
Citation based literature mapping tools - an update - tools offering premium accounts, the effects of the loss of MAG and use for evidence synthesis?

I've been writing about the rise in availability of open Scholarly metadata (in particular Open Citations) as far back as 2018 and how they might impact academia.
Clearly, the readily availability of open scholarly metadata (which is also related to PID providers and academic knowledge graphs) and to a lesser extent full text has led to the rise of numerous tools designed to exploit such data.
It is pretty difficult to classify these new tools since they overlap quite a bit plus a lot more research tools in more specialized areas like evidence synthesis support or not quite in my wheel house. But here's my best attempt to classify.

An easy to predict outcome is that it becomes easier to create new citation indexes by organizing leveraging such open metadata and indeed we do see some new citation indexes (e.g. Lens.org, Dimensions) emerging based on or building on open metadata made available from the likes of Crossref and Microsoft Academic Graph.
Similarly existing Science Mapping tools like VOSviewer, CiteSpace, Harzing's Publish or Perish took note of the availability of sources beyond the traditional Web of Science and Scopus and started to support sources from all these additional open sources.
A somewhat harder to predict development was the rapid emergence of a new class of products I have dubbed "Citation based literature mapping tools".
BTW I am horrible with coining of names, so I am not totally committed to this terminology, if anyone can come up with a better name for this class of products, I would be happy to consider following along.
They tend to have the following characteristics
1. They tend to be web-based services which are linked with and use openly available citation indexes or academic knowledge graphs such as Crossref, Semantic Scholar Academic Graph, Microsoft Academic/OpenAlex. This connection can be via the use of an API (light weight and cheap but can be slow to query) or via the service downloading the data in advance and using it locally (faster, more flexible but might have update delays).
2. User enters one or more "seed" papers that are relevant. These seed papers can be entered in a variety of ways, most commonly via imports of BibTex/RIS or by searching for papers in the connected citation index/academic knowledge graph. Some even feature auto-sync functionality with Zotero's collection.

Adding seed papers by searching connected citation index in Research Rabbit
3. Based on the "seed" papers entered, the system will use algorithmic methods typically based on bibliometric techniques to recommend relevant papers. A typical example is a tool that use the seeds paper you enter to look for candidate papers within 1 or 2 citation hops and then rank the candidate papers based on citation based metrics (e.g. cocitation, bibliometric coupling). Visualizations are also often used in the output to help the user see connections between existing seed papers or candidate papers to add. Most of these tools now allow you to iterate the process, or provide alerts, helping you build up a map of your literature review
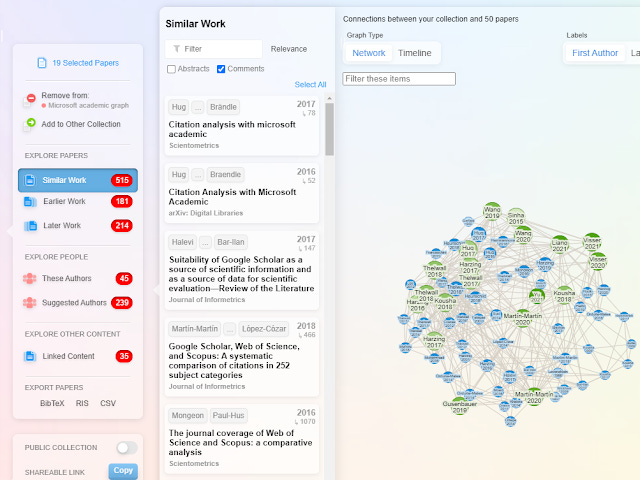
ResearchRabbit tool shows connections between existing seed papers and candidate selected papers visualization
Examples of such tools include Citation Gecko, Connected Papers, Research Rabbit, Inciteful, Litmaps and more. All these tools except Citation Gecko only emerged in 2020 or later , so all these tools are in their infancy.
They come from a variety of sources, from startups to researchers who are just experimenting, this explosion of ideas and tools only became possible because academic metadata on such a large scale (rivalling or even exceeding traditional citation indexes like Web of Science) was made available under open licenses.
I call these tools "citation based literature mapping tools", because most of them use only citations to make recommendations/cluster etc. It's not 100% clear since these tools don't always document how their techniques work, but that said I think a very few of these tools do use NLP based techniques for text similarity of title/abstract etc (e.g. Litmaps does title similarity, and it's unknown how many others do it because the algo isn't always transparent).
Unlike citations, the availability of machine readable Open Abstracts much less Open Full text is still lagging behind, which explains partly why citations-based techniques are still more common and predominant in the existing tools.
Tools that work primarily on textual data (full text or abstracts) do exist such as Yewno, Iris.AI and to Elicit.org etc but they are harder to scale and I suspect require more computational power even if the data is available.
The older class of tools, Science mapping tools like VOSviewer, Citespace, Bibliometrix are very closely related but can be distinguished.
The newer tools are designed to support researchers for their literature review with some even taking aim at supporting systematic review rather than for bibliometric reviews and as such tend to be more user friendly and have much less bibliometric jargon. While you can import many seed papers at one time for some tools, the intent is to start from a small set and slowly branch out from ground up.
In contrast, Science mapping tools tend to take a higher level view to help the user see broad trends and bibliometric patterns in an area and as such you tend to start by importing a fairly large (at least 50-100) set of papers found by a keyword search in Web of Science or Scopus. It also takes a bit more work, since you must use a separate tool to export results into the science mapping tool (though recently many Science mapping tools like VOSviewer have added API support that helps avoid this).Science mapping tools also generally expose a kitchen sink of options for analysis and visualization compared to their new cousins that typically have only a small number of carefully selected features.
I have reviewed this class of products on and off with my last update blog post a year alone in June 2021. What has happened since then?
Impact of MAG
I continue to update my list of such tools on this page, and since then I have added new tools including Citation Tree and Pure Suggest
The biggest impact though was the sudden closure of Microsoft Academic Graph on Dec 30 2021. Given that this was by far the largest source of open academic metadata, tools in these class of products that relied on MAG as a source had to scramble to find replacements.
Because MAG data is open data, prior data collected can continue to be used, however if the tools uses MAG as the only source of data or is the primary source, there is obviously a need to look for a replacement source for newer data.
The ones worth considering seemed to be Semantic Scholar - now known as Semantic Scholar Academic Graph, Lens.org and OpenAlex by OurResearch that was meant to be the successor of MAG
Sidenote - There is I think there is a difference between Semantic Scholar Academic Graph which is just metadata available via API and Semantic Scholar Open Research Corpus (S2ORC) which I think includes Open full text and is available via a data dump. I think most tools in this post are using the former.
New to OpenAlex? Watch this recent interesting video.
While OpenAlex seems to have successfully incorporated MAG data and then some by ingesting data from PID providers (see analysis comparing the two) realistically speaking because OpenAlex is still very new (it was launched in beta just before Dec 2021), many developers still have not yet had time to incorporate OpenAlex (which is also unstable as it is changing a lot initially), many such as the developer of Inciteful mainly considered the other two.
A review of the tools in this list, it seems Semantic Scholar's Academic Knowledge Graph is the source that many shifted to, either as primary source or as a backup. Of course, OpenAlex would be the perfect replacement but as of 31 July 2022, based on documentation on the tools page only the following have started to use OpenAlex
Litmaps (mentions "OpenAlex (coming soon)
VOSViewer and Harzing's Publish or Perish incidentally also support OpenAlex.
Business models for these tools?
Most of these tools/services are offered for free. Given how new they are, its understandable business models are unclear.
The saving grace is that they are probably fairly cheap to run. As the data they use is mostly open and free, so it's more about the server costs and compensating the developers for their work. But eventually as they get popular and costs start to rise with usage, and the developers start to feel they need some compensation to continue maintaining and improving the service, the question becomes what is the business model?
Will they eventually charge for premium (either personal or institutional licenses), get a grant, be bought out, or something else? It is important to note while a few of these tools are opensource like CitationGecko, the majority, particularly the popular ones, are not, so you can't just run it on your own machine when they start a business model you dislike.
Connected Papers, which in my estimation is one of the most popular tools (and one of the first besides Citation Gecko) has revealed that they now offer premium accounts. For each free account, you get up to 5 graphs per month. You can choose not to sign in, in which case you get only 2 graphs but assuming you are doing it in incognito mode, my tests show you can just reload. This can still be annoying enough that if you really use it regularly you might consider paying.

https://www.connectedpapers.com/pricing
Feature wise there is no difference between free and paid options.
Incidentally, Connected Papers also added a multi-origin graph option. For a long time, Connected Paper was somewhat unusual being one of the few tools that did not allow you to enter more than one seed paper to generate recommendations.
Multi-origin function changes this to a point. You can still only enter one seed paper in the beginning, but once the graph is created, you can select another node in the graph and add it as a second origin paper and it will generate another graph based on these two papers. You can then repeat it a third, fourth etc time. This is how they describe it
In essence, every time you add an origin you are refining your search. You are telling the algorithm: “I want more papers like these, please”.
What you still cannot do is to enter multiple papers at one go.
Another tool, Litmap has also started offering premium plans.
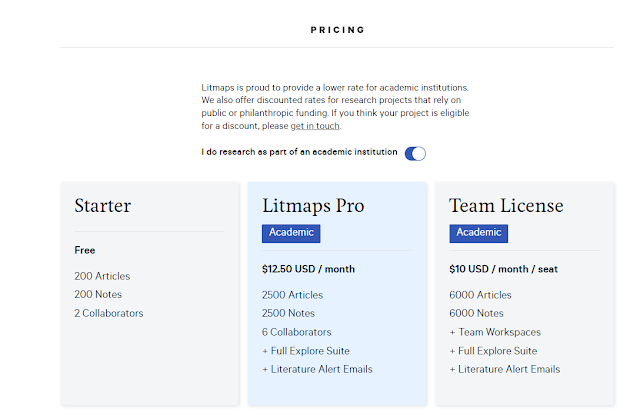
https://www.litmaps.com/#pricing
Their "starter"/free pack looks slightly more generous, allowing creating of maps up to 200, so if you don't have huge maps it is still fairly usable, but again if you use this heavily you going to have to pony up.
You also gain an additional feature of using the method of "Top deep connections" as an explore option on top of the "Top Shallow connections".
Using "Top deep connections" as a method means Litmaps will look at papers two citation hops or jumps away (instead of one) to consider recommending papers. This is quite a standard feature in many similar tools.
That said the next tier up, Litmaps Pro seems much more expensive (even as an academic) than Connected Paper's premium
New tools review - Pure Suggest and Citation Trees
Since June 2021, I spotted two other promising new tools, Pure Suggest and Citation Trees. I will just briefly give my impressions.
Pure Suggest by Fabien Beck is an Open Source Project, which makes it similar to Citation Gecko.
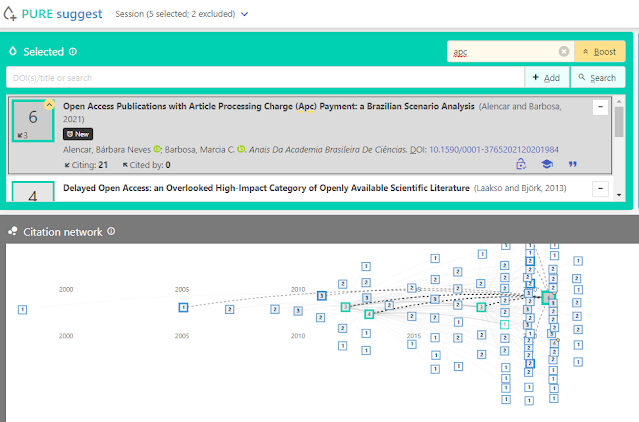
Pure Suggest should look familiar, you add seed papers (one or more) by searching by title or DOI using its index (it uses Crossref and OpenCitations which means it might have less coverage than other tools that mix in Semantic Scholar/MAG/OpenAlex).

Adding seed papers in Pure Suggest by searching title
As you add papers, it will suggest other potential papers to add on the right pane. The visuals are simple but effective , allowing you to see why papers are recommended (basically a sum of cited and citing from existing papers you already have)
I also love the fact that it tries to identify "highly cited" papers globally as well as possible "literature surveys". I personally wonder how it figures out the later given it draws from Crossref and OpenCitations which doesn't tag literature surveys? Possibly, a generic rule that look at number of references for each paper?

Pure Suggest suggests papers based on citations and can identify "highly cited", "literature surveys"
You can read this poster to try to understand the algo including the effects of "boosting" papers, but it seems pretty straight forward counting of references/cited of added papers + boosting effects.
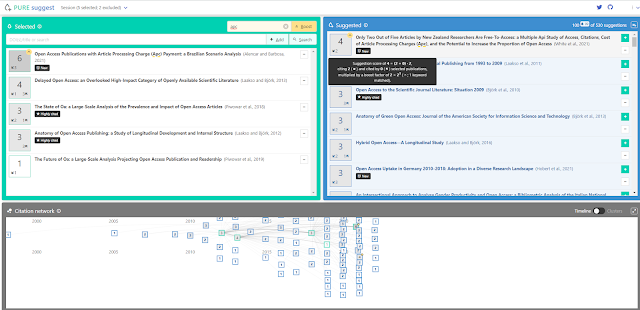
Effect of boosting keywords on suggested papers
Such tools will not be complete without a visualization and Pure Suggest offers two. The default timeline view and a clusters view. Again nothing fancy here but nice and effective.
All in all, while it isn't as fully featured as Litmaps or ResearchRabbit, it does seem worth a try.
Citation Trees is a even more simplistic tool. Its import accepts only one paper and as a DOI only (no searching by title). Currently there are zero options to customize once you have put in the paper. Below is what you see.

Using your seed paper and using Semantic Scholar and Crossref data it auto generates a citation tree visualization with older papers placed at the top and newer papers at the bottom.
There is no documentation, even roughly on how it works but it does seem to be mostly displaying papers that the seed paper references or is cited by (1 hop away) with dark thick edges and for those 2 hops away with lighter color edges?
Use of such tools for support for evidence synthesis, systematic reviews?
Warning : I have very limited knowledge of Systematic Reviews and Evidence synthesis, take the next section with a bigger pinch of salt then usual.
Because many of these tools have fairly unique names like "ResearchRabbit", "Connected Papers" it was fairly easy to identify them when I did a cursory search over reviews in Google Scholar for such tool names and I was surprised to see mentions of the use of such tools. Connected papers in particular was mentioned quite a bit.
For example to just take two examples I saw it mentioned in text like
"Citation analysis, or spider-searching, of included studies was conducted with the literature mapping tool Connected Papers"
or
"Additional sources were identified through the reference list of the eligible articles from the initial search and a co-citation method using the bibliographic coupling concept (www.connectedpapers.com)."
I even saw it mentioned in PRISMA flow diagram once! (Of course, I suspect not all such papers were properly conducted to the standard of a proper Systematic review)
While the idea of using citations to find possible relevant paper isn't new to systematic review practitioners, and they tend to use terms like citation chasing, citation searching, it isn't mandatory according to the guidance given for most conducting manuals.
I think at best they may select it's mandatory to check the references of included studies or systematic reviews (see MECIR Box 4.3.e). or perhaps "highly recommended" or good practice to check citations of such studies under supplementary search. Systematic review experts please correct me.
In any case, even if you want to do citation chasing or reference checking, you don't need "citation based literature mapping tools" because while some can do straight forward checking of references or citations (e.g. ResearchRabbit), a lot of them are recommending papers using totally non-transparent, disclosed methods. If that is the goal, why not just use the usual citation indexes or citationchaser which is straight forward just querying the lens.org citation index?
The moment you add tools like Connected Papers into the mix, you will be adding most likely non-transparent algorithms that might change all the time reducing reproducibility. Is that really what you want? Or does it not matter because you use search engines and they have totally non-transparent relevancy algos that might change at a drop of a hat anyway and you still use it. Also, these tools like Connected Papers are usually used as a supplementary method, used more as a final safeguard to see if anything is missed.
In fact, I was reading about EPPI-Centre's interesting work, where they used machine learning techniques on MAG data (now OpenAlex) to do a first cut for identification of COVID related papers and after human screening to update a living systematic review. It turns out to be able to identify papers (mostly non-English?) that were missed by the gold standard found by traditional process of searching and screening from multiple sources. So perhaps algos are the future?
I would be curious to see what experts in evidence synthesis think.
Conclusion
Hope this update is useful.