


Did you know? How embeddings from state of art large language models are improving search relevancy

Warning: I wrote this to explain to myself high-level technical details in deep learning, it is likely to include inaccuracies. The current clearest guide for me explaining the concept is here.
3 months later me, revisiting this post already notices certain fine points I could have better explained e.g. the difference between the two approaches - a) reranking b) direct use of Dense embeddings (which itself has a couple of approaches involving cross encoder vs bi-encoder vs late interaction models) , or the fact that Embedding type methods don't necessarily out-perform standard BM25/TF-IDF methods if tested on out of domain areas and the latest hybrid methods like COLBERT and learnable sparse embeddings like SPLADE but I think the main big points at a basic librarian level still hold......
The rise of large language models (LLM), such as GPT-3, GPT-4, ChatGPT and the accompanying capabilities in natural language understanding and generation brings with us the natural promise of improving information retrieval.
Most obviously, people have been amazed by the ability of ChatGPT and GPT-4 to gives direct answers to prompts. I personally think that is a bad idea and that if you want direct answers you should instead use something like Bing+Chat, Perplexity.ai or academic search equivalents like scite assistant or Elicit.org which use search to find relevant sections in documents which are then used as context to answer the query.
While this latter method is far from foolproof (such answers can still make up what the linked sources say), they at least allow you a way to verify the answer and as importantly can give the most current answers available found on documents/webpages. For example, if you use ChatGPT to answer questions, they are limited to data from before September 2021 as this is what was used to train the model.
But if you are using a plain old search engine that doesn't give direct answers and instead gives you the traditional ten blue links or documents ranked by relevancy, there is still a possibility you are benefiting from the current gains in state of art Large Language Models.

"Ten blue links" in Google Search results
In fact, more likely than not, the relevancy results of your results have also been quietly enhanced by the advancements due to Large Language Models. In a real sense, search engines today who have implemented such "semantic search" truly "understand" your search query (and documents) and give way better rankings of results.
Some may see "semantic search" to mean the ability to extract answers directly from documents as opposed to returning relevant documents, but this is not the way I am using it here. The technical term for systems that directly give answers is Question & Answering systems.
This is I suspect one of the most understated and least noticed improvements that large language models bring to search engines as they tend to be done under the hood and are typically not noticeable to users as interface wise there is no change.
But what does this actually mean and how does this work? What follows is my attempt to explain what this means in a layperson intuitive manner.
I will end by giving a real example, where this makes a difference and with some consideration of what this development means to librarians who mostly prefer strict boolean keyword search and dislike the unpredictability of smart/semantic/neural search.
The importance of embeddings
Language Models at its core are used to generate models to predict which sequences of words are most probable. How is this helpful for matching search queries?
Now consider, there is a hypothesis in linguistics that states "You shall know a word by the company it keeps" which suggests that if two words are semantically similar, they will tend to be used together by a similar set of words in a huge body of text (e.g. Wikipedia or another large source of text online).
For example, the words "swimming" and "river" may be used together with words like "water", while a word like "antibiotics" will be used with different words (e.g. "drugs" perhaps). This implies "swimming" and "river" are semantically closer than "antibiotics" is to either of them.
This has led to the idea of embeddings, where current state of art is to use deep learning models to learn representations of words (technically called tokens) by throwing them copious amounts of human text as samples, with the ultimate goal to represent each "word" as a long series of numbers (also called vectors).
Deep learning generally involves the use of multiple layers of neural nets. The idea here is that we can use all the available text on the internet as a trainer to teach the neural nets the right weights to predict words. Early in the training they won't be particularly good at predicting but as they train, they will adjust the weights using a method called Backpropagation to get better and better at the task (minimize loss), until they eventually become exceptionally good at it.
The first effective embeddings were those produced by algos such as Word2Vec, GloVe etc which worked amazingly at the time (2013-2015ish).
When trained over a large amount of text, they found embeddings represented by a series of numbers known as a vector that seemed to encode meaning or semantics with similar words being "close by".
More specifically, how does Word2Vec "learn" embeddings in neural nets when given a lot of text? There are two main ways, either you train a neural net to predict based on words on the left or right of it (Continuous Bag of Words Model) or given a word guess words on the left or right of it (Skip-gram Model). Typically, these methods will also have a "Sliding window" that determines what "next to" means. See more
These embeddings are considered dense embeddings as opposed to sparse embeddings (e.g from TF-IDF). Sparse embeddings tend to have “one-hot” encodings where most elements in the embeddings are zero. Compared to dense embeddings such as Word2Vec, more of the elements in the embeddings are non-zero and you get the similarity effect of similar words being close together (see below). More here, here . and here
The most famous example of embedding in Word2Vec is shown below.
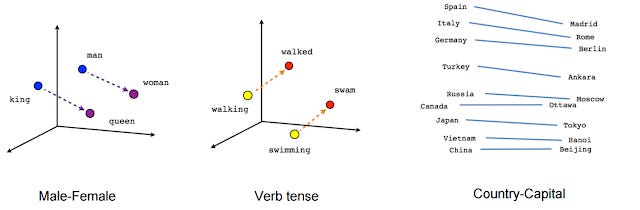
If you look at the positions of the embeddings, they seem to have some logic to them
Embeddings consist of thousands of numbers for each word, so they are technically represented in multi-dimension space, the diagram above has "squeezed them down" to just 2d.
Mathematically you could do something like
vector(‘king’) - vector(‘man’) + vector(‘woman’) result is close to vector(‘queen’).
Because each word is represented by a vector series of numbers, you can calculate how similar embeddings are using various similarity measures such as dot product.
Part of the issue with searching is the problems of synonyms, how do we know when you search for "cars" you are also searching for "automobiles"? Being able to look for words that are semantically "close" is clearly very useful.
So, you can see intuitively how a automated way to train embeddings or representations for words can be very useful.
Going beyond standard embeddings to contextualized embeddings
Word2Vec type embeddings were state of art in 2013, but they have since been superseded. One of the main flaws of Word2vec type embeddings is that once trained they have the exact same embedding regardless of context.
Take for example, the following two sentences.
"I went to the bank to make a deposit" vs
"I went to the opposite bank and started to swim"
Clearly the word "bank" is used differently semantically in the two sentences, one refers to a financial bank and one refers to a river rank.
Using Word2Vec you get only one embedding for "bank" and if it is trained on sentences of both types (which it typically will) it will learn a representation or embedding that is a "blend" of both types of banks. You can say it has collapsed the two different contexts of "bank" into a single vector.
This "bank" embedding from standard Word2Vec trained model for example will be "close" to both words like "financial", "deposit", "money" (relating to the financial bank concept) as well as words like "swim", "river", "water" (relating to the riverbank). There is clearly room for improvement here!
This is where Transformer based Large Language Models shine, as they will produce a different embedding for each type of "bank".
Without going into deeper details, these models generate what is known as context specific embeddings, and while they start with the standard embeddings from systems like Word2vec they adjust the embeddings to take into account the words they are used with.
But how do they do this? The secret sauce here lies with the self-attention mechanism built-into transformer models (a type of neural net).
I won't try to explain how self-attention works beyond noting that the neural net is trained to take into account which other words the target word (say "Bank") should "pay attention" to and this is what allows the system to distinguish different context of use.
For example, in the sentence
"I went to the bank to make a deposit"
Once trained, for the word "bank" it will know how to "pay attention" to the word "deposit", while in the sentence
"I went to the opposite bank and started to swim"
It will do the same for the word "swim" instead and this difference is what makes it able to distinguish between the two uses of "banks".
How does it know what to pay attention to? Partly this is based on similarity e.g. in the sentence "bank" and "swim" are semantically close.
Using words that "bank" pays attention to either "deposit" or "swim", this creates a contextual embedding (rather than a static embedding) that is more accurate.
Another advantage over Word2Vec type embeddings is these transformer-based embeddings consider order of words so the sentence "visa from Singapore to US" is interpreted differently from "visa from US to Singapore". For more details.
Transformer models - Encoder only models vs Decoder only Models
Today many people are mostly aware only of OpenAI's ChatGPT which is a class of language models built on the transformer model (a type of neural net). The transformer model was in fact first proposed recently in 2017 in a seminal paper titled "Attention is all you need".
Below shows the now famous image of the proposed transformer model which includes two main components - an encoder model (the left side of the image) and a decoder model (the right side).

A lot less people are aware that the well-known OpenAI class of models like GPT2,GPT3, ChatGPT actually implements only the decoder model (the right side of the image).
While autogressive decoder based Transformer based language models like GPT3 and ChatGPT have gone viral, Encoder only based Transformer models like BERT which stands for Bidirectional Encoder Representations from Transformers are the one that are also heavily used, particularly for the use case discussed here.
As the name BERT (Bidirectional Encoder Representations from Transformers) suggests, it is a way to encode representations (aka embeddings) using transformers models.
The "bidirectional" part of the name refers to the fact that it learns by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word (Multi-head Self-Attention). This is in comparison to GPT encoder type models which learn only from words in one direction (typically hiding only future words)- (Masked Multi-head Self-Attention). This is needed because GPT models are designed for text generation and need to "learn" without having access to future words. BERT models on other hand generally are trained via Masked Language Model as well as Next Sentence Prediction and are designed for various machine tasks except text generation
BERT models have in fact been heavily used in many aspects of research for machine learning tasks and incorporated into search engines.
The Hugging Face NLP Course states that Encoder models like BERT
are best suited for tasks requiring an understanding of the full sentence, such as sentence classification, named entity recognition (and more generally word classification), and extractive question answering.
In comparison they state that Decoder only models like GPT3
usually revolves around predicting the next word in the sentence. These models are best suited for tasks involving text generation.
Logically this makes sense since Encoder type models are bi-directional and learn the semantics of words from "both sides" and hence can better grok at the meaning, while Decoder type models are better at generating and predicting future text because they are trained specifically from the earlier words only. In practice, I am unsure if this makes a big difference as the newest GPT3.5+ and GPT4 models are very capable in most tasks anyway.
There are also sequence-to-sequence models that use both encoder and decoder models together, a fairly popular example is T5 by Google but we will not discuss them.
In practice, most people who aren't academic researchers will not know how to use Encoder models like BERT because they do not auto-generate text but instead return embeddings which needs some work to use.
That said, in terms of information retrieval, they are commonly used with search relevancy.
Want to go in-depth? Look at this youtube video and this article goes slightly more in depth into BERT and how it is used by search engines.
Is Semantic Search or intelligent search really here?
The holy grail in information retrieval is the idea of semantic search, the idea that the search engine can actually "understand" our search query, "understand" documents they have indexed and intelligently match the two. But this is not trivial.
Some may define semantic search to mean the ability to extract answers directly from documents as opposed to returning relevant documents, but this is not the way I am using it here.
Take a basic problem in search - the problem of synonyms, how does the search engine "know" which synonyms to match on in your query?
Traditional methods like stemming/lemmatization and search query expansion etc. exist of course but how do you determine what are the right synonyms? Inputting hand curated lists of synonyms is clearly not ideal.
In fact, when you think back of the example of how the word "bank" can mean "bank"(river) and "bank"(finance) so you want different synonyms to apply for different contexts, making any human curated list unfeasible and even synonym lists based on older embeddings obtained from older Word2Vec models are not ideal as explained earlier.
Worse yet, such methods to expand search results can lead to far worse results if they discriminately add synonyms to match.
BERT type models as explained solve almost all these problems, such search engines tend to convert your query into BERT embeddings, match against documents embeddings and find the closest matches (roughly speaking).
There's a lot more to this of course. For example, some search engines may use traditional search engine rankings to get the top n results and then of the top n candidate results convert documents to embeddings for matching (typically prestored in a vector database) to save computational costs or time. There may also be a need to do the embeddings at sentence or paragraph level. Lastly, embeddings/similarity alone are not sufficient to get relevant results. Just because query passages and document passages are similar does not mean they are the answers to the questions! This is where supervised learning techniques on large datasets with queries and answers like MS MARCO are needed. However, even if the model is trained in this way, it is tuned only for the type of questions in that dataset, if it is used on questions that are in a totally different domain, it might still not work. This is where self-supervised techniques like Negative sampling/contrastive come in.
Search engines that use such methods to do matching and rankings are sometimes known as "neural search" as well as "semantic search". This is in comparison to mostly keyword-based methods such as BM25/TF-IDF which are known as "lexical search". (I think older vector space type models that don't use deep learning are also not considered neural search).
Neural Search option in Zeta-alpha

Which search engines use embeddings from language models to do "Semantic Search"?
It's actually not easy to tell which search engines are using these new methods of matching unless they report it.
One possible tell-sign is if it is retrieving a lot of results that do not meet your keyword queries but that is not foolproof because a keyword-based search engine can still match articles like this using stemming, search query expansion etc.
Similarly, the fact that if you enter long strings of text and the search engine still returns results (that's don't have all or even most of the search query terms - less stop words) can be suggestive but it's not 100% evidence that they are using state of art contextual embeddings. (There are various ways to rank documents to search queries that don't match all keywords nor do they involve BERT style embeddings match. For example, consider how even years ago Google or Google Scholar would often decide to quietly ignore the last keyword in a query in certain situations).
In fact, we know many of these systems use hybrid methods, for example Google already uses BERT models to some extent for search relevancy. Roughly 10% of its searches benefit from BERT
The advantage they tend to highlight is BERT's ability to understand the order of words in the query.

Hybrid searches may use both methods for reranking, and in Zeta-alpha, the hybrid method combines results both from traditional keyword search methods and neural search methods, which will improve recall but probably at the cost of precision.
Are such semantic searches better than old style keyword searches?
To be honest, I used to think such advantages were at best small and hard to appreciate.
In fact, my experience in the past with new search engines that claimed they were doing "semantic search" was to be immediately wary as the results were often strictly worse and at best not much better.
Many librarians instinctively dislike such "Smart" or "Semantic Search" because they make it difficult to control the search. Such systems would randomly drop keywords they enter or do "synonym" matches that either don't make sense or make the results far worse.
I suspect over two decades the promise of "Semantic search" not working has scarred many of us. But perhaps, semantic search using state of art BERT type embeddings are now good enough to make the results not clearly worse but even better?
Recently though I ran into a case where I could clearly see the advantage.
For example, a while back I was running a quick and dirty search. I wanted to see if there are any new techniques for finding seminal papers. - "How to find seminal papers"
I threw it into Elicit.org and Google Scholar. I was surprised that the results in Google Scholar were far worse.
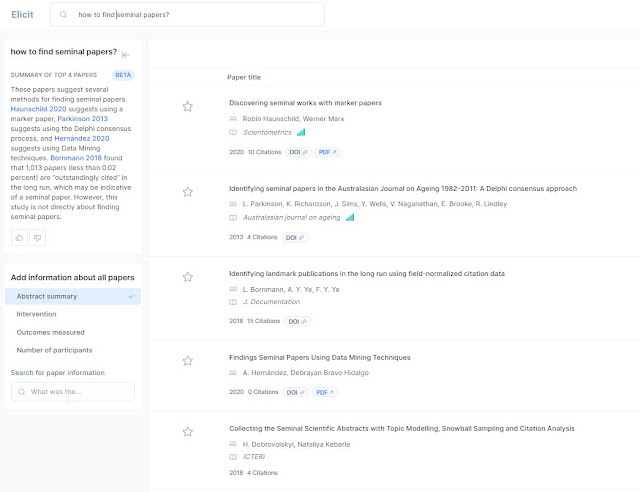

I've been seeing Tweets by users that say Elicit.org gives better relevancy results, but I always took it with a grain of salt. I thought it was at most at the same level, until these results gave me pause.
The results are particularly stunning given that Google Scholar has the advantage of more full-text and papers than Elicit.org (which is huge by most standards but still much smaller Semantic Scholar corpus)
So, what is the secret sauce to Elicit.org's rankings?
Below gives you an idea of how Elicit does its first cut for ranking the documents

As noted, they do a first step ranking based on matching of papers that are "semantically similar" to the query. Specifically, they use paraphrase-mpnet-base-v2 based on SBERT (sentence BERT) which is a
sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
to get the first 400 results. They do two further ranking steps using GPT-3 Babbage model and then reranking the top 20 using castorini/monot5-base-msmarco-10k.
As a non-specialist it looks to me this seems an insane number of steps to do relevancy ranking. While I can see why they might not want to use more powerful methods that might be computationally expensive (in terms of cost or processing speed), this seems way too many steps. But it seems to work.
In the example above, my search query was poor, instead of "how to find seminal papers", I should have tried "identifying seminal papers" or "detect seminal papers" which yield better results in Google Scholar but Elicit is never worse.
I am still not sure how much relevancy boosts using contextual embeddings gives over more traditional TDF-IF/BM25 methods gives particularly with better keyword selection from just this one sample, but as I tried increasingly more examples, I started to see occasions where Elicit did better than Google Scholar.
The differences are subtle because the majority of search queries were "easy" and both Google Scholar and Elicit performed on par for such queries. And obviously comparisons are not quite easy since we are comparing two different search engines with different indexed data and features.
Ideally, we should be able to compare Elicit.org with "semantic search" on vs off.
Conclusion
We librarians have traditionally insisted on strict Boolean keyword type searching but as neural/semantic search becomes more popular and actually useful, should we reconsider? While there are use cases like Evidence synthesis where strict Boolean keyword search is needed for reproducibility and predictability, these might be exceptions?