
Enhancing the discovery of institutional repository contents - 6 sources to consider


The "inside-out library" was a concept coined by Lorcan Dempsey as an interesting way to capture the change in the function of libraries today. Instead of merely bringing in content from the outside into the community (i.e the traditional role of buying of books and journals), academic libraries are now taking on roles of promoting the content created by their community to the outside world.
While I have mused on the challenges of institutional repositories (mostly around the reluctance of faculty to deposit), some institutional repostories (IR) do manage to get a fair amount of content in repositories. For those libraries, the question shifts towards how best to make their content as discoverable as possible.
What follows is my musings about 6 different sources you might want to optimize to ensure your IR content has the broadest reach possible, unfortunately my experience is that this isn't always very straight forward.
I will discuss the following three groups of sources
Search engines and aggregators like Google Scholar, BASE , CORE
OA finding tools like Unpaywall, OAbutton, Kopernio, Lazy Scholar
I will discuss why you might be interested in checking these sources or services and how you might possibly do this.
The too long didn't read summary is that besides optimising for discovery in Google/Google Scholar (obvious), it is probably a good idea to ensure your IR contents are well indexed in BASE and CORE as between these two you cover the three major web scale discovery services in use in academic libraries today (Ebsco Discovery Service, Summon and Primo).
In particular ensuring your IR content is well and correctly indexed in BASE seems important because it use crops up in diverse other services such as ORCID search and Link Wizard, Dissem.in and more.
Lastly we cannot ignore the rising influence of Unpaywall and it's API (formerly known as oaDOI now renamed to Unpaywall API) which is now intergrated with 2 major link resolvers SFX and 360link as well as in important databases like Web of Science , Dimensions and ScienceOpen. Up to recently it was heavily reliant on BASE for institutional repository content but it has since started it's own harvester.
Post blog note 15-03-2018: Just after I blogged, University of Liège Library released "Open Access discovery: ULiège experience with aggregators and discovery tools providers. Be proactive and apply best practices" - though some of the points are similar - such as the importance of indexing in BASE and CORE, it points out that you can directly ask to be indexed in Summon,Primo and EDS without going through a middleman like CORE or BASE even if you are not a cusomer of these services. It also points out you can add your IR content to Pubmed's LinkOut service further exposing your content to Pubmed users.
1. Google Scholar
Why do we care?
For most institutional repositories, Google Scholar and Google (Note Google and Google Scholar are two seperate indexes) are the most important sources of referrals to their content by far. When Google Scholar and institutional repositories were still new this was seen to be a surprise and somewhat ironic but today this is a established state of affairs. So obviously it is important to ensure these two important source have properly indexed your IR content.
How to check and optimise?
I wrote quite a bit about this in 2014 (see points 5,6,7,) and till this day it draws a lot of traffic. I haven't been able to locate much that is new on this topic.
To recap, by now I think most institutional repository managers know you shouldn't use the site command to get a feel of this. In other words, entering Site:http://dash.harvard.edu will not give you a accurate feel of how much of your content is indexed in IR.
As I wrote in 2014 " According to Invisible institutional repositories: Addressing the low indexing ratios of IRs in Google Scholar, the site operator will only show up articles where the copy in your institutional repository is the primary document (the one that the title links to in Google Scholar, rather than those under "All X versions")"
So what should you do?
Above we see one of the first well known research on SEO for both Google and Google Scholar for IR contents by Willard Marriott Library at the University of Utah.
Another more recent study and presentation was "Driving Traffic to Institutional Repositories: How Search Engine Optimisation can Increase the Number of Downloads from IR," in 2017. You are highly recommended to watch the recording.
The key trick seems to be getting access to Google Search Console for your IR , which can cover for the weakness of Google analytics missing downloads. I gave it a try and besides seeing the overhealth of your IR you can get statistics like what sites are linking to your pages and most interestingly, what keywords people are using to find your page and what the average position your page appears in. This is all old hat for SEO pros but I suspect not well known in library circles.
There is also a interesting web protoype ,Repository Analytics & Metrics Portal (RAMP) build to use this.
But is there anything official from Google itself? The answer is yes.
Darcy Dapra of Google seems to be the front person in Google for queries on indexing of institutional repositories in Google Scholar and she has helped me years ago when I was working on the institutional repository. You can lookup talks she gave about problems Google Scholar faces indexing publisher sites and institutional repositories.
2. BASE (Bielefeld Academic Search Engine)
Why do we care?
BASE (Bielefeld Academic Search Engine) is one of the leading global aggregator of open access content (journals, subject and institutional repositories) in the world. It claims to be the 2nd biggest academic search engine behind Google Scholar by size easily exceeding over 100 million records (123 million as at time of writing) and indexing over 6,000 sources.
BASE is not only one of the biggest source of free academic content but unlike Google Scholar it actually has an API so you can build many interesting services on it.
As such it is indexed or used in many services.
Some examples
1. Since Dec 2015, it has been indexed in Ebsco Discovery Service (EDS), one of the big four - web scale discovery service in the world. So if your IR contents are indexed properly in BASE, libraries using EDS who turn on BASE in EDS will expose your content to their users.
2. BASE is often used by many services as one of the default services for searching for content. Services such as OAbutton, Impactstory, dissemin, DOAI, and formerly unpaywall, OAbot (a wikipedia bot that adds to citations links to open content) all routinely use BASE to check for availability of free to read content or metadata (see later for more details)
3. BASE itself also provides a whole host of advanced features, in particular it is one of the sources ORCID draws from to add works to your ORICD profile using the search and Link wizard.
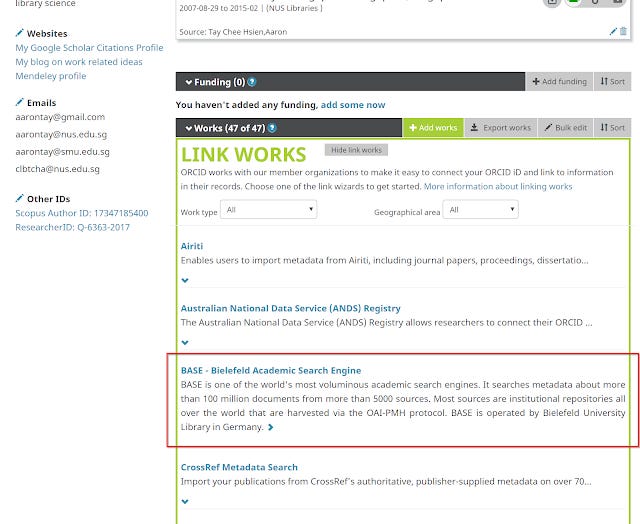
This will be useful in allowing researchers to easily add records to their ORCID profile if the records are already in BASE (assuming you don't already automatically push records to your researcher's ORCID via other means of course).
4. Innovative services such as Open Knowledge Map service also draws from BASE.
Many institutional repository have contents that are not properly indexed in BASE
More importantly, as I noted in many blog posts, BASE often has a problem indexing many IRs. For many institutions the problem isn't so much your content isn't indexed , in most cases the metadata record appears but BASE will have problems knowing if a record has full text attached or if it is metadata only.
For example a quick study of 3 institutional repositories in Singapore I did back in 2016, found that while the number of records in BASE matched up to 80-90% of total records in each IR, in terms of full text found it ranged from 0.6% to below 4%.
There is reason to believe this isn't specific to the ones I studied. As of writing, 43% of BASE records are open access, 4% are identified as non-open access and a whopping 53% of BASE records are stated as non-known. It is probably a fair amount of these 53% are open access as well.
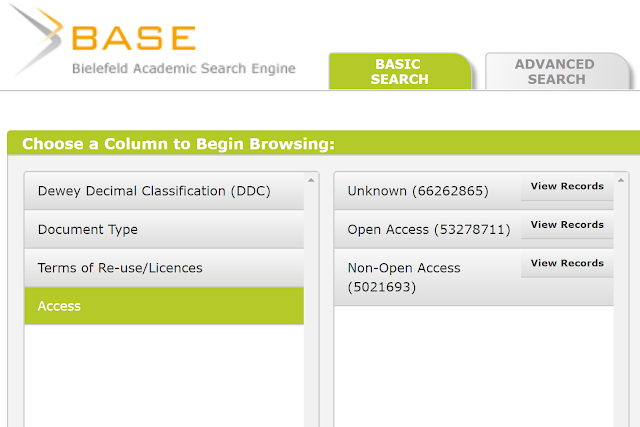
This isn't the fault of BASE as we will see.
How to check and optimise?
BASE is a standard predictable search engine with many facets so it's fairly easily to do a quick and dirty search to ascertain how big is set of records indexed by them.
For your institutional repository, there are many ways to do this, but I generally search for the university or IR name, find a record that is from there, click on "detail view" and right at the bottom of record , click on the base URL.
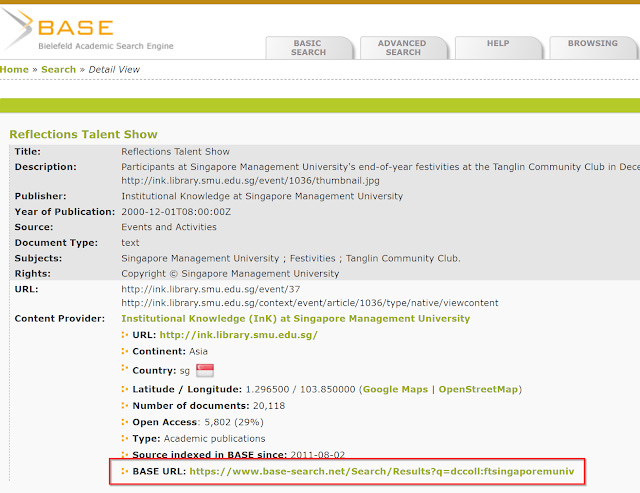
In my case it is https://www.base-search.net/Search/Results?q=dccoll:ftsingaporemuniv&refid=dcrecen
If you can't find anything at all (rare), you can check the following page to see if your IR is included as a source and there's a test to validate your source OAI-PMH
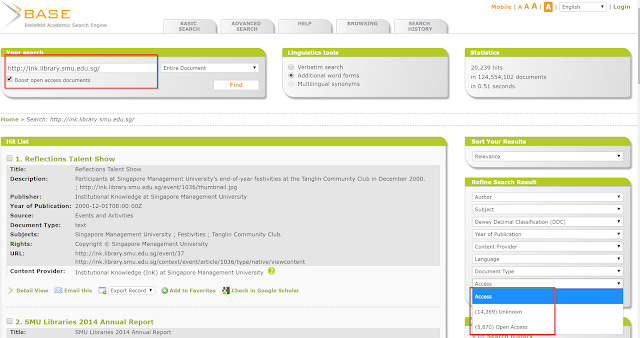
Hopefully the number of results you see is roughly the same as what you have exposed to the harvester. Also critically you should also check the facet for "Access", is BASE correctly showing the number of records that are full text?
A more advanced and indepth way to do this is to use the BASE API to pull out the subset pertaining to your IR and do a comparison.
If this is off by a lot what should you do? Sometimes it's a matter of triggering a reharvest, other times it can be a lot more tricky if the problem is with the metadata.
Like most institutional repository aggregators currently, BASE relies on OAI-PMH and harvest metadata with Dublin Core. As BASE notes this "is simple, flexible and a bit vague". So you may have to tweak your Dublin Core metadata a little for BASE to understand which records have full text.
Here are some tips from BASE
We have a short list of OAI/DC recommendations we call “The Golden Rules for Repository Managers”: https://t.co/A5v1hIIije#DublinCore #OAI-PMH
— Search Engine BASE (@BASEsearch) February 22, 2018
In particular, for the Golden Rules for Repository Managers, I highly recommend looking at the two sections below if you have problems with your content not appearing correctly as Open access.

Recently, I saw the following tweeted out.
“The biggest difference between BASE (https://t.co/ruozrKN1O9) and Google Scholar is that the BASE team answers emails” #PIDapalooza
— Daniel S. Katz (@danielskatz) January 23, 2018
I put it to the test and emailed BASE support. It took a while, due to various mixups with IT campus but we finally got it done and BASE kindly helped reindex everything.
What we did was that we basically tagged all our records in the DC:Rights by a CC license (the term "open access" works too). We had problems initially because our Digital Commons set was putting "Openaccess" in the dublin core qualified field which I'm told no harvester including BASE uses.
The tricky part I suspect is whether you can easily identify which records you have in the IR have full text. If you can't it can be painful to go retrospectively to fix things espically if you have a huge set of records. I understand there might be ways to do it for Digital Commons but I can't speak for other types of IRs.
3. CORE (COnnecting REpositories)
Why do we care?
CORE (COnnecting REpositories) by JISC is a peer of BASE and has pretty much the same goals. It appears a bit smaller than BASE reporting 85 million metadata records and indexing of 3,000+ sources as of Dec 2017. Like BASE, it has a free API and a bunch of services.
I would guess most institutional repository managers in the UK would be familar with CORE so this is more for non-UK IRs.
The reasons for caring about CORE is pretty much similar to BASE.
While BASE is indexed by EDS, the most used web scale discovery service, CORE will be indexed by Summon and Primo, the other two popular web scale discovery service. So if your IR is properly indexed in both BASE and CORE you will cover all your bases (pun intended).
CORE is also listed as a source by OA button.
CORE also offers a recommender system that will recommend contents from the CORE index. I don't think it is widely deployed yet, though the University of Strathclyde has deployed it on their IR.
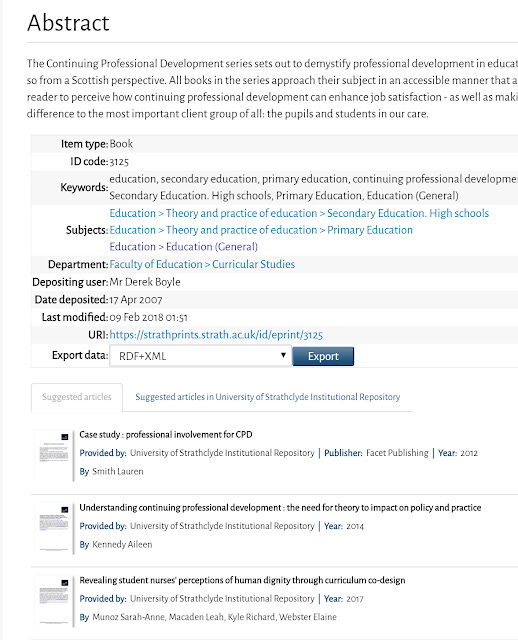
How to check and optimise?
You can use a similar method as in BASE by doing a quick and dirty search or if need be use the CORE API to download contents by your repository.
If there are no results, check if your IR is indexed at all here.
The metadata requirements to be indexed in CORE are available too.
Similar to BASE, chances are a typical IR will be already indexed in CORE without any manual intervention.
Below I have screenshot the recommendations from CORE.

For what's it's worth, CORE seems to be better at figuring out availability of full-text than BASE in my experience.
If you notice CORE doesn't just index metadata via OAI-PMH but it also stores a cached copy of the content, this implies it actually checks if the pdf exists, leading to better detection.
That's because CORE actually tests and validates the PDF links.
— Petr Knoth (@petrknoth) March 7, 2018
On top of that, there's also a CORE dashboard feature

.
I haven't tried to ask for access, but it seems like something that might be very useful for institutional repository managers to track the discoverability of their content in CORE. I'm unsure also if it is available for those outside the UK though it makes no mention of this.
4. Unpaywall, Kopernio, Lazy Scholar, OAbutton and more
Why do we care?
As I predicted in the past, as the level of Open access grows, there has been an explosion in services and tools around the discovery of open access versions. These tools typically implemented via a Chrome and/or Firefox extension include Unpaywall, OAbutton, Kopernio, Lazy Scholar, Lean browser and more.
Estimates from Unpaywall and Lazy Scholar show that such tools are closing towards a success rate of 50% when users are on a page with dois and I expect usage of them will increase as the level of Open Access further rises.
Of them all, Unpaywall has had the highest profile and is one of the most popular.
Of course I'm biased but I'd say Unpaywall :).
That said, I think I'm in good company. Active users (as shown on the Chrome web store page):
OA Button: 5,254
Kopernio: 4,179
Sci-Hub Links (top Sci-Hub extension on Chrome): 98,645
Unpaywall: 116,739— Jason Priem (@jasonpriem) March 2, 2018
Besides the ones he mentioned, at the time of writing, Lazy Scholar (rarely mentioned but a early pioneer) has about 9k users, and lean library browser extension (a commerical startup started by a librarian and marketed to library and adopted by academic libraries such as Havard, Stanford, CalTech) has about the same.
Clearly Unpaywall is in the lead by a lot, though unlike some of the solutions already mentioned such as Kopernio, Lazy Scholar, Lean browser it does not check for content subscribed by the user's institution.
Still, I kinda spoiled Jason Priem's (founder of impactstory and unpaywall) party by pointing out Google's own Google Scholar button extension blows all of them out of the water with over 1.6 million users. This also happens to be my top recommendation because of sheer simplicity (I don't need the extra features Kopernio, Lazy Scholar provide) and unlike Unpaywall it also gets you versions subscribed by your institution.
How much use are such tools getting? I suspect currently such tools still don't make up a huge amount of usage (many users won't install a Chrome extension and will just Google), but they will continue to grow.
Still, we see that in terms of API calls, Unpaywall has exceeded scihub in usage with over half a billion calls.
Wow, it looks like the @unpaywall database has overtaken Sci-Hub in popularity! We had nearly half a billion calls to our API in 2017, vs ~150M downloads from Sci-Hub. #oa #openaccess https://t.co/cI0wBM1TaG
— Jason Priem (@jasonpriem) February 1, 2018
I suspect a lot of this isn't just from Chrome or Firefox users.
This is because services like Unpaywall that provide a free open API can be potentially used beyond just in chrome extensions. They are likely to grow in importance as they will start getting incorporated into services like link resolvers, ILL/DDS services, databases etc.
The paradigm example here is Unpaywall and Open Access button (OAB). Some examples
1. Unpaywall data is used to indicate free full text in Web of Science , Dimensions and ScienceOpen

Web of Science open access indicators via Unpaywall
2. Unpaywall can be used in link resolvers like SFX , 360link with it coming to Alma Uresolver
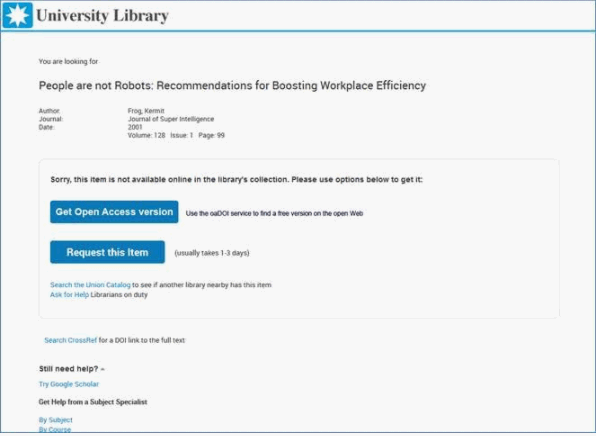
Unpaywall links to open access version in 360Link link resolver
3. UK universities have experimented with incorporating OAB (open access button) with ILL/DDS
How to check and optimise?
Unlike aggregators of repositories, it can be difficult to understand how these tools obtain their data. The following list is based on my understanding and can be quickly out of data as some of these services shift the sources they tap on as time goes by.
In rough order of popularity of services
Google Scholar button - Google Scholar
Unpaywall - Own harvestor (was BASE)
Lean library browser - Unpaywall API
Lazy Scholar - Google Scholar, PubMed/PubMed Central, EuropePMC, DOAI.io, and Dissem.in
OAbutton - oaDOI (now known as Unpaywall), SHARE , BASE, CORE , OpenAIRE, Dissem.in, Europe PMC,
Kopernio - "Open access publishers, Institutional repositories, Pre-print servers, Google Scholar"
Checking shows that DOAI.io (which predates the very similar unpaywall) claims to draw mostly from BASE, while Dissem.in also uses BASE .
So leaving aside the regional repository consortiums like SHARE , OpenAIRE or Life Sciences aggregators like PMC, if you are well indexed in Google Scholar and BASE you cover most of the bases.
The only major exception seems to be Unpaywall, the 2nd most popular service. It used to use BASE but has recently switched to their own harvester.
Though I can't find any unofficial documentation on Unpaywall's harvester, Jason Priem has endorsed the same tips as in BASE (despite having their own harvestor), so it seems you can optimise one for the price of two.
For IR folks looking to maximize their coverage in @unpaywall, BASE, and other aggregators these are great tips. https://t.co/5MxlEYPnGO
— Jason Priem (@jasonpriem) February 23, 2018
The other major one is Kopernio but there isn't any specific information on what is indexed.
Doing your own checks
This can be fairly easily done with services that have APIs including
In particular, I recommend you download from your IR, the records that have full text and run unpaywall API over it to see how well unpaywall detects the availability of full text. The same can be done for OA Button. For the rest, the best you can do is probably sample checks.
Not sure how to use the API? Unpaywall offers a handy batch doi uploader for you to use (up to 10,000 records).
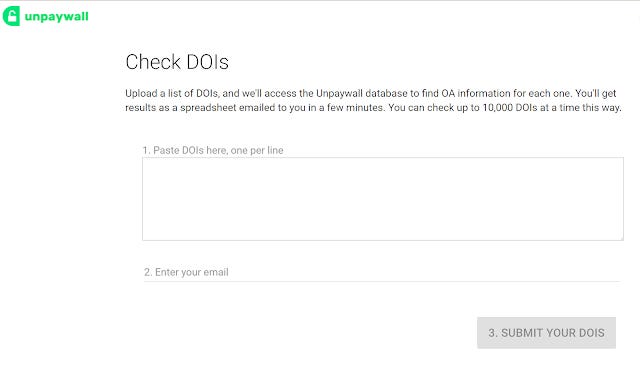
To doi or not to doi?
One thing to consider for Institutional repository managers is the availability of dois in their records.
You might notice that the unpaywall API and the batch uploader only works on dois (and in fact probably only Crossref dois). Does that mean Unpaywall can't find your full text if you didn't add a DOI to the record?
While the Unpaywall API needs a doi, the Unpaywall extension goes beyond just using the Unpaywall API but also does additional checks and fuzzy matching.
That being said, the vast majority of Green #OA in Unpaywall was discovered via our author/title/date/etc fuzzy matching algorithm, which is pretty effective at this point as well. Important that it be good, because very few IR records have DOI in metadata.
— Jason Priem (@jasonpriem) February 22, 2018
Still the advise is DOIs in your IR record helps a lot for discovery of content.
yup, DOIs in OAI-PMH data help us link a repository article to its published DOI, especially in cases where the title has changed or is very common.
— Unpaywall Data (@unpaywall_data) February 22, 2018
In comparison, the OA Button API "accept DOIs, PMIDs, PMC IDs, titles, and citations. Each of these can be passed in as the "url" parameter and the API will try to guess which is provided, or it can be specified by passing the specific type as the parameter name = "doi", "pmid", "pmc", "title", or "citation", I'm not sure if this means it can also fuzzy match contents in IRs with no dois.
In any case, it seems prudent that whenever possible , adding dois to metadata of IR records might be a good idea. This is despite the current Crossref guideline of only using the same dois of final published version of record and author accepted manuscripts versions, while earlier versions such as a preprint should have a different doi and be related to the author accepted manuscript/Version of record with relationship "ispreprint of".
Under "Associating posted content with published content (AM / VOR)", Crossref states
"Once a journal article (or book, conference paper, etc.) has been published from the posted content and a DOI has been assigned, the posted content publisher will update their metadata to associate the posted content with the DOI of the accepted manuscript (AM) or version of record (VOR).
Crossref will notify the posted content depositor when we find a match between the title & first author of two publications so that the potential relationship can be reviewed. The posted content publisher must then update the preprint metadata record by declaring the AM/VOR relationship."
It's unclear to me if many IRs follow this (many/most? don't assign Crossref dois and use DataCite dois) so it might be okay just in the Institutional repository record to assign the doi of the Version of record for all versions of it , even to preprints?
5. Regional consortium of consortiums - SHARE, OpenAIRE, JISC etc
These are regional groups around US, Europe and UK respectively. I don't have much to say about this because I'm not in any of these regions and I'm not sure if they can harvest outside their region, though I suspect OpenAIRE does. As these are big pools of OA content, they are often harvested by services already mentioned. Ensuring your metadata content is compliant with one of these grouping is probably a good idea as well, as I suspect this helps a lot with all the others alreadt mentioned.
Many services also pull CrossRef metadata via API to check for free versions. I don't think many institutional repositories can exploit this even if they are Crossref members except perhaps in cases where the library is a journal publisher and publishes Open Access and mints Crossref dois.
As earlier discussed I'm not sure if adding a "ispreprint of" relationship in the Crossref record of non- AM/VOR records will be picked up by sources using Crossref.
6. Others
There are other aggregators like Science Open, Microsoft Academic of varying importance, but chances are they dip from the pools already mentioned.
ULiège point out that if you have many medical/life science contents it is worth while to add your IR contents to Pubmed's Linkout service. This will expose your content to users of Pubmed. ULiege shows quite a high amount of usage from Linkout.
A interesting thought is handling sources like ResarchGate and Academia.edu. Obviously there isn't much one can do here, except maybe encourage users to link to the IR record instead of posting pdfs directly, but this might no longer be allowed or encouraged by ResearchGate.''
7. Bonus wild ideas
One thing I've long suspected about Institutional repositories is that, Wikipedia is slowly growing in importance as a source of referrals , typically in the top 10 at least , sometimes even top 5.
One natural idea that some have tried is to do is work in links to Wikipedia pointing to IR contents but that can easily cause conflicts with established editors.
A better idea would be to look for citations that already exist in Wikipedia and point them to open source versions in your repository.
I haven't been able to figure out a way to search Wikipedia systematically with a batch of dois, but I've been looking with interest at OAbot. It is "a tool to easily edit articles to make academic citations link open access publications"
"OABOT extracts the citations from an article and searches various indexes, apis, and repositories for versions of non-OA article which are free to read. OABOT uses the Dissemin backend to find these versions from sources like CrossRef, BASE, DOAI and SHERPA/RoMEO. When it finds an alternative version, it checks to see if it is already in the citation. If not there, it adds a free-to-read link to the citation. This helps readers access full text."
Again the same sources we mention above appear, so no additional work required. Still see https://en.wikipedia.org/wiki/Wikipedia:OABOT for advice.
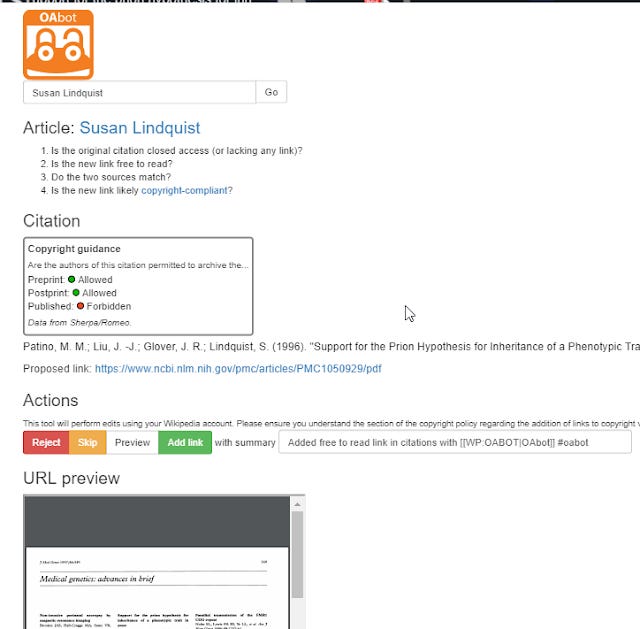
using OABOT to add links to Open Access content citations in Wikipedia
OABOT doesnt seem to add them automatically, but displays a recommended open version and lets the human check and confirm. It would be nice if one could check a bunch of dois belong to your IR but currently this isn't possible and you can check only random ones.
A even crazier idea would be to export IR metadata to Wikidata. There exists tools to batch upload via Zotero but this is experimental.
You can for example use #Zotero to save the bibliographic metadata of the entries in your IR and the export this to QuickStatements: https://t.co/aVnWDBMPCj (works also if no DOI is available).
— Philipp Zumstein (@zuphilip) March 6, 2018
Lastly, I've only focused on article content but datasets is another whole kettle of fish and is a new emerging area, but if your IR includes datasets definitely look at Scholix: A Framework for Scholarly Link eXchange which allows your dataset to be found via Scopus which supports it.
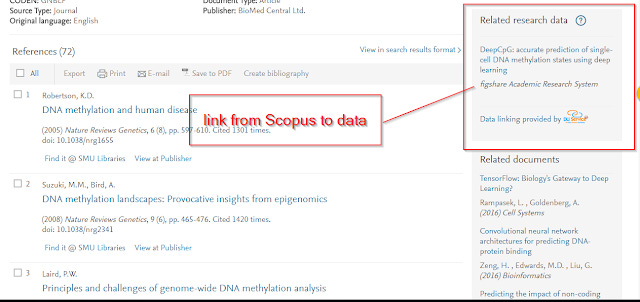
Link to dataset via Scholix in Scopus
Conclusion
This has been a very long detailed look at various ways people find open access content. It looks to me that the following sources are most important to be optimized well.
1. Google Scholar
2. Base - It is a source checked by so many other services
3. Unpaywall - The most popular OA discovery tool outside of GS , it has a presence in link resolvers and important databases like Web of Science and Dimensions
It feels very exhausting to look at so many sources, but chances are if your content is correctly indexed in say BASE , there's a high likelihood there will be no issues in most of the others as well.