
How does Scopus find and link to related research data? Or an attempt to understand how to link datasets to articles via Scholix

I have been recently thinking about dataset discovery, most recently on the possible impact of Google Dataset search.
One of the areas I've been investigating is the linkage between the article and the associate dataset.
In particular, one of the more eye catching areas where this link appears is in Scopus, where there is a "related research data" link section.
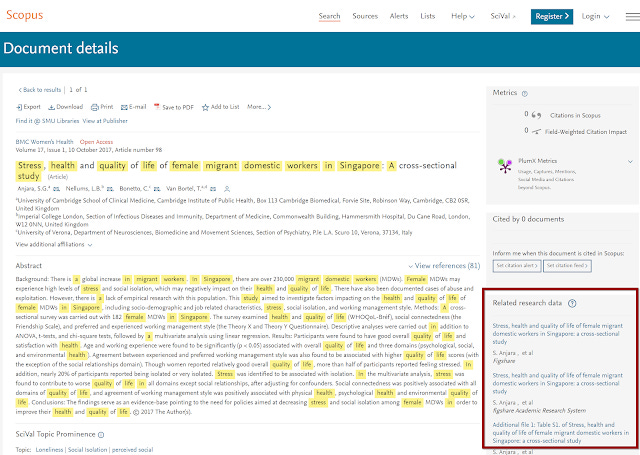
So the question I was asking myself is, how does Scopus know where the research data is and link to it?
More specifically, if you are a librarian who is accepting data deposits to your data repository, how do you ensure Scopus links correctly to your data repository?
This is my attempt to understand how it works, I'm not 100% sure if I got it all right, so please take my musings with a pinch of salt and I would be happy for someone more informed to correct me.
The growing importance of Scholix
I've blogged in the past of the importance of Scholix which is an initative to "establish a high level interoperability framework for exchanging information about the links between scholarly literature and data"
You can either read the paper on Scholix or better yet watch the video below for a high level understanding of Why Scholix and how it works on a high level.
So how does it work? Here's my rough understanding
At a very high level, how Scholix works is that there are several hubs that collate all the article to dataset relationship links (typically doi to doi, though other permanent identifers are allowed).
There are many hubs such as DataCite, CrossRef, OpenAIRE, EMBL-EBI but the first two are probably the most familar.
Scholix aggregates all the article to dataset links in these hubs and allows consumers of such data such as Scopus to query them to find relationships.
Post blogging note - 9th October 2018
William Mischo from University of Illinois at Urbana-Champaign Library, emailed me an alerted me to the use of Scholix in their enhanced bento search. Their state of the art bento search includes links via Unpaywall as well as Scholix allowing datasets to be surfaced together with articles results from EDS.
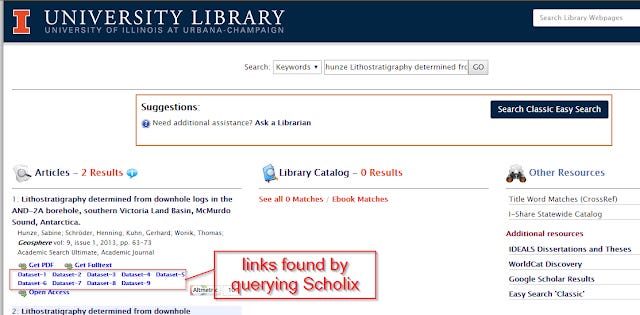
UIUC Library's bento box shows datasets found by querying Scholix's API
Capturing the article to dataset link from the journal end
One way the relationship is captured is if it is captured at the journal end.
If you submit a paper to a journal and you cite a dataset (minted with doi), there's a chance the link between the article and dataset will be recorded at Crossref in their metadata. It all depends on whether the publisher does the job correctly.
From the publisher point of view, there are two ways to record this link to dataset, either as a bibligraphic reference or asserted as a relationship. See this for more details.
I'm not sure how many publishers do this correctly, but I suspect the ones that mandate or ask upfront for datasets and even have tieups with repositories like Dyrad are likely to be doing this correctly. But this requires checking of course. It will be also interesting to investigate which of the two options journals use to create a relationship between datasets and articles.
This is of course the ideal situation where the relationship between article and dataset is made at the time where the paper is accepted and published, but in reality for many journals and in particular non-STEM fields, there will be no attempt to make this link between paper and datasets,
Capturing the article to dataset link from the data repository end
More likely though what happens is that the author will first submit a paper to a journal which gies through the peer review process and is published (with a doi). He will then deposit his dataset on his own to some repository, either a free or institutional data repository like Zenodo, Figshare (both free and institutional versions), Mendeley data etc. This is where it get tricky, the link between the data set doi and the article doi needs to be made correctly from the data repository end.
In either case, Scholix acts as a clearing house for such article to dataset linkages. Done correctly, search systems like Scopus, Europe PMC can query the article doi or the dataset doi and find any linkages as long as the relationship exists whether it is made from the article end, or the dataset end.
But how do you check if the relationship exists or is made correctly?

If you look at Scopus, it points to a service DLI Service - Data-literature linking service
Simply enter any persistant identifer, in this case DOI and you will be able to see what relationships exists.

And indeed as you see below , the system does find a link to a dataset at figshare.
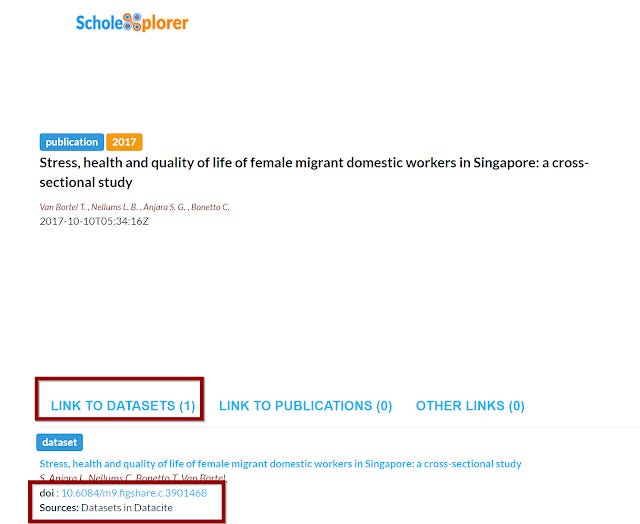
This is because Figshare mints datacite dois and the relationship is captured in the datacite doi metadata which is then aggregated in Scholix.
Things are not as simple as it appears
However things are not as simple as it appears. Say you are depositing a dataset that supports a published article to the free version of Figshare. How do you ensure the dataset is picked up?
A couple of years ago I wrote a paper that was published in Emerald and just for a lark , I added a figure into Figshare. Last month, I went back to see if I could link it up to the paper and see if the dataset to paper link would appear.
But which field should I enter to make a link for the article doi?
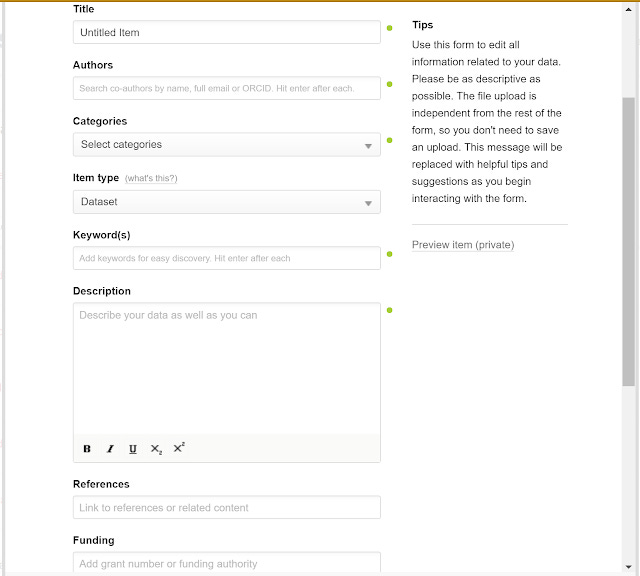
Fields you can submit in Figshare free
For the free version, the only field that I could find that looks vaguely relevant was the reference field.
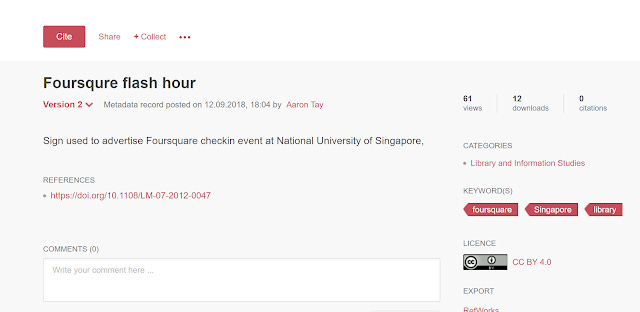
To nobody's surprise but mine, entering it there did not help the link appear in the DLI Service - Data-literature linking service.
I contacted Figshare support and an engineer kindly informed me that the only way to create such a link would be to email them seperately the details. Obviously this isn't ideal.
I also asked about the institutional edition, and was told that a special customized field for that could be turned on, but it had to be mandatory, which also isn't ideal....
In any case, the key seems to be metadata.....

Scholix on Datacite data centres
In addition I was poking around at other data repositories such as those on Dataverse, Zenedo and I noticed that many datasets have landing pages that seem to have links to papers but fail to be captured in Datacite.
One of the key things I suspect is that while data repositories can collect and even display fields for references to papers on their landing pages, but if these data are not captured and registered at the Datacite doi, it is for naught.
For example, if you look at the dataset that was found in Scopus, you can check to see what metadata is registered with the doi that was minted at datacite.
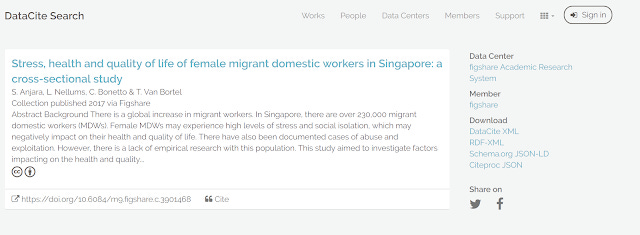
Clicking on say Schema.org JSON-LD, you can see among other things this section
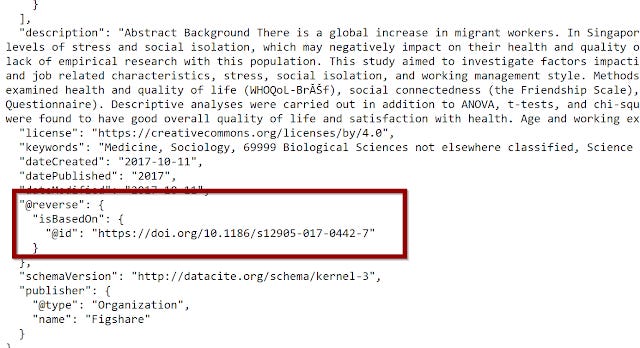
My guess is , this is the metadata showing the link between the dataset and the article and is one of the requirements for Scholix to pick it up from the datacite end.
Conclusion
Creating a link from a dataset to article from the dataset end can be quite tricky. I also have tried to do the same linkage by depositing a dataset into Zenodo. As you can see below, for Zenodo, it is more obvious which field to use to indicate a relationship.
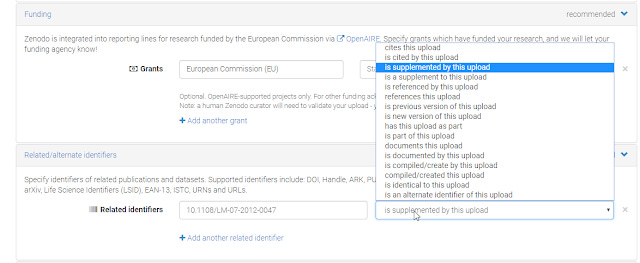
My check shows that registering an article doi this way to your dataset , the relationship is indeed correctly captured at the datacite doi. But it still doesn't appear in Scholix. So my understanding is still not complete....
Post blog note : 2 months after this, Scholoexplorer started to show the link, my guess that interface updates only periodically.
As I mentioned at the start, I don't have all the answers and there's a lot more investigation to be done with various services like Mendeley Data and journals. Authors more deposit datasets into repositories should also wonder, is the journal/data repository they are submitting their datasets (or links to) doing the right things?
It also seems to me data repository managers should definitely study this closely. After all what's the point of depositing datasets if they are not discoverable via the article they are associated with?