
Can Semantic Search be more interpretable? COLBERT, SPLADE might be the answer but is it enough?

Can Semantic Search be more interpretable? COLBERT, SPLADE might be the answer but is it enough?
Update : As of June 2024, Elicit has announced they are "working on": Sparse Lexical and Expansion (SPLADE) model,
In my earlier blog post, I described a simplified description of a framework for infomation retrieval from the paper - A Proposed Conceptual Framework for a Representational Approach to Information Retrieval,
I followed up with another blog post, that went deeper into the differences between Sparse retrieval methods that generally involve the use of Sparse embedding/representations (almost always bag of words approach) vs dense retrieval methods that generally use dense embedding/representations.
A typical traditional example of the former was BM25, while a typical example of the later is a bi-encoder model.
This second blog post went in depth into the strengths and weaknesses of sparse vs dense.
https://arxiv.org/pdf/2307.10488
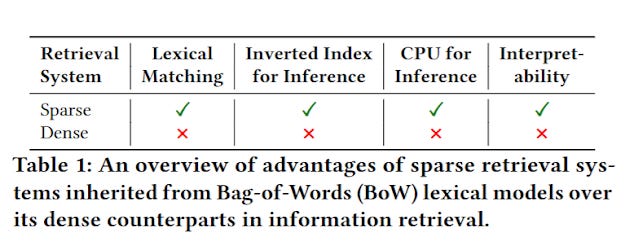
To summarise, sparse methods of retrieval which typically uses inverted index (as opposed to vector stores used by dense methods of retrieval) tend to be less computational taxing and run much faster leading to much lower latencies.
We also had a long discussion on the pros and cons of sparse methods of retrieval vs dense methods of retrieval. While the former, struggles to overcome the typical problems of vocabulary mismatch issue, and lacks the "semantic matching" capability of the later (which shine particularly for long natural language queries), there are situations where doing a straight lexical string match is important (e.g. search for specific entity name). and how in practice most systems use both methods and combine the results (e.g using Reciprocal rank fusion (RRF)) or by reranking using more accurate but computational expensive techniques like cross-encoders afterwards (hybrid search).
We also discussed how traditional dense embeddings are actually "learned" dense embeddings, they are not only pretrained with strings of text, but they are specifically fine-tuned with query-document pairs (query matched against relevant and non-relevant documents), and this helps explains why such dense embeddings tend to do very well with in-domain queries (queries in the area they are fine-tuned on), but when tested across a broad spectrum of domains, the average result struggles to match BM25 which is not specifically fine tuned on any domain.
But in this blog post, the key issue we are going to discuss is the lack of interpretability of explainability of dense retrieval methods vs sparse bag of words approaches.
Transparency vs interpretability
I've seen some librarians complain that these AI powered, vector/embedding/neural search lack transparency because we do not know the exact algo used for ranking.
To be honest, I have always struggled to understand this. People use Google, Google Scholar, various academic databases. Is the algo for ranking all known? Yet we use them.
More importantly even if the algo is mostly known such as PubMed (boolean match, followed by sorting using BM25 and Learning to rank algo trained on clicks is used reorder the top 500) does it really help the librarian explain why the results are the way they are?
There's a lot to discuss here, for example are you using boolean to retrieve documents and then do relevant rank using an algo in which case transparency of algo is less of an issue, since you can ignore the not so transparency algo and just bulk download all hits (I assume this is allowed).
Or are you not using boolean and just retrieving directly with BM25 or worse a bi-encoder?
Reminder : BM25 does not guarantee that all the terms in a query will be in the top set of document retrieved (it is not an "implict AND"). That said, many standard academic search database implementations do combine a boolean search with BM25 ranking but this is not true for all academic search engines e.g. Google Scholar.
I will leave these complications to another blog post, but it's clear that even by the most minimal standard, using Bi-encoders/dense retrieval methods to retrieve and rank results is problematic, particularly when the typical search leads to thousands of hits.
This is because by the very nature of dense retrieval, even if we knew the exact algo, the results are not easily interpreted or explained.
In short, even if we knew the exact algo details, we will not be able to understand WHY a document is retrieved (if it is used directly for retrieval), or why it is ranked higher or lower.
In Computer Science terms, we say the algo is not interpretable or explainable. Why is this so?
Conventional Bi-Encoders results are not interpretable or explainable
https://blog.vespa.ai/announcing-colbert-embedder-in-vespa/
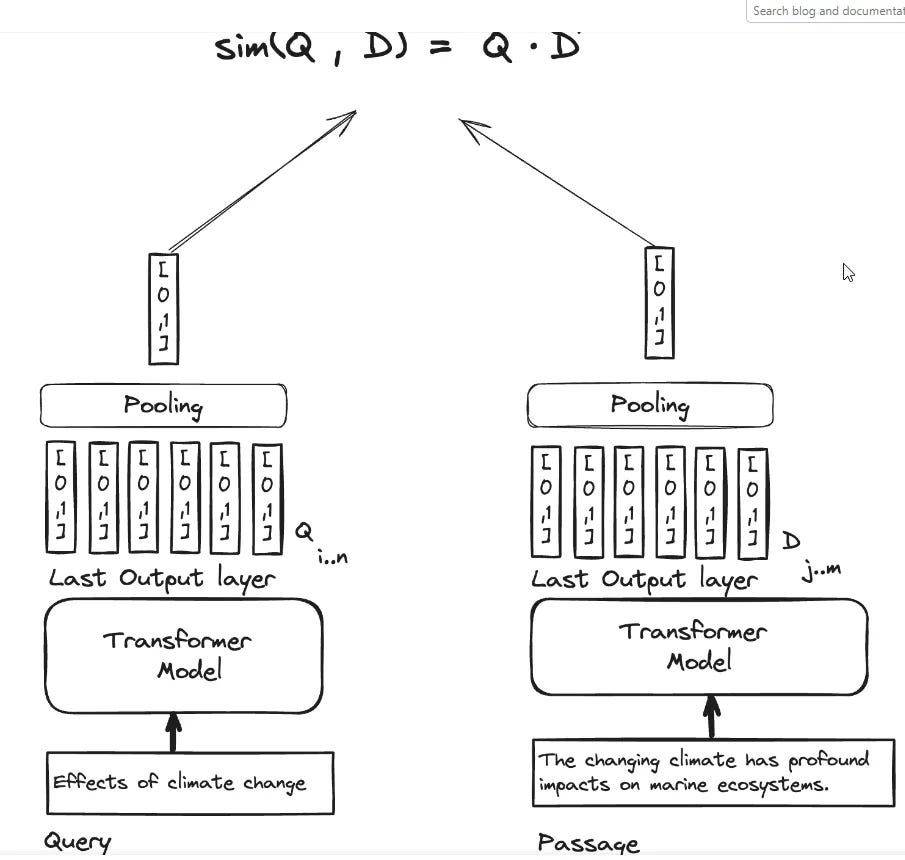
For bi-encoders, when working on document representations, while you initally convert each word or token into a seperate embedding (set of numbers) - one for each token, you eventually "Squeeze" them all into one overall embedding that represents the whole document by "pooling" (a type of averaging)
The same thing happens to the query (but in real-time rather than being precalculated), and each query term is converted into seperate embeddings before being averaged into ONE overall embedding representation that represents the whole query.
This overall embedding of the document and query is then used by comparing each other with a similarity metric (typically dot product, cosine similarity etc) and the documents are ranked by these scores.
Essentially the score you get say cosine similariy score between a query and document embedding is just a measurement of the overall "Aboutness" of the query (proxied by the average of embedding of words in the query) and aboutness of the document (proxied by the average of embedding of words in the document).
No-one not even a leading expert in Information retrieval can tell you WHY a document is ranked high or low. All they can give you is a score and say it shows the aboutness of the query representation and the document representation is high.
How can we make semantic search more explainable/interpretable
When you think about it, Boolean or even BM25 is more "explainable" because we can see the components of the scoring.
With Boolean we can see exactly which keywords match.
With BM25, the score is from a more complicated formula but with some study, we can intutively understand that if the term frequency of a document is high it should be ranked higher, if the term matched is rare in the whole document corpus (IDF or inverse document frequency) it should be ranked higher and with adjustments for term saturation and document length.

With the bi-encoder, all you get is one embedding for the document and one embedding for the query, you do not get token or word level information.
Essentially the score you get say cosine similariy score between a query and document is just a measurement of the "Aboutness" of the query and the document.
The question is can we get the power of semantic search via dense embedding but with the greater transparency of lexical keyword methods?
One of the earliest and most popular methods is ColBERT algo.
Why ColBERT is more interpretable
ColBERT stands for contextual late interaction and in terms of performance lies somewhere between Cross-encoder and Bi-encoders.
In the last blog post we talked about cross-encoders vs bi-encoders
From Multi-View Document Representation Learning for Open-Domain Dense Retrieval
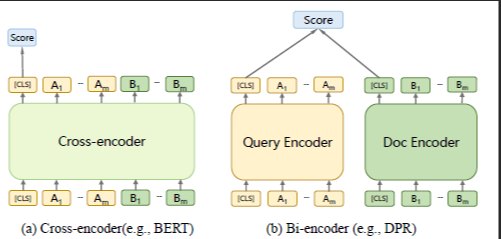
Unlike in the case of the Bi-encoder when you encode the query and document seperately and then use a comparison function to compare the two representations (typically using cosine similarity or dot product of the two embeddings), in a cross-encoder, you enter both query and document into the same encoder (e.g. BERT) at the same time, which will then output a score on whether the document is relevant to the query or how relevant the document is (score).
Empirically cross-encoders provide far better performance than bi-encoders, which makes sense because Cross-encoders captures interactions between tokens from the query and tokens of the document while Bi-encoders only take the overall embedding (shown as [CLS] in the diagram) as opposed to token level embeddings of the query and doc to do a comparison.
Of course, Cross-encoders have a huge drawback. Because of the way it works, where you need to feed query and documents into the same encoder, you can only do this in real-time and unlike bi-encoders you can't preindex the document, making it impossible to do so for large document sets!
The idea of ColBERT is roughly to be in between Bi-encoders and Cross-encoders.
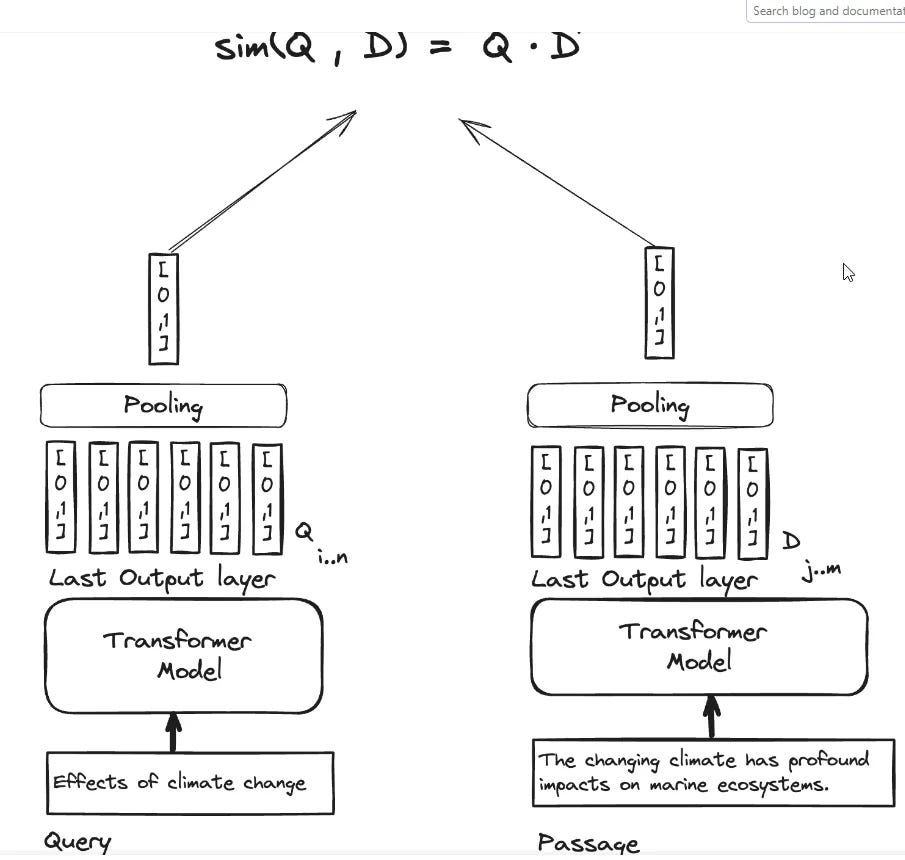
For Bi-encoders, we store one embedding for each document, after pooling or averaging all the embeddings of the tokens in each document.
https://blog.vespa.ai/announcing-colbert-embedder-in-vespa/
The idea behind ColBERT is instead of pooling all the token embedding into one overall embedding why not store and compare the embeddings of each token by token and use them for comparisons...
This is also sometimes call a multi-vector representations approach as opposed to a single-vector representation approach, when there is just one vector or embedding to represent the query or document.
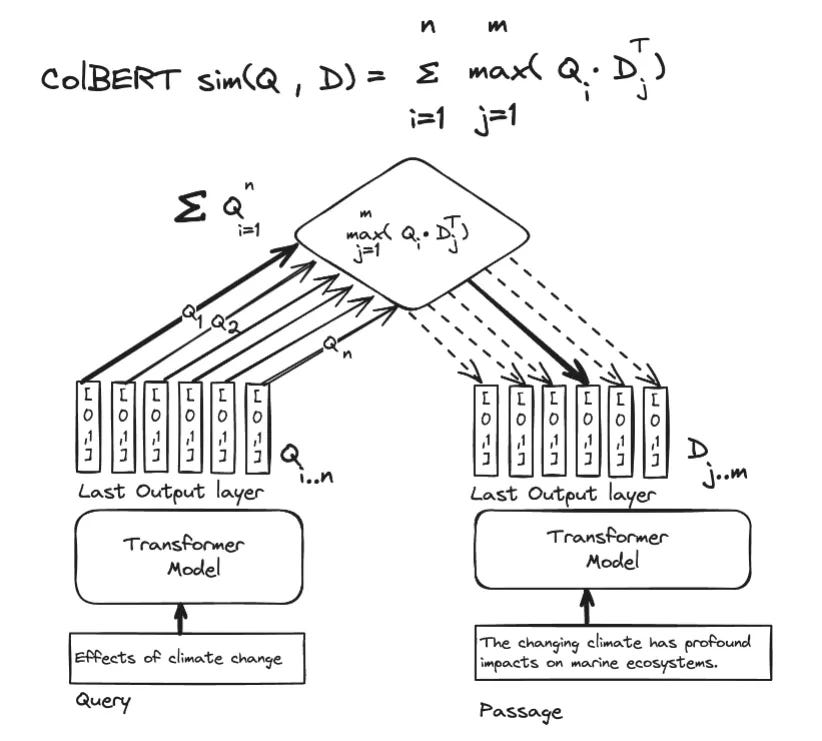
https://blog.vespa.ai/announcing-colbert-embedder-in-vespa/
How do these token embeddings interact? They use a function called MaxSim, I believe the algo works like this.
1. Take the first query token embedding
2. Calculate the cosine similarity of the query token against each of the token embedding in the document we want to score
3. Keep the cosine similarity with the highest score between the query and document token.
4. Repeat with the next query token embedding
5. When done, sum up all the scores for the overall score a document has scored against the query.
Still unsure?
So here's a over-simplified example.
Imagine your query has 4 tokens - "Open", "Access", "Citation", "Advantage" and you trying to match a document with say the tokens, "Open", "bibliometric", "meta-data", ...
For, the first query token "open", calculate the cosine similarity vs document tokens "open", "bibliometric", "meta-data" and ...., likely the highest score will be for "open" (since it matches exactly), Say the score is 0.7
Continue for the other query tokens. e.g. "Citation" and "bibliometric" might have the highest cosine similarity say 0.5.
Then MaxSim is just the sum of these cosine similarities.
Why ColBERT is popular
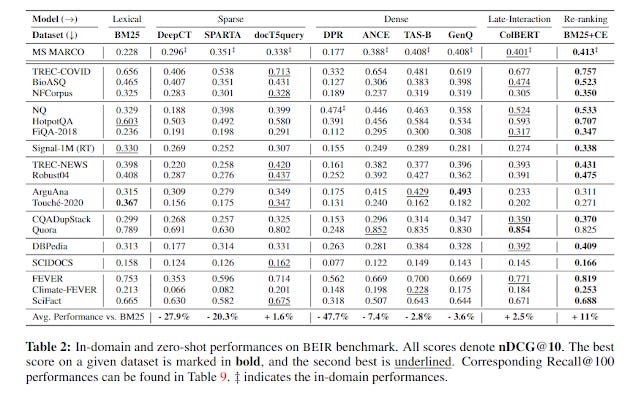
From 2021 paper - BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models
I suspect ColBERT is popular not because it is more interpretable but mostly because it gives better results. For example, in the above image of BEIR test results, it is one of the few algos that beat basic BM25 on average across all domains!
Compared to bi-encoders it tracks similarities at the token level instead of the document level, which leads to better performance. This makes sense, because trying to describe the "aboutness" of one document with just ONE embedding is tricky as there are likely multiple ways to describe what a document is about.
The other thing about COLBERT of interest here is that you can now have better insight on why a document got the score it got because we can "see" the token interactions. In, particular we can see like in the above example, the document scored high because the query token "citation" was "matching" the document token "bibliometric".
Vespa has even implemented a interface that you can use to help with ColBERT scoring interpretability

Here's another visualization
While the MaxSim operation only considers the maximum similarity score of document tokens for each query token to calculate the final document similarity score, in the visualization below, included is not only the maximum document token per query token but also a few other tokens with nearly as high similarity scores, to help give a clear picture of which document tokens are important
https://www.linkedin.com/pulse/guidebook-state-of-the-art-embeddings-information-aapo-tanskanen-pc3mf/

https://www.linkedin.com/pulse/guidebook-state-of-the-art-embeddings-information-aapo-tanskanen-pc3mf/
ColBERT itself has drawbacks. Compared to Bi-encoders, it is obviously more expensive to implement. You need to store more embeddings (one for each token, instead of one for each document) and during inference time, doing MaxSim, or multiple cosine similarities is more expensive and slower.
In fact, later versions of ColBERT e.g v2 mostly focus on technical tricks to speed up implementations.
Learned sparse embedding - interpretable by design
ColBERT is a dense retrieval methods (though it has been classed by some as a hybrid method) that is more interpretable but there are other approaches.
One idea that is now popular is to build on and improve lexical or sparse embedding/spare retrieval methods which are already interpretable by design.
As mentioned earlier, Sparse embeddings have many virtues over dense embeddings, they tend to be faster and easier to implement (inverted indexes are well understood) and run faster at inference time.
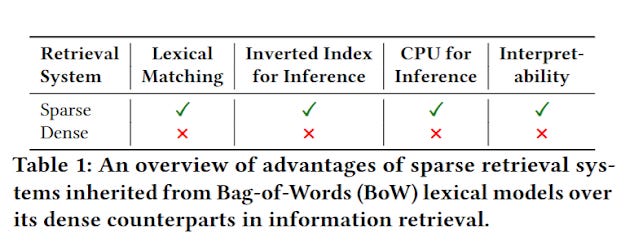
https://arxiv.org/pdf/2307.10488
You get the strengths of lexical match which is by default more interpretable. It's just a pity that traditional lexical search techniques using bag of words like BM25 can't do semantic type matching and run into the vocabulary mismatch issue.
Can we use the framework of sparse embedding used in an inverted index, but somehow learn the weights or values rather than using heuristics like TF-IDF/BM25?
This is indeed been what researchers have been doing with the recent development to explore the idea of fine-tuning or doing supervised learning on sparse embeddings to boost performance.

Another way of looking at it is, instead of starting with dense methods of retrieval like ColBERT, from the other direction, researchers are experimenting with learned Sparse retrieval representations , which lead to methods which are more interpretable but with guidance from dense retrieval techniques to gain the "semantic matching" performance gains.
Examples include (EPIC, COIL, TILDEv2, DeepImpact, SparTerm, SparseEmbed,etc) but with SPLADE (SParse Lexical AnD Expansion) currently being the most popular and promising.
Update : As of June 2024, Elicit has announced they are "working on": Sparse Lexical and Expansion (SPLADE) model,
This blog post provides a simplified explaination
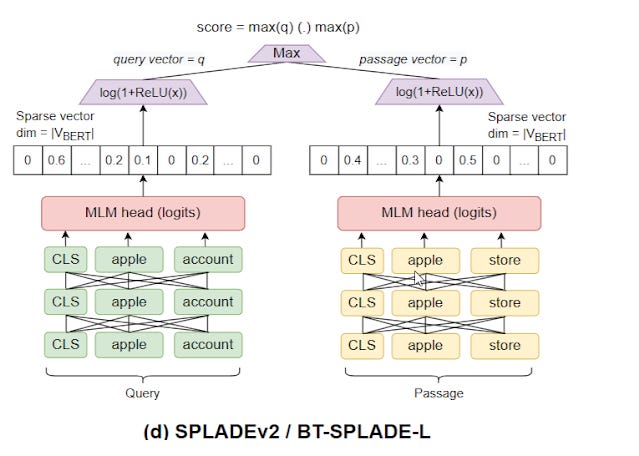
Instead of matching documents and queries in the non-interpretable BERT vector space, SPLADE aims to properly match documents and queries by finding the appropriate term (and weights) for the sparse representation. So, how is the model able to learn this mechanism?
In short, use BERT type methods to learn embedding for sparse representation/bag of words model.
At the heart of pretrained language models like BERT is a component called the MLM head. To enable prediction of the correct words in a sentence context, BERT is pretrained on sentences where words have been blanked out. The MLM head is in charge of mapping the latent continuous representations of words back to the full vocabulary. Most work that uses BERT discards this MLM head and readapts only the continuous representations. In our work, we take inspiration from SparTerm and EPIC (6, 7) and reuse the MLM head to predict expansion: each word representation from a document/query is mapped to the vocabulary, giving an estimation of the importance implied by the term itself for each vocabulary word. This also means that we work in the BERT vocabulary space with a WordPiece tokenizer (i.e. a space with 30,000 different sub-words, which is much larger than the 768 dimension of BERT embeddings)
This basically says once you finish training a BERT model with sentences with words blanked out , there is a MLM head or classifer that gets very good at coverting the embedding representations back to words. Typical bi-encoders methods just throw this away and use the overall weights that have been trained.
SPLADE like many methods similar to it, uses this MLM head to help predict when and how to expand. They use the BERT tokenizer method, so this means 30,000 "words/tokens" are it's vocabulary. (technically BERT WordPiece tokenizer like most tokenizers do not convert one word to one token, but it uses "subwords").
There is one final step called regularization
Unfortunately, representations obtained this way are not sparse enough, so it isn’t immediately possible to build an inverted index. In (6), the authors propose using a second model to learn which words to keep in the representations, but it wasn’t possible to do this in an end-to-end manner. In SPLADE, we propose simply adding regularization constraints on representations when training the model. We use the FLOPS regularizer—introduced by Paria et al. in an ICLR 2020 paper
This ensures that the representation obtained is sparse enough to be used in a inverted index. There is of course, a trade-off here (the more sparse, the lesser performance but faster latency), but in general they are able to reach State of art results even with high efficencies.
SPLADE in action
Still confused? At the risk of oversimplifying, the problem with traditional keyword or lexical search methods is that it is hard to solve the vocabulary mismatch issue. Query expansion methods help, but it's hard to know when and how to expand.
On the other dense retrieval methods, can be costly to implement compared to inverted indexes, and lack interpretability and the desirable properties of bag of word models to do exact-match of terms.
Can we combine the two?
SPLADE essentially uses BERT type methods to learn how to
(1) expand and how to remove existing terms
(2) how to weight each word/token.
But this is done in the framework of a traditional inverted index, so each of the weights in the embedding is interpretable.
In the example below, when you enter a query, the standard binary BOW (Bag of words) would just put a 1 in the appropriate values (this is one hot-word encoding scheme). Of course, you can put in weights based on TF-IDF, BM25 but these are still heuristics made up by people rather than learnt directly from the text.
SPLADE (and other similar methods), learn the weights in a very similar way to standard BERT style techniques but then use various methods to distill/project or push it back into a traditional bag of words system,
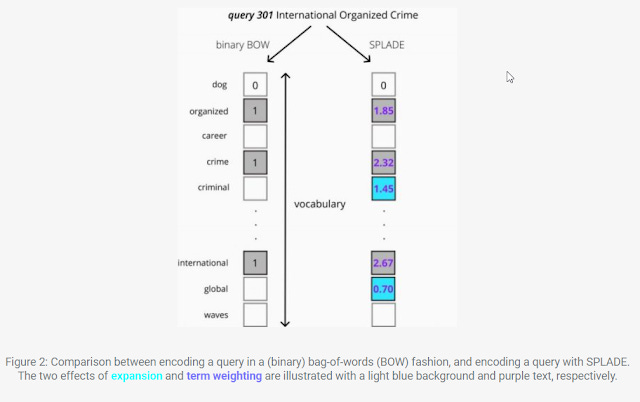
In the example above, you can see once trained, SPLADE, not only sets weights based on the query term "International", "organized", "crime" but also automatically expand to include "global" and "criminal".
The same happens for the document representation where SPLADE will not just weight the words in the document but include or exclude other words.

The example above shows that SPLADE isn't perfect at expansions, with some poor choices like "teeth", "arrow". This paper tries to explain why.
Some more papers to consult on learned sparse embedding
SPRINT: A Unified Toolkit for Evaluating and Demystifying Zero-shot Neural Sparse Retrieval
Towards Effective and Efficient Sparse Neural Information Retrieval
Improving document retrieval with sparse semantic encoders (opensearch)
Interesting results from COLBERT & SPLADE
There are many papers that probe ColBERT and SPLADE to try to understand what is going on. Here are some interesting ones
A White Box Analysis of ColBERT - studies weights of term importance in COLBERT vs traditional BM25 (IDF) and shows that it is correlated except when IDF>8 . Exact matches become more important when the word matched is relatively rare (high IDF). Low IDF tokens e.g stop words carry less information and are more heavily influenced by their context and are less important to match.
studies reproducibility and replicability of different versions of ColBERT. Also finds that ColBERT variants does semantic matching mostly on low IDF tokens and stopwords tokens. This agrees with the earlier paper, by implying that lexical matching is done mostly on mid to high IDF tokens
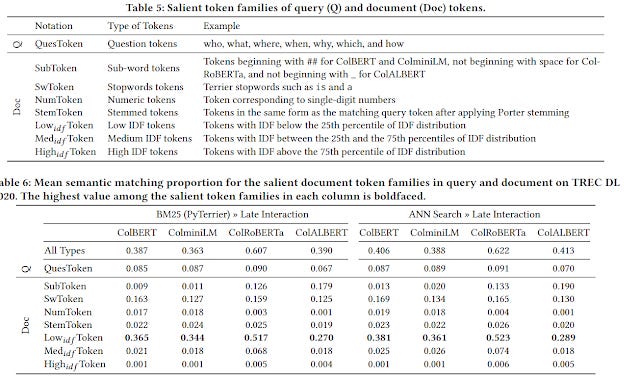
They also try calculating the performance by changing the ColBERT matching function to be using lexical matching only, semantic matching only , special token matching only vs the full matching all types method.
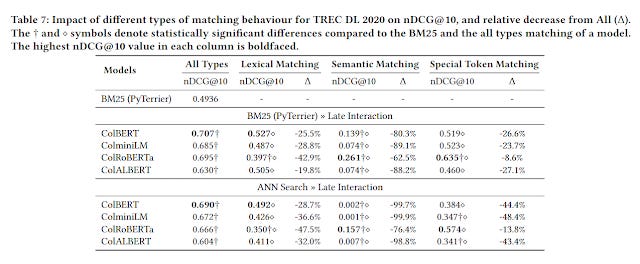
They find obviously, performance drops versus the full matching all time method, but between lexical matching and semantic matching, lexical matching is more important.
Conclusion
This has been a very deep dive into state of art dense and sparse retrieval models. While ColBERT and learned sparse representations like SPLADE are more interpretable than standard bi-encoder dense retrieval models, they are still less interpretable than outright Boolean.
This is because while ColBERT and SPLADE can allow you to interpret the results from a query after the fact, you cannot predict the results in advance.
For example with SPLADE, given a certain query, there is no way to predict in advance what words will be extended, or words removed (compressed) and the same holds for the document representation.
Similarly for ColBERT while you can see the token to token interactions, these are still compared using cosine similarity, which cannot be predicted in advance which query token to document token will have highest sinilarity unlike straight forward lexical matching!
Is this acceptable for most librarians? Is it acceptable for systematic reviews?