
All about citation chasing and tools that does citation chasing like Citation Gecko, Connected papers, Research Rabbit, LitMaps and more

New! Listen to a 10min autogenerated podcast discussing this blogpost from Google LLM Notebook
I have been writing about what I call citation based literature mapping tools for over 5 years now, starting from Citation Gecko in 2018. This trend really intensified in 2020, with the overall victory of the open citation movement making citation linking data effectively "free", and tools like Connected papers, Researchrabbit, LitMaps and more really started to get some traction.
In all this time, I would show these tools to doctoral level students in my institution and it was fascinating to see from the earliest days where most of these tools were totally unknown to them, to today where typically a few students would already be aware or use tools like Researchrabbit and Connected Papers, showing that these tools are very slowly making inroads. This isn't a surprise as it is commonly believed typically new research tools are adopted first by the emerging researchers as they are in the progress of figuring out their workflow.
Yet understanding and teaching such tools in depth can be complicated, as how such tools work are built on the concept of citation chasing and this is often not made clear in the interface.
In this long blog post, I will share some of my thoughts on understanding and teaching these tools, and also highlight two important recent work - Guidance on terminology, application, and reporting of citation searching: the TARCiS statement and Beyond Google Scholar, Scopus, and Web of Science: An evaluation of the backward and forward citation coverage of 59 databases' citation indices, that may impact understanding and use of these tools.
1. Focus on the why
I tend to overdo talking theory and concept of such tools but in one recent session where I focused chiefly on trying the tool out first, midway through the session, I had a Post Graduate student ask me a very basic question, when do we use these tools over something like Google Scholar?
The simplest answer to give is , you use this tools, either as a primary or complementary method if yous suspect or find keyword searching is going to be tricky!
Here's a nice formal answer from a recent paper (which we will discuss later) with excellent references.
As documents identified through citation searches use diverse language, citation searches produce unique results that would not be identified via alternative methods. Citation searches are particularly likely to yield unique results in the case of hard-to-identify documents or in fields with non-standardized language.4, 5 In some cases, they may even be better suited than keyword searches for identifying the bulk of relevant literature.6-8 Irrespective of whether authors use citation searches as a principal or supplementary search method, such searches have been found to improve search comprehensiveness9 and increase retrieval potential10 and may be regarded as keyword searches' complementary “safety net.”4(p.8)
Essentially, keyword searching is hard sometimes and citation searching might help either as principal or Supplementary methods to improve recall. They further explain reasons why keyword searching alone might be tricky.
Citation searching is particularly relevant in fields that use diverse, non-standardized language that might be difficult to capture with language-based keyword searching alone. In other words, citation searching is important when “core concepts are difficult to capture using keywords, e.g., where core concepts are described inconsistently due to systemic reporting deficiencies, or due to historical development of terminology.”6, 13(p.170),14-18 Thus, sciences involving abstract conceptualizations of phenomena, such as psychology, management and economics, social sciences, and humanities, particularly benefit from discovering relevant articles beyond familiar terminology. It is mainly these fields in which knowledge synthesis has also undergone a considerable uplift19 and thus may benefit from citation searching.
2. Are these tools "AI tools"? How do they work?
Many librarians and users are classifying tools like Connected papers, Research Rabbit, LitMaps as "AI tools" and lumping them with tools like Elicit.com, SciSpace, Scite assistant, Consensus.ai etc.
While "AI" is a very loose term, I would prefer to distinguish these set of tools that use citation chasing type techniquesfrom the other set of tools that leverage large language models directly, typically to generate answers using RAG (Retrieval augmented generation) and/or use embeddings for semantic searching.
Tools like Connected papers, Research Rabbit, LitMaps generally don't use language models but instead use bibliometric or network based methods to suggest papers from the beginning seed (or known relevant) papers.
That said some tools might be using the raw citation statement (text from citing paper) or citation context i.e. processed citation type or sentiment by a NLP tool (eg from Semantic Scholar) to help with citation chasing, recomendations etc This is a hybrid type of method that combines citation chasing with some amoubt of semantic parsing.
While there are a myraid number of ways to do this, they are often variants of techniques that the recent - Guidance on terminology, application, and reporting of citation searching: the TARCiS statement classifies under "direct citation searching" and "indirect citation searching"
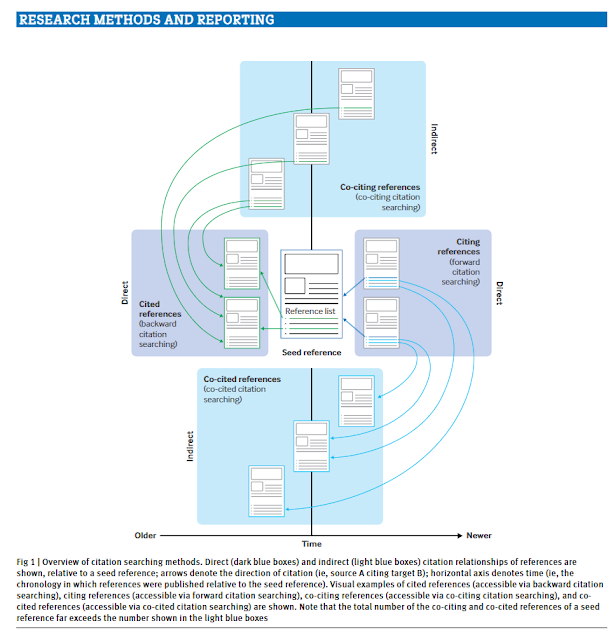
Direct citation searching
"Direct citation searching" including both "forward citation searching" and "backward citation searching" which is a simple concept that most are familar with.
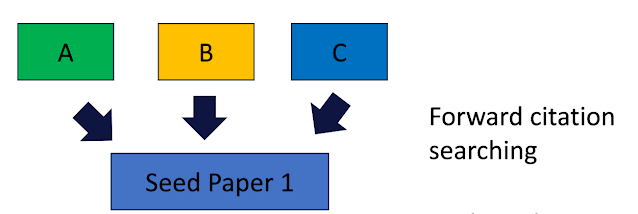
Forward citation searching involves looking at papers that cite the seed paper and check to see if any of these papers are potentially relevant.
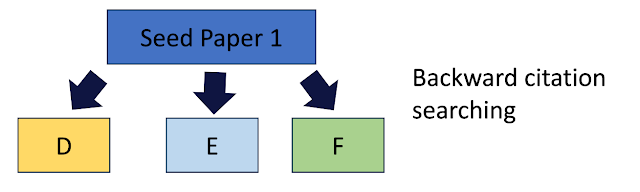
While backward citation searching involves looking at papers that the seed paper cited and check to see if any of these papers are potentially relevant.
Indirect citation searching
More tricky is the idea of "indirect searching".
One form of this is what the TARCiS statement calls "co-cited citation searching".
This involves looking at the papers that cite the seed paper (A, B, C below), and check if these papers also cite another paper, it is potentially relevant as well.
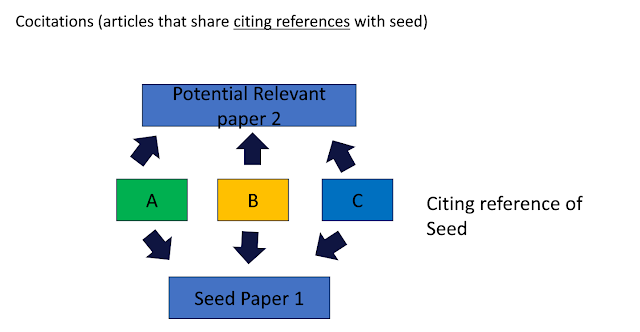
Alternatively you can say the papers you check are cocited with your seed paper.
You can of course do the opposite of this. The TARCiS statement calls "co-citing citation searching".
This involves looking at the papers that the seed paper cites (D, E, F below), and check if these papers are also cited by another paper, it is potentially relevant as well.
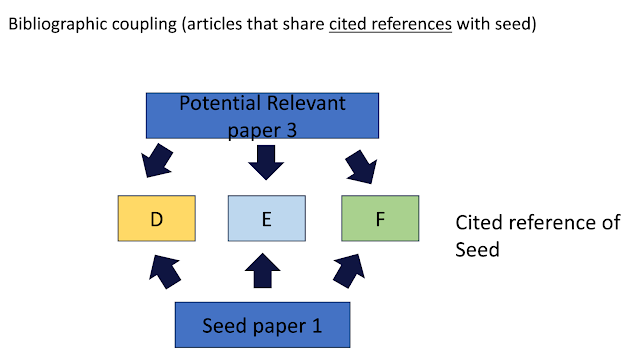
Alternatively you can say the papers you check are bibliographic coupled with your seed paper.
An example of a tool that does this on top of forward and backward citation is the shared reference feature in Litmaps, if you enter only one seed paper.
It is more complicated than that sometimes....
Of course, in reality it is unlikely to find papers, that share exactly all the citing or cited papers as your seed paper, so the algorithm when doing indirect citation methods may suggest papers with only partial matches (e.g. suggest papers that share only 80% of references with seed paper).
Also for the sake of simplicity, my examples only involve one seed paper, many tools like Research Rabbit, LitMaps allow multiple seed papers to be entered at the same time, which further increases the degrees of freedom in which you can use indirect citation searching.
Some tools also do n-hop direct citations, so for example if n=2, it may find citation of a citation, or reference of a reference, citation of a reference and reference of a citation, and use that as a pool of papers to work on. (To avoid the expansion not to explode there may be some limitation of how many citations it may follow at each step).
A very common technique used by some tools is to use the seed papers to expand to a pool of papers using some of the techniques mentioned above and then rank the papers that are "most connected" (which can be defined in many ways) in this pool of papers,
And there are of course even more complicated things you could do with citations or network graphs but you get the idea...
Of course some tools are not limited to citations and will do co-authorship analysis as well (e.g LitMaps or ResearchRabbit). Litmap even throws in text similarity analysis of text-abstract as a third method, which may use embedding based semantic search.
3. How biased are these tools?
Let's leave aside source issues for now, given that these tools based rely on the citation graph, network are they biased only towards finding highly cited papers.
Or to put it the other way, I have heard people say these tools will never find new papers that have zero cites.
While it is true that these tools tend to favour finding papers with higher citations even papers with zero citations could be found using backward citation searching or co-citing citation searching, where a paper with zero cites is surfaced because it shares the same references as a seed paper.
4. How complete are the sources used by these tools?
Most users instinctively understand that these tools are greatly affected by the quality of the index.
And indeed they are, As noted above there are two main limitations.
Firstly the seed item itself (the known relevant item you hope to leverage on) or the item you hope to find via citation chasing is not in the index itself. So for example, if the citation index does not index clinical trials or newspaper articles, you can never find them or even use them as a seed item!
The other issue is that while both cited and citing items do exist in the index, the linkage between the two is not made.
This can be due to a number of reasons
because the citation can't be matched because of an error , this can be due to
some mismatch between the reference metadata in the citing item and the cited item (also known as cited reference variants in Web of Science)
Constructing a Citation index - a simplified idea
Let's take a step back and consider how a citation index is constructed.
When constructing a citation index, typically you start with a "universe of indexed works" (e.g. all papers in Journal X, Y, Z from 19XX onward, or in cases like Google Scholar, what is crawled and classified as "Academic") and from each work, it will try to check if the reference matches any of the indexed work.
One obvious issue that can happen is when the reference in the citing item does not match the metadata in the cited item. For example, the citing author may have a made a small error in paging details, or typos in authors (or order of authors might be different etc).

In practice if you expect the cited reference in a paper to exactly match the metadata of the indexed work, it will lead to a lot of wrongly dropped pairs.
For example, there might be slightly differing name differences (e.g an extra hyphen, extra spaces, inverted names or not etc).
As such most citation indexes do some degree of "good enough" fuzzy matching using different algos/logics for a pair of works to be considered a match. Of course some systems are more "liberal" or do more "loose matching" of pairs of works even if the degree of difference is large.
Such "loose" matching in citation indexes this will increase recall of right citation matches with a tradeoff of more errors of course.
If you are a old school librarian with experience troubleshooting OpenURL link resolvers you will know exactly how bad this issue!
This failure to match leads to what Web of Science calls Cited Reference Variants
The rise in the use of PIDs, like DOIs and PMIDs in reference styles is slowly reducing this issue but not all types of work use PIDs, and the use of PIDs in reference styles is a relatively new development.
Further complications can come into play where there are multiple versions of the same work (e.g. preprint versions) and your citation index combines them together like Google Scholar but we will ignore this here.
Additional issues due to parsers
You might think, cited reference variants occur only due to errors in the source due to citing errors by the author, but this isn't always true.
As mentioned above, when constructing a citation index, typically you start with a "universe of indexed works" (e.g. all papers in Journal X, Y, Z from 19XX onward) and from each work, it will try to check if the reference matches any of the indexed work.
But where do you get the references? They can come in two forms.
If you are lucky, it comes in a structured format, like in RIS/BibTex, which gives you structured metadata information on title/abstract/author even DOIs if you are lucky.
From there, you may run into the problems mentioned above leading to Cited Reference Variants, if there was an error citing by the author of the citing work.
If you are unlucky, it comes in plain unstructured text and you will need to7k extract or parse the reference to enable matching with other indexed works.
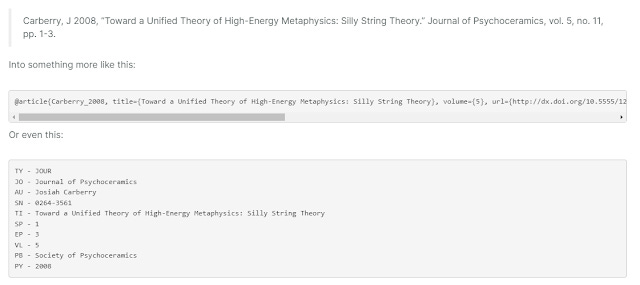
Using tools like AnyStyle, ParsCit, grobid etc you can start with text, PDFs etc and convert it into RIS or BibTex formats
Once you have done so, you can use this to match against indexed works you have in your citation index e.g. matching title, journal, first author last name against metadata of indexed works.
These days, references tends to have a PID like DOI or PMID, so you often just need to parse out the PID and this allows you to easily match cited works.
But for older works or types of works that do not have PIDs, parsing is much more error prone (e.g. it may confuse different spans of text for the wrong field), and if OCR is needed to be run over the text, even more errors might occur.
This interesting article by Crossref goes in depth on the ways to match unstructured references to indexed works and shows a promising technique that tries to avoid the use of a parser but instead using a "search based method" to compare the similarity between the unstructured strings for ranking.
In extreme cases an item might be indexed but the index is unable to get any references at all from the item, so they will appear to have zero references.
These cases are particularly common if the citation style used is very unusual (e.g. chemistry or law styles that are very abbreviated/terse or obscure and hence are very difficult to parse).
In very extreme cases, you may find records of items, typically monographs where the item is indexed but there is no references captured at all (often because it uses a footnote style).
Note that there are ways around finding citations of items that are not indexed, or finding citation errors/variants when you use certain citation index directly. For example in Scopus you can always search for Scopus Secondary documents, while in Web of Science you can use cited reference search function. In Google Scholar, if you see a record that has the tag [Citation] , it is essentially a record that appears because it is cited in indexed works.
In general though, you would expect issues when using these tools to try to find non-journal item content, particularly older seminal monographs in humanities and some social sciences, but you may be surprised.
For example, as of June 2024, OpenAlex has 5.4 million monographs of which 3.4 million have no dois. Sampling it seems a lot of them were inherented from Microsoft Academic Graph.
Typically you can find some old classic sociology text indexed but not the references in them.
Implication for citation chasing tools like Connected Papers, Research Rabbit
Most of these tools rely on the citation index source they use to make the linking, as such they are limited by the coverage and accuracy of these sources e.g. Semantic Scholar. But how accurate are they and how they compare to well known citation index like Scopus or Web of Science?
5. How do the citation sources used by these tools compare to Google Scholar, Scopus, Web of Science
Most users even if they are are familar with Google Scholar, Scopus or Web of Science are generally unfamilar with sources like Semantic Scholar, OpenAlex, Lens.org which are the most common sources used by such tools.
It's hard to be sure but these are some of the major sources and tools known to use them
Tool Data Source Connected PapersSemantic Scholar ResearchRabbitSemantic Scholar, OpenAlex Litmaps Semantic Scholar, OpenAlex, Crossref IncitefulSemantic Scholar, Microsoft Academic Graph, Crossref, OpenCitations Local Citation NetworkSemantic Scholar, OpenAlex, Crossref, OpenCitations Citation Chaser (Available as R package)* Lens.org Others
Of these sources, Semantic Scholar corpus is by far the most popular (particularly after the closure of MAG in Dec 2021), followed by OpenAlex and Lens.org. Important to note, this popular use of Semantic Scholar corpus applies not just to these citation based tools but also the newer "AI" academic search tools that use RAG such as Elicit, Undermind.ai, Consensus.ai etc.
There are many reasons for this, including being much more established than others like OpenAlex, having a stronger presence in Sicilion valley/startups, more generous api rates/more frequently updated data dumps
I find people tend to not realize these sources are typically large, at the 150-200 million record level, which is only clearly beaten by Google Scholar. This is much larger than most sources (e.g Scopus or Web of Science which is at 80 million level) they are familar with, so typically they worry too much if something can be found in the index, not realizing that isn't the issue.
For example, Semantic Scholar is estimated to be over 200 million, OpenAlex is estimated at 240 million and Lens.org in the same ballpark!
One trick i figured out when asked is to tell the user to search across the Semantic Scholar website (or Lens.org or OpenAlex if the tool uses those) to get a sense of what is covered.
There are a couple of caveats to this
Tools like Researchrabbit, LitMaps may draw from say Semantic Scholar, but they may have filtered out certain sets, so finding something in Semantic Scholar may not necessarily mean it is in the tool.
Tools like Researchrabbit, LitMap if they dont use the API, and instead use the data dumps only, they might be behind and may not have newer papers
If they DO use the API (or even in combination with the data dump to get best of both worlds), it is important to note that it might still show less than what is found by searching on the Semantic Scholar website because of licensing agreements.
All this is nice to know and all but how do sources like Semantic Scholar, Lens, OpenAlex stack up against the big 3 citation index - Web of Science, Scopus and Google Scholar.
In the formal literature there has been plenty of studies analysing and comparing the big 3 (and for a time Microsoft Academic Graph), but close to nothing on the more open citation indexes like Semantic Scholar, Lens.org, OpenAlex used by these tools.
Well nothing until now. that is, Michael Gusenbauer is a rare researcher who does not content themselves with just comparing the usual suspects (Google Scholar, Web of Science, Scopus), but has produced a body of work that comprehensively studies a large number of academic databases
Some past work that you definitely should not miss include
A lot of the results in his research is now available (and updated periodically) on the amazing SearchSmart website which is updated regularly, with complete details of over a 100 academic databases, including estimates on coverge per discipline, and feature lists that you can use to compare.
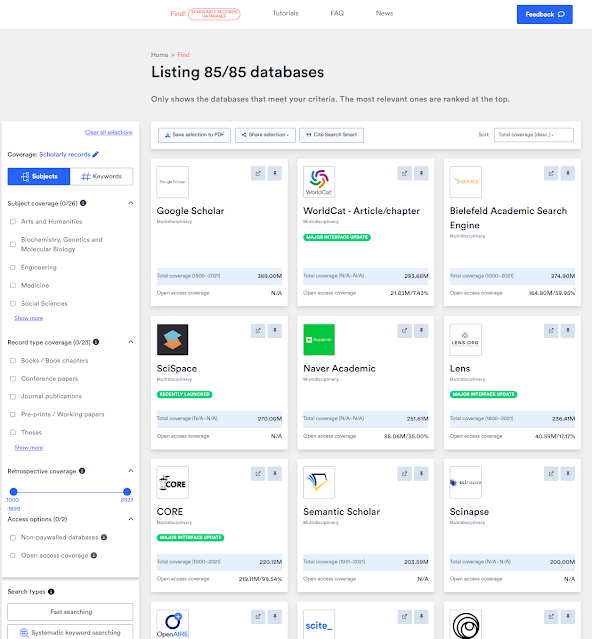
https://www.searchsmart.org/results/semanticscholar?~()
His latest work, Beyond Google Scholar, Scopus, and Web of Science: An evaluation of the backward and forward citation coverage of 59 databases' citation indices, attempts to quantify the peformance of 59 academic databases with backward and/or forward citation features.
For the rest of this blog post, FWC = Forward Citation and BWC = Backward citation
Limitations of this study
The study began by sampling some of the most cited papers (6 each) from each ASJC category resulting in 156 papers. However because this study was done on smaller specialized databases like IEEEXplore, this would result in too few papers for such databases. As such another 103 papers were added for a total of 256 papers to ensure each database has at least 9 papers covered.
The performance of each database for backward citation functions was done in a straight forward way. The author would manually check the full text of the 259 documents and count the references.This was furthered verified by comparing against databases had 100% or near 100% performance in Backward citations.
More formally
If BWC indices covered exactly the number of full-text references, their coverage was considered accurate, that is, with zero errors. Formally, the calculation of the BWC score was d × (1−f), where d was the share of articles with BWC information and f was the mean absolute percentage error.
Note for this comparison, to ensure smaller databases are on equal footing, only papers indexed in the databases are considered.
So for example, even though PLOS indexes only 9 out of the 259 papers (3.5%), all 100% of the 9 papers have BWC info. The mean absolute percentage error is low only 1%. The overall performance is 100% * (1-0.01) = 99%.
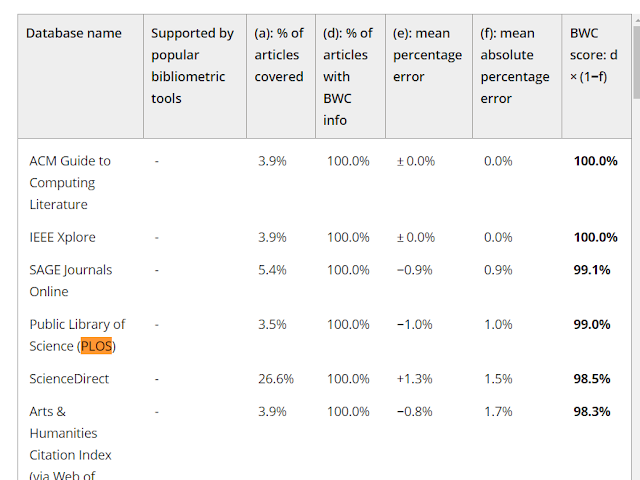
This looks fair enough, the greater issue was how performance of Forward citation function was measured. The author writes
I determined the coverage of the citation index compared to some optimal values. For FWCs, the optimal value was the maximum FWC count available at one of the 59 databases that served as the benchmark. The FWC score was calculated with b × (1−c), where b was the share of articles with FWC info and c was the indices' median deviation of the maximum FWC benchmark value.
There are a couple of issues here but the main issue is that the "optimal value" or the benchmark is the citation database that gives the paper the highest citation count. Unlike BWC, this clearly advantages larger citation databases.
I guess you won't be surprised to find out that in 243 out of the 259 papers (94%) the highest citation count (optimal value) came from Google Scholar! It was beaten only 16 times by
ResearchGate (11)
OpenAlex (2)
Semantic Scholar (1), Dimensions (1), and Econpapers (1)
The fact, that the measure of FWC does not put smaller databases on equal ground is not fatal, if you argue the aim of FWC to increase recall.
But by far the biggest issue is that there is no validation of the citation counts/links, so a citation index that is "liberal" or loose in doing citation matches (see above), would be scored highly even though many of the "citations" were wrongly attributed. In fact, there is some evidence, this is exactly what is happening for Google Scholar.
Ideally, FWC count should be based on validating the number of correct citation links between items indexed in each database, but clearly this involves a crazy amount of work that isn't realistic!
Results of this study
Despite the limitation of the methods, this paper is well worth reading if you are even halfway curious about citation searching. I will not attempt to point out all the interesting results, but just extract the FWC results for the indexes used by citation tools.
For FWC
Semantic Scholar - Rank #4 (98.5% coverage, 100% with FWC info, median deviation of max FWC -27.3%, FWC score 72.7%)
Lens.org - Rank #5 (96.5% coverage, 100% with FWC info, median deviation of max FWC -28.9%, FWC score 71.1%)
OpenAlex - Rank #9 (100% coverage, 99.6% with FWC info, median deviation of max FWC −31.4%, FWC score 68.3%)
Unsurprisingly, the main sources - Semantic Scholar, Lens.org, Openalex rank very highly based on FWC score, due to the huge size of their index.
Based on this metric they are also ahead of Scopus (Rank #11) and Web of Science Core Collection (Rank #12) - but take into account the limitations of this metric.
Semantic Scholar particularly looks good, its median difference in citation count from the highest citation score (typically Google scholar) is around 27%.
For BWC
Semantic Scholar - Rank #22 - mean percentage error +4.2%, mean absolute percentage error 17.0%
Lens.org - Rank #20 - mean percentage error −10.1%, mean absolute percentage error -17.7%
OpenAlex - Rank #31 - mean percentage error −23.9%, mean absolute percentage error -28.9%
Compared to Scopus and Web of Science
Web of Science Core Collection - Rank #11 - mean percentage error +2.9%, mean absolute percentage error 5.8%
Scopus - Rank #15 - mean percentage error +2.8%, mean absolute percentage error 10.1%
One of the more interesting findings is that the smaller specialised databases or platforms covering specific domains are particularly accurate with backward citations.
For example, ACM Guide to Computing Literature, IEEE Xplore have mean absolute errors of 0% and are essentially perfect.
SAGE Journals Online, PLOS, ScienceDirect have mean absolute errors under 2%.
In terms of the best balance between size and accuracy of BWC, Web of Science Core Collection seems to be the sweet spot with a big enough index with reasonable mean percentage error of +2.9%.
It seems like when looking at backward citations, Semantic Scholar is significantly less accurate than Web of Science but the fact that Semantic Scholar on average tends to overestimate +4.2% which is less serious than Lens.org which tends to underesimtate -10.1%
OpenAlex seems really really bad for backward citations though, on average it lists 30% less backward citations! It's hard to say what is happenning here , perhaps OpenAlex is not listing backward citations to non-indexed works?
More research needed here as noted by Guidance on terminology, application, and reporting of citation searching: the TARCiS statement but this paper is a good start!
Another area of research that is a priority in the TARCiS statement suggests research into "optimal use of indexes and tools and their combination to conduct citation searching". Indeed even restricting yourself to just direct citation methods, there are multiple ways of doing iterative searching (e.g. Iterative vs parallel vs sequential)
Interestingly they also suggest
Using the combined coverage of two citation indexes for citation searching to achieve more extensive coverage should be considered if access is available. This combination is especially meaningful if seed references cannot be found in one index and reference lists were not checked
In the case of using tools that draw on Semantic Scholar, Lens.org and espically OpenAlex, it might be worth considering using a second citation index. This is not so much because the seed references cannot be found in the source (coverage in the paper was >97%) but more the worry it is missing out backward citations particularly in the case of OpenAlex.
6. Reporting and Transparency when using these tools
If you are doing a systematic review, you might be concerned with two issues when using tools like Connected Papers, ResearchRabbit - one is what to report and second is transparency.
Reporting wise, the already mentioned Guidance on terminology, application, and reporting of citation searching: the TARCiS statement , gives a partial answer....
Also I was curious to see if people were using these tools in systematic reviews, A search in google scholar would surely overestimate use because there is no good way to limit to systematic reviews.
I suppose I could use PubMed but I would need to search full-text, just for fun I searched preregistered protocols at Prospero.
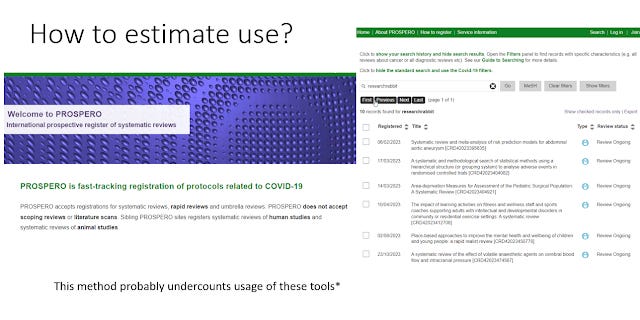
This would be a lower bound of course (most systematic reviews are not preregistered) and this is what I found.
CitationChaser(72) - 2021-2024
ConnectedPaper(24) - 2020-2024
Cocites(11) - 2020-2023 (discontinued)
ResearchRabbit(10) - 2023-2024
LitMaps(6) 2023-2024
CitationGecko(4) 2022-2024
The results are not surprising, Citation Chaser is extremely popular because unlike the other tools, it was the only one made espically for Evidence synthesis. The others are all relatively new tools starting from 2020 onwards....
Just for comparison sake, I also studied mentions in protocols of relatively new academic citation indexes.

As you can see Semantic Scholar is relatively popular (for searching often grey literature), but it's the oldest of the bunch, dating back to the mid 2010s.
Still despite being mentioned 202 times it is still relatively unpopular, for context, Google Scholar is mention >8,000 times in 2023 alone!
Transparency of these tools varies
Though many of these tools use citation based techniques, they variant hugely on how transparent they are. This makes it difficult to report on them.
Or perhaps it doesn't matter if it is just a supplementary technique?
For example, Connected Papers algo is just mentioned to be a similarity metric based on Co-Citation ( co-citing citation searching). and Bibiliometric Coupling (co-citing citation searching) but you don't get the exact formula.

On the opposite extreme you have tools like Pure Suggest, Litmaps (at least the top shared citation references function) etc which have relatively simple and understandable functions.
Inciteful in particular brings transparency to an extreme, you can actually change the algo used for ranking papers by editing the SQL rules!
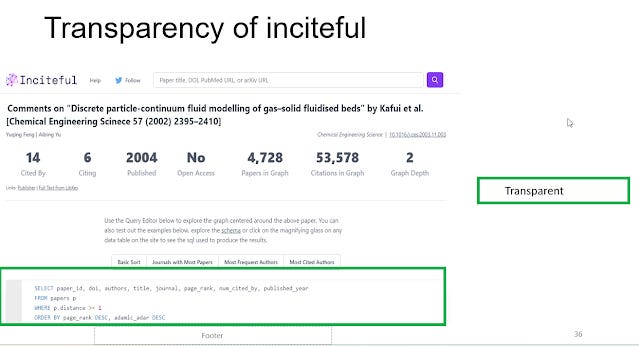
Many tools have a mix of algos, some of which are transparent , some not.
For example if you use the functions of ResearchRabbit to chase references or citations, that is clearly transparent.
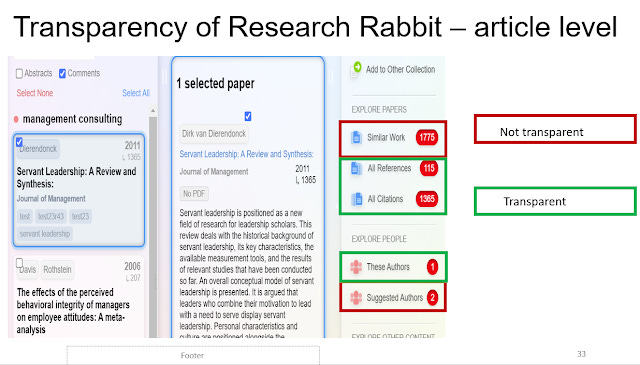
But if you use "Similar work", "Earlier Work" or "Later work", you get the following non-explaination.

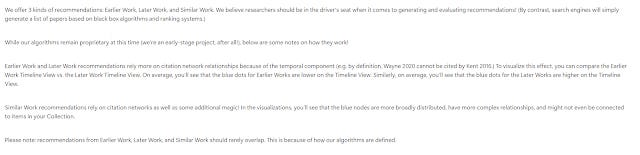
https://researchrabbit.notion.site/Welcome-to-the-FAQ-c33b4a61e453431482015e27e8af40d5#458ae1a94e77497eb69f78b725362ebc
Conclusion
Hope this long blog post, has helped you understand a bit more about citation searching and how tools like ResearchRabbit work.