


Do search+large language models or "retriever augmented" models (e.g. Bing Chat, Perplexity, Elicit.org) really work? The evidence so far

The story so far.
ChatGPT, or other large language models, is not ideal for information retrieval alone because it often hallucinates or fabricates information, including references. Moreover, it is not updated with the latest data, rendering it unable to answer questions on current events without retraining the model, which by the way is extremely expensive to do.
There is also suspicion that large language models like GPT3 at least might not be trained on full text of paywall articles, so relying on it to answer questions limits you to a limited subset of Open Access full-text papers.
The proposed solution is to use systems like Bing Chat, Perplexity or their academic counterparts Elicit.org, Scite assistant that adds on a search engine or "retriever" which is used to search and retrieve relevant content/text sentences (sometimes called context) that might answer the query.
This possibly relevant text sentences are then passed on to the large language models to generate an answer based on the content it found.
For slightly more details on how it can extract sentences that are relevant to the query, you will need to understanding the idea of vector embeddings.
In the case of a generator that uses a large language model like OpenAI's GPT models, a prompt like the following could be used.
Given the context below (<the extracted text answers>), answer the users question truthfully.

Difference between using a Language Model trained up to a fixed date vs one using a search engine to augment the results.
This "LLM augmented retrieval" methods or "retriever augmented language models" ensures at the very least the cited reference is something the search engine has retrieved and isn't made up and allows you to get answers from the most current pages or papers as long as it is accessible to the search.
This sounds incredibly good but how well does this theory stand up to the evidence?
For example, can we be sure the "retriever" can always find the right or even appropriate answers to feed the generator? For simple factual questions, like Who won the FIFA World Cup 2022, this is certainly true, but what happens if the search fails to find anything relevant?
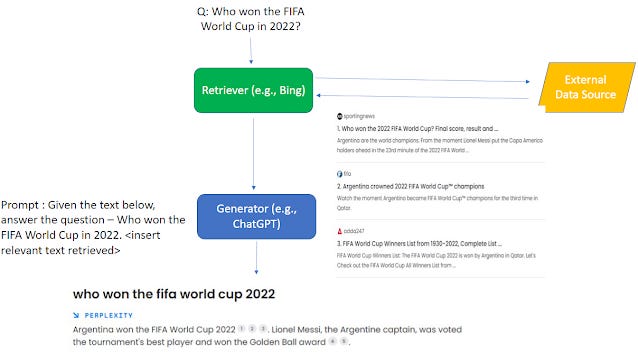
In the example above, Perplexity.ai is able to find three relevant answers from webpages that is used by the Generator to summaries and generate an appropriate answer
Even if the search or retriever finds something relevant, there is a not small chance, the generator/large language model when paraphrasing or summarizing the answer could distort or in human terms "misinterpret" the text evidence it finds.

With all these issues, do such "augmented retriever" search systems either general web or specialized academic search really score better on "factuality"(roughly factual accuracy, the related "faithfulness" applies more to correspondence between text and it's summarised content) than using ChatGPT alone? What does the evidence tell us?
To answer this question, I will cite evidence from two interesting recent preprints
1. Why Does ChatGPT Fall Short in Answering Questions Faithfully?
2. Evaluating Verifiability in Generative Search Engines
The first preprint studies the leading cause of ChatGPT making errors and it turns out to be memorization issues. They show by adding the correct evidence into the prompt the answer is solved.
In view of the results from the first preprint, this lends support to the idea of ChatGPT+ augmented retrieval may be a good idea.
However, a direct test is still needed, after all such systems do not automatically find the right golden standard as evidence and this has happened before. The second preprint's headline finding shows that factuality as measured by citation precision and recall is pretty bad but there are some other interesting nuances such as how users perceive utility of answers versus citation precision and recall.
The crux of the matter is this, if there are no webpages or results that can answer the query, the system is faced with a dilemma. Should it try to make up an answer that will better answer the query but will not be supported by citations? Or should it stay faithful to what it found but result in generated answers that don't quite answer the query?
What the paper found was that there was a negative correlation between answers that they perceived to be fluent and had high utility AND high citation recall/precision!
This makes sense because the less constrained you are to fit your answer to content found in papers/pages (citations), the more fluent and seemingly useful your generated answer can seem to be.
Google calls this the Factuality v. fluidity issue
We have found that giving the models leeway to create fluid, human-sounding responses results in a higher likelihood of inaccuracies (see limitations below) in the output. At the same time, when responses are fluid and conversational in nature, we have found that human evaluators are more likely to trust the responses and less likely to catch errors
Interested? Read on....
Why Does ChatGPT Fall Short in Answering Questions Faithfully?
This is an interesting preprint that tries to analyse why ChatGPT gives wrong answers.
The TLDR summary of this is they find that most of the mistakes GPT3.5 makes are due to errors in facts that it "knows" and by feeding the right evidence in prompts, most of these mistakes will be avoided.
Here's more details.
First off, they divide the errors into four types
Comprehension
Factualness
Specificity
Inference
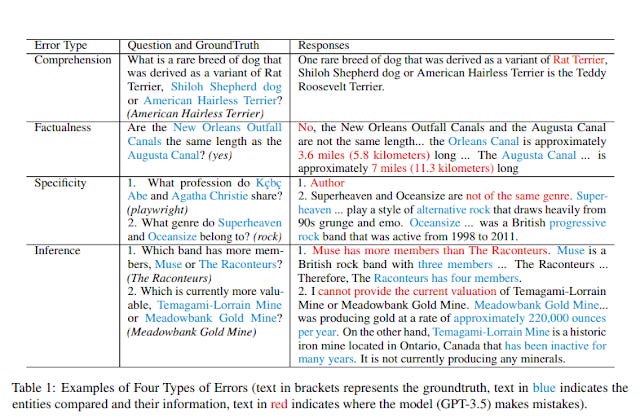
I encourage you to read the paper to get a full explanation of the types, e.g inference = failure of reasoning, comprehension = LLM misinterpreting the question, but of interest to us is factualness error which occurs
when a model lacks the necessary supporting facts to produce an accurate answer
I think they determine this lack of factualness by asking the LLM questions about the facts needed to answer the question.
They then did a test by sampling from 200 questions from HotpotQA (80 easy, 60 medium, and 60 hard) and manually classified wrong answers into the four types of errors.

You can see that most of the errors for GPT-3.5 was due to factualness. GPT-3.5 on its own got 60.5% right. 31 out of the 79 wrong answers (39%) was attributed to factualness.
So, what happens if you provide GPT-3.5 with the correct fact in the prompt? GPT-3.5 w/Evi row shows this leads to a huge improvement. Overall, GPT-3.5 now has 92.5% correct! Adding the right facts even reduces comprehension and specificity errors (but not so much inference)!
This outperforms even GPT-4. I am curious though why they didn't try to improve GPT-4 the same way..
The paper goes on to talk about how these errors map to human capabilities namely
Memorization
Association
Reasoning

Memorization is easy to understand. But Association is an interesting concept. This is analogous to someone who actually knows facts that can be used to answer the question but doesn't think to use it.
How can you tell the model is having a association problem as opposed to memorization?
To determine this, first take a question the model answers wrongly. They probe it by asking facts needed to answer the original question. If it answers this correctly (showing memorization isn't an issue), they then ask the original question in same conversation.
If it now gets it correct when it didn't when asking directly, this is an association problem. The model, like a human needs to be reminded what it knows.
But what happens if it still can't answer despite being "reminded", they classify it as a "reasoning" issue.
I'm not too sure about this classification but the procedure to determine association is fascinating...
They do further tests to see what types of evidence is needed to help the model get the answer correct such as adding
Key evidence - just adding the sentence with the answer
Distractor Sentences -Same as above but add other irrelevant sentences
Wikipedia Section - The Wikipedia section with the key evidence sentences
Wikipedia page - the whole page
They also do a whole series of tests on how much association is needed, whether all you need is to add
Entity Name
Wikipedia Background
Random Sentences
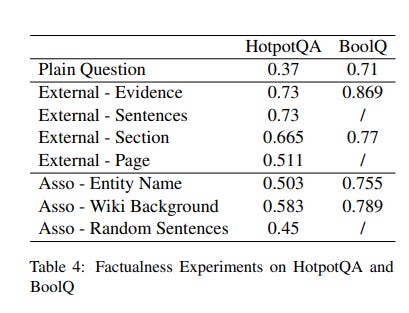
As you can see above, it seems GPT3.5 is pretty good at figuring out what it needs to answer the question so throwing it the needed sentence, or the needed sentence with distractor sentences gets you roughly the same improvement. Adding the whole section or page, the improvement goes down (the language model more likely to be "distracted") but overall results are far better than not giving it the evidence.
I won't cover the section where they try to improve reasoning errors by decomposition methods where they try to break the questions into smaller sections (the well-known Chain of Thought prompts is an example). The interesting result here is while decomposition methods do improve results, they don't seem to help much once you have already provided the right evidence.
Why is this paper interesting? It shows that a lot of errors GPT models make can be solved by just providing the right facts (at least for the test set in the paper) and this even works if you send it sentences + other text surrounding it. This of course, sounds very promising for "augmented retrieval" type search engines like Bing Chat.
Evaluating Verifiability in Generative Search Engines
The above paper is promising but it is still not a direct test of Bing Chat and similar search engines. Most importantly, it assumes the language model is automatically given the relevant and right details while search engines may fail to find the relevant answers.
Evaluating Verifiability in Generative Search Engines is the first preprint I am aware that actually does a direct test of such search engines namely
Bing Chat
Perplexity
YouChat
NeevaAI
and additionally sets out in my view a great methodology on how to test such systems.
Bad headline results - 51.5% of generated sentences are fully supported by citations and only 74.5% of citations support their associated sentence.
Reading the abstract alone is very disappointing. Less than 50% of generated sentences are fully supported by citations! Looking at it the other way around, for every citation given, only 74.5% are correct!
I suspect a lot of people stopped reading after this, but I urge you to read on. In my opinion, the results are not as bad as they seem.
First off, these scores are an average of the four systems but if you look carefully at the scores regarding citation accuracy, one of them YouChat is clearly bad.
The paper warns the four search engines might not be fully comparable because they "abstain" or do not answer a % of questions. This "abstention rate" is extremely high for NeevaAI (22%) and is low for the other three (<0.5%) but as they abstain on different questions, comparisons might be difficult given we do not know what criteria they use for not answering. But it seems to my eyes, YouChat is clearly inferior.
For example, if you exclude Youchat, the citation recall (more on that later) goes up to 65% (ie 65% of the generated sentences are fully supported by citations). while citation precision goes up to 78% (ie 78% of citations support their associated sentences).
The other reason for tempering the disappointment is that the test set chosen was mostly designed to be tricky questions with no simple factual answers.

For example, it includes a lot of questions that need long answers and sometimes even requires answers to be extracted from multiple table cells, something that is difficult for current large language models.
It even includes questions from open-ended questions from entrance exam for All Souls College, Oxford University which is rumored to be the hardest exam in the world! A lot of these questions are designed to be hard to be answered using a search engine, and example question given was "Could the
EU learn anything from the Roman Empire?", and search engines would struggle to find webpages with relevant content.
Lastly at the time of the test all but Bing had access to the latest GPT-4 model - which accounts for its higher citation precision (I suspect citation recall is more correlated with the ability of the search to find relevant pages) so for example Perplexity which now has GPT-4 and bests Bing Chat in citation recall is likely to do even better.
Definition of Citation Recall and Citation Precision

I found it initially difficult to grasp their definition of citation recall and precision despite having familiarity with recall and precision metrics, but the paper has a nice example (see above).
Citation recall focuses on generated sentences. If there is at least ONE citation that correctly (it doesn't matter if the other citations do not) supports, the generated sentence, the sentence is considered fully supported by citations.
There's a slightly technical point, where the paper discusses which generated sentences requires citations. Clearly statements like "As a language model, I do not have the ability to ban books" don't need citations but what about "obvious" statements like "The Pope is Catholic". The author states that they take the stance "all generated statements about the external world" should be backed by citations. I can't tell from the paper if this nuance adversely affected citation recall e.g., systems not giving citations for obvious statements.
As a sidenote, it is possible for two or more citations to support the generated sentences partly individually, but as a whole support the whole sentence. For example, if the sentence says, An Apple a Day leads to longer lives and less doctor visits and there are two citations - one that says Apple a Day leads to longer lives and the other that less Apple a Day leads to less doctor visits, the sentence is considered fully supported.
Citation recall is hence the percentage of generated sentences with at least one citation that fully supports the sentence.
However, if we measured only citation recall, systems would try to game it by creating dozens of citations for each generated sentence in hopes that at least one matches. That is why we also measure citation precision. This looks at each citation and checks how many of them support their associated sentences.
Citation recall compared
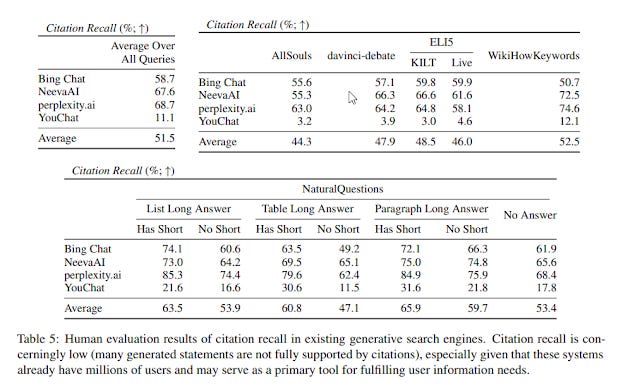
As already mentioned, YouChat is overall far worse than the other three. Only 10% of generated sentences are backedup correctly by citations!
In terms of citation recall, Perplexity does the best and Bing Chat despite using the latest GPT-4 is 10% worse. This is probably because citation recall is more likely influenced by the ability of the search engine to rank and find relevant content to be cited.
We can clearly also see differences in performance based on the type of question. All-souls questions are clearly very difficult and the poor performance is probably due to the fact that the search engine struggles to find webpages that provide content that helps answer the question.
The easiest questions are those where the answer comes from a paragraph and is answered with a short answer. Those that require extracting from tables and have no short answers are more difficult, which makes sense since these models are probably not good at understanding tables.
Citation Precision compared
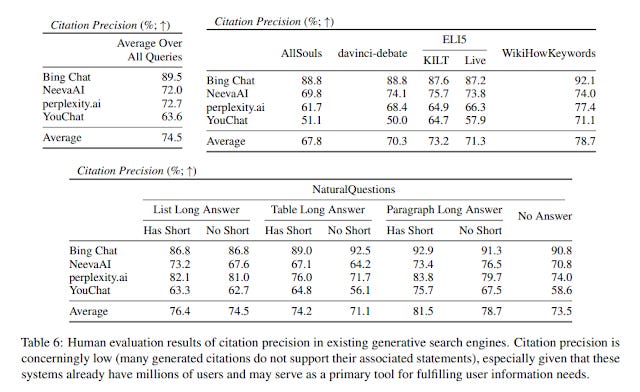
Citation precision shows a similar pattern with YouChat doing the worst. Excluding it, 78% of citations created by the three search engines correctly supports their associated sentences.
Again, AllSouls questions are the hardest and the models find it easiest when there is a short answer from a paragraph (92.9% for Bing Chat and 83.8 for Perplexity).
Bing Chat's superiority in citation precision of 89.5% vs the closest competitor Perplexity 72.7% I suspect is due to the fact it's the only one that used GPT-4 at the time. This means it is less likely to "misinterpret" a reference given that GPT-4 has 40% less hallucinations than it's predecessors.
Another possibility is there might be a tradeoff between citation precision and citation recall. Interestingly, the F score for three of the four systems aree remarkably close.
Bing Chat - 70.9%
NeevaAI - 69.8%
Perplexity - 70.6%
Youchat -18.9%
Citation recall and precision are inversely correlated with fluency and perceived utility
Another headline finding of this interesting paper is when people (via Amazon Turk) were also asked to rate answers by fluency and perceived utility (five-point Likert ratings) they found these ratings were negatively correlated with citation precision and citation recall!
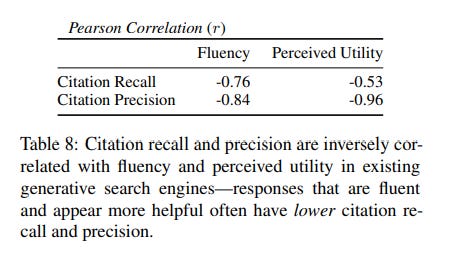
While the paper goes into comparison of fluency and perceived utility scores versus type of questions, most of the results were fairly obvious. However, this negative correlation between citation recall and precision vs Fluency and perceived utility is more concerning as it implies the less the answer is likely to be factually correct (citation precision/recall is low), the more users perceive the answer to be fluent and useful!
The paper makes the point that engines that try to closely paraphrase or directly copy from citations are likely to have high citation precision recall, but the answer is likely perceived to be less fluent or useful because it may not answer the question. The more the system tries to paraphrase, the more likely the answer will be rated more fluent or useful but the chances increase it makes a mistake doing so.
Summarization technique divide into "extractive summarization" which extract the exact sentences and produces them as an answer vs "abstrative summarization" which paraphrase and generates new words. At it's limit if the search engine only does "extractive summarization" and only spits back sentences extracted from the webpage, it will have very high citation precision and recall, but clearly it won't be rated very fluent and the answers may not even answer the question (low perceived utility).
Even worse if the search fails to find anything even remotely relevant, the system can either just make something up - generate sentences that seems to answer the question (high perceived utility) but the citations don't support or still try to generate sentences that are supposed by the citations. But the later option will result in answers that don't answer the question and are rated to be not useful.
This observation may also explain why a lot of users prefer answers from ChatGPT rather than Bing Chat. Part of the reason is simply, that for most questions, ChatGPT is able to give a lengthy , chatty answer because it is not limited to trying to generate sentences based on what the search finds. Because it can draw on the associations it has gained during training it is able to produce long expansive text that reads well and addresses the question. Most of it might even be true because of the vast amounts of data it has been trained on!
Search Engine like Bing+Chat, even if the search can find relevant webpages will typically be limited to trying to generate sentences from the top 5 or possibly 10 results. This leads to a less fluent and shorter answer.
I don't quite have access to the ChatGPT plugins that allow web searches, but these probably have similar limitations?
Conclusion
The paper covers a lot more including their attempts to test for the problem of data containment where the language model already has the answers "memorized" but I covered the meat of the papers.
We are in the incredibly early days of Search engines being combined with large language models for generation of answers. Thus far the limited evidence we have suggests that these systems are not exceptionally reliable except for the simplest factual type of question where the answer can be extracted from text. The more complicated the question, particularly ones where no webpage is likely to have the answer, the more unreliable the answers will be. If there is no webpage or result that can answer the question, the system is faced with a dilemma. Should it try to make up an answer that will better answer the query but will not be supported by citations? Or should it stay faithful to what it found but result in generated answers that don't quite answer the query?
The observation that users perceive more utility from answers that are wrong (or at least are made up sentences that are not supported by citations) is in some sense a banal truth. As someone observed to me society rewards bullshitters!
Still this also means users of such tools should always be careful to verify citations and not assume that they are true. In fact, the better the answer generated, the more you should be suspicious!
I have some thoughts on how to solve this conundrum between trying to generate answers faithful to the search results and not having the right answers from search, but this should be a separate post.