
A relook at GetFTR , Libkey, Exlibris Quicklinks, and other linking and authentication technologies

RISK WARNING NOTICE: my understanding of such matters are incomplete, read at your own risk!
I haven't been looking closely at Seamless Access and GetFTR for a while, but given it is nearly two years since GetFTR was announced, I decided to see how it has changed and was pleasantly surprised by some of the changes.
But before I go into the changes let me describe my experience playing around with Semantic Scholar.
Semantic Scholar support of GetFTR and Libkey paths to full-text
A while back, I was trying to sign in with Semantic Scholar via federated access by using the "Sign in with Your institution" option.
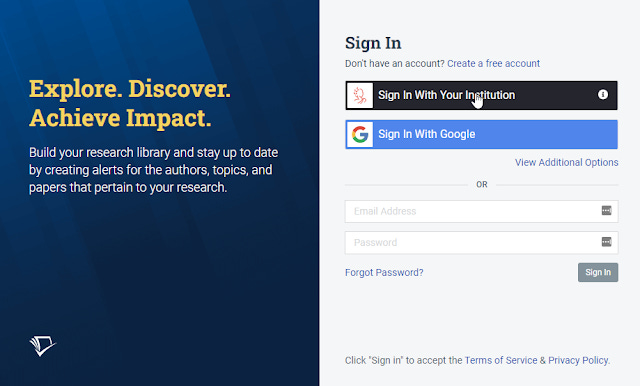
Login in Semantic Scholar via "Sign in with your institution"
Post blog note: Semantic Scholar seems to have implemented the OpenAthens Wayfinder service. which is intergrated with the SeamlessAccess service which saves any institution selected in Wayfinder (if enabled by the service provider) so it displays on the SeamlessAccess ‘button’ or icon.
I was pleasantly surprised to note my institution could be found (was registered in Federation).
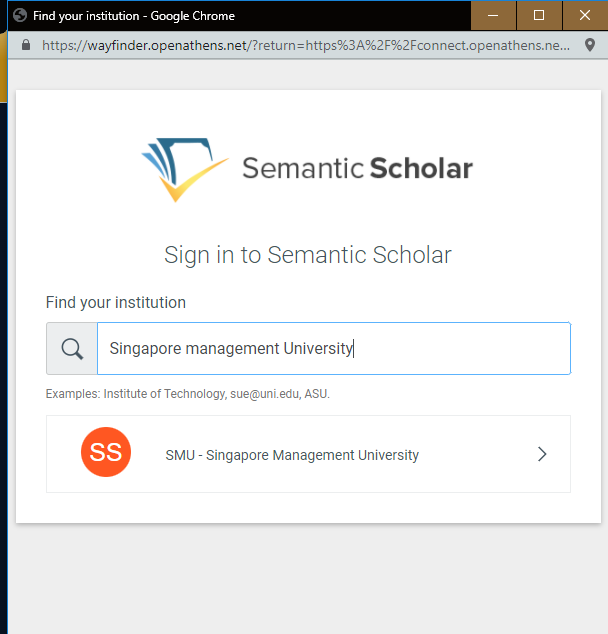
Sign in with my institution
Post blog note - Semantic Scholar states that "researchers have a privacy-centric way to create accounts and access content on and off campus through our institutional login powered by OpenAthens, and our support for eduGain, InCommon, and other identity federations"- My understanding of federations is very weak, but I think eduGain acts like a "meta-federation" and connects 70 federations so chances are very high if your institution supports SAML and is in some federation , it will be included.
After being redirected to my usual sign-in page (IDP) and signing back in, I got sent back to Semantic Scholar.
Big whoop right? Wrong. Because now Semantic Scholar knows what institution I am from it can selected display links when it thinks I have full text access.
And what does it use to display links to full text? It of course uses GetFTR first announced in Dec 2019 that publishers are throwing their support behind.
Semantic Scholar has a twist though.
Firstly as expected some articles will have a "Access PDF via institution" courtesy of GetFTR
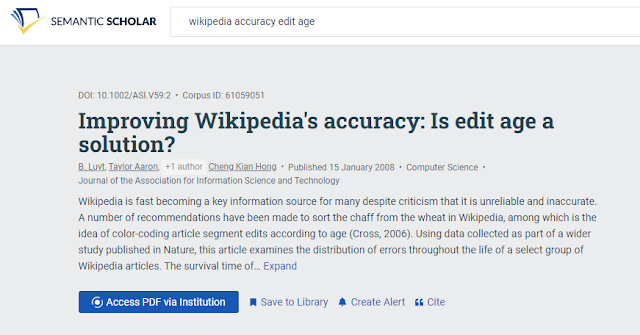
"Access PDF via Institution" in Semantic Scholar via getFTR
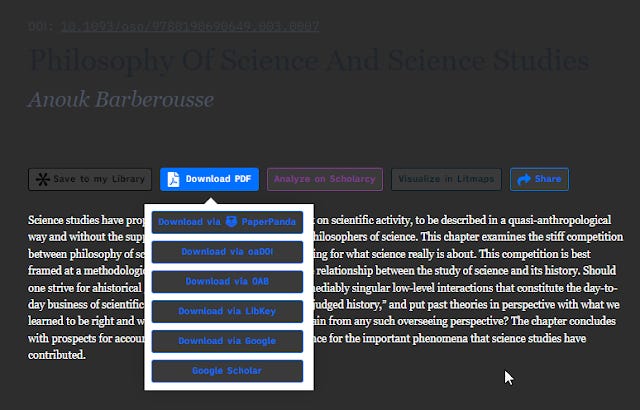
But on some other record you see that they support also Libkey and you see a "Access PDF via Libkey" button!
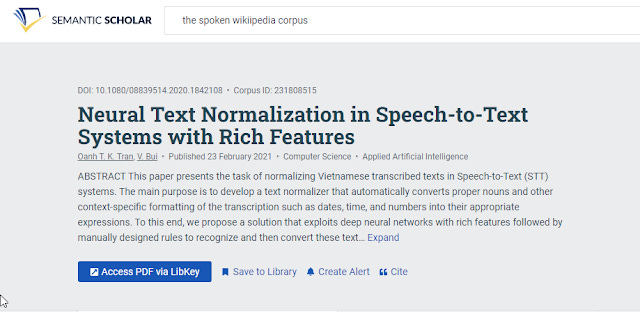
"Access PDF via Libkey" link in Semantic Scholar
This is really interesting because Semantic Scholar is the first platform I've seen support two different linking to full text technology - Libkey and GetFTR
From what I understand Semantic Scholar tried to use GetFTR first and if that fails to find a viable link it will provide a Libkey link if supported.
Some testing seems to suggest that while GetFTR uses your authenticated institution to display full-text links only if you have access, Semantic Scholar doesn't seem to do the same for Libkey. It seems to be a generic libkey.io link that requires you to indicate your institution and clicking on the link may lead to an article where you have no full-text
Post blog note : All these details including support of GetFTR and Libkey is confirmed on this page aimed for librarian by Semantic Scholar.
Lens.org support of Libkey and Worldcat registry link resolver paths to full-text
While Semantic Scholar has been ahead of the curve implementing both getFTR and Libkey linking to help guide users to full-text based on their affiliations, other platforms have also done similar work.
The traditional approach has been for subscribed database and platforms like Scopus, Proquest etc to approach each subscriber institution to ask for the link resolver path. But for mostly free services like Semantic Scholar and Lens.org they have no such existing relationship with institutions, neither would they want to given how lean these organizations can be.
One solution is of course to implement getFTR. And the other lighter weight option is to support Libkey.
However getFTR currently only supports publishers (and not all just the major ones) and no aggregators. Libkey supports a whole lot more and will even fall back to the institution's link resolver but not every institution subscribes to the commerical service.
But almost every academic library has a traditional link resolver. Is there a way for organizations like Lens.org or Semantic Scholar to automatically direct users to their link resolvers?
One could imagine a user of Lens.org or Semantic Scholar signing on with ORCID, which has the user's affiliations. This can be used to the direct the user to the right link resolver (with further signins downstream). The problem though is how can these organizations figure out where each institution's link resolver is without individually dealing with them?
There is an answer , sort of. The OCLC’s WorldCat registry of library resolvers.
This problem where the content owner needs to figure out the setting for thousands of diverse institutions is a general problem. It is often useful for the content owner to know a given institution's IP range, Ezproxy stem, link resolver path, IDP server etc so given a user's known affiliation, they can be properly guided to appropriate options. Registries like Theipregistry.org or apps like Zotero straight out maintaining their own lists have sprung up to solve this issue with varyng degrees of success.
Lens.org in fact supports this in a light weight manner.
As you can see below for every record there are two links, one labelled Libkey which tries to get you to full-text via Libkey using your affiliation and the Worldcat button that tries to figure out which link resolver path you should be sent to,

Either way both try to use your affiliations to access full text.
A flood of links to get full-text
Knowledgable readers of course know that what platforms like Semantic Scholar face is the age old "approprate copy problem" first identified 20 years ago where the platform needs to figure out how to direct each user to the best link that is likely to give them full-text.
Today, the problem has not gone away though these days we also need to take into account the possibility of open access or free to read copies.
Ultimately though while platforms can offer a multitude of links going to full-text e.g Unpaywall (formerly oadoi), Core Discovery and even illegal options , when it comes to legal options that use your affiliation (and not just try to find OA content) there seems to be only
1. getFTR
2. Libkey
3. Worldcat registry to link resolvers
Updated thoughts about GetFTR
In many webinars and conferences I have attended there are inevitably people who are confused between RA21/SeamlessAccess and GetFTR .
At the risk of simplifying, RA21/SeamlessAccess is about authentication (basically proving who you are or more commonly which institution you are affiliated with) while GetFTR mostly works after you are authenicated and then tries to solve the "Appropriate Copy Problem" (kinda but see later).
The idea here is that you are on a discovery platform that supports GetFTR (e.g. Dimensions, ReadCube) or some scholarly collaboration network like Mendeley and it is shows some articles in the results.
Because you have already authenicated it will know which institution you are affiliated with and it gets to do "real-time entitlement" checks (which as the phrase suggests is about finding what you are entitled to) to know "on the fly" if you have access to the article and display a direct full text link to the full text (usually PDF)
You might be thinking isn't this exactly the same as link resolver links in say Web of Science or even the Library Links in Google Scholar? (not to be confused with Campus activated subscriber access - CASA)

Google Scholar Library Links
While in terms of function they seem to do similar things, i.e. guide you or provide signposts to access to full text via your entitlements, how they work are very different.
GetFTR behind the hood
One of the better explainations of how GetFTR works seems to be this article - GetFTR: dataflows and user privacy
It explains the GetFTR process as the "integrator service" (the platform supporting getFTR) passing over to the GetFTR just two pieces of information
DOI of article whose status is being checked (is user entitled)
The user’s affiliation
The article explains there are multiple ways the "integrator service" can get this information via SAML or even SeamlessAccess logins or via IP recognition.
The last is a bit of a surprise, since when first announced IP recognition wasn't an option. The article carefully stresses that getFTR only uses the two pieces of information and does not capture any other information about the user to try to ally privacy concerns.
There's an interesting side note about if the IP option is used though
This means that integrators can also share user’s IP addresses with GetFTR, although this is optional. Those that choose to share user’s IP addresses with GetFTR and participating publishers, have to notify users via their privacy policy ahead of doing so. GetFTR and publishers who receive IP address information from GetFTR are only allowed to use this for the purposes of checking entitlements.
Once the user's affiliation is established, GetFTR uses the DOI of the article to query Crossref to figure out the right publisher that owns that content. Assuming the publisher supports getFTR, getFTR will check the user's entitlement (given DOI and affiliation) and return the following pieces of information
level of entitlement (e.g. yes, no)
access type (e.g. open, free, paid)
document type (e.g. version of record or alternative version)
content type (e.g. html, pdf)
link to full text
The intergrator service uses this information to display entitlement information on the webpage and similar to SeamlessAccess this is a piece of UI that has been well tested and tries to be consistent across all platforms that implement getFTR.
But how does this differ from traditional link resolvers?
Differences with traditional Link resolver links - Real time signposting + direct link to PDF
Firstly, traditional library link resolver links in most platforms are not "contextually smart". The link resolver link will appear next to every result and the user will only know if he has access only after they click on it.
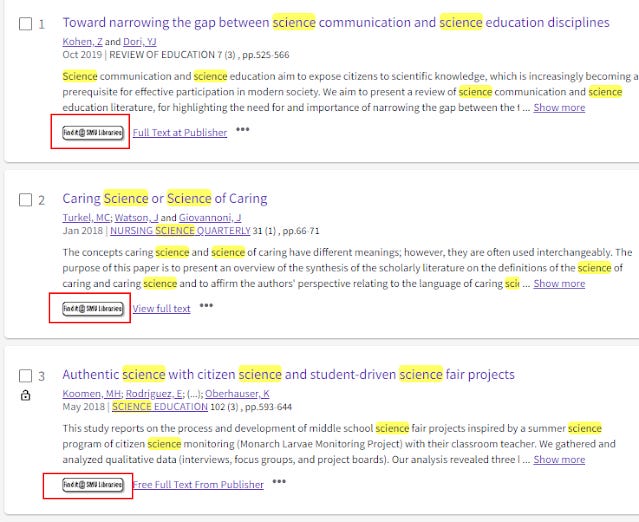
Link resolver links in Web of Science appears next to every record. User only knows the result (as access or not) after clicking on the link
Depending on the holdings of the institution the user is affiliated with, he may have access to full text and be directed to the appropriate link or if he has no access he may be directed to alternative services particularly Document Delivery or Interlibrary loans.
In comparison, GetFTR enabled platforms will do a pre-emptive check get the result and display on the interface whether the user has access once the page loads.
In other words, GetFTR will do a real-time entitlement check and display availability status (signposting) to the user next to each result upon the page loads, so users won't have to "click and pray" when using traditional link resolvers.
Depending on the content owner, they also have options to display alternative links instead if the user is not entitled to access the full text.
Note : There is a suggestion that even traditional link resolvers such as SFX can work functionally like GetFTR and check each article on the fly and display an appropriate link or message depending on availability and this is indeed true. But with the exception of Google Scholar links (see below) this usually isn't how most platforms implement it.
Google Scholar link programmes can help with contextual links
Still the idea of doing a precheck to see if a user has access before displaying the link isn't new. Libraries that support the Google Scholar's Library Link programme (most academic libraries) are basically capable of telling the user what he is able to access full text in the same way by only showing links next to articles which access is av ailable.
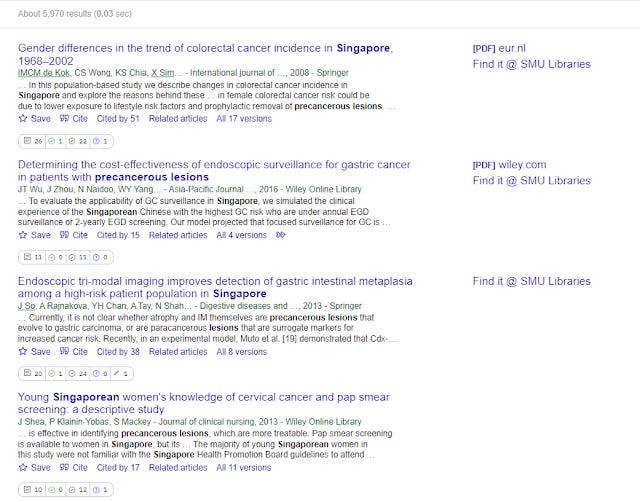
In the above image of Google Scholar results, the first 3 entries are accessible via my institution and a link ("Find it @ SMU Libraries") appear but the 4th result, Google Scholar determines we are not entitled to access and shows no link
How this is done is that each institution is setup to send their holdings to Google Scholar (updated monthly) that is used by Google Scholar "on the fly" to determine if the user has access to the article.
So for example the user has indicated to Google Scholar that he is from my institution. We have setup our Alma resolver system to send our holdings monthly to Google Scholar.
These records basically tell Google Scholar something like for Journal A we have holdings from 19xx to 20xx, For Journal B we have..... and so on
So when our user searches and see a set of papers in Google Scholar, Google will look at each displayed record and tries to match against it's copy of our holdings to determine if we have access and if so provide a link resolver link. Clicking on it will proceed in the normal link resolver manner.
This avoids the blind guessing you get when clicking on link resolver links on other platforms, though at the cost of needing to updating our holdings with Google Scholar every month.
Up to Feb 2020, Pubmed supported link resolvers with the Linkout local option which works like Google Scholar library links. Libraries would supply Pubmed with their holdings and this would be used to selectively show link badges on Pubmed platform. However as of writing the only option supported going forward is Linkout "outside tool" which provides a link next to all records, similar to most platforms.
Note: Google Scholar also provides a seperate, independent feature where Google Scholar can also try to provide a link resolver link even if there is no holdings match (see below)
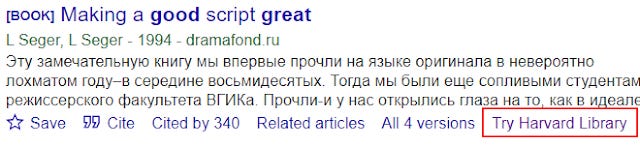
Google Scholar link that appears even if there is no holdings match
Why would you want to expose such a link? Firstly, this allows the libraries to provide options even if there is no direct access. This usually means providing options to do ILL/DDS without neediing to re-enter all the metadata.
Secondly, the holdings checking usually only works for *online* content. This allows you the chance to be directed to the catalog record of print books.
Lastly, holdings check might be inaccurate, more than once I have found that if you still try to go through the link resolver you actually find that you *do* have online full text access.
One thing I've noticed about the link generated by this feature is it does not appear on all Google Scholar records. My guess is the link is only generated when there is sufficient metadata (doi, ISBN) maybe for a fairly reliable OpenURL link resolver link to be generated.
Linking directly to full text
Endnote Click/Kopernio, popularized the "one click PDF" feature. ThirdIron Libkey claims "one-click access to full text articles".
The terms differ and may even be referring to slightly different concepts. But they all call out the fact that traditional link resolvers do not always or even usually link you directly to the full text. Often they will send to you to some landing page and you may need to click one more link to the PDF if not the html full text. This varies by platform of course.
The promise of newer systems is that they click to PDF directly and if failing that the html full text. Again there does not seem to be any reason why traditional link resolvers can't do this.
New [Dec 2021]! Exlibris discovery services Primo and Summon has announced a Quicklink feature that purports to bring you directly to the full-text. Currently the list of supported content owners are small and it's unclear to me if this is a discovery service feature or a general link resolver feature.

So if traditional link resolvers can in theory do all this what fundamentally new thing does getFTR bring to the table?
The key difference - Entitlement checks - should we check with the publisher or the library?
While the above mentioned differences between getFTR and link resolvers are not insigificant, I would argue the key difference between how GetFTR works and traditional library link resolver links works is where the entitlement check is done against.
While traditional link resolver methods (including Google Scholar library Links and even Libkey as you will see later) do their checks against the library itself (basically against the Knowledge Base of the library), GetFTR does real-time checking directly against the publishers (that support GetFTR).
In the sense, GetFTR cuts out the middle man of asking the library and goes direct to the source (publisher) to check for entitlements
Interestingly I actually see parallels with how getFTR works with how EndnoteClick (formerly Kopernio) works, since it directly queries publishers with your stored credentials to check if you have full-text. Similar to getFTR, when using Endnote click there is no need to setup anything with the library as it checks directly with the publisher!
Entitlement checks against the library - how Knowledge bases work
In the case of traditional link resolver checks, the checking is done against the library's "Knowledge Base" (typically Alma, OCLC worldshare etc). From the journal only point of view you can think of the Knowledge Base as a database listing each institution's entitlement for every journal (and where they can be accessed).
So for Journal X, the knowledge Base could say you have access for it at JSTOR from 1930 to 2000 and for the same journal you would also have it at Wiley from 2000 onwards.
BTW this nicely illusrates how Knowledge bases and link resolvers help solve the "appropriate copy problem" because users from different institutions might have access to the article via two difference sources. For example, depending on the user's affiliation he may have access to an article via a Publisher like Wiley, Aggregator like JSTOR or increasingly even open repository (e.g PMC).
Clearly keeping the Knowledge base uptodate is of critical importance for users to enjoy reliable accurate links.
If a institution's Knowledge Base mistakenly says the user has access to something he doesn't, that will lead to fustration as he runs into a dead end when he lands on the page. On the other hand, if a institution actually has access to something but the Knowledge base mistakenly leaves it off ? The user will be misled into thinking they have no access as the link resolver will not show that as not available.
Unfortunately after two decades of Library Link resolvers (essentially Knowledge base with OpenURL+other linking protocols) , we know that linking reliability peformance is mixed at best.
There are at least half a dozen of reasons why e.g. metadata mismatch inaccuracies, different grainularity of linking at the target and source etc but here I will focus on two most relevant reasons that getFTR targets.
Firstly even for a average sized academic library, managing journal entitlements is no easy task and involves managing hundreds of journal packages and hundreds of thousands journal titles.
This results in the knowledge base having errors or inaccuracies.
It doesn't help that up to recently, there has been lack of standardisation in how publishers provided entitlement and holding information to be uploaded into knowledge bases. But even with the excellent work of the NISO groups on KBART (Knowledge Base and related tools), it is still a big job, particularly when libraries have their own particularly unique package of journals and publishers are unable to provide holdings files for direct import into the library's system and the librarian has to spend time trying to beat the data into shape.
All this leads to delays where even though the ink to the contract is dry and the publisher has updated their access control to open access to users, the link resolver will continue to signal the newly available articles are still not available because of the delay in updating the Knowledge Base.
Even with advancements like NISO's KBART Automation - Automated Retrieval of Customer Electronic Holdings where systems like Alma can use publisher APIs to automatically populate their holdings, getFTR may have the upper hand in terms of creating more reliable links since you get the information from the "horse's mouth" so to speak.
As a sidenote, I have focused on accuracy of entitlements, but I think it is likely getFTR is able to get more reliable links even if both traditional library link resolvers and getFTR correctly list an article as available particularly if we talk about traditional OpenURL generated links which are prone to breaking due to metadata mismatches etc.
Checking at the article level vs journal level
GetFTR also touts one other reason for their superiority to traditional linking technology that relies on Knowledge bases.
As they correctly note, Knowledge bases specify entitlement at the journal/source level. While this is usually fine for subscriptions when we are specifying access, we live in a world where hybrid journals exist, such that some articles might be free in one issue which others might not.
GetFTR instead works at the article level. As described earlier, GetFTR starts off with a DOI which is a article level piece of information. It will
1. Check the DOI with Crossref for the publisher
2. Assuming the publisher supports GetFTR, figure out from the publisher APIs, whether the user (who has earlier authenicated) if he has access
3. Profit!
Notice this works at the article doi level, so the publisher is perfectly capable of replying that this article is available for access while another article in the same issue is not, something you can't do using Knowledge bases which can specify access only at the journal vol/issue level at most.
And this applies beyond hybrid OA, the publsher might occasionally turn on free access for some issues or articles for certain periods of time (e.g. COVID) and even if the Knowledge base could reflect these changes it would be extremely unlikely a library would borther to update their holdings for such reasons. With GetFTR such temporarily free copies could be seen as available with zero effort from the library.
Defenders of the traditional link resolvers might object that library link resolvers these days are a mix of technologies of which OpenURL is just one (and increasingly less important ones at that). For example, the hybrid issue can and is solved by bolting on OA finding services like Unpaywall, or even a paid for service like Libkey Link (see later)
Still it might be argued even such services would be less accurate or reliable than Publisher's own entitlements API (who knows better on whether a user will be rejected or given access after all!)
Comparison with Libkey
A somewhat interesting comparison is to compare Third Iron's Libkey with GetFTR and it often gets mentioned at webinars on getFTR on how similar or different they are
Here are the list of similarities based on my understanding
1. Both work at the article level and work only on DOIs
2. Both aim to bring you to full-text
3. Like GetFTR, Libkey (unlike Lean Library and other "Access broker" browser extensions) aims to be infrastructure for linking to full text for platforms (based on user's affiliation) around the world. Already some platforms like citationsy, inciteful, Lens.org, ideas.repec already support Libkey natively.
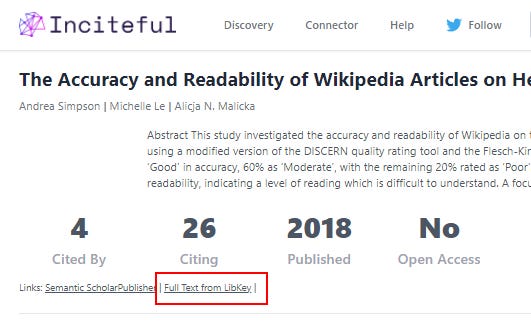
Inciteful platform natively embeds Libkey linking feature
Here are a list of differences
1. Libkey supports not just publishers but also aggregators including Proquest , Ebsco and OVID while GetFTR does not support aggregators yet (though there is "interest").
2. Libkey works with the traditional link resolver. It calls itself a link resolver "accelerator", and it will pass on requests to the link resolver for queries it does not have any hits. GetFTR suggests in the FAQ it might want to "expore" link resolver intergration but this seems far off.
3. Libkey is simple to intergrate for platforms (essentially Libkey.io/<doi>) compared to GetFTR which needs more investment.
4. Libkey does not build-in any authenication, while GetFTR does. If you have used Libkey prior to clicking on the the Libkey link, it may know your institution and work accordingly, but if it does not? You have to select manually your institution. You can of course also hard code WAFless Libkey links like https://libkey.io/libraries/[LibraryID]/[DOI or PMID]
5. Libkey works only if you are one of admittedly thousands of libraries that have a ThirdIron subscription, while GetFTR should almost always work (particularly if they do support IP authenication) if the platform chooses to implement it (and of course if the content is from a publisher that supports getFTR).
I don't want to leave you with the idea that GetFTR and Libkey are bitter rivals. In fact, ThirdIron has two staff members on GetFTR's advisory board.
While the two do seem to "compete" in terms of the use cases they can support currently, as we see in the case of Semantic Scholar, it's possible to implement both.
Also it might be possible for both services to work in parallel for exampe Libkey using GetFTR as part of the workflow to full text..... which itself might work with the traditional link resolver.
Comparison with Google's Campus Activated Subscriber Access (CASA)
People seldom mention CASA at webinar's on Seamless Access/GetFTR but there are indeed some similarities. Backed by Google from 2017, an impressive number of content owners including Heinonline, Gale, JSTOR, Ingenta Connect, Highwire hosted journals, Wiley, Project Muse, APA, Ebscohost ,Emerald and more have signed up to support it.
To be fair my understanding of CASA is it is more directly compared to Seamless Access than GetFTR.
It is essentially Google Scholar's attempt for your browser to remember your affiliation with a CASA cookie/token.
First, you need to access a link to a CASA supported publisher via Google Scholar while in-campus or via VPN/proxy. This will set a CASA token/cookie in your browser that remembers your affiliation.
When you are off-campus using the same browser, when you try to access similar links that go to CASA supported publishers via Google Scholar, you will still have access as if you were in-campus!
In addition, some publishers support "Universal CASA" so when users with a valid CASA token visit their pages without going through Google Scholar eg. Wiley, they may see a small grey badge labelled HTML or PDF on the right side of the page, that when clicked gives them full access even when off-campus.
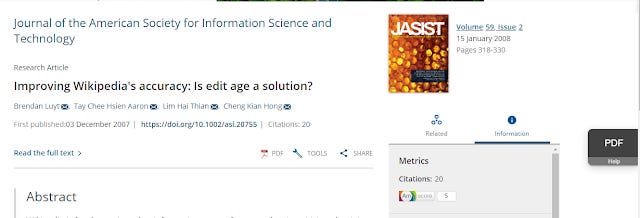
Universal CASA's grey badge labelled PDF on the right side of the page
Three other points to note about CASA
1. The CASA token doesn't last forever, you need to renew it every 30 days by coming on campus etc. (This may have been increased to 60 days due to COVID).
2. If you set up CASA while logged in to your google account, this can be shared with other devices that are logged into the same account. Yes this means working in mobile as well! Of course you don't need to use a Google Account if you don't want to.
3. It has been noted that use of "Universal CASA" will lead to information exchange with Google, you can turn this off in Google Scholar settings , under Account and uncheck "Signed-in off-campus access links".
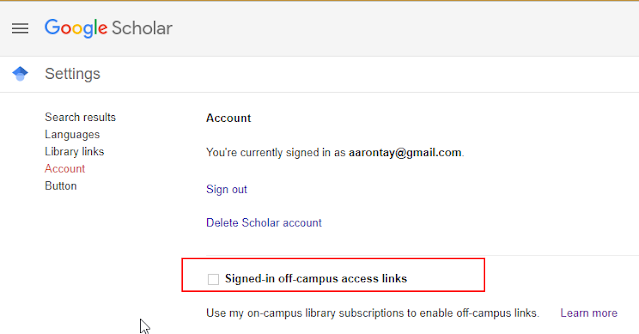
It is important to note CASA does not solve the appropriate copy problem, it simply enables you to authenticate automatically when you are off campus on CASA supported sites.
GetFTR concerns
When GetFTR was first announced by 5 major publishers in Dec 2019, librarians were concerned.
Since then some of the concerns were addressed. This includes
lack of representation from other stakeholders e.g. librarian - fixed with two librarians on advisory board
lack of IP authenication - included
Some concerns that aren't 100% confirmed to be addressed but are acknowledged mentioned includes
Will GetFTR support aggregator content? - A quick statement in the same month getGTR was announced stated that "“GetFTR is fully committed to supporting third-party aggregators", however as of time of writing this isn't there
Will GetFTR be allowed to be intergrated inot Link resolver? FAQ saying they are "exploring"
What librarians hopes to happen
At the end of the day, librarians major concern I suspect is around the struggle over who gets to control the user's experience of where they get the full-text.
After all, technology wise getFTR is a nifty bit of technology that you could keep in your back pocket to use when desired. The dream librarian scenario I suspect is for getFTR API to be allowed to be intergrated into existing link resolvers freely with the library deciding when (or even if) to use getFTR. This currently isn't possible I suspect.
Same applies for intergrating libkey APIs, or any other open or proprietary technique of course.
If Librarians were kings of the world they probably also would wish platforms would not unilaterally turn on UI elements for getFTR for their platforms (at least not without giving librarians an option to turn it off on their platforms) as this might lead to confusing duplication options to full text since a lot of them have traditional link resolver links already.
Or will those be eventually dropped? Who knows....
What probably will happen
There are actually three players here. The library/institution , the content owner (publisher) and the intergrator services (the platform the user is on).
At the end of the day, how wide spread getFTR becomes relies on getFTR's ability to convince platforms users are on to implement it.
The publishers particularly Elsevier has quite a bit of clout in terms of controlling popular scholarly spaces like SSRN, Digitial Commons, Scopus,Mendeley etc
But beyond that, I can see why even non affiliated platforms might want to support getFTR (more upfront effort) or libkey (easier to implement but less seamless in long run), while ignoring traditional link resolvers.
Main problem here is unlike the other two , there is no easy way to support link resolvers without such platforms setting themselves up to deal individually with the thousands of libraries.
There used to be a OCLC registry that had some institution link resolver settings (there might be commerical services??) and we see Lens.org try to use it, but in my experience the data in there is often incomplete or just out of date so this isn't a real solution.
On the other hand supporting getFTR and in particular libkey makes it easy to support all the signed up institutions in one fell swoop.... For startups and startup like organizations building discovery indexes, clearly getFTR and Libkey are far more attractive in providing bang for bulk.
Conclusion
As always, I wrote this piece more to puzzle things out for myself. Definitely something worth watching closely.