
Are the current AI search tools that are enhanced with transformer-based models, the unicorn - low skill cap, high performance tools we are looking for?

Summary
Classification of Academic Search Tools by Skill and Performance: This post explores a framework for categorizing academic search tools based on their skill cap (the expertise needed to use them effectively) and performance cap (the potential quality of results they can yield), drawing parallels to gaming strategies.
Trade-off: Tools like Google Scholar and Web Scale Discovery services (e.g., Primo, Summon) are seen as low skill and low performance cap tools—simple to use but limited in delivering high-quality results, especially for complex research needs. While PubMed and A&I databases are seen as the opposite, high skill but high performance cap tools.
Rise of AI-Driven Search Tools: The post reviews Undermind.ai, an AI-enhanced academic search tool that promises a high performance cap with a low skill cap, potentially revolutionizing academic search by using natural language input and GPT-4 to deliver more relevant results by doing agent like search with minimal user expertise needed in both product use and choice of keywords.
The post concludes by suggesting that while Undermind might possibly reduce the importance of knowing the right keyword (or knowing what to input) to some unknown extent but it still matters what to input, so skill is still a factor.
Introduction
In Are Google & Web Scale Discovery services - Low skill cap, Low performance cap tools? I mused about how you could in theory classify academic search tools into two dimensions.
Maximum performance of Tool also known as "Performance Cap"
Maxmium skill level needed to make the most of the the tool also known as "Skill Cap".
Using an analogy of the digital mobile CCG (Collectable Card Game) Hearthstone, I noted that certain types of decks, were relatively easy to play or low skill cap (perhaps because you typically played the same few patterns no matter the situation) but did very well only at lower levels of play (low performance cap) even if you played the deck to the highest levels.
Other decks on the other hand were hard to play (perhaps because there were a lot of exceptions to the patterns) but had high performance cap and if played skillfully could do very well even at the highest level of play.
Similarly, I mused that search tools could similarly be classified under these two dimensions of high/low skill cap and high/low performance cap.
It's hard to operationize these two dimensions concretely but you could use recall, F1 or NDCG@10 or similar relevancy metric for performance cap to measure how well the retrieval went. Measuring skill for "skill cap" is even more tricky but this could be roughly proxied by experience in terms of hours spent learning/trying etc. Another possibility is to try to quantify it with number of features (maybe from https://www.searchsmart.org/) assuming that more features opens room for skillful use.
This 2x2 grid then breaks down into four main quadrants.
At the top right, you have tools that are hard to use (high skill cap) but have high performance in the expert hands (high performance cap)
Examples of these tools would be PubMed, A&I databases with a ton of features including advanced field searching, filters and more.
At the bottom left, you have tools that are easy to use (low skill cap) but have low performance regardless of who uses it as you can't do much to improve it (low performance cap)
I am of the view that Google/Google Scholar and our Web Scale Discovery tools e.g. Primo/Summon are low skill cap but low performance cap tools as well. (Note: Some may disagree above the low performance cap bit if it meets their needs, so to a degree this is subjective)
In other words, it doesn’t take a lot of training to get the maximium performance out of something like Google Scholar, library web discovery systems like Primo/Summon but the best you can get out of it isn’t a lot.
Take Primo or Summon, on paper they have facets to do post filters and an advanced search, but in general, due to the diversity of sources indexed in the Central Discovery Index (which Primo/Summon draws on), quality of the metadata varies a lot. As such filtering on subjects or other metadata is not as effective as doing so in a proper A&I or subject database like PsycInfo, Scopus or Medline (via Pubmed etc) with proper controlled vocab like MeSH and subject thesauri.
Also on paper, you can do nested boolean searches in Summon or Primo, but in my experience nobody borthers and if you tried you often get worse results compared to just doing simple keywords. (See "The Boolean is Dead, Long Live the Boolean! Natural Language versus Boolean Searching in Introductory Undergraduate Instruction")
There is a roughly similar story with Google Scholar, but with an even more limited advanced search and lack of support of nested boolean at all (for example, parenthesis is not supported in Google Scholar). It is not to say you can't get decent results with Google Scholar, but you are expected to do many iterative simple keyword searches, combine them together with citation searching etc.
Incidently that is also why I suspect Google Scholar and possibly Summon or Primo are viewed with suspicion for use in evidence synthesis. Unlike search systems that supported nested boolean, you are forced to run multiple iterative search queries and combine them together which is less transparent than running one big nested boolean search.
This explains why academic librarians today rarely spend a lot of time teaching users how to use Primo/Summon despite it being the default library search box on most academic libraries. They rather focus more on say Scopus, PubMed, EconLit, which have more bells and whistles on top of supporting nested boolean + field searches.
I ended by wondering if because of our desire to be helpful and needed as librarians, our instinct is to see all tools at least at first as high skill cap tools even when they are low skill cap tools leading to us teaching unproductive techniques that at best don't work or at worse cause issues.
But since there is a trade off between high skill cap and high performance, all we librarians need to do is to spend more time teaching the high skill cap tools and avoid spending time on the low skill cap tools right?
But what if we are now seeing high performance cap, low skill cap tools that give good performance with little training?
Are the current "AI search" tools like Undermind.ai, Elicit etc the long awaited high skill cap, high performance tools?
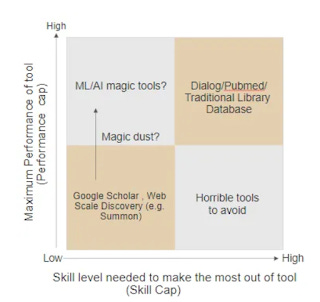
At the time I wrote this in 2018, I speculated if in the future AI could result in the fabled "high performance, low skill cap" tools.
Such a magic search tool, would automatically produce high quality search results even if you were a beginner with the tool or limited domain knowledge (so you use poor keywords) and conversely even if you were a librarian with experience with the tool or deep domain knowledge (so you know the right subject headings), you could barely do much better.
At the time of this writing in Nov 2024, my view is one of the leading commerically available academic search tools that uses "AI" is Undermind.ai.
I will use it as an exemplar of the current class of academic search engines that are enhanced with NLP capabilities from transformer based models to consider how closely it meets the fabled holy grail of high effectiveness, low skill use.
What is Undermind.ai and how it works
I've written a early review of Undermind.ai here in April 2024 and here is a more official review written for Katina magazine (formerly Charleston Advisor)
But here's a quick review of Undermind.ai
How undermind.ai works via the power of successive searching
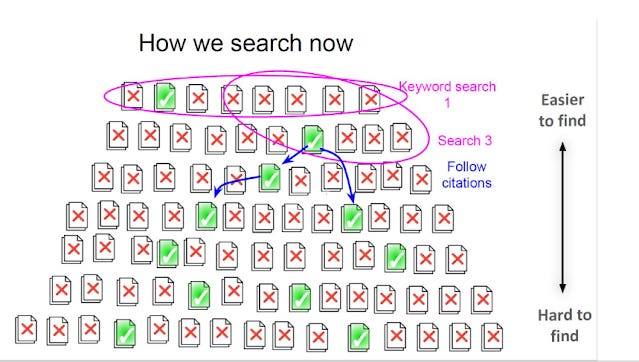
The main issue as you probably know with doing keyword search is that we may not know the right keywords. The technical term used in information retrieval is the "vocabulary mismatch problem".
Below shows three keyword searches (Search 1,2,3) that ended up with two relevant documents (green check).

Thankfully we can use citation searching to hopefully find relevant papers bypassing the "vocabulary mismatch problem"
Hopefully if that finds more relevant documents, you might realise hey - this other keyword is used instead so this allows you to run more keyword searches (Search 4, 5 below)
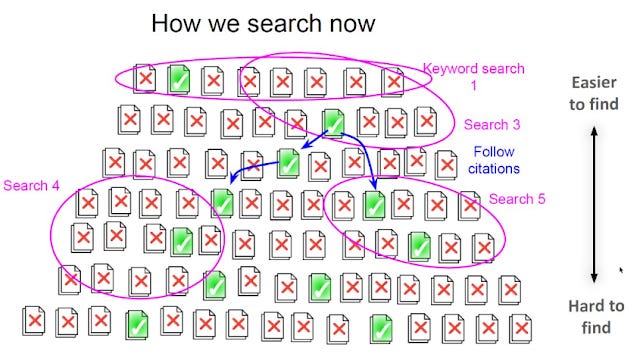
Then you can continue this cycle for a few iterations.

Most academic researchers use a variant of this method to maximise their chances of getting as many relevant papers as possible and Undermind.ai is a agent-like academic search that essentially tries to mimic this process of iterative searching with keyword/semantic search and citation searching.
We are told Undermind.ai uses GPT4 is to both steer the search (which also involves doing citation searching as well) and is also used directly to assess (based on title/abstract) if a item found is relevant or not.
Note: The open source project - PaperQA2 another agent based system has search modules "paper search" and "citation traversal" that looks similar to me in spirit as Undermind, though that systems goes further with the iterative retrieval of full-text of candiate papers for RAG evaluation etc to generate full answers, while Undermind only evaluates on title/abstract
Interface wise you type in your query in natural language. But beyond that, Undermind encourages you to be as specific as possible on what you want, like explaining things to a colleague.
Undermind's Whitepaper suggest that GPT4 and human judgement of relevance is around 90% correlated and I have read studies suggesting similar results for many NLP tasks. As such Undermind's method of using GPT4 for determining relevance is much more reliable as compared to just calculating a relevancy score based on say term matches. That is why Undermind highly recommends you ask for very specific things to take advantage of this near human judgement of relevance.
It will run your inital input through GPT4 which will ask you follow up questions.
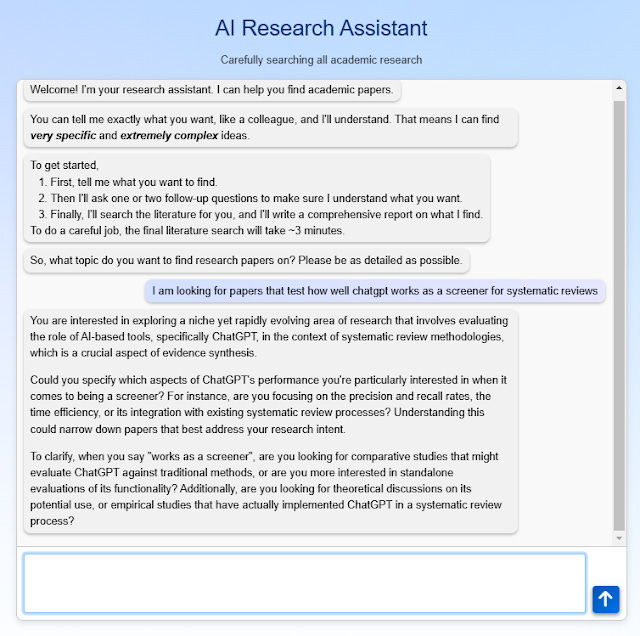
Like in the example above, I ask for studies on how well ChatGPT works as a screener in systematic reviews and it smartly ask me to narrow down. For example, it "knows" that there are studies that measure this using metrics like recall, precision. In some other attempts it asked me if I was looking for just ChatGPT performance or other LLMs.
The searching screen above is mostly a placeholder but it does give you a taste of what is going on, that Undermind.ai is doing and adapting multiple searches. Which is why it takes 3 minutes and not 10 seconds.
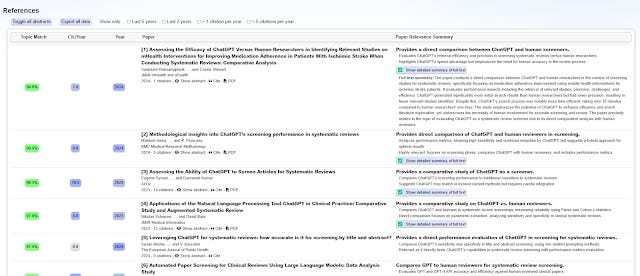
The final result screen has two parts, firstly there is the results page itself, include a column that tells you why Undermind.ai (actually GPT4) thinks something is relevant or not.
There is also a section - "discuss the results with an expert" which is the by now the familar feature of doing retrieval augmented generation over papers.
We will not discuss this section further because we are focusing on relevancy of results.
Undermind.ai of course using an extremely computationally expensive by both searching multiple times and using GPT4 directly to assess relevancy and this takes about three minutes to run.
But is it truly worth it?
Arguments for Undermind has a high performance cap, low skill cap tool
For Undermind to be a high performance cap, low skill cap tool it has to perform very well but require little training to use.
I am currently working on a study testing the performance of Undermind in terms of recall/precision by seeing how many of a gold standard test set found by systematic reviews are found. My current ancedotal testing is that Undermind.ai does indeed find more than other "AI search tools" - maybe conservatively it finds 30% on average of gold standard sets (10-20% more than other tools), though I've seen reports it found 80% for gold standard sets in computer science. This is an improvement over other tools but far from perfect if systematic reviews are the standard we measure again.
Similarly, when we trialed Undermind.ai at my institution, the feedback was almost uniformly very positive something I have not seen with other "AI tools", people seem to recognise there is a pretty large jump in improvement in the search algos.
Though this is not established firmly yet, let's take for the moment Undermind gives high quality enough results it is a high performance cap tool.
But even if Undermind.ai performs better than most tools, how do I know it is a "low skill cap" tool? Maybe most of the people trying Undermind.ai including myself are skilled searchers and if we let a rank beginner (say an undergraduate) they will do far worse than the current users of Undermind who are fairly seasoned researchers.
Conversely it is possible that even if we find say 99 out of 100 users get roughly the same performance, it may just be that because Undermind.ai is so new (I myself first found out about this tool in Jan 2024, less than 11 months ago), most of us haven't figured out how to make it work better so we are all stuck at the same level of incompetence!
Tips for using Undermind.ai - do I have any?
I have been using Undermind.ai for longer than most, I was first contacted in Jan 2024, when I tried the original version of Undermind.ai as described in their whitepaper that searched only Arxiv (that version took 30 minutes to complete but it did full text).
I tried it a few times but shelved it until they switched to Semantic Scholar corpus in April 2024, which is where I really became very interested. I am probably one of their first 100 users and probably one of the first to actually review it to some depth.
Of course, this doesn't mean I am the best Undermind.ai user as I am sure there are super fans who use it more but naturally a lot of people including librarians are asking me if I have any tips to using Undermind.ai better.
It struck me after thinking a while that if I could not come up with any or many tips this might be a sign that Undermind.ai is actually a low skill cap tool and that there's isn't much one needs to know to make it work well (again assuming that my knowledge of Undermind is sufficient)!
The thing is I think Undermind.ai does a great job of guiding users on what to do. For example, it states upfront that you are supposed to be very specific and brilliantly uses GPT4 to ask follow up questions to try to guide the user to be more specific. Because GPT4 has quite broad general knowledge of most areas of research, it's comments can even help user use terms that they may not have thought of!
So what can I advise that isn't already mentioned in the Undermind interface or a existing feature?
Firstly, I know that Undermind.ai only looks at title/abstract so maybe don't ask for things that can only be found in the full-text?
I also do notice some common mistakes, like users trying to ask Undermind for a certain type of paper (e.g. review paper) which it currently does not do yet (I understand this isn't a technical barrier just something they don't do yet). Similarly searching for other metadata other than year of publication like author, affiliation, journal title is unlikely to work.
But this is something Undermind can easily fix by detecting when this happens at discouraging it.
The Discovery progress and converging search
Keep in mind that Undermind.ai works very similar to a human researcher, as such it needs to be able to "decide" when to stop searching otherwise it could go on adapting keyword searches, doing citation searching and using GPT4 to evaluate relevancy forever.
Intuitively as a human you will typically start to consider stopping if you notice less and less relevant results are found as you go down the search result list or you yield less and less relevant papers in your iterative searches. Undermind.ai works in a similar but more formal way using a statisical model , this gives you the "Discovery progress" that estimates how many more relevant papers are not yet found.

In the example above, it checked 140 papers, of which it estimate roughly 9-11 that are relevant. It thinks there are still another 10% more relevant papers that could potentially be found if you extend the search further.
The FAQ also suggests that one reason a relevant paper does not appear is the search has not "converged" (assuming paper is in the corpus).
It seems odd that the message Undermind gives about extending search is the same whether it is 10% or 90% estimated found already, it seems to me it should priortize recommending extension of search when the estimate is low.
I probably misunderstand how this works, but if the estimated absolute relevant papers found is very low (0 or 1), it is also more likely that the estimated % found is off and it is probably worth extending the search as well.
Does keywords or your input really not matter when using Undermind.ai?
The importance of skill in using features in a search tool clearly can affect performance of the tool. But even more important typically is domain or subject knowledge leading to the correct choice of keywords in the search.
Undermind seems to work reasonably well with natural language and the fact that it adapts its sucessive search and does citation searching clearly helps a unknown ammount with poor choice of keyword/input but saying choice of keyword or input doesn't matter at all seems unlikely.
For example, I was recently doing a review on a paper that discussed OpenAlex. I knew from past readings there were a few papers comparing not just the scope of OpenAlex but also the metadata completeness of OpenAlex vs Web of Science and Scopus and I ran the following search in OpenAlex (see report).
The initial search gave excellent results but it just didn't have the specific paper I was thinking of.
I was thinking specifically of this "Beyond Google Scholar, Scopus, and Web of Science: An evaluation of the backward and forward citation coverage of 59 databases' citation indices"
Admittedly this is a little tricky because this paper doesn't mention anything about metadata completeness but the study shows OpenAlex's indexing of references is extremely incomplete compared to other citation indexs like Web of Science or Scopus which of course implies the metadata is less complete.
Looking at the "Discovery progress", or Undermind.ai's statistical model of the search progress, it said it estimated it found 3-7 relevant papers and this was an estimated 90% of all relevant papers with it's inital search of 140 papers.

I then extended the search and the desired paper finally turned up after it searched 340 papers. The paper I wanted was ranked 14, with a low topic match of only 9.4%! In practice of course most users would not have extended the search as the statistical model was already at 90% found and diminishing returns are setting in.

Tweaking the input slightly to mention citation searching and the paper I was looking for appears immediately abeit with the low rank of 29 and topic match of 3.2%. This search also claimed to find 90% of all relevant papers but estimated a higher 9-11 relevant papers found even after searching only 140 papers (vs the earlier 340). Arguably this is a better search that the first one.

Another input asking specifically for effectiveness for citation searching is even more effective bringing the desired paper up to rank 3 with topic match of 88.7%. On hindsight, I probably should have gotten even better results if I split the query into multiple undermind queries (perhaps one for each metadata field) and combining them together rather than asking at one shot for "metadata completeness and accuracy" of multiple fields at one time. This is of course "be specific" as a tip again.
I have seen some users attempting to enter the inclusion citeria of systematic reviews into Undermind. While others throw in the actual boolean strings used in systematic reviews and ask for papers matching these strings! My guts tells me the later shouldn't work well, but to my surprise.....
All in all there is so much we don't know about Undermind.ai today to judge if there are specific things we can teach to improve it.
Conclusion
In summary, Undermind does seem to have many characteristics of what we want in a high performance cap and low skill cap tool.
Natural language input and guidance from the languge models coupled with automatic agent like iterative searching (including citation searching) probably reduce the importance of choosing the right keywords somewhat but not completely (similar to older techniques like query expansion).
I can imagine research involving testing searchers who have varying subject knowledge trying Undermind and checking how much the results found by Undermind overlap. If most of the results still overlap and a reasonable number of relevant results are found, it probably provides some support to the hypothesis that we have a tool that equalizes skill/knowledge of keywords leading to a low skill cap tool.
However, currently to say what you input doesn't matter at all is still probably untrue and librarians still have a role figuring things out on how to use Undermind.
Still it's one of the closest we have seen so far.....