
AI & Retrieval augmented generation search - the content problem -reactions from librarians, authors and publishers & thoughts on tradeoffs

New! Listen to a 10min autogenerated podcast discussing this blogpost from Google LLM Notebook
Update Primo Research Assistant is out - See my initial preliminary view
IP and ethical issues surrounding the use of content in Large Language Models (LLMs) have sparked significant debate, but I’ve mostly stayed out of it as this isn’t my area of expertise, and while there’s much to discuss and many legal opinions to consider, ultimately, the courts will decide what’s legal. However, for those interested in exploring this topic further, I recommend Peter Schoppert’s AI & Copyright substack. As a publisher, his perspective naturally leans conservatively toward the rights of content owners, yet remains fairly balanced.
In this post, I want to highlight the growing awareness within the library and adjunct communities—librarians, researchers, and publishers—about how the content we create is being used and dare I say exploited by LLMs. This issue naturally causes a lot of anguish as this has potential risks to our professional livelihoods. Additionally, I explore the complex decisions academic content owners face when choosing whether to opt out of having their work included in Retrieval-Augmented Generation (RAG) style AI-generated answers.
All in all, the saying content is king has never being more true due to the rise of AI, and as librarians we have very interesting decisions to make...
Librarians are waking up to the fact that content from LibGuides is being used in LLMs
Springshare here! Just a note that unfortunately there's nothing we can do as these are publicly available webpages for scraping. We are not providing or selling LibGuide information to any company for the purpose of AI training (or for any other purpose, for that matter).
— springshare (@springshare) July 10, 2024
It is no doubt that a lot of what LLMs "knows" (even without search) comes from the pretraining of public libguides, whether it is APA citation, what databases are appropriate etc.
Springshare's first response was that it couldn't do much, that it wasn't directly selling data, but AI companies were publicly scraping.
Daniels Griffin a researcher at UC Berkeley School of Information observed that for the big players like OpenAI, most of their crawling can be controlled with robot.txt
Within a few days of that tweet, Springshare announced they were indeed using the robot,txt file to block crawlers in particular the crawler from OpenAI.
Our development team is currently making changes to robots.txt to block these AI agents, and we will also be blocking the ChatGPT user agent. From our previous experience, they may spoof or not respect robots.txt, but rest assured we will do everything that we can from our end.
— springshare (@springshare) July 11, 2024
Some have commented this might be a case of shutting the barn door when the horse has bolted though (since I doubt they will remove the data they have already pretrained on).
Interestingly Springshare isn't the only domain blocking there is evidence many other domains are doing the same. Related : Reddit is blocking all major search,crawler bots except for Google which made a deal.
My thoughts
I fully empathize with how and why librarians are reacting. It is the same scary and sinking feeling artists and other professions have experienced in the past few months as they saw LLMs benefiting from their work and potentially replacing or at least reducing their value. I myself had a tiny taste of that when in early 2023, I found Bing Chat gave a good or interesting answer when before it could not (I know because I was testing it to see if anyone had written on the subject before writing my blog post!), simply because it found my blog post and quoted from there.
Still, my first thought to blocking OpenAI crawlers with robot.txt was do we really want to do that?
The irony is many libraries racing to create chatbots based on LLMs, are implictly relying on the fact that these chatbots are trained (or can retrieve from) content on the web.
Moreoever even if you don't want to do that (or only want the information to be used by your chatbot and nobody else), my other thought is don't we want our content to be found?
It is also important to note that the content can be used by "AI" in two ways. Firstly, it can be used to pretrain the LLM. Secondly it can be used in a Retrieval augmented generation (RAG) system.
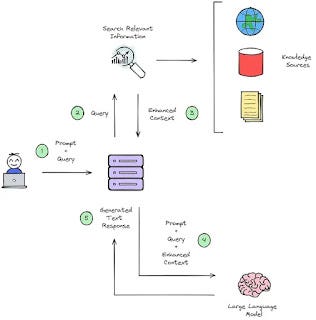
Model of Retrieval Augmented Generation (RAG)
In a RAG system (e.g. Bing Chat, Microsoft Copilot, Perplexity.ai etc), it essentially works first has a search engine, and your query is used to retrieve retrieval documents or text chunks from documents as a first step. In the next step, the top ranked results are just fed to an LLM which is prompted to try to answer the question with what was found.
Another way of thinking of RAG is that when using RAG the LLM is in a open book exam and is able to consult anything on the web before attempting answers. In this analogy, without RAG, pretraining of data would then be the equalvant of the LLM "reading" and "learning" or "memorising"? content before taking the exam and trying to answer on their own.
It is possible to block one use (data is crawled and used for pretraining) without blocking use in RAG.
Which should we block (if we have the choice)?
My first gut feel is I am uncomfortable with using LLMs to pretrain on our content but I am okay with it using via RAG. I am unable currently to articulate why to my satisfaction.
That said, using it via RAG is essentially the same as it being indexed in a search index, the information is transicent and will change as our webpage changes and the index updates.
I anticipate that Google (via AI overviews) and Bing (Bing chat/Copilot) and practically every search engine will be using RAG to generate answers. If you choose to block use via RAG, it means that when users type "Opening hours of XYZ library", they won't get direct results. Is that what we want?
Aren't we supposed to save the time of the user? Lisa also points out a interesting contradiction
Interesting to see pro-SciHub librarians trying to block AI crawlers from their websites and institutional repositories. Maybe not as into intellectual communism after all?
— Lisa Janicke Hinchliffe (@lisalibrarian) July 31, 2024
The cynical answer is it is one thing to be all pro open and all "information wants to be free" when the content isn't yours and a totally different matter when it is your own painstakingly created content and worse potentially affects your livelihood!
All in all though I wonder if this backlash over AIs might start us down the road towards the end of the search engines' free ride of being free to index public sites without any consequences.
The fear of big tech companies scraping data for pretraining and/for incorporation into RAG style results might mean the web will become very hostile to search engines even those crawling for old school style search
Can you say you want your site to be indexed for normal search results but not RAG style results? I suspect it might be possible at the search engine end, but they would always be one switch away from doing so.
Researchers/Authors are waking up to the fact that content from LibGuides is being used in LLMs
While librarians were waking up to the uneasy feeling of their content being used by LLMs, authors are having the same moment when news broke that Taylor & Francis are selling access to research out to Microsoft AI.
Edit: Others like Wiley, Cambridge University Press might be doing the same.
As usual details on this are scarce, but my guess this is feeding the pretraining of LLMs and not RAG? Of course, this feels even worse than the case of Libguides, because the company is presumably profitting off this deal and authors don't get a cut...
Again this has shades of researchers setting papers to CC-BY and then getting upset it is used in ways they didn't expect e.g include CC-BY papers in collections for sales, though in this case simply reading the terms of the copyright assignment/transfer form should tell you all you need to know (you basically signed over all rights to the publisher).
BTW Even if your work is CC-BY, it may not be sufficient for LLMs to use it for pretraining due to lack of attribution
Publishers are opting out of Retrieval augmented System
Declaration of Interest: I am a member of the Clarivate Academia AI Advisory Council. However, this blog post is not based on any information obtained through my role on the committee, and I do not have any special access to Primo's or Clarivate's AI (not even as a beta tester) at the time of writing.
Besides offering data to be used for pretraining LLMs, publishers also face an interesting decision when it comes to discovery. Should they allow their content to be used to generate answers in RAG systems?
Exlibris recently showcased their upcoming 4Q 2024 - Primo Research Assistant again. This is a fairly standard RAG type search restricted to the content in CDI (Central Discovery Index), the academic content indexed and available for discovery by Exlibris/Clarivate.
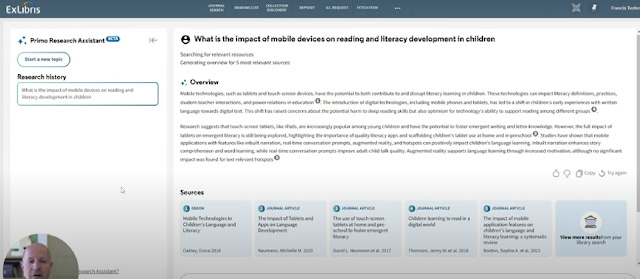
Primo Research Assistant works like most standard RAG systems
You get the top 5 results of a search summarised into an answer with citations. Nothing we have not seen in many other products from the earliest leaders to peer products.
Still. there are a couple of interesting things I noticed or am curious about. For example, is the RAG search only over abstract like most academic RAG search, or is it over the 65K characters from the material's full text which is indexed in CDI?
I also note, the generated RAG answer is not the run by default for every search but you have to click to go to another site and the interesting decision of "expand CDI search by default" means you will get answers with citations from content your institution might have no access to, but the point I want to discuss here is that some content e.g from JSTOR and APA was excluded.

I find this exclusion interesting because some in the publishing industry actually like the model of RAG possibly because it makes usage in LLMs easily measurable!
Note my followup post - shows more exclusions including Elsevier
My thoughts
I am going to assume that Exlibris went to ask permission to all the content owners contributing to CDI and some came back to object the use of their content in RAG answers leading to their exclusion, though some of the exclusions might be the decision of Exlibris themselves eg many subscription databases are just not suitable (also I suspect many databases are aggregators so the aggregator owners have no rights to decide?).
But for the purposes of this piece, I am going to take on the role of a publisher of content. If I were the publisher of content and I had the right to do whatever I wanted to do with the content because I had the IP (this might not hold true for JSTOR) what are the pros and cons to be excluded from RAG style answers
In Primo Research assistant implementation, it only shows the generated answer and the five cited papers used in the answer. In other implementations like Elicit.com, the generated answer is followed by not just the papers which were cited but also other papers like a normal search result.
My first thought is publishers wanting to opt out are shooting themselves in the foot. They are making the same mistake as publishers first refusing to be indexed in Google Scholar and later the central discovery indexes by Summon, Primo, EDS in the early years of 2010s. In the end, pretty much everyone gave in, because if you were not discoverable in these indexes and your competitors were, you would just lose out and would be less discoverable and hence less used. This happened because eventually most academic libraries put these discovery services front and center as the single default search box driving all the eyeballs there.
This was a lesson that every publisher learned in the 2010s particularly when librarians started showing large scale studies showing insanely big increases in COUNTER stats comparing content indexed in discovery indexes and plunging usage in content that were not. Being indexed or not in Google Scholar is even a bigger deal as everyone knows from traffic analysis.
That said, the parallels are far from perfect here.
Firstly, Exlibris is being cautious here, the CDI Research Assistant is not the default. The generated answer is not produced for every search, you need to make a special effort to go to another site. So the impact on not being discovered in the Research Assistant is far less.
I actually support this careful approach, Primo and Summon together are two of the 4 default search systems on almost all academic libraries. Sticking it as the default is going to result in millions of searches and unprepared librarians, researchers getting upset by the change. These systems aren't Google level of use (see their problems with AI generated overviews) but used by enough people for it to be a good idea to go slow. My past experience in such systems is that known item searches make up a large % of queries, to stick a RAG generated answer all the time might be pointless (thought there are ways to handle that). Not to mention issues of hallucinations where the generated answer might not reflect what the cited items say. We have no clue how serious an issue this is, since vendors of RAG systems do not release such stats. I assume they have it for internal testing but the fact they are not sharing it is interesting.....
This is similar to how are the major established products are doing it, Scopus AI, Statista etc, That said, if this feature becomes very popular with users (and I can see it happening), these systems might switch to the default and work like how Elicit.com, SciSpace etc and ALWAYS show a generated answer with a list of papers below (including papers not cited in the generated answer).
There are also cost reasons not to generate a RAG style answer with every search, but LLM operating costs and search techniques are always getting cheaper, even Elicit which used to charge credits for search, recently made search 100% unlimited free!
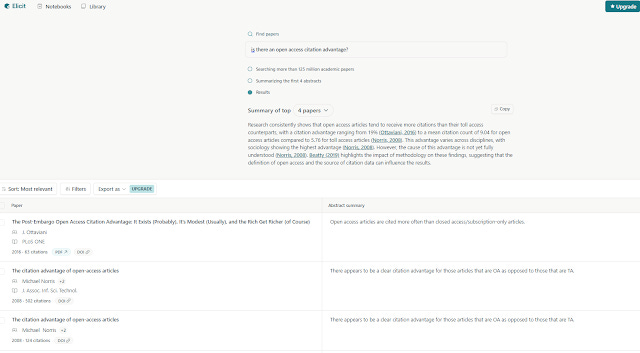
Elicit always shows generated answers and list of results below (like a normal search engine)
In such a scenario, the decision to be excluded from the RAG generated answer, I argue is possibly more costly to discoverability. The RAG generated answer holds a very prominent place and to be excluded from there is not a good idea. I also assume such exclusion is only for the RAG answers but the opting out publisher content would be in it's normal spot in the search results page but that's clearly lower down.
Still even in such a case, I can imagine, someone still preferring to opt-out from appearing in the RAG answers with a interesting argument.
I suppose one could argue as such.
If my content is cited in a RAG generated answer, many users would not click into my content and instead rely on the AI generated summary of my content and just cite. And librarians will look at my reduced usage statistics and more likely to cancel me!
This is analogous to why some web owners are so angry with Google producing direct answers using older methods like Google Knowledge Graph, google featured snippets which they consider stealing of content because users no longer click in to their sites!
I guess how strong this argument is depends on if you think a lot of users are lazy.
In fact for this argument to work they need to be a special kind of lazy! Lazy enough to not look at the paper if there is an AI answer that mentions the paper, but hardworking enough such that they would go to the full-text if it was not in the answer!
My guess?
Assume there is a generated AI answer and you opt out so your content is not cited in the answer.
If someone is lazy enough to just take from the generated AI answer? Most of them would just take whatever is there. If you opted out and your content doesnt appear in the answer but appears lower down in the normal search results? They would not cite you anyway and would cite whoever was in the generated answer.
I think more likely, most people would see the generated answer citing the paper stating it says something which might make them more curious to go in and take a look... Does this make sense?
Before we go on, I was impressed to realise COUNTER already has thought about the problem of AI impact on search and has FAQs on it!
Generative Ai related FAQ on COUNTER usage
My COUNTER knowledge is rusty so I won't interpret for you, but there are answers for handling RAG I think. (eg RAG is definitely a search). I don't think it counts as a request. Not sure about investigations.
As a librarian, I would prefer the choice of which content to show in RAG answers would be in our hands, but I not holding my breath. It also depends on how accurate the generated answers are etc.
It's also interesting to speculate what happens when or if the sleeping giant Google Scholar decides to join in the fun! Again, my instinct is to think everyone would be idiots not to allow Google Scholar to do RAG answers over their content, but on second thought it might not be so simple (same dilemma and unknowns as Primo Research assistant).
Conclusion
The discovery space is very exciting now, akin the the 2010s with the dawn of the library discovery services. Content is King is a well known saying but it has never been truer with the rise of AI that can use data in more ways than before and this leads to much more interesting decisions......