ChatGPT Plus - new DALL-E 3 (image creation) & Vision (image recognition) capability - A quick overview & why I am disappointed.

On September 2023, OpenAI announced that ChatGPT Plus would be enhanced in three ways
1. It would allow you to speak directly with GPT and it would also be able to reply in voice
2. It would be able to create images using DALL-E 3, OpenAI's image generation model
3. It would be able to accept image inputs
Since I finally gained access to these features, I will briefly review them with my thoughts on how impactful they might be for library work. To anticipate, the conclusion, these features are very powerful but yet I am disappointed. Because each of these abilities are unlocked separately and cannot be combined. In other words, this is still not what I consider a true multi-modal model that can accept input in multi-modalities (eg text, audio, images) and output formats (eg text , audio , images)
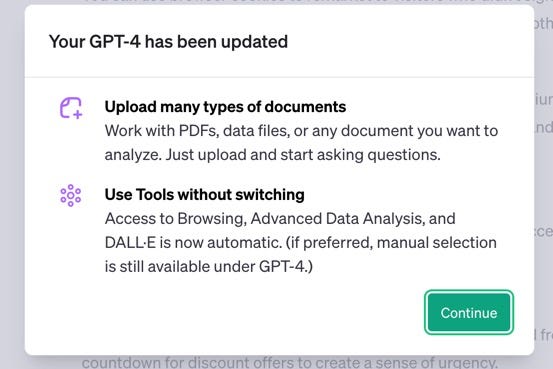
Update Oct 30th 2023 - Just about 10 days after I blogged this, OpenAI announced an update that allows you to upload different docs and access to browsing, advanced data analysis and DALL-E 3 capabilities all without switching modes. In other words, this makes it closer to a real multi-model model....
Note: There's a "new" - Browse with Bing feature as well. I put new in quotes because ChatGPT Plus came with at least two earlier versions of this plugin that enhanced ChatGPT with results from the web. The second version also based on Bing was taken down earlier this year because people found a way to use it to bypass paywalls.
My quick tests show it is nothing special, we have been playing with similar features in Bing Chat, Perplexity.ai (and of course my blog charts the progress of academic search engines that use RAG), and there's nothing that suggests Browse with Bing is notably superior.
1. It would allow you to speak directly with GPT and it would also be able to reply in voice
I don't have full access to this capability, my Android ChatGPT app allows me to talk to it (with very high accuracy - based on Whisper?) but it does not respond back in voice.
This capability is probably the least impactful in my view since we had smart assistants for a while now with pretty good voice recognition. That said these smart assistants were always dumb in the responses they gave so perhaps it will feel totally different if they respond intelligently with voice!
For example - Tim Spalding is very impressed by the voice feature saying it gives "Jarvis vibes" and is comparing it to the first time he used a Mac, Gopher and World Wide Web and even ChatGPT itself!
The new “Voice Conversations” on the ChatGPT app is… well, I think this goes up there with the first time I used a Mac, Gopher, the World Wide Web, and ChatGPT itself. Serious Jarvis vibes.
— Tim Spalding 🇺🇦 (@librarythingtim) October 8, 2023
If he is correct, and he is a very smart dude on such matters, once such technologies are in smart assistant/homes, we will be amazed.
2. It would be able to create images using DALL-E 3, OpenAI's image generation model
When OpenAI first launched DALL-E in 2021 and DALL-E 2 in 2022 people were amazed. This were two ground-breaking text to image generators.They were quickly followed by competitor's such as Google's Imagen (against the original DALL-E) and Stable Diffusion and Midjourney (against DALL-E 2).
In particular, Stable Diffusion grabbed a lot of attention by being available Open Source and in terms of capability Stable Diffusion and Midjourney (commercial) among others seems to have improved rapidly to surpass DALL-E 2's capabilities.
I have been particularly impressed by Stable Diffusion's capabilities including text to image, inpainting and outpainting. (try free here), though it might be some of it's capabilities comes from the fact that Stable diffusion is trained on an extreme number of images scraped from the web and has less guardrails to prevent 'unsafe' images from being generated.
However, OpenAI has finally struck back with DALL-E 3, and it claims to nail one of the last weaknesses of text to image generators. Up to this point, you could describe an image and these tools would be pretty good at understanding what you want, but if you asked it to create an image of something with the words "Happy Birthday" at the bottom, most of them would fail terribly at generating the words.
To use DALL-E 3 in ChatGPT Plus you need to select a special mode - DALLE-3
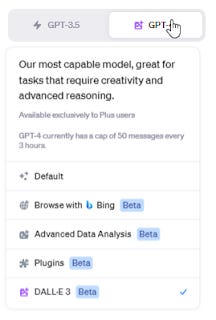
I did a couple of tests using the prompt -
"Draw a picture of a Terminator robot from the moves face to face with a human librarian At the bottom are the words "AI vs Human" and repeated it twice. This is what ChatGPT with DALL-E plugin shows.
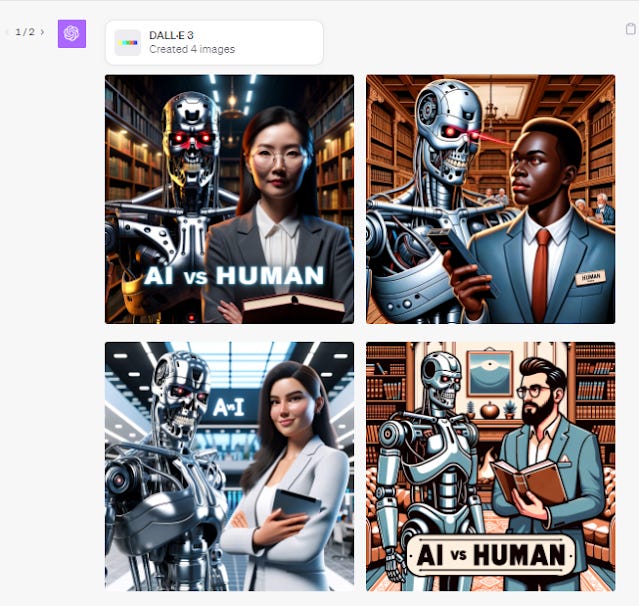
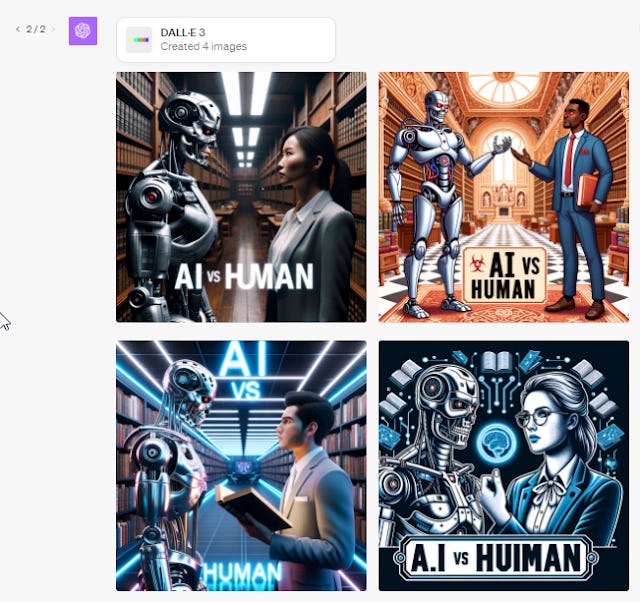
The results are not perfect, in the first batch of four, two don't even have the words! In the second batch of four, they all have the words, sort of anyway. The last one for some reason misspells it as HUIMAN. Still the fact it gets it sometimes right is impressive since most other image generators will totally fail most times.
Because DALL-E 3 is now invoked via ChatGPT (or Bing Chat), you can modify the images using natural language. For example, you can ask it to change a male to a female or replace the terminator with a demon and it understands very well.
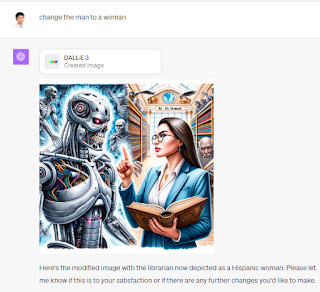
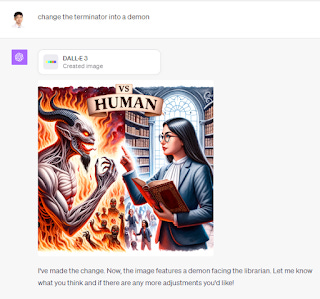
To be honest this wasn't the feature I was very excited to get in ChatGPT plus, because I had already tested the same function which you can get free via Bing Image Creator which is powered by DALL-E 3 and the results were similar.
Also, while being able to specify text to add is cool, it isn't particularly difficult to add text labels to a generated graphic.... Though I suppose one possible workflow would be for the system to summarise a paper , the use that summarise to try to create a Scientific Poster or Visual abstract. But so far, I am not successful.
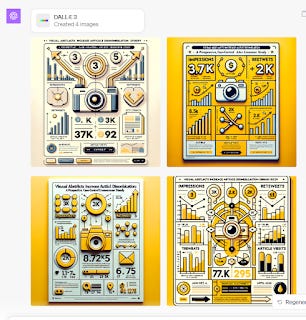
For fun, I tried uploading a simple visual abstract to ChatGPT and using its vision capability it described the visual abstract. I then fed it to DALLE-3 to create the visual abstract. The results were weird...
For example, while it could describe the following simple visual abstract well.


Feeding the same description to create a visual abstract with DALL-E 3 leads to weird results.
Stable Diffusion I think is still more capable in some ways than DALL-E-3 because it is less filtered. For example, you can easily create photos based on celebrities or even create faces that are 20% celebrity X and 80% Celebrity Y, while Dall-E-3 will refuse to generate images of any individuals.
The image data that Stable Diffusion trained on is very broad, it even includes an image of me! For example, based on the "Have I been trained?" database, there is at least one photo of me included!
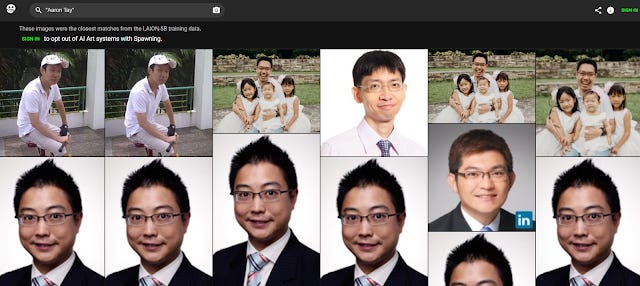
Fortunately, or unfortunately there are far more photos of other "Aaron Tay", so when such systems try to generate a prompt with input "Aaron Tay" it is unlikely to get an image close to me (though it will likely generate Chinese facial features). For celebrities it pretty much nails it of course since almost all the training images will be of their likeness (try say Angelina Jolie)
DALL-E 3 when used via ChatGPT plus also has a host of other restrictions, if the system prompt here is accurate other restrictions include instructing the model to
not "create images in the style of artists whose last work was created within the last 100 years"
not "create any imagery that would be offensive."
"Silently modify descriptions that include names or hints or references of specific people or celebritie by carefully selecting a few minimal modifications to substitute references to the people with generic descriptions that don't divulge any information about their identities, except for their genders and physiques"
3. It would be able to accept image inputs
This is probably the function that is getting the most attention right now. This gives ChatGPT the ability to understand images you upload.
Image understanding is powered by multimodal GPT-3.5 and GPT-4. These models apply their language reasoning skills to a wide range of images, such as photographs, screenshots, and documents containing both text and images.
People are really impressed by this capability and so am I. For one, it can read screenshots of English test, figures, tables from papers. This is clearly going to be useful for interpreting papers.
Twitter/X is full of amazing examples, here I try an example by uploading a visual abstract created by my colleagues.

This is what ChatGPT with vision sees.

I tried a few more examples of visual abstracts and it is not perfect but still impressive
Okay I tried this visual abstract on GPT4 vision. It has trouble understanding that there is an icon for RCT and Population based Cohorts. It thinks that double arrow icon means < (less than) , (1) pic.twitter.com/K9b6n5r4M1
— Aaron Tay (@aarontay) October 16, 2023
I asked GPT4 for the 95% CI for intubation, at first it correctly refused saying it isn't labelled. I ask it to estimate anyway and it basically makes things up (multiple tries) - (2) pic.twitter.com/4ZTAvAvyFQ
— Aaron Tay (@aarontay) October 16, 2023
A true multi-model Large Language Model will be amazing
Despite all the amazing new capabilities, I was still somewhat disappointed because each of these capabilities can only be used seperately.
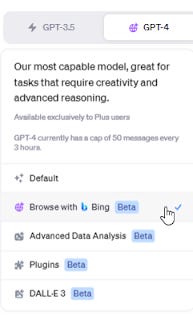
By default, when you start a prompt in ChatGPT you must choose from the following options
Each of these modes are mutually exclusive. There's isn't a mode you can choose for uploading images, but it only appears when you choose "Default"
Option to upload image only appears if you select default GPT-4 mode. Any other mode this option is not there
This is such a shame, because I was looking forward to combining ChatGPT's new vision capabilities with the existing "Advanced Data Analysis" capabilities (formerly known as Code Interpreter).
As I covered in past post , this is the mode that adds a "Code Sandbox" for GPT.
OpenAI describes it as
We provide our models with a working Python interpreter in a sandboxed, firewalled execution environment, along with some ephemeral disk space. Code run by our interpreter plugin is evaluated in a persistent session that is alive for the duration of a chat conversation (with an upper-bound timeout) and subsequent calls can build on top of each other. We support uploading files to the current conversation workspace and downloading the results of your work.
This mode also allows you to upload all types of files including csv, text, Python scripts, PDFs. It is then capable of running code in the Code Sandbox to extract information about the files you upload.
In the earlier blog post, I uploaded a zipped file of a research dataset that was already deposited into our data repository and asked it to analyse the files.
In particular, I ask it to interprete the files uploaded and suggest ways to improve the quality of the deposit.
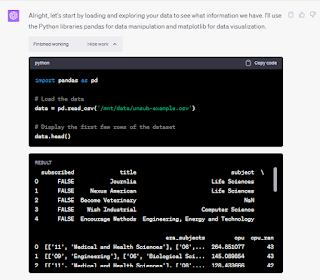
Using its python interpreter, it could load csv files of codebooks, data files and handle it pretty well.
However, when it comes to images (figures) or PDF, it has to use Python libraries to try to extract the text with uneven results to 'see' what is in there.
It seems to me if the newest image/vision recognition mode was included into this mode, results would be much better!
Similarly, the ability of ChatGPT Plus to interpret image and draw images are two separate modes that currently can't be combined.
In other words, you can upload an image for it to be described but you can't then use DALL-E 3 to edit it. This is a surprising weakness since other competitors like Stable diffusion do allow this.
All in all, I expect when LLMs are truly multimodal and can accept input in different formats (e.g. text, audio, images, video) and generate output in diff formats (e.g. text, audio, image , video), we going to have even more wild use cases.
Imagine uploading a zipped file of different data formats and asking it to analyse then amend and generate analysis in anything from text to image to videos! The possibilities are endless from writing/editing a paper, creating a short summary of a paper in a poster , video etc.
True multmodal language models are rumored to be coming next in Google's next generation large language model -Gemini (due 3Q/4Q 2023), so we shall see what the future brings...
Also see the latest GPT4 update@ 30 October 2023/