
Knowtro and Citation Gecko - 2 tools for literature review with a twist for Phd students & researchers

Update 2023: Since I wrote this, Knowtro was discontinued.
The closest tool I know of that is similar is System Pro, though as of time of writing (May 2023) it extracts only from PubMed.
Another tool that can create a research matrix of papers with preset and even custom variables is Elict.org. - See 3+1 Innovative tools that can help you create a Literature review — Research Matrix of papers — Scholarcy, Elicit.org, Lateral.io and Notion/Obsidian/Roam Research
Today everyone doing research including students and faculty in most fields instinctively reach for a keyword based tool like Google or Google Scholar to do a literature review. The other major tool in their tool kit would be to do citation searching, by searching references in key papers and/or papers that cite their papers of interest.
In this blog post, I will review two free tools that help literature review but with a slight twist from the norm.
Firstly, I introduce Knowtro which does what I call a findings first approach to search as opposed to a paper first approach. By extracting findings from papers and allowing you to browse and search through them, you can quickly review what past papers have done in terms of variables studied and the results obtained. This allows you to quickly orient youself on what the papers in a certain area are doing.
Secondly, I briefly review Citation Gecko , a project by Barney Walker a Phd student at Imperial College London. By combining data from OpenCitations, Crossref and Microsoft Academic, this allows you to quickly create a citation map using seed papers you input. It's quick and fast, and I can imagine many use cases for it. For example, you can use this to explore connections (if any) between different strands of research you might want to combine and of course it could be easily used to spot interesting papers you might have missed by purely keyword searching.
While both tools can be useful for any researcher, I have a hunch they can be of even greater value to Phd students who have less familarity with the literature (or researchers working in unfamilar areas) as between the two tools, they allow one to quickly capture up on this by looking at papers by results (giving one a sense of what is usually studied) and giving them a bird's eye view of the way research in the field is connected.
Summarising quantitative studies
When I was in my final year as an undergraduate in Accounting, I had to do my very first piece of real academic research for my final year thesis. It was on predictability of profit forecasts in IPO prospectus. I remember doing my literature search on various platforms (this was before the days of Google Scholar or Web Scale Discovery) , summarising past papers on the same topic and writing it all up. My supervisor at the time sugguested a practice that will probably be familar to most researchers, to summarise past literature in a table, with each row highlighting a study and columns showing what variables were found significant (or not) with profit forecasts.
Wouldn't it be nice if some service existed that helped you do this? Something that allowed you to search by findings? While no such service exists to my knowledge, Knowtro - which I had highlighted slightly in a past post on "some interesting discovery ideas, trends and features for academic research" comes close.
A findings first approach vs a paper first approach
Knowtro if you are unaware is a interesting search engine that extracts and highlights quantitative findings findings in papers and displays them for searching. So for instance you might be curious about the outcome variable CEO Compensation and Knowtro allows you to see what other studies have established on this variable.
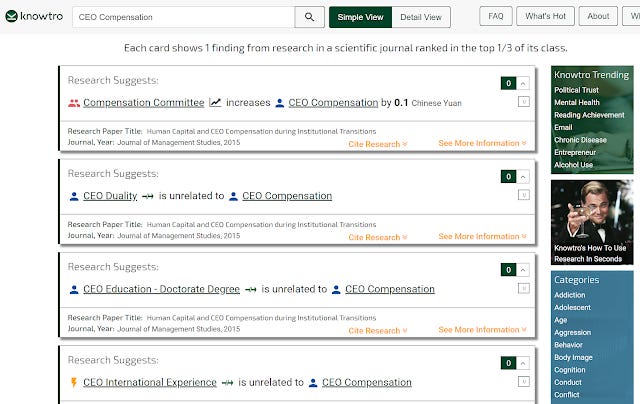
This is a findings first approach rather than papers first approach, though you can of course link to the papers for each finding.
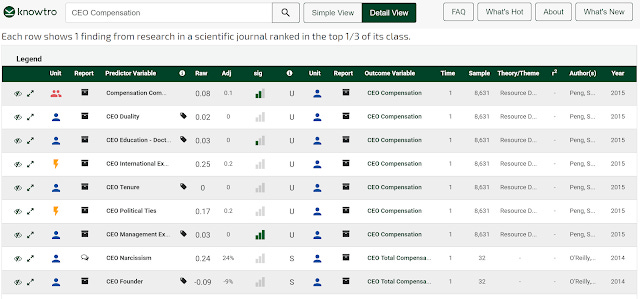
In the detailed view, you get even more information, you can see the level of significance, effect size, unit of analysis, R-squared of the model etc.
When I was at Computer in Libraries 2018, I had the pleasure to hear the founder Sean McMahon speak about Knowtro.
To my surprise, he described it has a solution to help undergraduates who did not know how to search, how to easily interprete the results and yet need reliable sources.
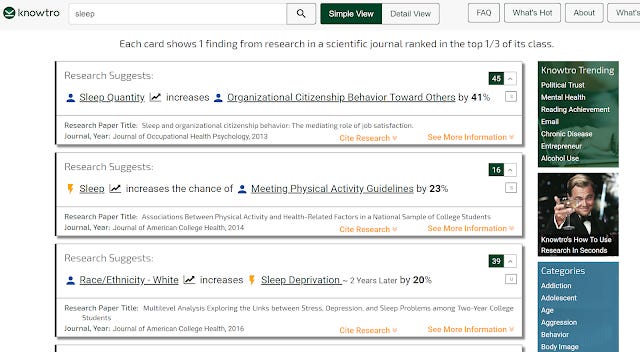
So for instance, a undergraduate asked to write a paper on effects of sleep, would go to a discovery service like Summon, search for "Sleep" and get dozens of papers with the title "Sleep" which would be useless to him.
Instead with Knowtro, the student could get a taste of what the research in that area was about, with all the different findings nicely summarised.
I found this fascinating because prior to this I assumed Knowtro was designed for researchers, as Knowtro makes it easy to help look at what has been done and help spark research questions.
The fact that Knowtro surfaces significance values, even R-Squared for models also has interesting implications to me. Imagine combining this data with citation metrics. Does more robust findings get cited more?
Now imagine if Knowtro like information is combined with links to datasets, perhaps using Scholix like the way Scopus does it. I believe such a tool would be a greatly valued by many researchers.
Throw in some open data citations and linked data magic and you could answer questions like what findings were generated by data XYZ.
The main weakness of Knowtro currently is that the coverage of articles is still quite small. For example while there are papers on CEO compensation from certain journals, the accounting journals that have similar work are not covered. Even in covered disciplines, the number of papers included seems low to me. I understand there has been an effort to prioritze in areas that the public might be interested in.
It would be interesting to see how far Knowtro could go with more resources, or if intergrated into Web Scale Discovery services like Summon, Primo or Ebsco Discovery services.
Citation Gecko - Identifying relevant papers using network methods

Many graduate students or research assistants are often tasked with doing literature review and may be given seed papers to start looking for additional papers. Most of them eventually stumble upon the idea of doing citation searching, finding papers cited by those seed papers or finding papers that cite these seed papers.
But given seed papers, an alternative way of generating more papers is to use article recommenders systems, which are now a dime a dozen and you can find them all over the ecosystem using different techniques from collobrative filtering to content based filtering approaches. and more new fangled techniques like deep learning.
Some of these might even be using variants of bibliometrics style techniques like co-citations and bibliographic coupling to identify potential related articles to recommend.
Some of them work at the article level and have a find similar article feature, others work at the project level where you upload a bunch of articles and it will pit out recommended articles.
Some examples include
Publishers - e.g. Sciencedirect article recommender, SpringerNature Recommended Service, Sage, JSTOR
Others - e.g. Google Scholar, BX recommender, CORE recommender
For a very in-depth yet readable primer on article recommender systems please see A practical guide to building recommender systems.
That said, the main weakness of recommender systems is that they do not help you see the "shape of the research".
Imagine if you are phd student and you want to see what linkages if any there are between 2 different strands of research you are working on. How do the papers you are reading cluster together? A recommender system wouldn't help you see that.
But a citation map would. Back in Oct last year, I blogged about a new intriguing tool called Whocites that scraped Google Scholar for papers and references and automatically generates a network map.

While it is a great tool, it's quite slow as it involves scraping from Google Scholar and as such isn't a reliable tool.
How would such a tool look like working on open data and citations? The tool would look like Citation Gecko
How it works is that you add seed papers by searching using doi, titles or by uploading from Zotero.
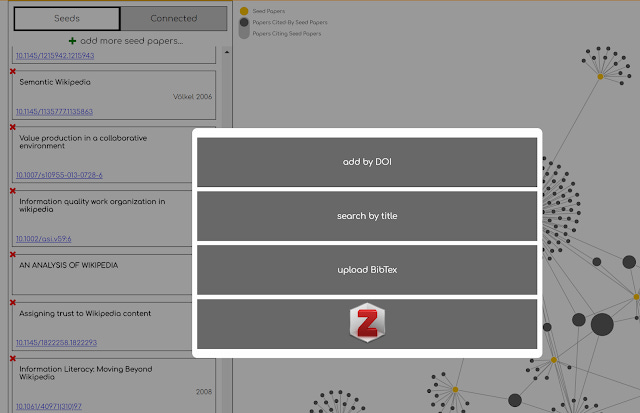
Once you have added enough seed papers, you can see the network graph. In my example, I entered some papers on Wikipedia, my old project about a decade ago, trying to study the accuracy and reliability about Wikipedia articles.
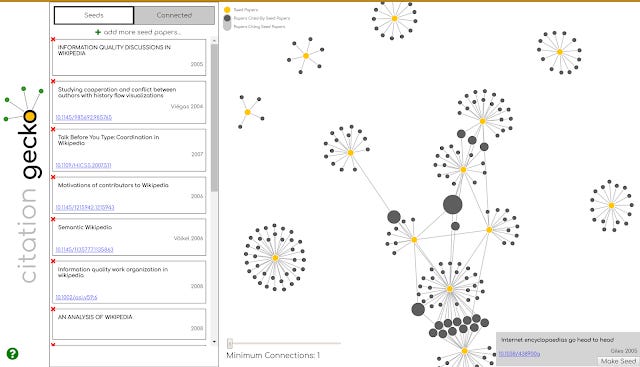
Above shows some quick and dirty results. The yellow dot represents your seed papers and by default the small dark circles are papers cited by my seed papers.
Immediately you notice there is a big dark circle in the middle that was cited by many of my seed papers. Hovering over the circle shows it is "Internet encyclopaedias go head to head" (Gile 2005) , one of the first studies on the accuracy of Wikipedia article, which indeed inspired my eventual published paper.
You can add it as a seed paper by clicking on "make seed".
Alternatively, you can go to the list view (on left of screen) and click on the tab connected and with the option "Seeds cited by" you can see Gile 2005 was a paper cited by 10 of seeds showing it's importance.
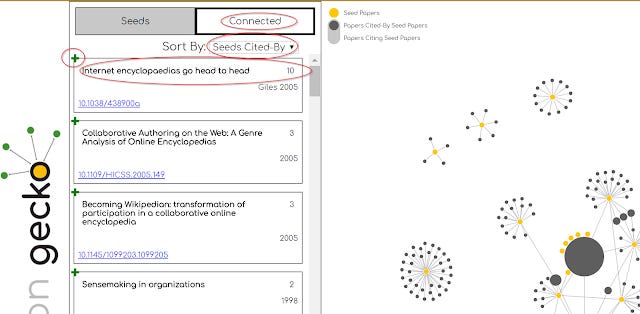
You can then add this important paper as a seed by clicking on the green + button next to it.
Alternatively, you can try to find related papers by looks at papers that cite many of the seeds, in the list view. Again you can add this paper (often new) to the network.
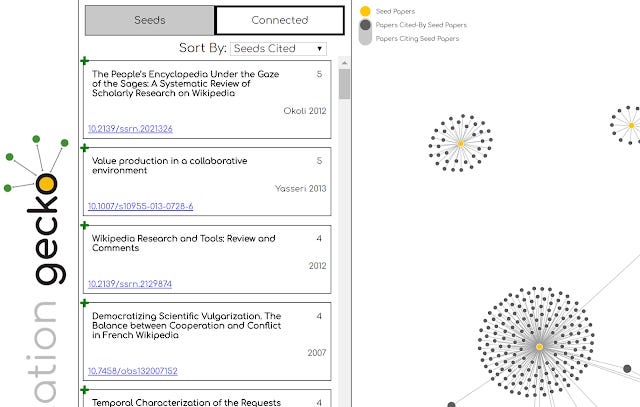
In my example, I added "Value production in a collaborative environment" as a seed paper because it cites many of the seed papers and looks relevant. This results in the yellow dot above surrounded by many other black dots. It looks like this paper (now a seed paper) cites a lot of other papers, could be a review paper of some sorts.
Now for something complicated. In the network graph, by default the black dots represent papers cited by seed papers. So we are now only seeing papers no older than the seed papers.
Let's try to change the black dots to mean "papers citing seed papers" by switching the switch at the top of the network graph.
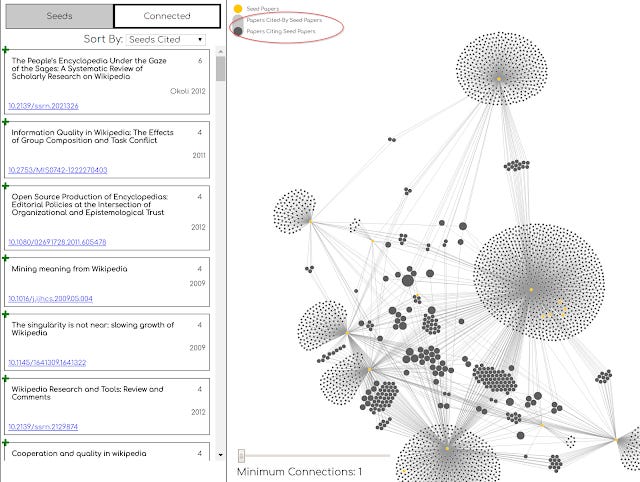
This time the graph explodes because there are a lot more papers that cite these seed papers as we go forward in time.
This can be useful to see what papers cite both seed papers that are perhaps in different areas.
Some thoughts on Citation Gecko
The obvious thing to ask is where does Citation Gecko get all the data? The answer in the video seems to be OpenCitations, Crossref and Microsoft Academic.

This is an amazing use of open citations and is likely the combination of these 3 sources would ibe close enough in size to Google Scholar for most intents and purposes.
I know such citation maping tools are not new, for example Web of Science offered them (still offers?) citation maps but I never found them useful for various reasons including the make it was clunky to use.
One thing I noticed while trying is that it's fair easy to trigger Microsoft Academic data limits. I entered only 10 papers from a recent paper, and when I flipped the switch to "Papers citing seed papers", I got a message about exceeding Microsoft academic limits. You can see in the picture below on the left, many papers marked as "unavailable".
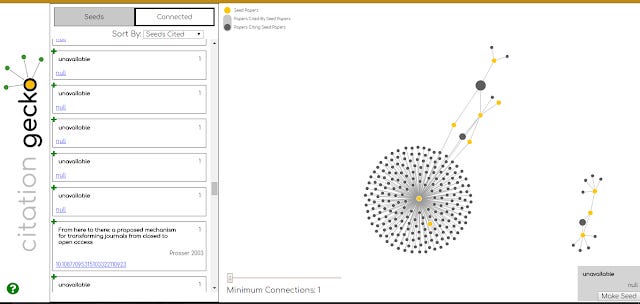
I'm still puzzling out how best to use Citation gecko. For instance are papers cited by a lot of seed papers (co-cited) more likely to be relevant as opposed to papers that cite a lot of seed papers (bibliometric coupling)?
I'm forgotten most of what I have read on research in this area, but I kinda remember reading co-cited articles are likely to be more relevant. With Citation Gecko, one can test this by taking a paper, randomly selecting and entering 10 references in it and see if the top co-cited papers or the top bibliometric coupled articles are most relevant (also cited in the same paper)?
I'm still playing with Citation Gecko but it seems very promising.
Some improvements to the tool, could be to allow filtering or shading by year of publication or perhaps even show a year by year play as nodes are added to the network. Letting the size of the node represent number of citations in general the paper received (rather than just by seed papers) might also be interesting.
I'm tempted to say look at the network visualization functions of VOSviewer for inspiration (where there's a lot of flexibility), though obviously some of the functionality there might just be of lesser interest to individual researchers trying to do their literature review rather than plan institution strategy.
In any case, if you think the project is useful do sponsor the project, (no minimum pledge) pledges end by 1 Aug 2018.
Conclusion
Of course the difficulty with Knowtro and Citation Gecko like approaches is where is all the open citations and full-text coming from for extraction to occur? I'm not well versed in the legal aspects of text data mining paywalled articles and extracting findings, but as a practical matter it isn't easy to get your hands on such data in mass.
MIT Libraries's API for Scholarly Resource Libguide is probably the most comprehensive guide on this topic in particular CORE has one of the largest free sources for Text data mining, though one must take into account that unlike publisher sources, the papers found can be versions before the version of record.
As for open citations, see my piece on open citations.
All in all, I hope these two tools were interesting! Do share any other less well known tools you use in the comments below.