


Linking to freely available articles - how various databases and citation indexes use unpaywall data

Note : Jan 2019 - I wrote the bulk of this in July 2018, when Scopus announced a deal with Unpaywall. I have updated it to take into account some developments up to Jan 2019.
Note 2: Feb 2021 - This area has been changing quite a bit with changes to the Unpaywall API and more importantly, Scopus's definition of open access now includes those available in open repositories (typically referred as ‘Green OA’) as long as they are author accepted manuscripts or version of records. This will show in the filters but the links will not show up in the Scopus record.
With @unpaywall data now in @scopus as well as @clarivate Web of Science and @digitalsci Dimensions, we've got all the major commercial discovery services covered. Will be hard to do search without finding #OA! #excited https://t.co/AmdKLsL0ox
— Jason Priem (@jasonpriem) July 26, 2018
So it has come to pass, the big 3 discovery and citation indexes in our industry, Web of Science, Scopus and Dimensions now provides widespread native support to users to find open access versions of papers as in July 2018. This is a remarkable achievement, besides the 3 major citation indexes mentioned, Unpaywall data is also used in Europe PMC, ScienceOpen, Lens, link resolvers like 360link (though the data usually isn't preloaded but is called dynamically on the fly like in the earlier examples) and more.
Discovery services like Primo,Summon, EDS have added OA filters and indicators and have added or will add big chunks of content via large scale OA aggregators like CORE and/or BASE.

Open Access indicator and filters in Primo
EBSCO Information Services and Bielefeld University Will Make BASE Database Searchable in EBSCO Discovery Service https://t.co/2TmH4BwjYL
— Richard Poynder (@RickyPo) December 8, 2015
Add the explosion in tools like Kopernio, OAbutton, Anywhere Access, Lean Library Browser , Google Scholar button and more that help users find papers (both subscribed and paid) there is no doubt that the discovery of open access papers is now mainstream in library related tools.
To think that just 3.5 years ago in July 2015 my surprisingly popular "5 things Google Scholar does better than your discovery service" I lamented the irony of how library based discovery tools were horrible at detecting OA content compared to Google.
Things certainly have changed since then and as I noted in July 2017 that OA has become too big to ignore in discovery.
But what are the implications in a environment where finding freely available items is the norm with our tools?
Firstly, just because a service or index like Dimensions, Scopus, Web of Science, Europe PMC etc are licensing unpaywall data doesn't means they will be using it in the same way. As you will see later some of them are selectively exposing only a subset of the links (e.g. Scopus is showing only Gold OA, while Web of Science shows Green as well as long as it is a author accepted manuscript or published version), while others (e.g. Dimensions) are using the full set.
Secondly, what is the right policy for links? Should we demand such services and indexs to link to everything that can be found freely available? Or set a tool like Lean Library ezbrowser to only show author accepted manuscript or published versions? Also given the difficulties of version detection can we be sure this is working?
Thirdly, should such OA detection functionality reside at the database vendor site eg Scopus or should they be controlled by the library typically via our link resolver that will offer subscribed versions first.
Lastly, given our tools are now exposing students to more versions of papers , how should we shift the way we do information literacy ?
A note about terminology
There is some confusion on how to call different versions of papers. For example, what exactly counts as a "preprint"? A "post print"? These terms no longer make sense when journals are born digital. Terms like "working paper" add to the confusion as disciplines have different practices.
What standards are there to resolve this
The NISO JAV (Journal Article version) standard recommends the following
1.Author's Original (AO)
2. Submitted Manuscript Under Review (SMUR)
3, Accepted Manuscript (AM)
4. Proof (P)
5. Version of Record (VoR)
6. Corrected Version of Record (CVoR)
7. Enhanced Version of Record (EVoR)
I'm not sure if it ever caught on, though the term Version of Record (VoR) to refer to the final version that you see on publisher platforms seem to be commonly used, the others not so much.
The other standard that seems important is DRIVER Guidelines v2.0 VERSION types (also used in Unpaywall API) It gives
1.draft
2.submitted version
3.accepted version
4. published version
5. updated version
I prefer this version, because it's simpler and a bit more descriptive though I believe it lacks the equivalent of NISO's "proof" and "EVoR". Granted I guess these versions are less commonly encountered unless you are a publisher.
The truth is while terms like "Preprint" and "Postprint" have become hopelessly confusing, I suspect they are still influential due to tradition and they are still used in sites like Sherpa Romeo. In fact, there is a whole class of up and coming repositories that carry the label "Preprint servers".
For the purposes of this post, I'm going to use the terms
1. Preprint to refer all versions up to just before the accept version (also known as Author accepted manuscript).
2. Accepted version or alternatively author accept manuscript (AAM) - the version just after peer review but before published version
3. Version of record (VoR) - published version
Users will encounter more versions of papers. Need for Information Literacy?
Here's an announcement that helps demonstrate why students (and others) are going to be encountering preprints *in* library subscription databases and thus in our #infolit sessions. https://t.co/05pAIzEKTj https://t.co/w2VEmHXAd6
— Lisa Hinchliffe (@lisalibrarian) July 26, 2018
A few days ago, Lisa Hinchliffe asked on Twitter how librarians were discussing preprints with users. The answer from another librarian and from me was similar, we didn't think many librarians were talking much about preprints, particularly to first years.
I suspect the reason is that many librarians focus on recommending traditional databases like Ebsco or Proquest ones which points to version of so the issue never comes up.
Of course, I'm not naive, and I know our users whether it be faculty or undergraduate, use Google, Google Scholar and do encounter versions that are not version of records. There's in fact I suspect a high likelihood they treat it just like a VoR and cite it as per normal, unless it occurs them to ask someone.
But until recently, a librarian was able to maintain the polite fiction that our users would only see VoR because for most part if they were using our databases they would rarely encounter other versions.
In the past year or two, keeping up this fiction is becoming harder and harder. As Lisa points out in the tweet above, even our subscribed databases are starting to point to non-VoRs.
Users and Libraries are also increasingly beginning to support use of tools like Kopernio, Lean Library Browser (e.g Stanford is encouraging use of this) which not only brings users to subscribed resources but further increases the chances of users running into OA versions that are not version of records.
Stanford's support of the Lean Library browser extension
Of course, one interesting question is what open access versions do these tools point to? If they pointed only to Gold OA (including hybrid) copies, everything would be as per normal. It's unclear to me what these tools surface by default and whether there is flexibility given to libraries to change this default.
Will this drive more traffic to our institution repository?
One can imagine even within the library there might be difference between opinions on what such tools should point to. For example , a Institutional Repository (IR) Manager might rejoice at how the current trend towards pointing to OA could help drive traffice to IRs.
Time was, both aggregators and faculty would shy away from leading users to green-OA content, shaking their paws disgustedly like cats who had accidentally stepped in a puddle.
If we are lucky, this will lend green OA some legitimacy in faculty eyes.— Library Loon (@GaviaLib) July 26, 2018
This may be true, but it depends on firstly how good such OA finding/linking tools like Unpaywall are good at surfacing Green OA , particularly institution repository and secondly and more important how the licencees use the data. For example, they may only add links to Gold OA material or only to version of record copies.
Even if they point to earlier versions like author accepted manuscripts or even preprints, such tools may prioritze versions located at subject repositories like PMC as they are bigger , more well known and hence more likely to be customized for (in terms of metadata extraction) than individual Institutional Repositories.
What can unpaywall detect?
Let's focus on Unpaywall data which is now probably the most widely used source of data for detecting OA material though many tools further enhance it with their own sources.
Unpaywall data is of course at the article level and among other things, allows you to tell where the OA article is hosted (host_type = Publisher or Repository) and version of OA paper (version=submittedVersion or acceptedVersion or publishedVersion). It can also tell you the license (Creative commons or Publisher License or Implied OA).
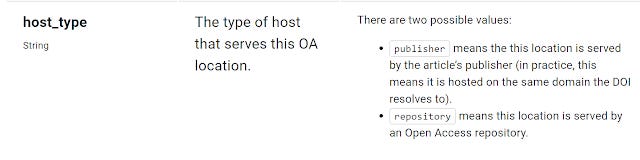
Unpaywall API will detect host type of OA content
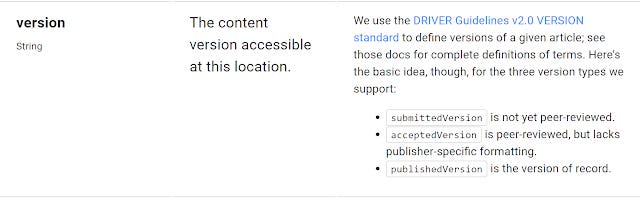
Unpaywall API will detect version of OA content
Sources that license unpaywall data can choose to use the data to provide all or only some of the links known to Unpaywall. This data can also be used to show the facets and filters relating to open access.
How different licensee of Unpaywall data expose open access papers
How Dimensions uses Unpaywall data
Dimensions I believe uses the whole unpaywall data to show all links known to Unpaywall. In terms of filters, they provide filtering by host type whether an article is publisher hosted or repository hosted. In other words, you get all the OA versions whether preprints, accept versions or version of records at least as of July 2018.

Open Access Facets in Dimensions as of July 2018
As of Jan 2019, Dimensions still gives you an opportunity to get all OA, though it adds more nuance for the Green OA.

Open Access Facets in Dimensions as of Jan 2019
Europe PMC I suspect does the same and includes all links found by Unpaywall. ScienceOpen might be as well.
How Web of Science (WOS) uses unpaywall data
But for Web of Science, own a subset of the unpaywall data is used.
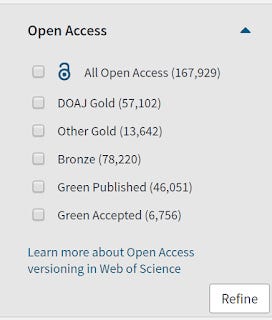
Open Access Facets in Web of Science as of Jan 2019
As you can see the filters allow you to filter to
DOAJ Gold
Other Gold
Bronze
Green Published
Green Accepted
As an aside this is an improvement from an earlier verison where they grouped all Gold and Bronze together. I'm slightly puzzled by the decision to split DOAJ Gold from other Gold. In most databases, I would say it is a good way to ensure you won't get any Predatory journals but this is Web of Science where supposedly only the best of best are included. :)
In any case WOS only includes a subset of Green , only the published or accepted versions.
In unpaywall terms I guessthey link to accepted versions and published versions which are in both Publisher and Repository hosted.
The help file claims to use Unpaywall API to link to
a) Gold and Bronze versions (which by definition are versions of records)
b) Green OA , but only accepted and final versions.
In other words, preprints are excluded.
In particularly for Green this is what is said
"A freely accessible version of an article located in a subject-based repository such as PubMed Central or in an institutional repository. This version of the article may vary from a peer-reviewed accepted manuscript to the final published version based on the journal’s policies. Because accepted manuscripts may vary from the final published versions, they are labelled distinctly as Green Accepted and Green Published, respectively"
Though the help file states that Green OA includes both subject repositories and institutional repositories, in reality I bet most of Green OA links in Unpaywall will be pointing to subject repositories like PMC. This is because of the well documented difficulty of detecting versions in institutional repository. I suspect this can be particularly difficult if you want author accepted manuscripts.
My understanding is as a result, chances are your content in the Institutional repository despite being a accepted version will unlikely show up in Web of Science because unpaywall is not able to confirm the version.
I did quite a bit of sampling and it was tough to find a Green accepted or Green published link that didn't go to a Subject repository like Europe PMC but to a Institutional repository.
I did find some though. For example take this record in WOS
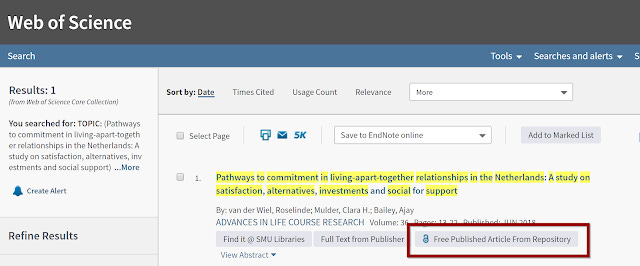
Link on Web of Science that goes to a institutional repository at University of Groningen
Another example is the article "Style and substance in rococo science" in the Journal of Interdisciplinary History which Web of Science provides a link to "University of Warwick open access research repository - WRAP"
Institutional repository managers should definitely study this issue to see how tools like Unpaywall detect versions or risk these tools failing to correctly detect and display them in databases like Web of Science. (I suspect by default tools like unpaywall tags copies as preprint if it's cant find signs the copy is a accepted or published version)
Looking at the ones detected, a wild guess is the cover page should clearly indicate the version.
How Scopus uses unpaywall data
Lastly what about Scopus? As I write this in Jan 2019 , it is almost 6 months since the announcement Scopus made, but it's unclear to me what is happening here, though there seems to be some evidence that Scopus will only be using the Gold OA set from unpaywall.
In "How Unpaywall is transforming open science" it was reported that Scopus will increase the number of links to fully available articles from 1.2 million to 7 million after including Unpaywall data. It goes on to say that it "is still around 13 million articles fewer than are listed in Unpaywall’s database as freely available (See 'Unpaywall Revolution'). This gap exists because Scopus will not link to articles posted in repositories."
Still there seems to be hope? Look at the screenshot taken at the time of writing (26 Jan 2019) from Scopus. You might like to compare it with a screenshot taken in May 2018 (just after announcement of deal with Unpaywall and prior to any change made)
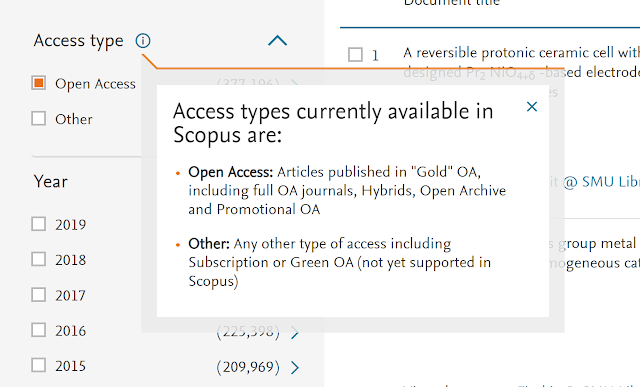
Help file about Scopus OA filter data as of 26 Jan 2019
As the help screen above shows, Scopus is currently tagging only Gold OA, but there is some wording suggesting that Green OA is "not yet supported in Scopus".
The "not yet" phrasing seems to suggest Elsever might eventually perhaps follow a policy seem to Web of Science and include OA links by version type regardless of where it is hosted?
In particular the announcement that Elsevier has purchased Science-Metrix in Dec 2018 which includes the discovery tool 1Findr (which is known to have a very capable OA database) makes me wonder......
Updated: Feb 2021 - , Scopus's definition of open access now includes those available in open repositories (typically referred as ‘Green OA’) as long as they are author accepted manuscripts or version of records. This will show in the filters but the links will not show up in the Scopus record.
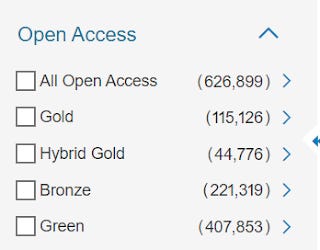
Scopus OA filter as of Feb 2021 includes Green OA
Will Elsevier add Green OA papers?
Everyone seems to think linking to OA is good for users, but given this is Elsevier at the time when they announced they had licensed Unpaywall data a lot of people were suspicious.
For example, some wonder if Elsevier is going to use this data to go after repositories that have unlawful versions of papers up.
I think this is unlikely , chances are Elsevier already has similar technology or can build one if needed and it's unlikely they will go after mostly law abiding IRs who are run by their library customers. In any case, Unpaywall seems to have anticipated this
Good question. The intended use is not to chase down copyright issues at repositories. In fact the contract explicitly prohibits them using Unpaywall data for this purpose, and both parties are happy about that.
— Jason Priem (@jasonpriem) July 26, 2018
Yet others speculate that Elsevier will use this to push a small price increase.
The way I see it, this is just Elsevier ensuring that Scopus maintains competitiveness with Web of Science and Dimensions. In fact as mentioned Elsevier's purchased Science-Metrix in Dec 2018 is perhaps their way of adding capability.
Also Elsevier can and will follow standards if it suits their needs. For example it's an earlier support of the open Scholix standard linking articles to datasets and recently began to aggressively push researchers to use ORCID for journal submission.
Of course being a publisher of journals unlike Clarivate (WOS) and Digital Science (Dimensions) arguably they may decide increasing exposure to Green OA does not suit their needs and hence their solution simply enhances detection of Hybrid OA which is traditionally hard to detect.
Is there a need to better aggregate/link different versions of papers together?
Everything form preprints to emphemeral digital objects are being assigned DOIs. In #scholcomms this is often resulting in the minting of a DOI for a preprint, an AAM & a final published version. Not to mention items deposited in 3rd party repositories minting their own DOIs.
— George Macgregor (@g3om4c) July 26, 2018
Macgregor then asks "In other words, do we need a super identifier in which all known referenced manifestations of a work are unified, a bit like the #FRBR model of bibliographic objects where various manifestations of the same work are distinguished but unified."
This is a very important question to ask now that non version of records are increasingly surfaced.
First off you might not be aware that Crossref has encouraged registering of dois for preprints since November 2016. In fact, growth of doi registration for preprints has been 10 times higher than journal articles. Ross Mounce points out that versioned dois do exist for F1000 as well.
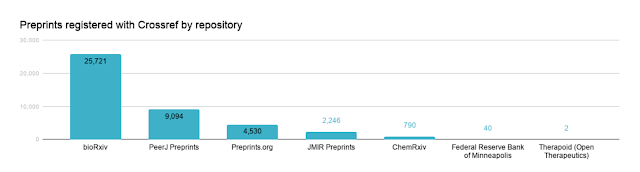
Preprint repositories that register with Crossref
Having a doi for preprints is a first step but how do you know one doi is a preprint version of another doi that is the published version?
It does - we help preprint depositors identify when a final paper has been registered with Crossref, and the preprint registrant adds that relationship to their preprint metadata and also links to the final work from the preprint landing page.
— Crossref (@CrossrefOrg) July 12, 2018
As the tweet about shows if you register a preprint with a doi, you not only get the option to edit your metadata to create a “isPreprintOf” relation type to the accepted version or verison of record. but you are informed that the possibility exists.
In fact Crossref states "Once an item has been published from the posted content, the posted content publisher must update their publication metadata with the AM / VOR DOI using the “isPreit printOf” relation type." (italics mine)
Is there a requirement to be a link from the other end (from AM/VOR DOI to preprint DOI)? I believe not.
I'm not sure if tools like unpaywall are able to exploit the isPreprintOf relationship to work backwards from a AM/VOR DOI to preprint DOI, hopefully it does.
My last comment on this is that it seems that the accepted version and published version is meant to have the same doi, which makes variant detection as mentioned above difficult.
Control of linking to free content - the library resolver vs database
That said the always interesting Lisa Hinchliffe wonders if this move has RA21 implications and/or maybe a strike against Link resolvers.
I'm still thinking it over it's relation to RA21 and proxy servers but she does make the following good points I agree with
a) Ideally the library would like to be able to control the ordering of what is shown, this includes both subscribed content and open access versions, and link resolvers are slowly adding this capability to add links to open access versions as an option (360link already works with unpaywall and Open access button), but with Scopus adding the link separately, this might confuse issues
b) One might think, who cares if the user clicks through a link resolver and end up at a open access copy or if he clicks directly to the same open access copy natively bypassing the link resolver. Lisa thinks that the lost data point here, could hurt libraries.
For one thing, libraries lose the ability to tell how much users value the non-version of record open access version vs the subscribed version.
Still from the usability point of view I wonder if letting the vendor expose links to OA (when available) is better. This is because the current way library link resolvers are implemented in typical databases led to very bad user experiences.
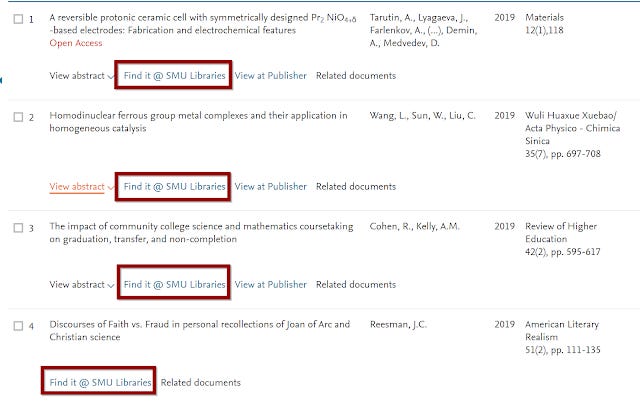
Typical Library Link resolver links in database always appear you have to click and pray....
With a typical link resolver implementation on databases, the link added is not dynamic. For each record, regardless of whether the user will have access to it, there will only be one link - typically "findit@xyzlibraries" , users will have to adopt a "click and pray" technique to see if it resolves to full text via subscription, full text via OA link, or just nothing with a invite to do Document Delivery if available.
From the user point of view, they may get turned off if they realise clicking on the library resolver link doesn't always get them a free version or subscribed version. I can see from the usabillity point of view it might be cleaner to just have a seperate free article link that always works seperate from the library link resovler.
Conclusion
Users using Google or Google Scholar to find different versions of papers has been happening for years of course, but the recent trends has made them more likely to find non-final versions in library databases and citation indexes.
Librarians should also watch and study carefully how and what types of OA or freely available material databases are linking to and not assume that every announcement of a tieup with unpaywall means Green OA will be exposed.