


Google Scholar adds review articles filter, Harzing's Publish or Perish 8.0 and OpenAlex launches

A belated Happy New year to all my readers!
The first blog post for the year will be a mixed bag of events or changes that have caught my eye.
Google Scholar introduces "Review Articles" filter
Harzing's Publish or Perish 8.0 launches
OpenAlex including API launches in beta
If you squint a bit you will see a common thread....
1. Google Scholar introduces "Review Articles" filter
Academia's love affair with Google Scholar is well known and I have talked about the reason for this here and here.
Though Google Scholar is extremely powerful it has some infuriating basic gaps in their feature set, even though they have slowly being filling it in over the years.
Of course some of the missing features could be deliberate e.g for legal reasons.
For example, I highly doubt if Google Scholar will ever allow a legal way to mass export records due to possible limitations placed on them by content owners. Currently the best way to do it without writing code to scrape or use an external tool like Hazing Publish or Perish to do the same would be to use the Google Scholar "My Library" function which provides a "Export all" function. However, you will still need to add each record manually to "My Library".
That said not all of the missing functionality can be explained away so easily.
In any case, I noticed Google Scholar added one of these "obvious" missing functionality a few days ago.
You can now filter Google Scholar results to find "Review Articles"!
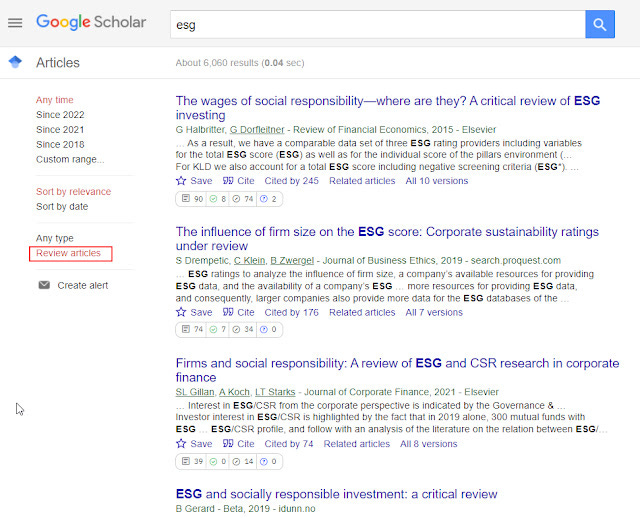
Google Scholar - "Review Articles" filter
Why this review article filter is so keenly anticipated.
When I first noticed this feature, I was amazed. This is a common feature you can see in academic databases (e.g. PubMed, PsycInfo, Scopus,Web of Science) and even academic search engines that compete with Google Scholar such as Semantic Scholar.
As I teach in my workshops on doing a literature review, finding a good review article (review paper, systematic review, meta-analysis....) is a very helpful technique that can save you a ton of time in some scenarios. As a bonus it is often the target of a lot of citations and you can apply other citation related techniques to generate more papers from it.
I'm not the only one who figured out that Google Scholar's huge index would be an amazing hunting ground to find review papers and suggested doing a keyword based strategy to try to find such items in Google Scholar despite the lack of a filter.
In short the trick is you search in Google Scholar with either something like <topic> review or sometimes use the intitle: function and do intitle:<topic> review or other keyword search variants (depending on your need for precision or recall). This generally works well due to the fact that reviews tend to have the word review in the title.
But it now seems that this is no longer necessary?
Is this feature really new?
One thing I did on noticing this new filter was to go check the Google Scholar blog to see if there was an announcement on this. However, I couldn't find anything. I then went on Twitter to look around and I found only 3 tweets at the time talking about it.
One was in Nov 2021, the other two were in Oct 2021 (here's one by a librarian).
Dean Giustini who is a UBC biomedical librarian and an expert on Systematic review (and also the use of Google scholar in Systematic reviews) notes that he thinks this feature has been around since Mid 2021, though he is only able to provide a screenshot taken on Nov 2021.
So it seems based on this cursory search, this filter has been around since 4Q 2021 and possibly by Mid 2021.
Given the heavy usage of Google Scholar and how useful this new feature is - it's intriguing this new feature did not draw that much attention.
Certainly my Tweet and Linkedin post on this drew quite a lot of attention and it seemed for most this was news (and exciting one at that) to them too.
Is this new "review articles" feature that significant?
Like any new feature, researchers, bibliometricians will likely wonder what signals Google Scholar uses to detect "Review Articles".
The least likely possibility is that it is using metadata that is tagged with the item, basically because most items would not be tagged that way. While I can imagine this is one way Google Scholar can detect such items (I still consider this extremely unlikely), it cannot be the main way.
The simplest way to do such a filter would be to create standardized search strategies or what is often called Hedges to detect review articles. You can see here the search strategy the NLM uses to detect Systematic Reviews . Of course the simplified search strategy I teach the participants at my workshop is based on the same idea.
Of course this being Google, they probably are doing some sort of machine learning to recognise such review papers.
Is this new filter by Google Scholar more effective in terms of recall or precision than keyword based strategies? What signals are used to detect such papers? I am playing around with it a bit but I will leave the professionals to study this deeply.
The usual Google Scholar warning....
Josh Nicholson of scite comments on this new development
It's frustrating that such a low bar is cause for celebration. This is Google, the world's best search engine. What is to become of Scholar in 5-10 years? Will it still be here? Maybe monetizing it in various ways would help as it would lead to more innovation in this space. https://t.co/f0BduVEKel
— Josh Nicholson (@joshmnicholson) January 19, 2022
That's the rub isn't it? Leaving aside the fact that one could imagine what Google Scholar could do if they were not a small almost hobby project in Google, academia's reliance on Google Scholar is possibly dangerous, since it leaves the fate of the world's most popular academic search engine in the hands of a commercial company that has proven in the past to have been not unwilling to close much beloved projects particularly ones that are not considered "core" part of the service.
Besides Josh Nicholson, many such as Peter Kraker (of Open Knowledge Maps) , Richard Jefferson (of Lens.org/Cambia) have also questioned the wisdom of letting Google Scholar dominate.
While these experts are conveniently backing their own solutions as the alternative, you can take it from the author of this blog who has no dog in this fight that their concerns are valid. I don't think it is beyond the realms of impossibility for Google Scholar to be closed one day.
But I'm just sure not what we can do about it since FREE + Super effective is really hard to beat.
Even big pockets as deep as Microsoft's have tried and failed. Just as Bing failed to even move the needle against Google, Microsoft's 2nd (or 3rd depending on how you count) attempt to match Google Scholar just ended Dec 31 2021 when they closed off Microsoft Academic Graph (though arguably they managed to prove to many including yours truly the importance and utility of Open Scholarly metadata and the importance of Open Infrastructure).
Technical note : Microsoft Academic Graph is the dataset fueling Microsoft Academic whch is the search engine. For this blog post I will use both terms interchangably.
2. Harzing's Publish or Perish 8.0 launches
Harzing's Publish or Perish celebrated her 15th anniversary in Nov 2021, with the launch of Publish or Perish 8.0.
Most readers of this blog should already know what the Publish or Perish software does, but here's a short summary/
It first began as a tool that could scrape results from Google Scholar and could automatically calculate a bunch of metrics such as H-Index. I could be wrong but it was probably one of the earliest or maybe even the earliest tool that did so.
Over the years, it continued to be supported and developed as Google Scholar evolved, and it even began to support other search indexes beyond Google Scholar, Google Scholar profiles including
Crossref
Scopus (Subscription needed)
Web of Science (Subscription needed)
Microsoft Academic (defunct as of Jan 2022)
Semantic Scholar
and V8.0 brings in PubMed as a source
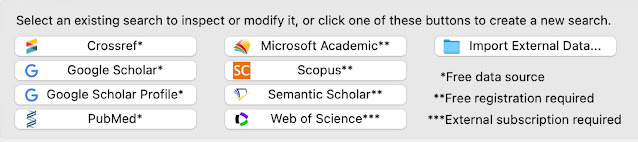
Publish or Perish Data Sources
I wasn't paying attention in November and only caught wind of V8.0 in a tweet in Jan 2022 which provided a round-up of all the new features
I must admit I haven't been paying that much attention to this tool for a while so it was good to look at it again.
Some of the features that I found interesting included
Still I think the following set of features around finding citations was probably more significant
Essentially Publish or Perish has a hard limit of extracting 1,000 records (because GS never shows more than 1,000 or so usually), so if you have more than that you will need to partion your search and do the extraction in batches.
V8.0 adds features that make this doable including the ability to add year ranges to retrieve citing works in Publish or Perish and the abilty to merge citations from 2 or more records.
3. OpenAlex including API launches in beta
As mentioned above, Publish or Perish lists Microsoft Academic as a source they used to support. So it would be good if they can find a replacement to it.
They are hardly unique in this, for example the Science Mapping Tool - VOSviewer also accepts a variety of data sources similar to Publish or Perish including Microsoft Academic.
And while Publish or Perish and VOSviewer aren't totally unusable even with no replacement for Microsoft Academic Graph (since they can accept other sources), other tools like ResearchRabbit or Inciteful which use Microsoft Academic Graph as their primary index will definitely need a replacement to remain functional if one is interested in works beyond 2021.
But is there a replacement? For certain use cases, people have been looking at existing sources like Semantic Scholar or Lens.org (see Inciteful test of both these resources) but there's a new resource that is more directly a replacement.
It is known as OpenAlex by OurResearch , which is currently seen as *the* replacement.
If you are unfamilar with the company, you may be more familar when I mention this is the team behind the popular Open Access finding service - Unpaywall and librarians may have heard of Unsub a tool that helps libraries assess their big deals using various data in particular Open Access availability.
The name OpenAlex is a reference of course to the Library of Alexandria. In this case the dream here is to provide an open index of all scholarly content.
Essentially by combining as many open sources of scholarly metadata out there as possible the dream is to have an index spanning the whole scholarly content universe.
Some of the sources they list as using includes
Microsoft Academic Graph and Crossref (base)
Because we live in modern times, the key part that makes linking all this diverse data sources is the use of PIDs (Persistent Identifiers) - DOIs, ROR, ORCIDs, ISSN, Wikidata IDs, PMIDs,Arxivids and more.
Of course both Microsoft Academic Graph and now OpenAlex do also attempt to cluster and disambiguate entities with no PID but that is a last resort.
While you can think of it like a search index like Scopus , Web of Science or even Google Scholar (less the full text), it is much much more than that.
Similar to Crossref's idea of a Research Nexus in 2017 . Here's how NISO/Crossref puts it in 2021
"Metadata can unite researchers, publishers, funders, and libraries in accelerating research. We see ourselves as key to creating a research nexus: a comprehensive, ever-expanding set of interconnected research objects. These objects can facilitate further research and understanding of what goes into and comes out of the research cycle, who’s involved, who’s funding what, and more. Each research object has myriad relationships — a journal article has many versions, and also consider all that can be related to it: data, contributors to the data, supplemental materials, funders, grants, conferences, conference posters and presentations, open peer reviews, other works that cite the article, podcasts, blogs, tweets that cite or explain the research, and more.
Imagine those relationships painlessly made machine actionable so that a funder can fully assess the impact of their funding, a researcher can discover how their research is being cited and discussed, and research can be placed in context."
The relationships between research objects can also be summed up roughly in two words -"Knowledge Graph". Here's a vision from a researcher.
Super excited about @OpenAlex_org by @OurResearch_org at https://t.co/i7XQic6FYz. This seems like the knowledge graph of scholarly research that we've all been waiting for!
Here's what the schema could look like in network form: pic.twitter.com/vKUeus8D6D— Daniel Himmelstein (@dhimmel) January 11, 2022
More concretely, this is how OpenAlex is structured

Indeed OpenAlex dataset model shares similarities with the Microsoft Academic Graph schema with some changes which can also be seen as a Knowledge Graph.

Compared to Microsoft Academic Graph, some major changes to the schema (my interpretion) includes
Dropping of patent coverage (I believe Microsoft Research had a partnership with Lens.org)
Microsoft Academic graph did a lot of complicated calculations to create a "rank" (Salience?) for entities like institutions, authors, journals/conferences and even topics. This is dropped
OpenAlex will also assign topics similar to Microsoft Academic (seems to be using tags on existing papers as training data), but there will be a lot less topics (only topics with >500 papers will be used). Obviously the algorithms used for tagging is different.
Of course the biggest loss besides the lost of algorithm used (e.g for clustering and disambiguation) is due to the fact that Microsoft Academic Graph crawlers or more accurately the data they bring in will no longer be available. It is unlikely Unpaywall crawlers are as comprehensive or are allowed behind paywalls as Microsoft's. This results in the following
Paper citation contexts not longer updated - You need full-text for this
Random webpage-hosted papers cannot be detected- OpenAlex won't be able to find any more of these as it will be limited to what open sources include and their Unpaywall harvesters which focus on publisher and repository sites only (not the whole web).
Conference instances and conference series - OpenAlex will still be able to "see" a lot of conference papers as long as they assigned a DOI but may miss out conference series and conference instances if they are webpages
And of course, OpenAlex doesn't inherit the exact algos used by Microsoft Research to assign field of study, do disambiguation and cluster if there are no PIDs. It's unclear how good Microsoft's were compared to what OpenAlex is now using.
Still Compared to Microsoft Academic Graph, OpenAlex gains
Linkage to Unpaywall OA status and links
Linkage to ORCID - use of ORCID for disambiguating authors (Microsoft Academic has famously questioned the need for ORCID given the "low" uptake after "heavy promotion for decades")
Full ISSN support - "OpenAlex provides a comprehensive list of ISSNs associated with each journal, including the ISSN-L, the standard for for deduplicating journals."
Use of ROR - the new institutional PID
Why OpenAlex is so exciting - It is for all levels of users
OpenAlex started in beta by releasing a data dump in Nov 2021. This was followed by the API release in Jan 2022
In many ways, OpenAlex reminds me of the strategy behind Unpaywall. Like Unpaywall the data is not only open, but easily used by users of different technical skill levels.
There's the big data dump if you have the need and skill to download and manipulate it and also a OpenAlex API if you want to query results on the fly.
As someone who only started to have a clue about APIs after playing with Unpaywall's API and particularly Crossref's API, I can't help by notice how OpenAlex's API seems to be modelled on those two. This is good news because this means this REST API which supports only Get request is as simple as it can be.
I am not the only one who thinks so.
For example like Unpaywall API there is no API keys to struggle over, you are encouraged to add
?username=youremailaddress
to your Get Request to be put in the "polite pool" which gives you faster response
How simple is it to use?
I have been playing around with searches like
1. https://api.openalex.org/works?filter=institutions.ror:https://ror.org/050qmg959&group_by=oa_status (Output of my institution ROR by OA status)
2. https://api.openalex.org/works?filter=institutions.ror:https://ror.org/050qmg959&group_by=is_retracted (Number of retracted papers by my institution ROR)
3. https://api.openalex.org/institutions/ror:050qmg959 (General info of my institution)
Other interesting stuff I see are by people connecting it to Zotero clients, plot network of related concepts, for more tips see OpenAlex tip of the day.
All in all, OpenAlex API for sure is much easier to use than trying to query Microsoft Academic Graph.
What if the word "API" frightens you? You can still use OpenAlex via the website which will be launched in Feb 2022. I believe this will allow you to search for entities and see the results in a nicely formatted webpage instead of in JSON.
Even now you can get a nice human readable webpage if you know the OpenAlex ID. But how do you know what the OpenAlex ID, say for your institution is? For now there is no search.
For example this is the API output for my institutions
https://api.openalex.org/institutions/ror:050qmg959 , notice in OpenAlex API you can directly add PIDs like DOI, ROR, ORCID etc with the right syntax. In this case I am querying with my institution's ROR.
If you are unfamilar ROR or Research Organizations Registry , it is the new PID registry for Research organizations and replaces GRID. I found my institution's ROR by searching there.
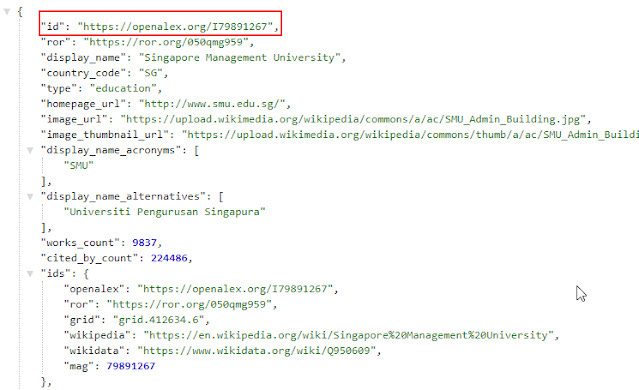
This gives you the Output in JSON. You can see that for this ROR, there is a OpenAlex ID. When I run the OpenAlex ID - https://openalex.org/I79891267
This gets me a very nice summary.
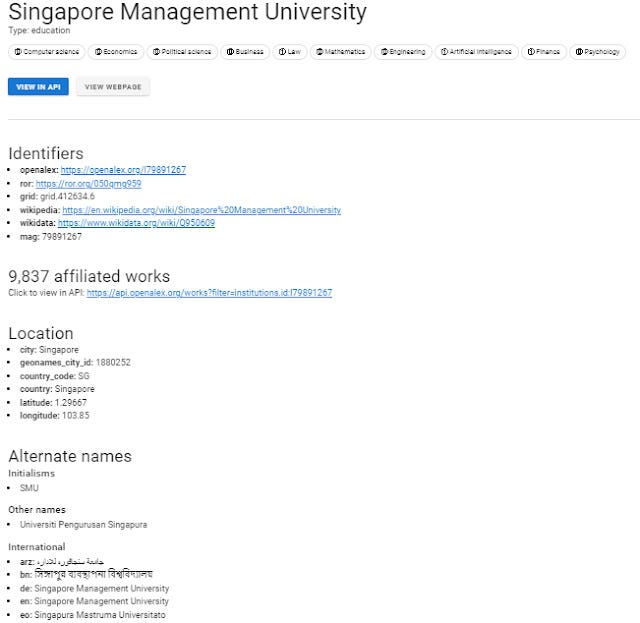
In particular, the field of study tags for my institution e.g. Computer Science, Economics, Business, Law, Finance etc are perfectly on target.
Here you can see it actually one-ups Microsoft Academic because it shows alternate names and for some entries even shows images of the Institution logo thanks to it's use of Wikipedia/Wikidata
OpenAlex Tip of the Day
OpenAlex currently includes 27,077 institutions and 65% of them have associated images!
See key "image_url" in API: https://t.co/JweMx65x55
This example links to the image for our local Douglas College! :)
More info in docs: https://t.co/HAGtPduUDI pic.twitter.com/QF8stDgnFn— OpenAlex (@OpenAlex_org) January 21, 2022
Why OpenAlex is so exciting - It is extremely open
One of the major reasons for Unpaywall becoming so dominant in the OA finding/status space such that it is used by almost everyone both endusers and vendors/publishers is that the data is extremely open.
Like Unpaywall, OpenAlex API has extremely generous limits. As of writing, users of the OpenAlex API are requested to consume no more than 100,000 calls a day though there is no hard cap currently. And yes this is free. I can think only a very small percentage of people or organizations will need more than that.
Similarly as of time of writing, even the data dumps can be downloaded for free without even a token fee!
Just as I praised Google Scholar for being hard to beat + free, OpenAlex like Unpaywall might become popular and dominant for the same reason (assuming the coverage and quality of data is good)
Still when something is free like Google Scholar and OpenAlex, one must ask is the project sustainable? After all, many tools and users may end up relying on OpenAlex as infrastructure (just as they did for Microsoft Academic), and would be heavily disrupted if OpenAlex for some reason isn't continued.

Some apps that relied on Microsoft Academic Graph data as of May 2021
One thing that gives us some comfort with OpenAlex is that the team behind it has a known track record in the Scholarly communications space.
Like OpenAlex, Unpaywall started off with grant support but Unpaywall eventually got popular enough to be financially sustainable by figuring out a business model that was free for most users but would charge the heaviest users (usually commercial entities) for their datafeed which provides daily and weekly changefiles reflecting changes to the database.
While such a method wouldn't work for OpenAlex (since it allows ordering by update date) (and their inclusion of Unpaywall data into OpenAlex might affect their paying customer base there), their track record suggests it is likely they will be able to figure something out to ensure OpenAlex is sustainable.
OpenAlex is committed to Principles of Open Scholarly Infrastructure (POSI)
All in all, we need to avoid a repeat of what happened for Microsoft Academic Graph, where countless organzations relied on the open data released by Microsoft Research but were caught off guard when it was announced the project would suddenly end.
The question here is same as the one raised for Google Scholar earlier, how can we ensure such systems or infrastructure remain sustainable and have visibility/transparency on what is happening and a possible transition plan if the system is to be closed. This is the issue of open infrastructure.
OurResearch the team behind OpenAlex is a non-profit but more importantly it is extremely transparent and one of the first organizations to commit to Principles of Open Scholarly Infrastructure (POSI) which gives us some assurance on using it.

OurResearch and Principles of Open Scholarly Infrastructure (POSI)
By committing to POSI, we can see how well OurResearch does in various aspects such as governance, sustainability.
We learn that all the source code is open on Github (e.g. Curious about how OpenAlex tags concepts? The scripts are here.), almost all the data is open and in many cases considered facts and are not copyrightable.
This means that if OurResarch is to ever close the OpenAlex, it would be much easier for any successor organization to continue where they left off. Compare this to Microsoft Academic Graph, where only the data is still available via ODC-BY but we have no way of reproducing the techniques used to generate the open data.
OurResearch is really transparent, see their transparency page. You can see all their grant proposals (successful and not) at https://www.ogrants.org/ by searching by names - "Piwowar" or "Priem".
More astonishingly to me, you can find salaries and tax filing of the company employees particularly the co-CEO Heather Piwowar and Jason Priem as well as a third employee Richard Orr.
Their main weakness is in terms of governance particularly governance by representative stakeholders as currently they have a extremely small board compared to organizations like Crossref, Datacite etc.
Alternatives to OpenAlex
The idea of bringing together all the open scholarly metadata into one coherent networked graph is hardly a new idea. As far back as 2018 , OpenAIRE was talking about DOIBoost which enriches Crossref metadata with data from Microsoft Academic Graph, ORCID, Unpaywall.
"DOIBoost, a metadata collection enriches CrossRef (May 2018) with inputs frm Microsoft Academic Graph (May 2018),ORCID (Dec 2017), Unpaywall (Dec 2017) for purpose of supporting high-quality & robust research experiments, saving times to researchers" https://t.co/BSSflHAQ1Q pic.twitter.com/Vi88XRqRek
— Aaron Tay (@aarontay) October 18, 2018
Today we have the OpenAIRE Research Graph . How does it compare? I am unsure.
Conclusion
There we have it, Google Scholar, Publish or Perish V8.0 and OpenAlex.