


Avoiding misconceptions - testing "AI search tools" - What not to do & some research questions to consider

As more and more academic search tools start to increasingly leverage on the fruits of "AI" (actually transformer based models) and librarians start to encounter such tools whether it is from brand new products like Elicit.com, SciSpace, Scite.ai assistant etc or from existing vendors bundling in AI such as Scopus AI, Primo Research Assistant, Statista Research AI etc (see list here), it becomes even more critical for librarians to understand how to properly test these tools.
I've always thought that librarians could play a role in helping rigorously evaluation these new tools given that we are neutral and trusted parties.
Generally, vendors of AI products also do not share their benchmarks and evals which they most certainly have to guide their improvement process. But even if they did, would you trust them?
While it is easy to do a subjective, "vibes based" test, where librarians informally give a score of A, B, C grading based on various criteria etc (here's one example) which have value, there are more formal rigorous methods.
So I decided to see how the formal literature was testing AI search tools and searched in Google Scholar for keyword terms like "Elicit.com", "SciSpace", "Scite" etc and limited it to 2024.
As expected, there weren't a lot of hits (typically around 100+) and most were somewhat glancing hits (e.g. Papers disclosing they used these tools or just general descriptions of the tool)
Many of the more evaluative papers were qualitative in nature but of the ones that were quantitative in nature, I was surprised at how bad some of them were.
I am not going to call out those specific papers, as it is we already have not enough emperical papers testing AI search tools but a lot of them make the same two major errors that I think stems from misconceptions of how these tools work.
The Two main ways - Search benefits from AI
In my talks I always say there are two ways in which academic search benefits from "AI".
Firstly, the search is getting more powerful, allowing us to search in natural language to get higher quality results thanks to advances in "Semantic search" sometimes also called "neural search/retrieval" (which rely on embedding matches of dense embedding derived from Transformer neural net models, and typically also paired with powerful rerankers using LLMs and cross-encoders) as well as the possibility of agent based search (.e.g Undermind.ai, PaperQA2, Gemini Deep Research)
Secondly, retrieval augmented generation techniques allow us to not just surface potentially relevant docs to answer the query, but we can generate sentences, paraphrased from text chunks from top relevant documents to answer the query with cites to those documents!
In many talks, I mention a third benefit, where systems like Elicit, SciSpace create tables or synthesis matrix but this often also relies on Retrieval Augmented Generation (RAG), though some systems are just using long context LLMs to extract answers which is less preferred because you can't check the answer as easily.
Testing the first benefit is nothing new in the field of information retrieval (at least as far back as 1992 with TREC conferences and 60s from the Cranfield experiments), while the second, testing retrieval augmented generation is a new area with a host of new metrics proposed such as
Answer correctness
Answer relevancy
Source Faithfulness (Citation Recall or Precision)
Context Recall
Context Precision
Noise Robustness
Negation Rejection
Counterfactual Robustness
Information Integration
Retrieval Augmented Generation is a relatively new area of evaluation with this year's 2024 TREC covering Retrieval Augmented Generation. Below shows their evaluation procedure.

RAG evaluation is quite a new area, so for this blog post, I will be addressing only studies trying to assess quality of retrieval results which is on firmer ground.
I hope to have a blog post on RAG evaluation next year once I better understand it.
There are some things I noticed about some of the current literature in this area as applied to "AI search", that I dislike or thing is misguided.
1. Stop trying to measure "hallucination" of sources retrieved
I know that when ChatGPT first hit the scene, there was widespread knowledge of the fact that the references it created tended to be wrong or worse yet fictional and I saw more studies that I could count that showed this (here's one).
The problem is that many people don't seem to realize this issue applies only when LLM (Large Language Models) that do not search are used, and they do not apply to search engines even ones that are "AI".
Below shows search results shown by a typical "AI search" tool, Elicit.com. Of the Top 8 results shown below they are 100% "real" even if you think the results are retrieved and ranked by "AI"!

Why is this so? When you do a search in an "AI search" tool like Elicit or SciSpace, it is not working like a LLM such as ChatGPT, it does not use the LLM directly to generate references (which is why hallucinations occur).
Technically speaking LLM are decoder only models that output tokens (including references), while "AI search" is typically using embeddings derived from encoder only models to do retrieval or matching of existing document indexed in your source.
Instead your query is used to find documents that has been indexed in your source, and your query is matched to existing documents just like any standard search engine!
Granted the part that makes it "AI" means it might not be JUST doing purely keyword or Boolean search (it may be also doing a closest similarity match between the embedding representation of your query and documents), but all the same, the documents it finds and ranks are "real" and not made up by the LLM!
I see so many studies wasting time, trying to measure how "verifiable" the papers retrieved by AI search engines like Elicit, Scite.ai. Some construct what they call a "Hallucination Source Index" based on how accurate the different citation elements are which shows they totally misunderstand what is happening.
Sure when you measure it this way you will realize the references in Elicit, SciSpace are not perfect (maybe 95-99% accurate) with minor errors. But that's not due to "hallucinations", that's just due to errors in the source. In Elicit's case the source is Semantic Scholar, SciSpace is using their own proprietary one (though effectively because it likely uses open sources it ends up similar in scope to OpenAlex, Semantic Scholar etc) and yes, there is some degree of differences in how clean the sources are.
If you still don't get the point, saying these are citation errors due to "hallucinations" is the same as saying because you cite on the "cite" button in Google Scholar and it often gives you a citation that is not 100% correct, Google Scholar hallucinates!

It gets absurd when I see a paper, trying to verify if references found by Scopus AI are "real" and concluding 61 out of 62 are verifiable because 1 of the papers found by Scopus AI is listed only as a [Citation] by Google Scholar. Honestly, this is such a waste of time, Scopus AI is just using Scopus's index (which is known to be higher quality than Google Scholar) if you can't trust Scopus who can you trust!
To a lesser extent, verifying the citations from generated answers from retrieval augmented generation is equally pointless, since these citations come from the "Retriever" or search which are definitely "real". Indeed, if a RAG system is properly implemented, the citations will be from real retrieved items. You still have to worry about the LLM "misinterpreting" the real paper that was retrieved but that's a different problem!
All in all, I can see it might be worth doing this, as long as a) you are aware you are not measuring "hallucinations" but rather the reliability of the source and b) the source itself has not being studied (i.e this is pointless for Scopus, Web of Science) but then you have to be upfront you are studying the source not "AI".
2. Be aware of the sources used by the AI search and understand how it might affect your hypothesis.
This is less egregious but still quite sad. But I see so many studies test somewhat uninteresting things because the results is obvious.
But example, I see many studies pit "AI search tools" like Elicit, SciSpace, Scite vs conventional databases like Web of Science and Scopus.
This is fine as it goes, but if you pit these two sets of tools and one of your metric you are measuring is "quality" of retrieved results, when "quality" is defined as anything in a top journal/has high Journal ranking/high citation, the foregone conclusion is Web of Science and Scopus is almost likely to triumph.
This is because Elicit, SciSpace, Scite etc are all using huge inclusive indexes, roughly in range of 200M according to SearchSmart, while Web of Science and Scopus has a index that is clearly more exclusive with less than half the size, focusing only on top journals.
Almost by definition, the results retrieved by Web of Science are all from journals with some ranking!
Granted, it is possible for the search algo to compensate for this by heavily weighting citations or journal tiers as Scite.ai assistant and Google Scholar does, but mostly source will prevail.
Somewhat similar applies to a study that I saw trying to compare "AI tools" like ResearchRabbit, Inciteful vs Elicit and SciSpace in terms of "quality" of results (defined similar way as before).
No surprise again that ResearchRabbit and Inciteful just trounced the other two in this metric. Why? ResearchRabbit and Inciteful are citation based mapping tools, their algo is biased towards recommending/finding highly cited and hence typically in top journals! Meanwhile, Elicit and SciSpace are mostly by default doing semantic search and hence text similarity is the main ranking factor and citation signals is ignored by default.
Another example, a study tried to study how "unique" were the papers retrieved by "AI search" tools vs Web of Science, Scopus, and generally speaking the AI search tools found more unique items which again isn't that surprising given the difference in the index size of the typical AI search tool vs web of Science.
To a lesser extent I also dislike studies that try to determine % of retrieved items by publication type (e.g. monographs, preprints, journal articles), though it is conceivable search algo makes a difference, more likely than not source is the predominant factor.
Maybe I am too harsh and someone needs to try these "obvious" tests to confirm what we already know. Still it seems to make sense more to me to compare say Elicit vs Undermind as both are using Semantic Scholar corpus and while there might be some differences in how it is used in both companies, at least any differences in retrieved results can be more easily assigned to the algo.
What I want to see
This blog post isn't designed as a how to test IR tools but here are some interesting research questions that I am curious about.
I can't guarantee nobody has studed these topics, but they are of interest to me as a Librarian/ practitioner.
Degree of non-determinism, randomness in results
One of the things about AI search tools that people have noticed is that their results (whether it is just the search results or the RAG generated statements) can be non-deterministic.
For RAG generated statements, it is easy to understand because we all know from experience ChatGPT and other modern LLMs based on decoder transformer models is non-deterministic and running the same prompt twice gets slightly different responses.
Why does this happen? The obvious reason is that the default settings for most of the LLMs we use in the web interface is set to be somewhat random in the selection of words/tokens so it does not always select the token with the highest probability (though it's biased to select higher probability tokens). The degree in which it varies is controlled by settings like Temperature, Top P, Top K etc. Interestingly though, when you set there factors to 0 or turn them off, there are still non-deterministic responses! I understand this is caused by factors like . Parallelization in Computation, rounding errors in floating points and more
But people are noticing it also happens for the search results (not the generated sentence) as well, such that if you rerun the same query for some Ai search tools say the next day, the order of search results is different.
Again, it seems weird this is happening since most of these AI search tools are using dense embeddings from trained embedding models (encoder models) and in theory they should produce the same embedding for the same input. One among many possible reasons is that many AI search engines are doing Approximate Nearest Neighbor (ANN) Search to speed up the search at the cost of accuracy. As such if you try the exact same query but the system uses a different seed/starting point, you may end up with a slightly different result. Still IR systems are so complicated nowdays, there are many subsystems that might cause non determinism, eg using LLMs to do query expansion in real time.
It would be interesting to have a study to study how serious this issue is across a variety of systems. For example, are the variants mostly minor? E.g. Top 5 results are almost always the same but with minor variance in order or can we get really different sets of papers? Are certain systems like Elicit which use SPLADE (a learned sparse representation model which does not need to do ANN) , less affected by such issues?
Sensitivity of input / "prompt engineering" impact
"AI search" now encourages you to query in natural language. This means you can query for what you want in multiple ways that are equalvant in "Semantic intent" and ideally you should get similar results (in terms of what is retrieved), how true is this?
This could be measured simply by
a) Checking for overlap of results returned by alternative queries in top K
b) Checking for overlap of relevant results returned by alternative queries in top K
c) Comparing performance of alternative queries using typical information retrieval metrics, like Recall@K, Precision@K, NCDG@K, F1 etc), how different are they?
d) Comparing "diversity" of results between "AI search" and keyword search systems (but remember the source needs to be somewhat comparable).
A conceit of AI "Semantic search" is that the results are good even if you do not know the right keywords.
For example, between the query "Is there an open access citation advantage" vs "Does open access papers get more citations" does the former query do better because I knew the right keyword jargon? Or do they return roughly the same papers and/or same performance?
If they do, this has great implications for academic search.
For these examples, it might also be a good idea to use a pure Boolean keyword search engine like Scopus as a baseline and also comparison of whether a result is "good".
Another area librarians are interested in is to teach "prompt engineering", akin to how we teach people to search. As I have blogged before, unfortunately, many librarians may be just blindly copying prompt engineering strategies tested on pure LLMs (without search) and have no evidence the tactics work.
Think "role prompting" (aka "You are XYZ") works for AI search engines? Try it out with and without these magic words and study to see if the results are better! Or are they giving somewhat simlar results?
A piece of warning, again knowing a little bit about how the system you are testing works will be helpful.
For example, it might be helpful to know Primo Research Assistant, Scite assistant etc actually use LLMs to generate keyword searches which are then used in lexical based search and do not actually do embedding based semantic search directly! This might lead you to expect differences compared to something like SciSpace that does semantic search with embedding match.
Another example, we know that Undermind.ai is using agent based iterative searching, employing both keyword search and citation searching multiple times. A interesting hypothesis to consider is whether citation searching and the interactive searching will lead most semantically similar intent queries to be more similar or less similar than typical AI search.
On one hand, citation searching means for semantically similar queries it will almost always end up finding the seminal papers and possibly from there the search converges for the two queries. On the other hand, the very first papers found by Undermind is very criticial and by sheer luck , the butterfly effect of the first paper might cause the search to totally diverage between the two queries.
If it turns out that the overall performance of Undermind doesn't vary too greatly even if you know the right keywords va just normal language and still gives decent results, this supports my wild speculation that these AI search tools are the magical "Low skill cap, High performance ceiling" tools!
I also suspect no matter what results you get, it may not generalize much as right now information retrieval is in a state of upheaval and pretty much wild wild west with many ideas.
I could be wrong but compared to the past decades where most academic search systems were using Boolean, and doing relevancy ranking by BM25. there are many more options right now for "AI search".
Sure BM25 can be implemented differently, you can put different hyper-parameters for k and b, and I am sure there are many other differences and tricks like different ways to do query expansion, stemming etc but I wager in academic search they are pretty standard.
My impression is that the current standard for "AI search" tends to be something along the lines of a hybrid search with multi-stage rerankers
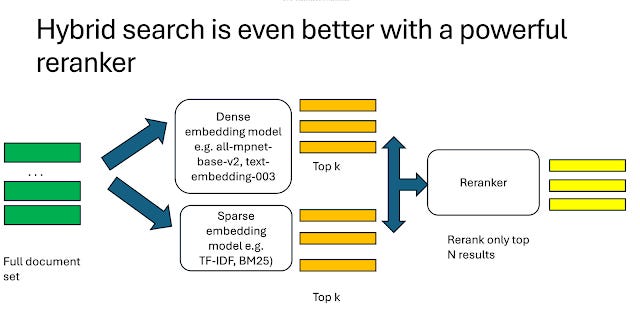
Basically the search uses both lexical and semantic/dense embedding search to get an inital pool of candidate papers then use a reranker (e.g. Cross encoder, ColBERT, GPT4 class LLM model) to rerank.
But even if AI search follows this structure, there is still quite a lot of freedom of choice, dense embeddings vary greatly based on how they are pretrained and fine-tuned, systems can give different weights to the inital first stage retrieval for lexical vs dense embedding, LLMs can be used in different ways to do query expansion, enhance documents context etc.
Any biases in search when moving to semantic search
I was looking through one registered protocol that was comparing Ai search tools and conventional databases and it was doing the usual comparisons eg comparing by discipline queries, but I was struck by a interesting hypothesis - that Semantic/neural search methods would retrieval more papers authored by males than females compared to conventional search.
That's an interesting hypothesis but is there reason to believe so?
For sure we know embeddings and LLMs being pretrained on the internet's data, pretty much learn gender stereotypes like Nurses are females etc, but I was curious to see if there is any research on whether using "neural search" (or Semantic search based on dense embeddings) exhibited bias in retrieval compared to traditional lexical keyword search.
Interestingly the answer seems to be yes at least in the type of writing,
For example, see Do Neural Ranking Models Intensify Gender Bias?, Debiasing Gender Bias in Information Retrieval Models among others
I think these papers don't actually look at the gender of the authors of the retrieved papers but at the text used (e.g. counting frequency of male related pronouns), so this is a interesting question to ask.
There's even a recent framework proposed - Does RAG Introduce Unfairness in LLMs? Evaluating Fairness in Retrieval-Augmented Generation Systems
How should we combine it with citation searching?
Traditionally there are like two major ways to search. Lexical keyword and Citation searching. Now we have a third method, semantic search.
This of course opens up a whole series of studies trying to see the value add of Semantic Search, assumng keyword & citation searching is done already for example, just as I have read many papers trying to see the value add of different variants of citation searching on top of lexical keyword search. Or trying to figure out the optimal order to use Keyword, Semantic search, Citation Searching (eg Use Semantic Search first to figure out keywords).
See also my coverage of the TACRiS statement and their suggested areas for future research.
A slight issue I think with doing this is that most of the AI search tools are using a hybrid of keyword and semantic search, so you won't get a "pure" semantic search. Still it is nice to know empirically when best to use say Elicit.
I expect our systematic review, evidence synthesis people will be studying this types of things.
Other ideas - more qualitative
Another area to study would be user perception of such systems. We librarians always worry that with semantic search, boolean matching will go away. Do users care as much? Do they even notice? I find sometimes the fact it isn't doing boolean matching irriating but sometimes not.
Compared to traditional keyword search systems do these systems change user search behavior in other ways? Do they do more or less iteration of search? Do they enter more keywords? Do they look at more results?
Many many questions....
Conclusion
Not sure how useful any of this is, but as you can see AI search tools open up so many interesting questions, more than enough to occupy researchers for years...