
How learning evidence synthesis (systematic reviews etc) changed the way I search and some thoughts about semantic search as a complement search technique

I've spent a large part of my career as an academic librarian studying the question of discovery from many angles. Roughly speaking they include
The "web scale library discovery" (now known as Library discovery layer) angle - This was in the 2010s to 2015 where I tried to implement and spent long hours thinking and studying the impact of the now ubiquitous library discovery searches like Primo, Summon , EDS
Citation indexes and bibliometrics angle - Web of Science, Scopus and Google Scholar - Thinking of web scale discovery tools naturally led me to think how they differed from Google Scholar and cross disciplinary citation indexes like Scopus, Web of Science. Here I studied bibliometrics and more importantly how citation indexes were constructed and clarified my understanding on what citation indexes really were vs abstract and indexing databases and other types of search engines
Open Access and Open Scholarly metadata angle - Here I learnt a bit more about the raw materials of search indexes, from understanding more about DOI registration agencies like Crossref/Datacite, linking to Open Access papers and datasets via Unpaywall etc, the rise of Open Scholarly meta data, thanks to the efforts of grassroot groups like I4OC and I4OA and watched as the fruits of such open data lead to the rise in large mega academic searches like Dimensions, Lens.org, OpenAlex etc as well as what I call citation based literature mapping services like Connected Papers and ResearchRabbit. I even did a minor detour studying the "delivery" angle, on how to make authenication and authorization processes for content and services as seamless as possible
Information retrieval and Large Language Models - More recently, I started looking at the magic of Large Language Models, Retrieval augmented Generation based search and started reading more formally things from traditional information retrieval areas since this is the foundation of search. This itself now draws from two different subfields of Computer Science - NLP (eg BERT and transformers) and traditional Information retrieval focusing on systems (think TF-IDF, BM25, Text Retrieval Conferences (TREC) etc), and this survey provides a good introduction of the later to practioners of the former.
There are of course many other areas that I wish I had more knowledge of, such as looking at it from the lens of linked data/knowledge graphs, metadata schemas etc but throughout it all, I was long aware of a body of knowledge posessed by a special group of librarians who were masters at evidence synthesis. I knew they went way beyond the basic nested boolean search strategies that we taught at our freshman information literacy classes and all I knew was they were truly masters of search.
As ChatGPT put it in a whimsical way
In a realm where boolean search strategies were mere stepping stones for freshmen wandering the vast libraries of information literacy, there existed a clandestine order of librarians. These weren't your garden-variety book custodians, oh no! They were the fabled evidence synthesis wizards, cloaked in the mastery of MeSH and fluent in the ancient dialects of the Evidence-Based Medicine Pyramids. With a flick of their wrist, they navigated the treacherous terrains of RCT and research designs with unparalleled grace. They were the unsung heroes in the quest for knowledge, embarking on epic journeys to vanquish the dragons of bias and conjure the magical elixirs of meta-analysis. Through their sage understanding of reproducibility, they wove together strands of disparate data, creating tapestries of insight that illuminated the darkest corners of inquiry. In the hallowed halls of academia, they were the keepers of truth, guardians of the grail of evidence-based practice, and the bridge between the realms of known and unknown.
I was so in awe about them when 10 years ago, a Phd in area of Public Policy approached me for help with a systematic review, I threw up my hands and directed them to the medicial librarians (at my former place of work).
But still I couldn't help but notice the stuff they studied and produced was SO useful. For example, I was blown way by Neal Haddway and Michael Gusenbauer's amazing work analysing the tiniest details on the capabilities of a wide variety of academic search engines (see also SearchSmart a free tool I use sometimes to check for academic search tools) and the interesting work released at the yearly evidence synthesis hackathons.
Even before that I was really impressed by the rigor of the work they produced around the possibility of using Google Scholar for systematic reviews. Or how evidence based the guidance in conducting standards like the Cochrane Handbook for Systematic Reviews of Interventions was(I loved reading papers where they try to determine the value add of various supplementary methods such as citation searching).
But in 2020, with COVID in full swing, I finally decided to buckle in and try to learn formally this magical art of evidence synthesis. I was partly inspired by all the debates around meta-analysis on COVID related issues (e.g. meta-analysises giving totally different estimates on fatality rates of COVID-19) and partly I thought given my interest in all things discovery, it was high time, I learnt evidence synthesis formally.
1. Learning evidence synthesis at least the principle of it wasn't really that tough for me
The main barrier to me learning evidence synthesis is that I really wasn't that interested in clinical medical type subjects, but when the Campbell Collobration made a systematic review and meta-analysis online course that focuses on social science disciplines in June 2023, I immediately took the opportunity to take the free course!
To be honest, while doing the course, I found most of it pretty familar to me.
Part of it was my general familarity with the technical aspects of database and searching. For example, I was long aware that Web of Science is not a database but a platform and I even know that specifying Web of Science Core Collection is technically not sufficiently reproducible because different institutions may have different holdings/year coverage!
Also through my time studying open science issues and reading about reproducibility, made me sufficiently familar with the idea of evidence synthesis as a reproducible search. The idea that one should look for grey literature and not filter to only "top" journals because of the file drawer effect (and do critical apprasial for quality assessment) were not new ideas to me.
I also was included in some past efforts to see how reproducible Google Scholar across different locations...
As expected the parts I found most difficult involved statistics and critical appraisal as I was relatively weak at understanding research design.
See some of my thoughts in tweets here and here.
I still don't think I am really a evidence synthesis librarian (I don't get enough real practice) but I know enough to fake being one :)
2. Even though I don't need to do full fledged Evidence synthesis searching often, it has changed the way I search
Since I formally took a course on evidence synthesis, I had only a few opportunities to formally do evidence synthesis once (and it was actually a update of a existing systematic review where I helped translate existing search strategies to the platforms we had access to).
In general, my institution just doesn't do a lot of formal systematic reviews or meta-analysis, though there is quite a lot of demand for help with doing literature reviews.
Still, I find that learning how to do evidence synthesis has slowly changed the way I think about searching.
IMHO, the fundamental difference between librarians trained to do evidence synthesis and most searchers including even librarians (particularly people who come from information literacy) is that they have a viewpoint that aims at high sensitivity or high recall searches, while the average searcher or even librarian tends to optimise for higher precision.
Mind you, that itself is not wrong if you are aware of what you are doing and that is what you are going for. But I find, often people only have that one mode of searching and aren't aware they could do it differently.
For example, in the past when asked to construct a search query, I would try a few keywords, maybe combine them together in a nested boolean fashion and skim through the first few results to see if the results were mostly relevant.
While I am not saying precision in searches isn't important to save time, this was still fundamentally a viewpoint that worried about saving time and/or getting a "good enough search" as opposed to one that optimised or at least equally slanted towards not missing relevant results when possible.
More recently, I started to do a small but simple thing. I would ask for (or find myself) some target papers that were definitely relevant and kept it aside. Independently of this, I would craft a search strategy and try it out.
After doing this a few times, I was amazed at how easy it was to make a silly mistake creating search strategies. I would inevitable come up with search strategies that miss out target papers.
So for example, I would search in Scopus with my first search strategy and realize I made a silly error forgetting to do a wildcard or forgetting an obvious synonym and miss out a relevant paper (and yes the missed paper was indexed in Scopus). Other times, I would add keywords or whole concepts that I thought were definitely was needed and it turned out the relevant paper did not have that at all.
Worse yet, I notice taking the word of a domain expert (someone familar with the literature to some degree) didn't necessarily mean you were safe.
For example, I was working with a domain expert in a certain area relating to environment science and the person insisted that all the papers he needed was of the following form
(A OR B OR C) AND (D OR E) AND (F OR G)
I was a bit dubious on whether F OR G was necessary but I was assured it was. But when we did the search live, we noticed one of the target papers was missing. It took a while to figure out why, but in the end, we realized the paper lacked the keyword F but instead had H!
I have done this enough times now to realize this isn't unusual.
Notice how if all you did was to look at your search results (without having a seperate target paper to compare against), you would by definition not notice your search wasn't the best.
That said, I do understand most of the researchers I help with literature review searches even though they claim to want not to miss relevant papers they definitely have a lower threshold on how much effort they want to spend looking through or screening papers than most researchers doing actual evidence synthesis.
That is why I tend to ask the researcher I am helping how many papers they are willing to screen though to help guage how broad a search strategy to use and make decisions on trade-offs.
As a librarian helping with the search strategy, I realize I have to straddle the challenge of trying to increase recall but at the risk of the researcher deciding not to use the search strategy I suggest because it has too much results, and at the other end filtering too much to reduce the number or results to a reasonable number and lose relevant papers.
In my context, a lot of the researchers I help insist we narrow down to a limited set of journals, which is of course not kosher by evidence synthesis principles (bias from only looking at top impact journals!). But this also means , I can afford to do VERY broad searches (since limiting by journals will cut down on a lot) and the cost of missing even one relevant paper is far worse than usual
This is also why live searches and experimenting are very important, rather than discussing search keywords on paper abstractly. Even domain experts often do not have a sense of how keywords they propose will affect the number of results retrieved.
BTW thinking of sources to search is another area where evidence synthesis thinking leads you to do things differently but this is worth another post
How do you know the search strategy is effective?
A few collegues also joined me to do online courses on learning evidence synthesis, and one comment I heard the most is they were surprised that these courses were mostly focus on theory and methods but did not actually make one pratice on keyword construction search strategies.
Sure things like PRESS Peer Review of Electronic Search Strategies: 2015 Guideline Statement exist but even following the checklist feels like more an art than a science.
There doesn't seem to be a way to actually learn to get good at constructing search strategies beyond lots of practice.
But here we run into a problem, to actually learn from practice, we need actual feedback. But how do we know if we did well or badly? This is why I suspect many searchers think they are way better searchers than they actually are , particularly if they don't go out of their way to test their searches.
Again imagine a scenario where you are asked to help a research team come up with keywords. You do your best and use some common sense keywords, chain them in a nested boolean fashion and skim the first n results and they look okay. Worse, you hand it off to a research team and they never come back to you to iterate the search or maybe they actually just use exactly what you found and screen down and cite what was found. How would you ever know your search didn't miss out obvious papers?
As I said, the simple act of trying to see if my search strategy found relevant target papers , greatly shook my confidence that my search strategies were good. This made me paranoid. How good were our searches anyway even after I corrected for the obvious mistakes?
I know of course that in reality properly done evidence synthesis searches, do more than just boolean searches across multiple sources but also consult experts, do hand searching, do citation chasing etc. Here, I am just considered about the search strategies.
One of the things I recently did was to actually look at papers that resulted from support by the literature search support we did.
So for example, we were recently acknowledged in a review paper which covered an extremely broad topic. I extracted the references and compared it to see how many of the candiates papers we gave. We in fact did the following
Did a Scopus search with a fairly complicated nested boolean search - roughly 3,700 results
Was provided with a set of 40 known relevant papers - using Citationchaser - extracted citations (1,388) and references (950)
I am not sure if this is a fair test but I was wondering of the 83 references that were finally cited how many of them were in the unique set of 1+2 ?
For purposes of this blog post the actual results don't actually matter. But essentially I found of the 83 references cited only 19 were in (1) + (2). Is this good , bad or expected?
To further complicate matters of the 83, 33 were from the 40 known relevant papers, so realistically, we could find only 83-33 = 50 of the remaining papers. So say if (1) + (2) found 19, it is a rate of 19/50 or 48%.
I am also wondering if the researcher we gave the results to actually screened the candiate papers we gave her and found even more papers on top of those, or if she ignored it and did the search her own way and after iterating the search many times found the additional 50.
I am still thinking where this is a fair way of judging the quality of search strategy. This is because it may not be realistic to expect just keyword search to find most of the relevant papers and in reality you need a combination of different techniques.
3. Semantic Search as a complement
One of the ways in which new academic searches like Elicit, SciSpace are changing is in the way they change not how but also what is retrieved in the search results. (Elicit also generates a paragraph of text as a direct answer with citations, but this isn't what I mean here)
By combining results from both standard lexical search like BM25 (a improved version of TF-IDF) with results from semantic search (typically a dense embedding type system) and doing a reranking (probably with computationally expensive rerankers) , academic searches like Elicit have the possibility of overcoming the shortcomings of straight out lexical keyword searching and surface relevant documents which may not have the exact keyword used. (See this discussion of Boolean vs Lexical search vs Semantic Search/dense embeddings)
It might be some search systems are using only BM25 a lexical search for the first stage retrieval followed by a crossencoder reranker using BERT or similar models. On paper, this might not bring the same benefits as having a semantic/embedding type search as the first stage retriever as the initial BM25 might already miss out relevant documents if the wrong query was used but in practice it's actually still very good and hard to beat as a baseline.
One thing I have been trying is to try out searches in Elicit, SciSpace with queries and looking at the top 50 results for relevant papers and using this as target relevant papers. You could of course do this with a typical lexical search based system only and it will still give you some clues on what keywords to use but clearly this will be a lot more effective for search engines that also use semantic search/embedding type technology as this might surface papers that don't have the query terms at all.
One of the tricks about using systems like Elicit is that they recommend that you type what you want in full natural language and not keyword search (where you drop the stop words) for better results.
I probably will cover this in another blog post, but the literature I am looking at suggests (based on experiments) that transformer based systems (typically BERT or dervivatives) do better ranking and reranking if the query terms are in natural language as opposed to keyword.
So for example do
Is there an open access citation advantage?
as opposed to
open access citation advantage?
This is what we would expect using purely theory, because unlike standard bag of word/lexical search methods, BERT type models are able to take into account order of words as well as words that might be considered stop words typically.
Below shows a simplistic example of how embeddings "understand" words in the context of a sentence rather than just by individual words.
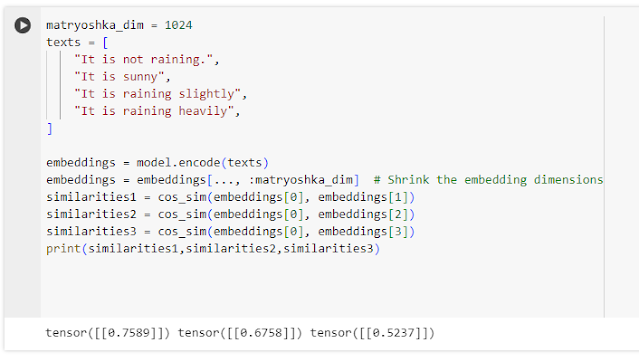
Above shows that when you embedding the above four sentences in a state of art sentence embedding model and try to compute cosine similarity, the system knows that
"It is not raining outside!" is most similar to "It is sunny" (score=0.7589) as opposed to "It is raining slightly" (score=0.6758) and "It is raining heavily (score=0.5237).
It seems to "understand" the "not" in that sentence modifies "raining"...
Interestingly when I use a smaller emebdding body with only 64 dimensions instead of 1024, the scores are 0.8428, 0.7141, 0.5489 keeping the same ordinal ranking, so one can probably save storage space using a small embedding model with just 64 dimensions! This shows the whole point of the Matryoshka Embedding Models Or Russian Doll embedding models where the first few numbers in the embedding are more important so you can use smaller embeddings with roughly the same result.
As a technical aside
I've been reading the literature on information retrieval and current state of art efforts involve trying to use the superior NLP capabilities of cross-encoder models to "teach" simpler sparse embedding models to better represent queries or documents, the hope here is to automatically train sparse embedding models that are as accurate as the dense embedding models but are less computionally expensive to run than dense embeddings and are more interpretable to boot.
For example, representing weighting using TF-IDF clearly isn't the best way to capture semantic meaning, but with the right "teaching" by BERT models, the weights could take into account synonyms via query or document expansion etc.
See for example, DeepCT and HDCT: Context-Aware Term Importance Estimation For First Stage Retrieval
Term frequency is a common method for identifying the importance of a term in a query or document. But it is a weak signal. This work proposes a Deep Contextualized Term Weighting framework that learns to map BERT's contextualized text representations to context-aware term weights for sentences and passages.
See also Deepimpact, COIL etc.
It seems to me the same idea can be transferred to using such models typically BERT type models to help human systematic review librarians adjust their keywords?
Conclusion
Experienced/real evidence synthesis librarians looking at this piece probably might think what I am saying here is obvious but to me, a pretty experienced librarian in the area of discovery , a lot of what i wrote above is fairly recent insights thanks to thinking a bit more like a evidence synthesis librarian.