
Learning about proposed changes in copyright law - text data mining exceptions

Recently, a researcher I was talking to remarked to me that University staff can be jumpy around copyright questions and some would immediately duck for cover the moment they heard the word "copyright". I'm not that bad, but as a academic librarian my knowledge of copyright is not as good as I want it to be.
But last month, I attended a great engagement session at my library by Intellectual Property Office of Singapore (IPOS) and Ministry of Law where the speakers gave a great talk on copyright in Singapore and addressed some of these proposed changes. They managed to concisely summarize the copyright law in Singapore, the current situation (the irony of how the copyright law in Singapore pretty much copied the Australia one which itself is based on UK was not lost on the speaker) and the rationale for change.
Given that understanding basic copyright is going to be increasingly one of the fundamental skill sets needed by academic librarians, I benefited a great deal from attending.
There were many interesting and beneficial proposed changes for the education section but I was most captivated by proposed changes in the copyright laws with respect to Text data mining in Singapore designed to support the smart nation initiative in Singapore.

This proposed change I believe is very similar to the one already in the UK , except that covers only non-commercial use. EU is also I believe mulling over a similar law.
Like in the UK law, I believe the proposed change will also disallow restriction of text data mining via contract.

Why is this proposed change important?
One of the most common issues we face today is the fact that increasingly many researchers are starting to do text data mining on content in our subscribed databases, they could be doing it in newspaper databases (e.g. Factiva) or journals (e.g. Sciencedirect) or other resources.
Many researchers I find aren't quite aware that for most part when the library signs an agreement for access, such rights exclude TDM (or do not state TDM as a allowed use).
Most databases we subscribe to also have a system to detect "mass downloads" and as such any TDM eis most likely going to be detected (though I believe some researchers may try to bypass this by scripting human-like behavior).
Businesses are never one to forgo a revenue opportunity and many databases require we pay an additional known expensive fee on top to allow TDM.
Others have a more "come talk to me and we will see" style policy and the rare few enlightened ones like JSTOR actually allow it up to certain limits. Many academic libraries have created guides like this and this to try to keep track of things.
As text data mining can be more easily done via API through than scraping data, another approach is to offer a guide of the APIs that can be used. One example is MIT's libguide
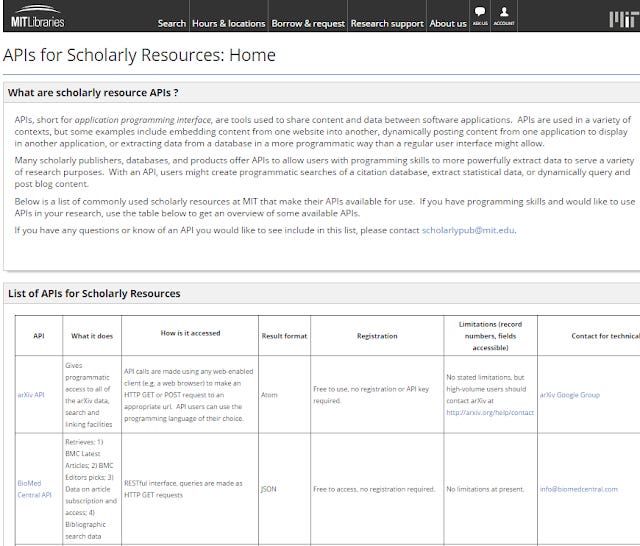
http://libguides.mit.edu/apis
The proposed law would have two effects. Firstly, the status of researcher's doing data mining of the open web was always hazy. In theory if you mine say reviews on blogger say and use it for your research, I understand content owners of the blog could possibly sue you for copyright infringement. The proposed changes clarify this and allow TDM of such data (but not merely aggregation) of such data.
More interestingly for data that researchers have legitimate access to aka subscribed databases, there is no longer any distinction between reading an article and doing text data mining. And such a right cannot be excluded by contract by the vendors.
The data/position paper set out by the ministry of law/ipos here is a great read, and it points out that if such a change comes into effect, it is likely vendors who already charge for TDM will "price in" the cost of TDM because they can no longer exclude these rights.
Will the exception disadvantage libraries that don't have users that won't do TDM?
There was an interesting Q&A afterwards mostly centering around the TDM exemption.
One of the more obvious points made was, is it necessarily desirable to put in these exemptions when it will lead to vendors "pricing-in" TDM rights for database packages automatically? While the bigger Universities and institutions would probably have staff that would do TDM, the smaller institutions would be unfairly affected resulting in higher prices for no benefit. Why not allow each institution to negotiate with vendors and allow exclusion of TDM depending on each institution's need?
I am sympathetic to this view point.
But my current gut feel is that overall this will be beneficial.
Let me try out this line of argument.
Libraries tend to be in a far weaker negotiation positions than the vendors (due to the fact that a lot of vendor material is unique) and what often happens is that under current law many libraries will simply play it safe, pay only for basic read access but not TDM because it's very hard to predict who will want to TDM even for big Universities. Some librarians will even refuse out of principle to pay for TDM.
So vendors will not be sure at first how much they are losing by not charging for TDM as whatever they getting now is probably less than true demand.
The proposed changes package everything into one, and it turns the game into a game of chicken. While the vendor might want to price things as high as possible and to even recapture all the possible TDM revenue but there is a need to compromise (anchored around current prices that exclude TDM) or they will end up earning nothing.
That should put a cap on too exorbitant price increases at least initially (though in future periods they might be able to properly estimate the real TDM demand and price accordingly). I suspect the net effect is while prices will go up ,overall a lot more TDM will occur and if the intent is to encourage TDM that is a win and TDM generates sufficient benefits it will be a win.
But this is a wild guess.
I'm also wondering once the law forbids vendors from preventing TDM once libraries have paid for lawful access to the database, can they say "Okay, you can now do TDM but only via method A (probably API) and not via scraping or trying a script to do automatic download via the usual human facing interface?". This seems to suggest No.
It would be great if we could learn from the UK experience and I started asking around my usual international network of librarians but came up empty.
One librarian pointed out to me that even though the law was passed in 2014, given subscriptions cycles of 1 year or more, and research lag time, any such research probably is still in the works!
Still I ask readers of my blog, if you work in UK as a academic librarian what was your experience like? Did you find prices of databases that are most often targets of data mining start to rise even faster? Did the sales people reference the change in law as a reason? If you are a researcher in UK who has done TDM under this law, what was your experience like?
Even anecdotes would be nice. You can comment below or send me emails privately if you like and I will preserve any anonymity.
What law are the contracts signed under?
Another point that was brought up that was more damaging was that when libraries sign contracts with database vendors which jurisdiction of law will the contract be under? If the contract is to be under US law (fairly common?), the changes in the copyright act would have no sway over the breach of contract, effectively making it toothless.
I'm not a lawyer so I do not know what will happen if a library was sued for breach of contract overseas outside Singapore and awarded damages.
Other comments and questions
The Q&A was a good exchange of opinions and views between both the speakers and the audience (made up of faculty and librarians). Topics covered included open access (Gold open access is usually frowned upon by librarians in Asia which I think is quite different compared to the west), copyright for MOOs and more.
One interesting point made by the speaker was that he was a bit surprised to see while there was organization on the author /creator side with organizations like The Copyright Licensing and Administration Society of Singapore Limited (CLASS), Composers and Authors Society of Singapore (COMPASS) representing the author rights, there wasn't such a group on the user side.
He suggested perhaps the Universities in Singapore band together to negotiate collectively on some agreed core content? Is this what we call a library consortium?
Then again Singapore is a really small market, so who knows perhaps the law would make little difference and vendors might just let it go?