
Deep dive into AI powered embedding based search - sparse vs dense embeddings

Warning : I am not a information retrieval researcher, so take my blog post with a pinch of salt
In my last blog post, I described a simplified description of a framework for infomation retrieval from the paper - A Proposed Conceptual Framework for a Representational Approach to Information Retrieval,
This is my second part of the series, where I delve deeper into the details....
There has been a revolution in information retrieval since 2019, where transformer based BERT models (cousins of GPT models), has led to "real" semantic search (as opposed to lexical/keyword search), where you could score the closeness of query and documents based on similarity or "aboutness", helping reduce the vocabulary mismatch issue and other issues of pure keyword search.
Earlier, I introduced the idea of dense retrieval approaches like Bi-encoders where you would convert in advance documents to embeddings by running them through a transformer neural network model like BERT to obtain a representation of the document as a single vector embedding which is then usually stored in a vector store.
Queries would get the same treatment and be converted in real-time and be represented as a single query vector embedding.
The resulting query embedding would be compared against the stored document embedding using some function and will be scored on how "close" they are. Typically something like cosine similarity can be used.
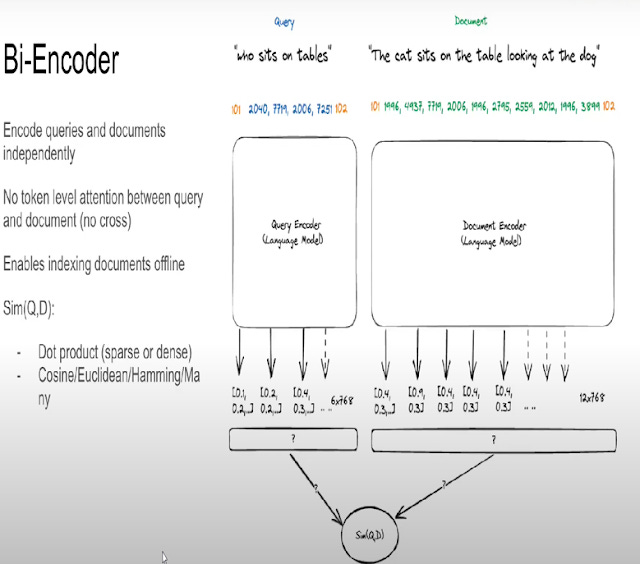
Talk by Jo Kristian Bergum, Vespa
While this method seems easier to understand, in practice if you have millions of documents, doing the comparison of embeddings in real time can be very slow even if the document vectors are precomputed in the vector database. There are various techniques to speed this up including Approximate Nearest Neighbour (ANN) approaches like HNSW, where you tradeoff speed with accuracy where it may not always converage to the closest or best document etc This often is not a serious issue since these scores are only approximate functions of relevancy (e.g is a doc that is 0.023, really that much more relevant than 0.022?). The only concern I suspect is I wonder if this will have reproducible issues. I.e. the very same query when run across time, might give slightly different ordering of results?
Is dense retrieval methods/embeddings always superior?
In my last post, I also talked about how bi-encoders uses uses dense representations/embeddings or dense retrieval methods, while the alternative, sparse representations/embeddings or sparse retrieval methods generally are traditional "bag of word approaches" like TF-IDF/BM25 (see here for a good basic guide on BM25).
However is it true that sparse retrieval methods are always inferior to dense retrieval methods in all ways? As you will see later, the answer is surpringly no for a couple of reasons.

https://arxiv.org/pdf/2307.10488
Leaving aside effectiveness, sparse retrieval methods tend to not only be more interpretable because they do lexical or keyword matches (see later) but are also much more computationally cheaper to run (you don't need powerful GPUs) because inverted index are much lighter and faster to run.
But is it really true the performance of dense retrieval methods in terms of retrieving relevant documents is always better?
It is now known that while typical dense retrieval methods perform better than traditional sparse retrieval methods, like TF-IDF/BM25, they tend to do so only for in-domain tasks (e.g. searches for certain domains/areas) but often do worse in "out-of-domain" tasks
In fact, as you will see later, lexical search or sparse retrieval methods, tend to be a good allrounder regardless of the domain, partly because it is more capable of exact lexical matching.
Why is this so? Also what makes a task considered in-domain vs out-of-domain?
Learned representation vs unlearned representations
One of the thing that's took me a while to realize is that many of these dense retrieval methods are not just basic pretrained BERT models but are often fine-tuned further with task specific fine tuning.
In the context of information retrieval the task here is to find relevant docs. So the fine tuning here involving feeding it pairs (or even triples if you have different classes of relevancy) of queries and documents that are relevant or not relevant that are typical of the types of query it will be used on.
So for example the model could be further finetuned with say, typical queries done in a academic search and fed these queries and documents that are definitely relevant and definitely not relevant.
This fine-tuning is of course also the same as supervised learning.
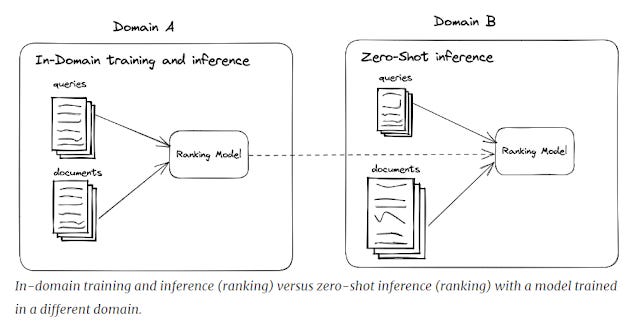
In NLP parlance, they like to talk about in-domain vs out of domain tasks.
Essentially, if you fine-tune with examples from say academic queries in life sciences and then you test with queries from the same area or domain, it is considered and in-domain task.
But if you fine-tune with only academic queries in life sciences and you test with queries on say humantities areas, it would be an out of domain task or sometimes called "zero-shot" test or inference.
The term "inference" here just means running the model after training.
Why do this additional learning or fine-tuning?
Basic language models like BERT are trained to predict the next word or sometimes the next sentence, but this does not imply it can necessarily identify the most relevant document for a query (or rerank documents if used as a reranker).
Sidenote: In NLP there are tasks called Semantic Textual Similarity (STS), paraphrase, and entailment (e.g “Aaron sold the car to John” entails “John now owns the car Aaron sold to him”) and you can see how each embedding model performs in these tasks on the MTEB leaderboard. How are they related to the concept of search relevance? If a model is able to do either or all 3 tasks will it be naturally good at information retrieval? Some have argued despite some differences, (e.g. Queries in information retrieval tend to be much shorter than documents, the other NLP tasks like entailment tend to be roughly the same length, symmetry etc), that these three NLP tasks are mostly related to relevancy.
Notice that unlike the pretraining task where all you need is a lot of text (self supervised learning with "predict the next token" or in the case of BERT "cloze" tasks), the tricky bit here with this in-domain training is you need a lot of labelled data, of queries and documents that are relevant, unrelevant to the query. Other things to consider
You might be able to give one or two relevant documents for the query, but you won't have ALL or even most of the relevant documents
You might want to give "hard" negative examples as opposed to easier examples
Where can you get more labelled data that meets all the above requirements?
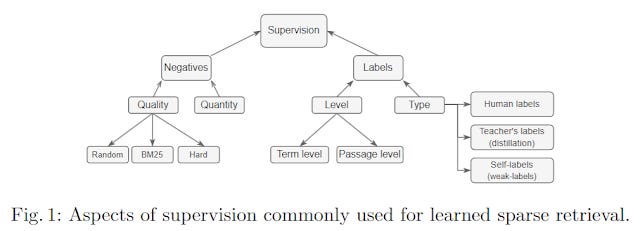
As you might expect there is a whole bunch of techniques to try to get around this (e.g contrastive learning), and a relatively new idea to solve the last question is to use methods that involve using LLMs itself, such as Cross-encoders or even GPT models to label the data. Lexical search methods can also be used to find "hard" negative examples (weakly supervised methods).
Given this hunger for labelled data of relevant papers for each query, I am surely not the first person (and even I have heard some references to this by vendors) to realize the professionally done evidence synthesis studies with included gold standard studies can be very useful data for such training or even just evaluation.
I can imagine if there is a standard format for this e.g. RIS, Covidence files with included, excluded papers and search strategies this can be or already is being used to fine-tune the latest AI powered academic search engines.
Is in-domain fine-tuning training "cheating"?
Now that you know, dense retrieval methods or dense embedding/representations generally have this additional in-domain training while traditional sparse retrieval methods like BM25 do not, is it really THAT surprising that the dense retrieval methods (aka bi-encoders/cross encoders), easily beat traditional sparse retrieval methods like BM25 in tests?
After all, the way I see it, the former was given a chance to "study for a test before taking it", while the later is going "in blind".
Technically speaking BM25 scoring formula has two hyper-paramters, k1 (for term saturation) and b (for document length) that can be "learned" from the corpus for best results but people tend to just use the standard values
But one thing you might wonder is, if these dense methods/bi-encoders are fine-tuned on certain domains might it lead it to poorly perform in other domains at least compared to the baseline which is BM25?
In fact, BM25 despite being a model that does not learn for specific domains turns out to be a very capable generalist. It is still surprising hard to beat on average across many domains and tasks as shown by the BEIR benchmark (2021).

From 2021 paper - BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models
From above, you can see that while the Bi-encoder models listed under "dense" in the table (e.g. DPR, ANCE) are superior to the baseline BM25 on certain test sets, on average across a wide variety of test sets they are actually worse!
The only one that seems on average better is ColBERT (which we will describe later). By far the best is "BM25+CE", which is doing a BM25 first stage retrieval followed by Cross-encoder reranking as described in my last blog post,
But of course time marches on, and it is 2024 at the time of writing, and there are dense models, and/or learned sparse/hybrid models that claim to outperform these benchmarks (or rather BEIR's sucessor MTEB).
While this might be true, we cannot discount the possiblity is that some of these benchmarks are being gamed with the models being trained on the test set due to leakages.
The importance of lexical , exact string matching
If you use search engines like Elicit.com or SciSpace, you notice that they have features to filter down to specific keywords.

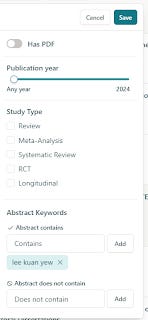
This is a odd feature to have in conventional academic search that do keyword search only but critical for academic search engines that use semantic search based on dense retrieval methods (or at least blend it with lexical search) because you are not guaranteed to have results with exactly the query term you searched for.
For example, if you search for a specific DNA string or a specific name, the semantic search may gives you matches that are close but not exactly what you want.
But shouldn't "real" smart semantic search "know" when to do exact lexical matches? Actually the answer is not always.
In Match Your Words! A Study of Lexical Matching in Neural Information Retrieval - they show evidence that for most state of art dense retrieval models, they struggle with correctly doing lexical matches when needed, particularly for out of domain tasks. Essentially, this helps to explain why these models tend to be poor across the overall BEIR benchmark mentioned above.
In Searching for Meaning Rather Than Keywords and Returning Answers Rather Than Links, technologists at TROVE, experimented with enhancing their standard BM25 standard search of australian newspapers from the 90s with semantic search techniques.
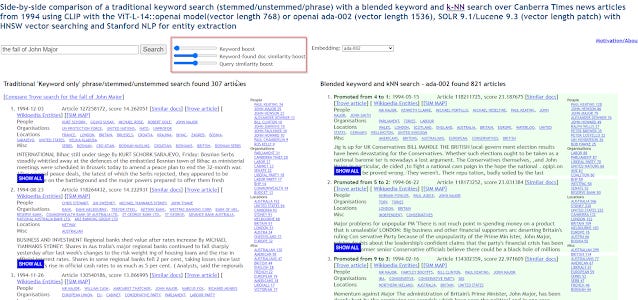
http://nla-overproof.projectcomputing.com/knnBlend?set=1994&embedding=ada-002&stxt=the%20fall%20of%20John%20Major
You can play with their live demo, where you can blend three different techniques by changing the weights.
Besides the standard keyword boost technique (BM25 with a boost if keywords are used nearby or in a phrase), you could also use
a) Query similarity boost - which is the usual embedding similarity match of query embedding and document embedding (in example above using ada-002 embeddings)
b) Keyword-found doc similarity boost - a technique where the top 10 ranked results found by keyword would be converted into an embedding, which are then used to find other similar ("close by") documents.
The demo is very fun to play, besides showing results side by side, it also color codes the results, with green being results that are promoted (pushed up compared to standard keyword), demoted results are in red, and dark green are results only found by either of the two embedding methods (not found by keyword).
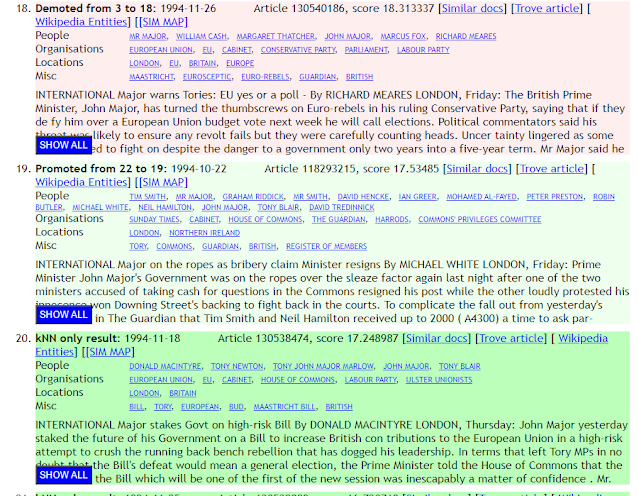
Though not a formal study in terms of measuring performance using MMR, MAP, nDCG etc, the paper does a good job about discussing the strengths and weaknesses of standard keyword vs the embedding based methods with various examples.
Essentially keyword matches shine for specific type of searches where exact matches are important such as personal names e.g. John Major (a UK prime minister) where you don't need to find semantic variants.
On the other hand, they suggest that the concept of train crash is more tricky, since it can be expressed from anything such as
railway accidents or derailment or level-crossing smash or train smashes into bus or any other number of other slightly broader, narrower or related concepts.
However as they point out
As queries get longer, they tend to convey even more “semantic intent” that is impossible to honour with simple keywords, even when attempting to automatically expand the search with keywords.
They give the example of searching for the fall of John major
For example, a search for articles using the fall of John Major (a prominent conservative British Prime Minister during the 1990s) conveys a clear semantic intent. If a patron walked up to a librarian and asked for content using that phrase, the librarian would have a good idea about what they were after. Performing this search on Trove (limited to 1993 Canberra Times articles to enable a comparison) produces results a user familiar with Google does not expect: many results have nothing to do with “John Major” – they just happen to have each of those 5 words somewhere in the article. Perhaps worse, many directly relevant articles are not found: perhaps they use ousting or downfall or undoing or unravelling or humiliation or collapse of support rather than fall, perhaps they describe the political pressure he was under in other ways.
Also
The value of a semantic search is particularly evident when performing a search most naturally expressed as a question or phrase rather than a set of keywords, and it does indeed seem that the ada-002 embedding (and to a lesser extent, the CLIP embedding) manages to encode a commonly understood intent behind the phrase and match it successfully with articles, for example, this search on infiltration of ASIO by communist spies which returns zero keyword matches yet many relevant semantic matches.
This clearly aligns with my earlier blog post on - Why entering your query in natural question leads to better result than keyword searching with the latest AI powered (Dense retrieval/embedding models) search
Finally, they show the power of semantic search, when searching with a single term cybersecurity. While a single short keyword typically favours semantic search, in this case the term wasn't used much in the 90s so a straight keyword search of cybersecurity gets no results, while a semantic search does find relevant results.
All in all, this is why current industry practice is to combine both results from lexical (sparse method) and semantic search (dense method) and rerank the results to try to cover for the weaknesses of both methods.
As such in practice most systems use both methods and combine the results (e.g using Reciprocal rank fusion (RRF)) or by reranking using more accurate but computational expensive techniques like cross-encoders afterwards (hybrid search).
Will Boolean search go away?
Many librarians ask me if Boolean search will go away given the increased popularity of embedding based, dense representations.
As I've shown earlier, current practice is to combine both lexical search or keyword search based method e.g BM25 AND dense embedding methods. However, lexical or keyword based methods like BM25 do not imply they support strict Boolean!
For example Elicit.com and SciSpace do not support Boolean, though their results do blend items found using lexical keyword based methods like BM25 and more modern bi-encoder type methods.
Is this an issue? It might be if you need very transparent, controllable searches e.g for Systematic review. But then again many of our modern search engines like google already do not support strict boolean for over a decade but act close enough usually.....
Conclusion
This has been a deep dive into how modern state of art search technology works. Hopefully it has been interesting and enlightening and gives you some foundation for understanding how search is evolving.
This piece sets the stage for my concluding piece in this series, on the interpretable of modern state of art search algos, why conventional bi-encoders are not interpretable, followed by a deep dive into ColBERT and SPLADE, newer techniques that blend the power of state of art semantic type search but are more interpretable.