
Adding ezproxy to the url - 5 different methods

Many libraries in the world provide remote access to electronic resources via EZproxy .
As Andrew Perry explains here
"Essentially, Ezproxy uses some URL mangling, rewriting all hyperlinks, to pass traffic via the proxy (rather than using a conventional browser proxy setting). If the user is not logged in to the proxy (ie has no fresh & valid cookie), a login screen is given before being forwarded to the journal site."
In the case of NUS Libraries, a user visiting http://www.springerlink.com/content/j187567w723h43m4 will not be able to logged in via NUS Libraries and hence cannot access full text. However if he accesses the same link with the extra string in red appended http://www.springerlink.com.libproxy1.nus.edu.sg/content/j187567w723h43m4/ , he will be accessing the page via NUS Libraries and hence will have full text access.
While links from our library portal will typically have being specially treated to include the string in red, in today's world, a user is more than likely to stumble upon a journal vendor site from some outside source that did not rewrite the link (e.g. Blogs, forums, web search engine results). As a result, users will not be able to access the full-text article.
This is particularly so for users using Google or Google scholar. Ideally if everyone was linking using openurl (which google scholar does) and every library had a openurl resolver (not all have) things would be a lot easier (besides being a much superior method for being certain whether a library has access if the same article can be found in different sources/vendor platforms) but ..... In any case, this post assumes that linking via Openurl has not occured and one is dealing with a simple link to a specific vendor url.
In such cases, one can always manually add the string ".libproxy1.nus.edu.sg" to the url just after the domain name but clever librarians have come up with many ingenous ways to speed things up.
Some methods that can be used include
1. Bookmarklet
2. Libx
3. Greasemonkey
4. Zotero
5 Others
Use of bookmarklet
This is perhaps the most commonly used method. For this to work, one installs a bookmarklet into the browser. Clicking on the bookmarklet will automatically append the needed ezproxy portion of the url into whatever url the user is on, hence allowing him to access the resource.
Example : , (description)
Pros
Lightweight, works on most browsers.
ConsThe bookmarklet can only work retrospectively, after the user is already on the url. In most cases, as the user is initially not authenticated via EZproxy, the page shown will be the public page. Clicking on the bookmarklet will then convert the page into the subscribed version. Unfortunately, some vendors will detect that you are not authorized to access the page and redirect the page to a generic error page. Obviously, clicking on the bookmarklet now, would be futile. Vendors that do this include Web of Science and Scopus?.
Also certain vendor sites (Wiley-blackwell is one) will report errors with cookies, when using the bookmarklet. The only way around these problems would be to convert the url on the fly before even hitting the page (Which the Greasemonkey script, Libx and Zotero do).
Libx toolbar
As I covered in a past post , Libx toolbar is a specialized custom toolbar that libraries can offer to their users to help enhance access to their collections. Among the many functions of Libx is the ability to support the use of EZproxy. This is done via two methods
1. When the user is already on the page.
Similar to the bookmarklet method, when the user is on a page that he is unable to access, he can right click and select the option "Reload samplepage.com via Library proxy", and this will automatically reload the page he is on, with the ezproxy built in.

2. Prior to visiting the page.
Alternatively, before even hitting the page, he can right click on the link and select "go to samplepage.com via Library proxy". This can be helpful in avoiding the situation mentioned above with vendors redirecting to generic error pages.
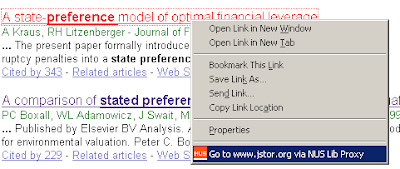
Example : NUS Libx toolbar demo
Pros
Because one can rewrite the url link , before even visting the url, this avoids the problem mentioned above with vendors redirecting to generic error pages. Also Libx supports both main browsers Firefox and Internet Explorer, although the bookmarklet supports more browsers.
Con
Libx adds a ton of features, and is probably overkill, if all you want is just some way to add support to exproxy. It is of course possible to create a small simple Firefox addon that does just these functions, for instance recently I discovered this from way back in 2005!
Using Greasemonkey script
Greasemonkey is a Firefox addon that allows users to dynamically rewrite webpages. It is possible to create a greasemonkey script that will on selected domains (which user can add) rewrite outgoing urls to work with ezproxy.
Example : Greasemonkey script demo (NUS libraries) , Script originally from Andrew Perry
ProsUnlike using bookmarklets or Libx, once configured properly, outgoing links will be automatically rewritten. Users save time, because they don't have to click on the bookmarklet or right click and select context menu etc for it to work everytime you go to Jstor via Google scholar. You can also add more domains into the list.

Cons
Greasemonkey is Firefox only, though Internet explorer users might try it with greasemonkey with IE.
Once a domain is added, all outgoing links will be converted. This can cause problems in some instances. For example, one can't simply add http://scholar.google.com* and hope to convert all Google scholar links, because the next page button doesn't work then!
Zotero
Zotero is a well known opensource citation manager that runs as a Firefox add-on. It has tons of powerful features. However the latest 1.5 beta adds automatic proxy support
When I first read about it, I thought it worked like Libx's. But I was wrong, it's far cleverer.
It works as follows, the first time you visit any url via ezproxy, Zotero will popup the following dialog box.

There isn't much detail on how it works. But here's my understanding, if you click "add proxy", Zotero will silently track any urls that use ezproxy, and automatically create pattern matching rules so that similar urls to the same domain will be converted as well.
For instance if you visit http://www.springerlink.com.libproxy1.nus.edu.sg/content/j187567w723h43m4/ for the first time, Zotero will notice that you are using a proxy to access Springerlink.com. If you click "Add proxy", two things will happen
1) In the future whenever you go to any link that has springerlink.com in it, libproxy1.nus.edu.sg will be automatically appended.
2) In addition, you are not just restricted to Springer. if you next visit say JSTOR at http://www.jstor.org.libproxy1.nus.edu.sg/action/doBasicSearch?Query=stated+preference&wc=on&dc=All+Disciplines , Zotero will silently learn (no prompt) about JSTOR links as well, so again in the future similar links to JSTOR urls will be converted.
The more vendor sites you visit via ezproxy, the more Zotero learns about which links (based on domain) should be converted. All this works transparently, the user does not need to do any work at all!
In short, what you have here is a simple autolearning system, that automatically learns what urls should be converted and appends the needed string!
Pros
Very user friendly. Domains that should be converted to use with ezproxy are automatically added without intervention by user. Once Zotero has learnt that certain url from a domain should be passed through Ezproxy, it will work automatically, saving time compared to using bookmarklets or Libx.
Do note that Zotero proactively converts recognized urls similarly to greasemonkey, so it works fine with links to Web of Science or Wiley unlike using bookmarklets. Unlike greasemonkey script it selectively converts only recognized urls, rather than all urls on the page, so it works great with say Google scholar and there is less chance of problems.
Cons
Unfortunately, Zotero is Firefox only add-on, so users using other browsers are out of luck.
Also though Zotero automatically recognises urls that require the ezproxy string to be added, it does not itself add the ezproxy string when you first visit a domain it doesn't recognize.
One can of course combine methods. Use any of the earlier methods to append the ezproxy string to any new domains not yet recognized by Zotero, and the next time when you visit links in those domains, Zotero will kick in and work automatically.
In particular, given that both Zotero and Libx are opensource tools that are popular with users of Firefox, many librarians have began to recommend the use of both . So use the later to append the ezproxy string to unrecognized domains for Zotero to learn.
Conclusion
These are only some methods that can be used to append the ezproxy string. No doubt there are some other methods (e.g. other Firefox add-ons such as redirector and quieturl). Update 21/4/09 : The 5th method is courtesy of a library user from my institution. He uses shortcut typing tools and recommends the following typinator, textexpander (os x); fastfox, phrase express (pc). These tools allow you to type a letter or two and expand it into a whole phrase, like a macro.
Overall I think Zotero's method is the smartest and easiest way to solve the problem of automatically adding the ezproxy string. It might even be worth installing it alone for this feature, if you constantly find yourself needing this feature.
Do note that if you append the ezproxy string and you still don't have access, it doesn't necessarily mean your library does not have access to that article. It is possible that you can still access the same article via another vendor or site.