to score the most relevant documents which are then typically ranked and displayed.
In fact, one of my favourite papers on information retrieval written in 2021 - A Proposed Conceptual Framework for a Representational Approach to Information Retrieval, points out this model applies both for "dense retrieval methods"/Neural Information retrieval/Embedding vector search as well as more traditional "sparse retrieval methods" like BM25/TF-IDF.
Technically speaking the model above is a "logical scoring model" as opposed to a "physical retrieval model" which focuses on the actual implementation and efficiency of retrieving documents from a physical storage medium.
So for example, it would focus on how to do top-k ranking of sparse representations (e.g. BM25/TF-IDF) with an inverted index in as efficient way as possible (e.g. with WAND, Block-max) or in the case of dense representations involve the use of Vector stores and approximate nearest neighbor (ANN) search such as hierarchical navigable small world graphs (HNSW) to do the comparisons.
I'll spare you from the formalism in the paper but describe it using an example.
Bi-encoder approach
In past blog posts, I have talked much about the rise of new powerful semantic search, fueled by embedding based search/neural search.
Most of this is done using a bi-encoder architecture model. How is this done?
Pre-search the system runs documents through a language model (eg encoder only BERT type models, other embedding encoders such as those based on GPT type models are possible) to encode documents (or text chunks) into embeddings of a fixed length.
Typically these vector embedding generated are then stored in a vector store.
When the query is entered it is also seperately in real time converted to a vector embedding of same fixed length and they are compared or scored using cosine similarity to the documents that have been pre-indexed to find the closest match/highest score.
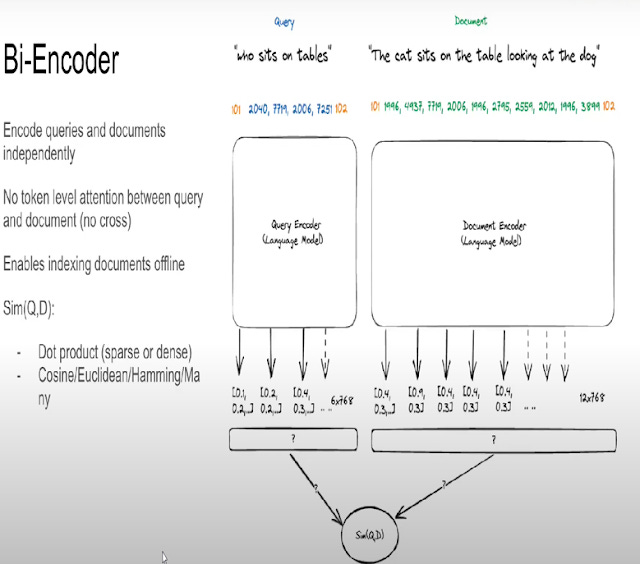
\
Talk by Jo Kristian Bergum, Vespa
It is important to note that when the query or document is passed through a Bi-encoder language model, it actually outputs a embedding vector for each token. These multiple embeddings are "pooled" together (multiple methods such as averaging or the [CLS] token see later) to produce one embedding each for the query and document and it is this overall document embedding that is stored and indexed and it is this document embedding that is compared with the query embedding.
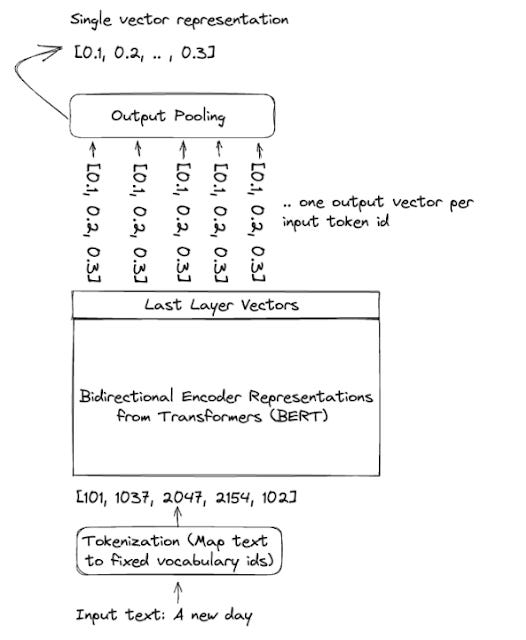
As you will see later, trying to condense the "meaning" of the document into one embedding (as opposed to retain embeddings for each token) reduces performance
In practice even with all documents pre-indexed and stored in a vector space, it is too slow to do cosine similarity one by one, so approximate nearest neighbor (ANN) search such as hierarchical navigable small world graphs (HNSW) are used.
BM25, TF-IDF and other bag of words approach
For BM25/TF-IDF and other bag of word type sparse retrieval methods you can see it as storing documents in a term-document matrix
CMPT 621/664 Information Retrieval- Session 2 - Boolean Retrieval
In the example above, a term-document matrix is created where 1 is indicated if the document contains the term and 0 otherwise, which allows support of basic boolean search.
The query encoder can uses a multi-hot representation, with a weight of one if the term is present in the query, and zero otherwise and the comparison function can be the inner-dot product.
Instead of using a binary scheme to encode the cells, you can also use TF-IDF or BM25 weights to create vectors and do the same.

Introduction to Information Retrieval - Session 8: Term Weighting and Vector Space
In practice of course, for such bag of words methods, inverted indexes are used to store the documents.
Sparse vs dense representations/embeddings
Traditionally "bag of words" type methods like TF-IDF, BM25, result in sparse embedding/representations.
This is because typically all the terms in the vocabulary are included, and as such in a term-document matrix , most of the cells are zero because documents only have a vast minority of all words, resulting in a sparse embedding/representation.
This is as opposed to the dense embedding/representations seen earlier which has a fixed embedding length (typically much smaller than the whole vocabulary) and as such most of the cells are not null.
Traditionally sparse embedding/representations are stored using a inverted index and can be retrieved much faster than dense embedding/representations that are stored in vector databases and tend to be slower to retrieve.
As you will see in the next blog post, dense embeddings also tend to be fine-tuned for their domain tasks....
Cross-encoder approaches
So far the two methods discussed allow you to do a pre-search encoding of documents, to generate either spare or dense embeddings for indexing and fits nicely into the conceptual model above. But an alternative to bi-encoders is cross-encoders which is harder to fit in.
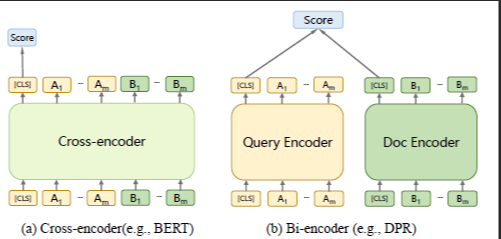
From Multi-View Document Representation Learning for Open-Domain Dense Retrieval
Unlike in the case of the Bi-encoder when you encode the query and document seperately and then use a comparison function to compare the two representations (typically using cosine similarity or dot product of the two embeddings), in a cross-encoder, you enter both query and document into the same encoder (e.g. BERT) at the same time, which will then output a score on whether the document is relevant to the query or how relevant the document is (score).
Empirically cross-encoders provide far better performance than bi-encoders, which makes sense because Cross-encoders captures interactions between tokens from the query and the document while Bi-encoders only take the overall embedding (shown as [CLS] in the diagram) as opposed to token level embeddings of the query and doc to do a comparison.
Here, it is harder to accomodate cross-encoders into the conceptual model above, unless one argues the the Transformer inference is part of the comparison function!
Of course, Cross-encoders have a huge drawback. Because of the way it works, where you need to feed query and documents into the same encoder, you can only do this in real-time and unlike bi-encoders you can't preindex the document, making it impossible to do so for large document sets!
Hybrid Search and multi-stage search
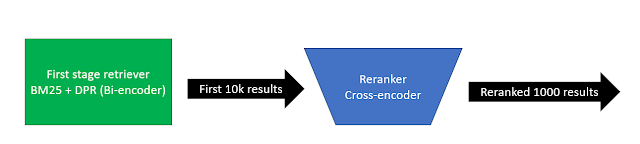
This is why the idea of multi-stage retrieval with rerankers are used. The trick is to use a cheaper first stage retrieval system (often BM25 or even a dense retrieval method) to retrieve say the top 10k results and then rerank these 10k with a more powerful but computationally expensive algo like Cross-encoders.
You can even try to use multiple rerankers (multi-stage reranking) to try to squeeze out more performance, progressively reranking smaller sets with more computationally expense but accurate algo.
Of course, you have to be very careful that the initial first stage retriever does manage to find all the relevant articles that is being passed to the reranker. Otherwise if the relevant documents are not in the inital pool of candiates to be reranked it doesn't matter how good the reranker is.
That is why a common practice is to use more than one method to find the initial pool of canidates. A common idea is to use both sparse retrieval methods/lexical search methods like BM25 and dense retrieval methods/semantic search methods like Bi-encoders. This allows you to cover the weaknesses of both methods (e.g. semantic search is weaker at exact match searches, slower and may have problems with newer terms not known to tokenizer)

https://cameronrwolfe.substack.com/p/the-basics-of-ai-powered-vector-search
Evaluating the results
There is an array of metrics that are used in information retrevial to measure peformance from
Recall@K
Precision@K
MAP (Mean average precison)
MRR (Mean Reciprocal Rank)
Normalized Discounted Cumulative Gain@K (NDCG)
If you have multiple ways of scoring (say you want a search to take into account ranking using standard lexical search with BM25 and a dense encoder method), you can create a hybrid score using Reciprocal rank fusion (RRF) methods (essentially create an overall score by summing up the reciprocal rank of each method) or use traditional learning to rank methods to learn the best weights for each method, if you have data on relevancy ranks.
For example, you may decide you want to include factors like citation count, journal , topic relevance into the ranking but unsure what weights to use. Learning to rank will look at say what people click first as a signal what is relevant and learn the right weights.
A new paradigm?
So what is wrong with following this? Nothing really, for decades pretty much every search engine both web-based and academic is built on this paradigm.
But at the end of the day, these type of searches tend to follow what I call the very familar "google paradigm".
Firstly, we expect searches to return results within a short amount of time. This may not be a very big issue when the best algos we had like BM25 was very efficient and increasing compute time spent on it did not lead to much better results but as we have seen with Cross-encoders this might not be true with our current state of art neutral IR methods.
Also many of these search engines are tuned for high precision rather than high recall searches (e.g. Recall@10, NDCG@10) which while good for explorary searches, isn't ideal when you want to do a deep through literature review much less an evidence synthesis where the aim is to find as many relevant articles as possible (say 30-50).
Unfortunately because relevancy algos up to recently just aren't good enough to even try...
Part of it is as any evidence synthesis librarian will tell you, it is unlikely that any single search (even one with state of art embedding search like COLBERT or SPLADE as of 2023) will have that high a recall, you typically will have to run multiple searches and aggregate the results together.
I know a evidence synthesis librarian will say you need not just multiple search queries but multiple search queries over multiple databases and not just in one but 1) multiple searches over a huge database and combining results is almost certainly better than just one search 2) Most studies that say GS despite having huge recall, is let down by inferior features that do not allow high precision searches do not seem to have studied the impact of using multiple different Google Scholar queries...
While the latest Elicit notebook feature allows you to do multiple searches and combine the results, this is done manually by you, is there a system that does this automatically for you?
To be fair, Elicit itself is planned to have multiple workflows, and what we call Elicit now is just the "find literature workflow"... and more workflows might be coming
Particularly something like AI agents such as Auto-GPT, AgentGPT, BabyAGI will do the trick?
In other words, is there a academic search that
a) acts as an Agent like system that does multiple searches and adjusts the search based on what is found
b) optimises for recall rather than precision
c) Is not under pressure to return results in less than a second because such searches is likely to take a while?
I believe there is one and it is called Undermind.ai , more on that in the next post.
EDIT - April 2025
Since I wrote this blog post in April 2024, "Deep Research" tools have become all the rage, that combine agentic search and producing long form reports are now all the rage.
Resources to learn
Librarians have asked me for resources to learn about information retrieval formally. For fundmentals of Information retrieval, you can just consult any standard Computer Science - Introduction to information retrieval 101 course. I notice a lot of these courses draw examples from Stanford's Introduction to Information Retrieval book
Some course material that I found helpful are
Introduction to information retrieval - by Behrooz Mansouri, Fall 2022, University of Southern Maine
Goes into depth into indexing, retrieval ("physical retrieval model"), WAND etc.
CMPT 621 Information Retrieval, Spring 2021 course at Qatar University by Dr. Tamer Elsayed [video]
This gets you typically up to the state of art as of 2010s, Pre-BERT era. After that, you can try to read the literature from 2020-2023
Some good review papers I enjoyed
Pretrained Transformers for Text Ranking: BERT and Beyond
Very through but dense, don't start with this :)
A Proposed Conceptual Framework for a Representational Approach to Information Retrieval
This blog post mostly inspired by this article, but I read this after I had quite a bit of background already
Semantic Models for the First-stage Retrieval: A Comprehensive Review
Less lengthy version of first piece but still formidably dense without background
But if formal literature isn't your cup of tea to learn about 2020+ developments , you can consider blog posts and youtube channels from industry players (e.g. Vespa, Elasticsearch, Cohere, Langchain, Llamaindex).
The Basics of AI-Powered (Vector) Search
This goes into depth into sentence bert (Sbert) which I did not cover and is also pretty technical
Haystack EU 2023 - Jo Kristian Bergum: Navigating Neural Search: Avoiding Common Pitfalls [Video]
Vespa is a open source search platform that is used by many state of art search engines like Elicit. Competes with Elastic search I believe. I've learnt a lot from tweets from Jo who is a Vespa Distinguished Engineer and the talk about is a great practical summarization if all you care is the high level details of search
Vespa Blog, Elastic Search blog, Cohere LLM university,
These are all great industry , practioner based sites to learn the essentials of building a great search if you don't care about academic jargon
Langchain and Llamaindex youtube channels
This blog post doesn't focus on RAG (Retrieval augmented generation) but some of the best places to learn include Langchain youtube channels (eg RAG from Scratch series)
Good luck!