
Identifying seminal papers - some methods -scite citation statement search, Q&A systems, Reference Publication Year Spectroscopy (RPYS)

I was recently asked a question - how do you find seminal papers/work/research?
My first thought was just to read (articles, reference works etc)! But my second thought was, that's actually quite an interesting question, as I throw around the term "seminal paper" all the time in workshops. This is often in the context of doing citation chasing or using it as a seed paper to do citation tracing or throwing it into a tool like Research Rabbit, Connected Papers etc.
But is there a efficient quick way to find seminal papers without doing much reading?
In this blog post I explore the following
Searching citation statement/context in scite.ai for seminal papers
Asking academic discovery systems which use large language models like OpenAI's GPT for Q&A capabilities like scite.ai, Elicit.org etc to identify those papers directly
Using "Prior works" feature in Connected Papers
Using Reference Publication Year Spectroscopy (RPYS) technique with Bibliometrix/CitedReferencesExplorer (CRExplorer)
I conclude that such methods are fairly reliable , as they tend to surface similar works, however they may not be the easiest to do. More study needed of course!
Perhaps as confidence in such detection methods grows, academic search engines will have a filter/feature for such works?
#1 - Searching citation statements/context in scite.ai for keyword phrases like "Seminal works" + Topic
The most obvious way to figure out if something is a seminal work would of course be to notice when some author in a literature reviews calls a work a seminal work. But can you do a keyword search to pick such papers up immediately?
I've blogged about scite.ai multiple times and how it allows you to restrict your search to the citation statement/context (essentially the sentence with in-text citations and one or two sentences before and after that) and it seemed to be the perfect tool to do this.
Scite.ai also has a fairly powerful advanced search, supporting nested Boolean, wildcard support (single to multiple character) and even proximity operators and search history, so we can do powerful search strategies.

scite advanced search builder
For my purposes, I just did the following
The results (4) are decent.

scite result #1 searching for seminal papers on adaptive governance

scite result #2 searching for seminal papers on adaptive governance

scite result #3 searching for seminal papers on adaptive governance

scite result #4 searching for seminal papers on adaptive governanc
Can you improve on this to find more seminal papers? You can try some of the following phrases. (You will need to convert them to scite search syntax)
"Pioneering work" OR "Pioneering study" OR "Pioneering paper" OR "Pioneering research"
"Foundational work" OR "Foundational study" OR "Foundational paper" OR "Foundational research"
"Landmark work" OR "Landmark study" OR "Landmark paper" OR "Landmark research"
"Ground-breaking work" OR "Ground-breaking study" OR "Ground-breaking paper" OR "Ground-breaking research"
"Fundamental work" OR " Fundamental study" OR "Fundamental paper" OR "Fundamental research"
"Pivotal work" OR "Pivotal study" OR "Pivotal paper" OR "Pivotal research"
"Classic work" OR "Classic study" OR "Classic paper" OR "Classic research"
Other terms to consider - "laid the foundation", "builds on", transformative, historic, crucial, fundamental, game-changing, definitive etc.
Can we use other databases searches that cover full text?
scite.ai is unique in that it collects not just the usual meta-data but also citation statements/context.
The only other major source of citation statement/context is Semantic Scholar, however there is no way to directly search for text in citation sentiment in the web interface as far as I know.
The API allows you to look for papers and for each paper look at the citation statement (if available) but I don't see an easy way to search for it. If you know how to do it, do let me know.
https://api.semanticscholar.org/graph/v1/paper/search?query=psychology&contexts=seminal&fields=url,abstract,authors
https://api.semanticscholar.org/graph/v1/paper/search?query=psychology&contexts=seminal&fields=url,abstract,authors
But why not try it on databases with full-text and when it comes to full-text the obvious one to try is Google Scholar which indexes by far the most full-text.

Trying to find seminal papers on Adaptive governance
As you can see GS does find some good hits but there are a few problems. Firstly, you can't filter only to citation statements, so you get hits in title and all parts of the paper.
You can't even filter just to full-text and exclude abstract in Google Scholar. (You can exclude keywords in title at best in Google Scholar).
Secondly, even when you do get a good result (second result above), Google Scholar snippet view is unpredictable in what it shows, and you can't tell at a glance if it is a good result unlike in scite.ai.
There might be some database that allows you to restrict matches to just full-text and exclude abstract (and not include title or other metadata) but I currently can't think of any big ones and even in such cases it might have more false drops without restricting to citation statements, as the keyword and seminal work phrases might be matched for incidental reasons.
#2 Can we directly ask discovery systems that have Q&A capabilities to find seminal papers?
Interesting future idea - we live in an age where transformer based deep learning models are showing amazing NLP (Natural Language Processing) capabilities and discovery systems like Elicit.org, Consensus.app and even scite.ai itself are using such systems. Instead of typing keywords and looking at a list of papers, these systems try to extract answers directly from papers and present the answers to you. (For a recent coverage see my post - Q&A academic systems - Elicit.org, Scispace, Consensus.app, Scite.ai and Galactica)
In particular as I write this, scite.ai is trialing in closed beta a new Q&A service which tries to answer questions in prose from citation statements. Can we try to directly ask for seminal papers using this service? The results are somewhat mixed.
Using the beta Q&A feature and asking it directly for seminal papers gives mostly wrong but occasionally interesting results. The results for asking for seminal papers on adaptive governance are horrible but below shows a slightly better result.
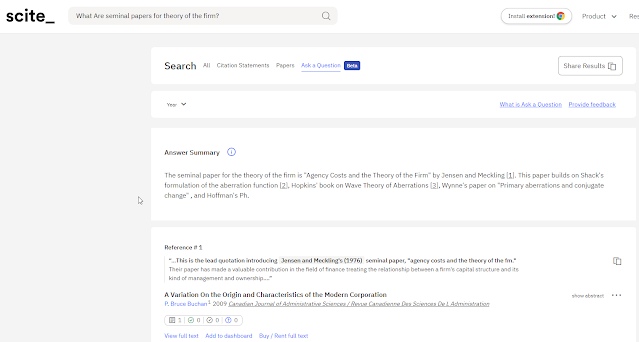
Using scite's new "Ask a question" to ask about seminal papers on theory of firm.
Using Elicit.org isn't much better. Yet sometimes it gives interesting answers, for example below it recognizes it doesn't know (a common response, reminiscent of ChatGPT's modesty)

Asking Elicit - what are seminal papers on theory of the firm
I got similar results with Concensus.app (not shown).
It's hard to say what the problem is here. In the case of Elicit.org it's possible that Elicit.org just doesn't have sufficient full-text to answer such questions (abstract alone can't help) and it just takes answers from it's top 5 ranked papers. That said I am impressed by the way it writes - it tends to say it can't actually directly or explicitly answer the question, but the papers it finds "provides some insights that may be relevant/useful to the question" and then it tries to compare and contrast. Feels extremely ChatGPT like.
With scite.ai, it's more disappointing the results are not good because we know the data isn't an issue as keyword searching gets decent results, so the Q&A type search should in theory be able to get the same answer. More tuning needed probably.
Hopefully, this is an area of further research.
But if this is eventually cracked, I can see this technique becoming a great boon to researchers in the future. Imagine being able to ask the system to compare two different theories or list different frameworks/theories, compare definitions etc. In fact, some of the elicit.org results look quite nice when you ask complicated questions on theories...
Using bibliometrics to detect seminal papers
The method above of searching text in hopes of identifying seminal papers is I think fairly novel. It's main issue is it may not work if no-one explicitly mentions which papers are seminal.
Also, as I already mentioned, it probably works best if you have a database where you can restrict searches to citation statements. Currently, scite is the main one but even scite's coverage of citation statements is far from complete.
Seminal papers are generally papers that people tend to cite so the obvious alternative is to use bibliometric techniques to identify them, right?
The obvious method - search then sort by citation count (not ideal)
One of the most obvious ideas is to grab a set of papers/works on a topic and look at which are the most cited.
Without thinking too hard you might try this
1. Keyword search in a database citation index like Scopus
2. Sort by most cited
3. Look at the top few results.
See an example below.

Using Scopus to find seminal papers by searching keyword and sorting by total citations
While this might sometimes work, this isn't strictly speaking the best method for the following reasons.
Firstly, high cites may indicate review papers, which while useful isn't what we are looking for.
See research on whether citation counts help in distinguishing important seminal research from literature reviews with a degree of accuracy
Though you can get around in some databases like Scopus by filtering out review papers.
A bigger problem is by searching directly the database for possible seminal works means you assume the seminal work is actually indexed in the database or citation index you are search in.
This may be a bad assumption, because often seminal works are older and/or monographs that may not be directly indexed in the citation index you are using so doing a keyword search on X, and sorting by citation count may miss them.
For example, in Scopus if you search directly, you will never find a classic monograph like "The Sociological Imagination" published in 1959 in the main search results, despite the fact that many sociology articles do cite this monograph.
As I noted in a earlier blog post, Scopus and Web of Science do index some monographs and books but they tend to be newer ones. They unlikely to index older classic works in say the 60s or even 80s.
Lastly, often the seminal work may not even have the keyword you used to search for even if they are indexed before they predate the term being defined.
So, what is the solution? A better method is to look at the references of relevant works in the subject to see what is cited the most.
This ensures you won't miss out a seminal work even if it is not directly indexed.
On the face of it, this doesn't seem to be an issue in Scopus, since you can select papers than select "view references" of these papers , then sort by citations. Below shows the steps

Use the view references function in Scopus to look at references of papers
Yet the results are odd.

Scopus list of references of papers
All you get for the most highly cited references are general references to works like R (the programming language), statistical methods etc and nothing to the actual topic.
This is yet another problem.
Strictly speaking you shouldn't be using total cites, but only cites by papers in the area. So, for example, a seminal paper on say sustainability should be one which has highest cites from other papers on sustainability only and not one that has highest cites because it was cited by other papers from other areas for other reasons.
In bibliometrics this is often distinguished as "global citations" (all citations) vs "local citations" (citations from only selected papers in the area) and by sorting by "global citations" you are just going to get works on general method or data references because those are most common.
Given all these problems, we will need to use specific tools....
#3 Using Connected Papers - Prior papers feature
So, to recap, we want a tool that does the following
1. Identify a set of relevant papers on topic
2. Look up references of those papers.
3. Rank the references by "local citations" ie - count only cites that come from those set of papers in #1
Currently one of the easiest tools to do this is via ConnectedPapers - Prior works feature

Using Connected papers - prior works feature to identify seminal works
With Connected Papers you can enter one seed paper and it find other similar papers based on "similarity" creating a "similarity graph". From there you click on "prior works" and it will find "papers that were most commonly cited by the papers in the graph".
This is exactly what we want. Importantly, we should sort the resulting papers by "Graph citations" which only includes citations from the identified papers that we care about.
My adhoc testing shows this is not bad a method but results vary hugely depending on the initial seed paper you choose. This is the drawback of not being able to manually specify paper by paper what is relevant but instead relying on the system's algorithm.
Are there other systems such as ResearchRabbit, Litmaps, where you can manually enter papers and do the "prior works" type of analyse? If there are any, do let me know.
#4 The most professional method - Reference Publication Year Spectroscopy (RPYS)
If there are any bibliometrics guru's who made it down to here, I can hear some of them screaming to use the Reference Publication Year Spectroscopy (RPYS) method invented in 2010.
When I first read about this method it sounded really daunting. The term "Spectroscopy" evokes some stem-like concept.
RPYS is a bibliometric method which can be used to analyze the historical origins of research fields or researchers. This method analyzes the cited references (CR) and especially the referenced publication years of a publication set.
In fact, the idea isn't that complicated and follows from what we have discussed so far.
As explained above the idea here is to look at cited references (CR) of a set of papers to try to identify seminal papers of an area. But the question becomes what criteria should we use to decide a paper has abnormally high cites and are candidate seminal papers?
In order to identify those publication years with significantly more cited references than other years, the deviation of the number of cited references in each year from the median of the number of cited references in the two previous, the current, and the two following years (should be looked at).
In other words, you compare the deviation or difference between the number of cited references in a year against the average cited reference for 5 years and if you see a peak, there is a candidate seminal paper.
We will see later why we do this by cited reference year as opposed to individual works.
Why the fancy term "Spectroscopy"? I think, if you look at the favored way of representing the results (see below) you will see why.
Tools for RPYS
There are a couple of tools to help do RPYS, one is CitedReferencesExplorer (CRExplorer). The other more general and newer tool is Bibliometrix -a R Package designed to support bibliometrics work.
You will notice many of these tools tend to focus on Web of Science data (CR is a field in Web of Science for Cited references), and while many support Scopus as well, there is some conversion needed.
Here I will use Bibliometrix instead which supports importing Scopus data directly.
I won't go into the use of Bibliometrix and Biblioshiny the shiny app but I have written a piece reviewing them here.
Once you have imported the papers, you can run those dozens of different visualizations but for own purposes there are two main ones we want to look at.
Easiest is just to look under "cited references" and select "most local cited refereces", then generate the table/visualization.

Most local cited references in Biblioshiny - "Citations" here are presumably local citations not total
The gives you the references that are cited the most by the papers you imported into the system. This is effectively the same as using Connected Paper's Prior works feature but you can choose which papers to be included as the initial set unlike Connected Papers.
Note that the highlighted works are cited references so they may not always have full details, but you should be able to figure them out.
This might be all you need.
But maybe you want to go all the way to act like a professional bibliometrics expert and actually do RPYS.
If so click on "Reference Spectroscopy" and generate the graph. Below is what you will see.

Reference Publication Year Spectroscopy (RPYS) graph generated by Biblioshiny
The graph above can be hard to see , so let's zoom in to the publication years where there are peaks

The red line basically shows divergence between the number of cited references for the year vs from the median of the number of cited references in the two previous, the current, and the two following years (5 years).
So from the graph for example you can see a peak in 2003 (if fact it's the highest). This is the year when the number of references to paper in 2003 was much higher than the median citation from 2001, 2002, 2003, 2004, & 2005.
This indicates a seminal paper candidate was published in 2003.
This is in fact hinting to Stern(2003)'s The Struggle to Govern the Commons is a seminal work. It is comforting to note the same work also appears via other methods including keyword match in Scite and Connected Paper's Prior works method!
There are also other peaks at 2009, 2005, 1990, 1978, 1973 etc.
But wait a moment, the graph only shows a year, how do I find the actual work?
Let's try to investigate say the lower peak at 1990.
To check 1990 for the candidate seminal paper simply click on the tab, "Table - Cited References", then filter year to 1990. The answer should be obvious.

Looking at cited references in 1990 from Biblioshiny to identify seminal papers
Notice that the cited references are not 100% clean, there are 7 variant cited references for Ostorm(1990)'s book - governing the commons.
In this case it doesn't affect the results because we analyzing at the publication year level and the different variants merge because they have the same year but if the cited variants diff by publication year, some cleaning is needed first or we may have misleading results.
Conclusion
This has been a long post trying to find shortcuts to identifying seminal works quickly. Though I did not formally test the methods, they looked reasonable to me and often they converged on the same works which is comforting.
It is definitely a good trick to consider trying if you want a quick lay of the land. Though most of the methods are somewhat complicated. I suppose just as citation indexes and even Google Scholar have increasingly added filters for review papers, they might start doing so for seminal works, if detection methods become better.
That said, I am unsure how useful these methods are for a researcher who needs to gain deep familiarity with their research area. This involves reading anyway and you will automatically pick up which are seminal papers anyway from the background reading they have to do without needing such tricks.
Well until Large Language Models advance to the point they can do literature review as well as the average researcher, I guess!