

As an academic librarian, I’m often asked: “Which AI search tool should I use?” With a flood of new tools powered by large language models (LLMs) entering the academic search space, answering that question is increasingly complex. Both startups and established vendors are rushing to offer “Deep Search” or “Deep Research” solutions, leading to a surge in requests to test these products. As a working academic librarian even one with a focus on AI search, I have limited time to invest in these new tools, and only ones that stand out in performance, novelty or price are likely to catch my attention.
Honestly, many are unstable or perform poorly, making them unready for widespread use. My current benchmark for performance is Undermind.ai. If a "Deep Search" product performs significantly worse than Undermind in retrieving relevant papers for my sample queries, I quickly lose interest. I know my sample tests aren’t foolproof, but I have to draw the line somewhere!
In today’s blog post, I’ll highlight two academic deep search/research tools that caught my attention: Ai2 Paper Finder and Futurehouse’s PaperQA2-based search. These two tools are currently free, and perform at roughly the same level as my current favourite Deep Search Academic tool - Undermind.ai.
More importantly, while Undermind offers a polished, user-friendly interface, its process feels like a black box, revealing little about how it retrieves results.
In contrast, Ai2 Paper Finder displays every step—query analysis, search workflows, and relevance judgments—making it easier for librarians to trust and explain results to researchers.
Similarly, Futurehouse’s Reasoning tab provides detailed insights into the papers found and the evidence considered, empowering users to understand the search process.
For academic librarians, transparent tools foster trust and enhance our ability to guide researchers in navigating and evaluating AI-driven search results effectively.
[ADV] Want to learn about the fundamentals of AI in academic search from me?
I rarely do this, but this is likely of interest to my readers.
I am offering a "Master Class" on May 29, 2025, from 4 PM to 5:30 PM (SGT), tailored for librarians navigating the new era of academic AI search. Prioritizing general principles and understanding over specific tools, this session will equip you with the foundational knowledge to excel.

As I write this post, there are now less than 10 seats left out of the 50 for my "Master Class." Can’t attend live? You get recordings! Register here.
1. Ai2 Paper Finder

Regular readers of this blog are familiar with Ai2, or the Allen Institute for AI, and in particular the work they do on their Semantic Scholar search engine. Arguably more significant is that they provide much of the dataset behind Semantic Scholar openly for use, and many—if not most—of the startups in the academic search space, such as Elicit.com and Undermind.ai, use this dataset as a base for their search engines.
More recently Ai2 have also been developing their own fully open LLMs such as OLMo 2 and now
Ai2 themselves have gotten into the act applying LLMs to search, and in March 2025, they launched Ai2 Scholar QA, their version of Deep Research that generates long-form reports. See my coverage of academic Deep Research tools here.
But Deep Research tools are extremely hard to evaluate, requiring not only careful reading of all citation statements to ensure they are faithful to the source but also subjective assessments of the coherence of the writing. As such, my current interest lies in evaluating results from Deep Search alone.

This generally involves examining the list of results generated by the Deep Search engine and checking whether most of the known gold-standard results are included.
I will discuss this further in a future post, but using articles from published systematic reviews as a gold standard often makes the "test" too easy for such Deep Search systems. They will inevitably find the systematic review and, through iterative citation searching, identify most of your gold-standard papers.
Indeed, Ai2 has launched a seperate deep search called Ai2 Paper Finder which recognises that
literature search is a multi-step process that involves learning and iterating as you go.
It creates an agent that simulates this process by
break[ing] down your query into relevant components, searches for papers, follows citations, evaluates for relevance, runs follow-up queries based on the results, and then presents not only the papers, but also short summaries of why the paper is relevant to your specific query.
If this sounds familiar, it’s exactly what Undermind does, and Ai2 even name-checks Undermind as
working in the same domain with a similar goal of finding good and exhaustive sets of papers on a topic.
Ai2 Paper Finder: Overview
So why do I spotlight Ai2 Paper Finder?
First, I believe it is intended to be free (as in free beer) for the foreseeable future. Second, they aim to be as "open as possible." Although they do not currently open-source their code, they
plan to release more of our(their) source code in the future.
Even without releasing their code, Ai2 Paper Finder is far more transparent about its processes.
Unlike Undermind.ai, which hides its process behind a generic placeholder screen, Ai2 Paper Finder acts like an open book. It displays every step—think of it as a librarian showing you exactly how they tracked down your sources—making it easier to trust and understand the results.

Query Analysis and Intent
For more context, the introductory blog post to the tool provides a fairly detailed explanation of the inner workings of Ai2 Paper Finder, and I’ll quote liberally from it in italics below.
First, the query analyzer goes to work and does two main things. It determines the query intent, which essentially has two modes:
Searching for a specific known paper
Searching for a set of papers on a topic


My observation : In my early testing of Ai2 Paper Finder, it erroneously assumed I was searching for a specific known paper too often, which caused failures and occasional crashes. After providing feedback to the Ai2 Paper Finder team, this issue seems mostly resolved.
I find it interesting that unlike most Deep Search or Deep Research tools like Undermind.ai, Gemini Deep Research, OpenAI Deep Research, it doesn't ask for clarification and goes straight off to search. This could help the system decide which mode to go into.
Second, the query analyzer checks if the query string includes metadata criteria like author, year, or journal. It can also recognize terms like "central," "popular," or "recent."
For example as seen below, it recognizes "Accounting Review" as a journal and the years of publication specified.

My observation : It doesn’t yet work for metadata like institutional affiliation.
Search Workflows and Sub-Flows
The analyzed query is then passed to the "query planner," which launches several predefined "workflows," including:
Specific paper search
Semantic search with potential metadata constraints
Pure-metadata queries
Queries involving an author name
Each of these sub-flows (that can be thought of as "sub-agents") return a set of paper-ids, and in sub-flows that include a semantic criteria, each paper-id is also associated with a list of evidence, and a ranking score reflecting its judged adherence to the semantic criteria.
Like any good system today, reranking is performed, and result sets are:
re-ranked according to a formula that combines the semantic relevance with metadata criteria, such as prioritizing more recent and more highly cited papers. This is influenced by query modifiers such as "recent", "early", "central" or "classic" that increase the emphasis on the metadata criteria over the semantic one.
The specific paper subflow
The specific paper sub-flow is designed to help you find the one specific paper you’re thinking of but can’t recall the title. It employs three strategies in parallel:
Searches the Semantic Scholar title-search API
Search for sentences containing the core search terms, focusing on those that also contain a citation and looking for what the majority of them cite (for example, in the query “the alphageometry paper”, it will search for “alphageometry” and see what is cited in its vicinity)
Asks the LLM directly for a paper and verifies its existence via the Semantic Scholar title-search API
Observation : As researchers, you’ve likely experienced wanting to cite a paper you vaguely remember but can’t find. This sub-flow seems designed to address this use case.
Initially, I even mistakenly thought the name Ai2 "Paper Finder" implied it was only for this purpose!
While the idea is good, I find it often fails for me. I suspect this is because what a paper actually says may differ from what it’s commonly cited for, which may differ from what you want to cite it for. For example, a paper might be cited for a certain conclusion, but you found a nuance in its research method interesting and want to cite it for that. Given the algorithm, you can see why Ai2 Paper Finder struggles here.
Semantic search sub-flow
The explanation in the blog post isn’t entirely clear when I read it, but here’s OpenAI's o3's interpretation based on the text.

It sound plausible to me and should be close enough I guess...
Iterative searching
The search process then enters another round, based on the most relevant papers so far. In this round, an LLM reformulates more queries based on the original query and the text of the found relevant papers, and sends them to the above-mentioned indices. Additionally, it does both forward and backward citation tracking based on the most relevant papers, which is again followed by LLM-based relevance judgment. The process continues for several rounds and stops when it either finds enough papers or scans too many candidates.
Observation: Nothing surprising here, but the fact that it performs both forward and backward citation tracking on the most relevant papers explains why using published systematic review papers as a gold standard is not a good test. The system will quickly find the systematic review, identify it as highly relevant, and citation searching will uncover the rest. (I’ve seen this in practice.)
How relevance is judged
Developing a reliable method for relevance judgment was challenging. While the system is still evolving, we found a "mini breakthrough" that significantly improved results and usability: ask an LLM to break the user's semantic criteria into multiple semantic sub-criteria, to be verified separately. For example, in the above query about dialog datasets, these sub-criteria would be “introducing an unscripted dialog dataset”, “English language”, “annotated speaker properties” and “relation between dialog and annotation”. Each of these titles also includes a brief elaboration. Then, the relevance-judging LLM is asked to first provide adherence to each of the individual sub-criteria, which are only then combined into a final score and final judgement.
Observation : This seems to involve asking an LLM to assess each candidate paper based on sub-criteria, somewhat similar to how LLMs are used for screening in systematic reviews, where they score title/abstracts based on PICO (Population, Intervention, Comparison, Outcome).

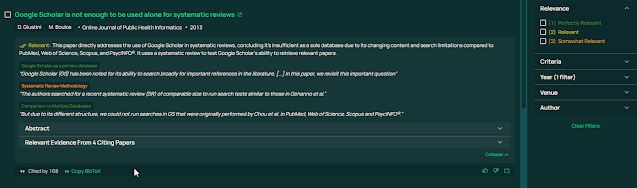
In the above example, the query is "Paper showing Google Scholar can be used for systematic review instead of using multiple databases" and three sub criteria used by the LLM to judge relevancy are
Google Scholar as a primary database - judged "perfectly relevant"
Systematic Review Methodology -judged "somewhat relevant"
Comparison to multiple databases - judged "perfectly relevant"
with overall judgement of "relevant"
This is somewhat similar to how LLMs are used for screening in systematic reviews and they are instructed to score title abstracts based on PICO.
Impact of citing papers
In the relevance judgment phase, an LLM goes over all the candidate papers and judges how well they match the semantic criteria in the user's query. For each candidate paper, we format it as markdown text that includes the paper's title, abstract, and the returned snippets from the search, where the snippets are ordered by the paper order, and include the section titles of the sections in which they appeared. If the returned snippets include snippets that cite this paper, these snippets are added as well.


Observation : There’s a “Relevant evidence from 4 citing papers” section, presumably affecting relevance?
Fast mode vs work harder mode
As you may imagine, the full process is effective but rather lengthy... For this reason, we also introduce a fast mode that does less work: it retrieves fewer papers in the initial stage based on the user's semantic criteria without additional reformulations and without the follow-up iterative procedure.
This fast mode is the mode that runs by default, so you don't wait two or three minutes for each response. Based on the results, you can then ask Paper Finder to "work harder" in which case it will invoke the more exhaustive mode described above. You can also invoke the exhaustive mode directly by asking Paper Finder for "an extensive set of paper about X" or something similar in the original query. This way you can get good and (relatively) fast answers to 80% of your queries, while getting higher quality and exhaustiveness for the 20% of queries that require the exhaustive mode.
Observation : Fast mode works well, but I've found asking it to “work harder” often doesn’t significantly improve results which is by design I suspect.
Limitations
As for the semantic queries, while we get top results on academic benchmarks such as LitSearch and Pasa, there is still a lot to do. In particular, we’ve already identified several areas which are particularly challenging: queries when the user does not know the right vocabulary, overly long and rambling queries where the user enters a very long, paragraph-length description of their intents, some queries that involve a combination of multiple semantic criteria where each of them appears in different part of the paper, and queries that search for things that are inherently hard to search for using an index (e.g. numeric ranges such as in "training techniques for models with more than 7b parameters", or negated semantic criteria as in "fairness papers that do not discuss race or gender")... Finally, the system is now strong but quite rigid, and while it is influenced by LLM decisions, the flows are predominantly shaped by the researchers and engineers in our team. This is powerful and effective but also limiting (as an almost trivial example, a query like "the bert paper and the roberta paper" is currently not handled well, and could be trivially supported by a more dynamic, LLM-controlled flow). Going forward, we'd like to see more and more decisions delegated to the LLM, supporting more dynamic and ad-hoc flows.
Observation : In The Differences between Deep Research, Deep Research, and Deep Research , the author classifies deep research tools in two dimensions.
a) Depth of search - Shallow vs Deep
b) Hand crafted vs Trained

Ai2 Paper Finder is clearly on the handcrafted side, with specifically defined sub-flows (rather than the LLM being trained via reinforcement learning), making it vulnerable to performing poorly on unexpected scenarios, as noted above (e.g., long, rambling queries).
Another area we recently started to explore is interactivity and multi-turn interactions. Real world search is not a one-shot process: once there are results, the searcher may like to refine the query. This refinement may refer to the returned results ("these are great but now focus on memory efficiency" or "the third and fourth are great, can you find more like these"), and we'd like the follow-up queries to take this into account.
Observation : Agreed
Overall assessment : I spent considerable time testing Ai2 Paper Finder against Undermind, and its performance is very close, though it can be less robust, with occasional unexpected failures (hopefully now corrected). I suspect Ai2 Paper Finder is still more sensitive to unexpected query inputs than Undermind.
UI-wise, Undermind.ai offers a polished experience, while Ai2 Paper Finder has room for improvement, though I’m pleased they adopted my suggestion to add more filters for criteria and relevance.
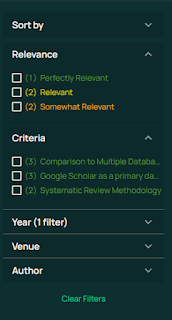
Criteria filters are particularly helpful for focusing on the most important aspects of your query that must match.
2. Futurehouse Platform search
Besides the commercial Undermind.ai, which dates back to early 2024, Futurehouse’s PaperQA2 was another early “agentic search” in the academic search space. An open-source project, you can read details in the preprint or this blog post.
More recently, they launched a platform offering “AI agents for scientific discovery.”

They offer three types of searches (leaving aside “Phoenix,” which is designed for chemistry-only tasks):
1. Crow: Based on the original PaperQA2, good for specific questions.
2. Owl: Used for precedent search, ideal for checking if something has been done before. This reminds me of Ai2 Paper Finder’s “specific paper” mode.
3. Falcon: Used for Deep Search, producing long reports with many sources, likely comparable to Ai2 Paper Finder and Undermind in standard topic searches.
The data source they are using is "38 million papers on PubMed, 500,000+ clinical trials" and Open Access papers.
Note that while, PaperQA2 is open source, these new agents are not. You can access them via an API or the free web interface.
So why do I spotlight Futurehouse?
It’s currently free, and the results are good, though I haven’t tested it as extensively as Ai2 Paper Finder.
How does it work?
My experience with “Owl” for finding specific papers I vaguely recall has been underwhelming, for the same reasons as Ai2 Paper Finder. So, I’ll focus on Falcon (Deep Search) and Crow (Concise Search).
Falcon Deep Search vs Crow Concise Search
Interestingly, when I tested the same query, Crow (Concise Search) took longer than Falcon (Deep Search), contrary to my expectations!

For the same query, Falcon (Deep Search) took 5 minutes, while Crow (Concise Search) took over double the time—12 minutes!
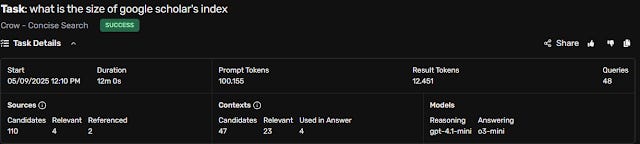
Despite spending less time, Falcon ran more queries (71 vs. 48). In terms of sources considered, Falcon evaluated 45, found 20 relevant, and referenced 14, while Crow considered 110, found 4 relevant, and referenced only 2!
I think Falcon isn’t necessarily “deeper” but produces a broader literature review than Crow. For example, Falcon’s output spanned 22,144 characters, while Crow’s output was only 3,247 characters, reflected in the “result tokens” used. Crow’s answer dives straight into studies estimating Google Scholar’s index size, while Falcon provides a longer, scene-setting report.
In this case, Falcon also performed better, finding 20 relevant papers vs. Crow’s 4. To be fair, Falcon’s broader literature review makes it easier to find relevant papers. Still, looking at the actual output Falcon clearly outperformed Crow in surfacing studies estimating Google Scholar’s index size, so I’ll focus on Falcon Deep Search for the rest of this post.
Falcon Deep Search interface

Falcon’s interface is the same as Crow’s and Owl’s.
Besides task details (which reveal the LLM models used), there are three tabs: “Results,” “Reasoning,” and “References.”
References Tab
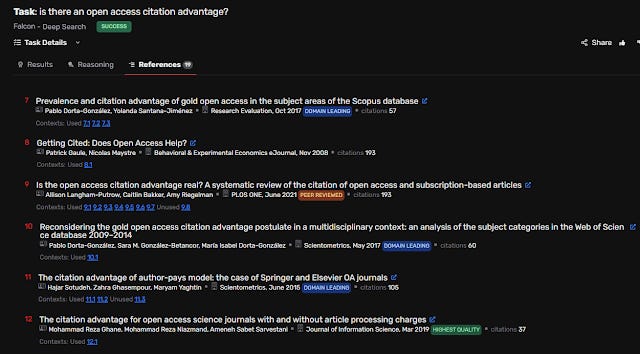
The References tab lists the references used in the generated answers. Two things stood out: some references are tagged with labels like “Domain leading,” “Highest quality,” or “Peer reviewed.”
Under each paper, contexts (both used and unused) are listed (e.g., 1.1, 1.2, 1.3).

Mousing over them shows what appears to be a “reasoning trace”—typically a summary like “The excerpt from Author (year) discusses…” Each context (1.1, 1.2, etc.) may start similarly but generally differs.
Result Tab

Reasoning tab
The Reasoning tab is the most interesting, offering insight into the system’s steps, including papers found and “evidence found.”


Conclusion
As the landscape of AI-powered academic search tools continues to evolve, the proliferation of "Deep Search" and "Deep Research" products presents both opportunities and challenges for academic librarians and researchers. To me, Ai2 Paper Finder and Futurehouse’s PaperQA2-based search stand out in a crowded market by offering robust performance, transparency, and free access, with performance that rivals my favourite Undermind.ai.
In my view, while Undermind retains an edge in user experience and polish, the openness of Ai2 Paper Finder’s processes and Futurehouse’s detailed reasoning traces provide valuable insights into how these tools operate, fostering trust and enabling users to better understand their search workflows.
These tools demonstrate that effective "deep search" capabilities are becoming more accessible, and the push for transparency could become a key differentiator in this rapidly evolving market. Although both have areas for refinement, from Ai2 Paper Finder’s occasional sensitivity to query inputs and UI improvements, to the need for more extensive testing of Futurehouse's offerings, their current performance and open approach are commendable. Their emergence signals a healthy dynamism in the field, offering powerful, free alternatives that challenge established players and empower users with greater insight into the AI-driven discovery process. As these and other tools continue to mature, the quest for the ideal AI academic search companion – one that is effective, transparent, and user-friendly – remains an exciting one to watch.