
Making your datasets discoverable - 2 aspects to look at

There is something in the air right now around datasets. Increasingly, datasets are being made visible and shared online in data repositories.
Undoubtedly getting researchers to deposit their datasets whether open or even closed to data repositories is a difficult task, but once that is achieved the next challenge lies with making the datasets discoverable. After all, preparing a dataset for sharing is a much bigger undertaking than merely sharing the paper, so it seems a shame if the dataset is not discoverable.
On a personal note, I have been studying data repositories for the last 6 months , mainly through the lens of discovery, what does it mean for datasets to be discoverable? Which data repositories particularly institutional ones do best here and what are they are doing? Data discoverability is of course a very new area and up to recently, there didn't seem to be much clear guidance or clarity but I think I am starting to see the light, thanks to two recent excellent webinars.
Two discovery pathways to datasets
So how does one promote the discoverability of datasets? One way to think about it is to consider how we find papers. We find papers by either searching by keywords in some big aggregator database of papers (or search engine as we call it now) or alternatively by following references.
The parallel for this for datasets are firstly, we need datasets to be appropriately indexed in dataset search engines and secondly they need to be properly referenced from other items that cite it (mostly articles), so users can find datasets by following references.
How do we optimise our datasets so that they are properly indexed and surfaced in the appropriate dataset search database? There are of course a lot of things to consider here, but up to recently, no general purpose dataset search even existed (though it seems, Digital Science and Elsevier products might start to aggregate datasets from other data repositories on top of their own) , so the issue was almost moot.
In Sept 2018, Google launched their Google Dataset search twhich is designed precisely for that use(see my reflections on the implications). Of course there was a huge groundswell of interest immediately and one of the main questions was how to get datasets deposited in repositories indexed in the Google Dataset search.
Secondly, we need to consider the issue of data citations. The Force11's Joint Declaration of Data Citation Principles affirms the importance of treating datasets as a first class entity by citing them properly, so efforts are underway to encourage researchers to properly cite datasets in their papers particularly with PIDs (permanent IDs).
One area in particular to consider is that not only must these references exist but they should be available in machine readable/actionable format so they can be queried , aggregated and otherwise studied in bulk.
For example, take the following "data availability statement" (which is a kind of data reference) in a journal article.

Data availability statements are increasingly becoming more common for journals, and in the above case the article acknowledges and references the dataset supporting the study at Figshare with both a URL and a doi. This is good of course.
However, without the proper metadata this is where this information remains. A machine readable data citation would allow a system to harvest and aggregate all data citations ( data availability statements are a kind of data citation) and allow you to do queries like, how many articles cite this dataset? Or the reverse which datasets are cited by this set of papers.
Similarly a reference to an article at the data repository side is equally ineffective if there is no machine readable citation. Below shows an example of a reference in the Figshare data repository.
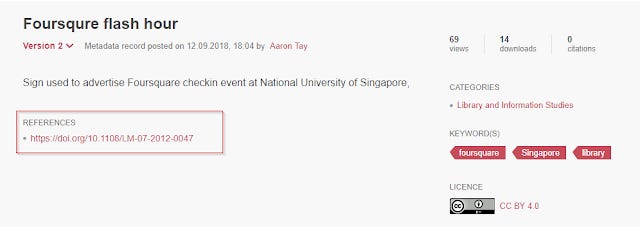
Reference to article appears in landing page for Figshare data repository, but is there the right metadata?
To do this, an infrastructure needs to exist that governs how references between articles and datasets are exchanged and aggregated , and indeed between CrossRef and Datacite collaboration and Scholix (which is pid agnostic), such a framework is beginning to emerge.
Sidenote : It occurs to me datasets are more complicated to deal with than articles, because while Crossref is not the only DOI Registration Agency that issues dois for Scholarly articles (mostly published final versions but now including preprints) , it does issue the vast majority of them. Datasets are more murky and while Datacite is surely the lead doi minting services for dataset related hubs , there are plenty of datasets that do not even have dois but have other pids. But for rest of post I'm going to focus on dataset searches with Datacite dois.
The great thing is both these questions have been answered by 2 excellent webinars by Datacite. I highly recommend anyone interested in these issues to have a look at them.
You should really watch both webinars which are both under 1 hour in duration each, but I will briefly summarise what I consider the main points.
Google Dataset Search Webinar - everything you always wanted to know about Google Dataset Search
https://blog.datacite.org/google-dataset-search-webinar/
Why care about Google Dataset search? As noted by Martin Fenner from Datacite recently, Google Dataset search is already in the lead when it comes to searcher interest.
This is a similar comparison for discovery of research data. Data Citation Index vs. DataCite vs. Datamed vs. Google Dataset Search. Google Dataset Search still young, but already in the lead https://t.co/9EznswtWuz
— Martin Fenner (@mfenner) February 5, 2019
Some points I found interesting from the Webinar
1. It is indeed "Google Scholar but for datasets" though the service appears to be responsible by a different team.
2. That said there doesn't seem to be any special crawler but data is picked up using the regular crawler than cleaned, reconciled with Knowledge Graph and like Google Scholar it tries to pick up "replica" or duplicates and can show multiple locations of the same dataset.
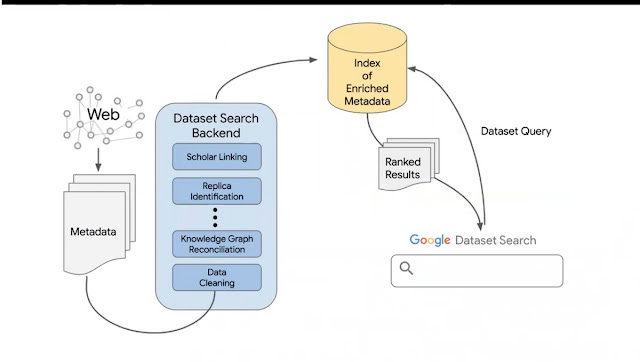
3. There is some interesting elaboration about how data picked up by crawlers is reconciled against Google Knowledge Graph
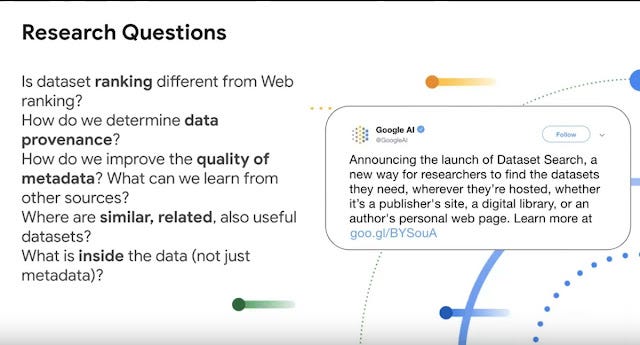
4. The speaker mentions that the same dataset in multiple locations can generally be seen as a sign of quality dataset (ranking signal?). That said, Google is still trying to figure out how best to rank datasets "Ranking is big issue, no one really knows how to rank datasets". Trying to determine similar or related datasets is also another interesting challenge. e.g. Can you find 2 complementary datasets with similar index that can be combined? Google is mostly "mostly using web ranking", other signal citations & metadata quality, the hope is to release this tool first and see how users are using it.
5. Schema.org is king. For the dataset to be visible Schema.org tags for dataset type (preferably JSON-LD but Microdata format, tags in html works too) needs to be on the repository page. \
6. A sitemap isn't strictly needed but it is good practice to ensure the crawler can get to the data. You can also check your Google Search Console to see if there are issues (this is pretty much standard good practice for checking optimization of webpages and even Institutional repositories).
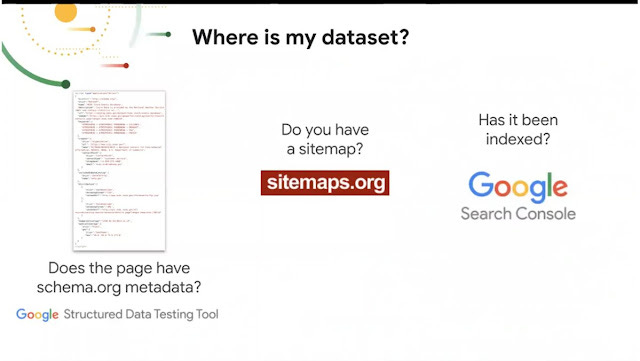
For more details refer to the FAQ linked from Google Dataset search, which talks about using the Markup Helper to create metadata and Structured Data Testing Tool (SDTT) to verify if there is the right metadata.
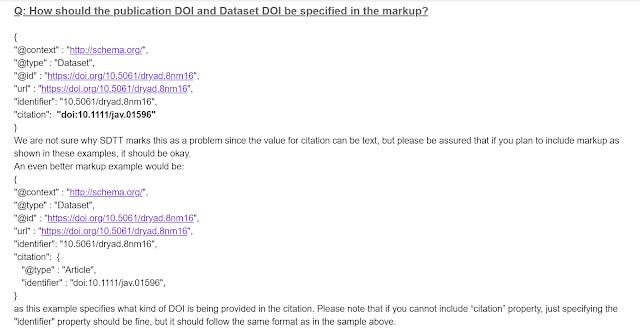
Q: How should the publication DOI and Dataset DOI be specified in the markup?
Interestingly, the FAQ suggests the SDTT tool is somewhat buggy.

7. "Although it is currently not a listed property in our documentation, you can refer to details about the "funder" property on http://schema.org/Dataset."
8. Question about how data citation counts works.
All in all, it seems everything is in flux and Google themselves are unsure how things will progress. At the very least , we now know how to get datasets indexed.
How well do the main data repositories particularly those used by institutions e.g Figshare, Dataverse etc support being indexed in Google Dataset Search?
As I noted in my earlier blogpost on Google Dataset search, the key when selecting a data repository is to ensure that there is support of embeding of Schema.org JSON-LD on the data repository pages.
A Data Citation Roadmap for Scholarly Data Repositories https://t.co/o2lQkoNclB . Curious how well do data repositories like @figshare @dataverseorg @tind_io @Mendeley_Data, @datadryad, @ZENODO_ORG, Dspace etc match up to these requirements? Anyone done an analysis? pic.twitter.com/CTzwbHUvz8
— Aaron Tay (@aarontay) August 10, 2018
Interestingly enough the Data Citation Roadmap for Scholarly Data Repositories only lists support of Schema.org as a recommended and not required guideline but I suspect the launch of Google Dataset search will make this a must have. Already repositories like Zenodo, Figshare etc already have this support (see replies to my Tweet).
I'm less sure about open source options like DSpace or Eprints but if you manage it yourself it might be a good idea to go check. A simple site:datarepositoryurl.com should suffice.
Of course, if your datasets all have datacite dois, Google dataset will catch them via the Datacite search pages which are all embedded with Schema.org tags but why be indexed in such an indirect way?
Machine readable/actionable data citations - linking papers to datasets
In October 2018, I speculated about how Scopus is able to link to datasets from papers on their details pages in the "Related Research Data" section. Others that try to pick up articles to Dataset links include Europe PMC and Dryad
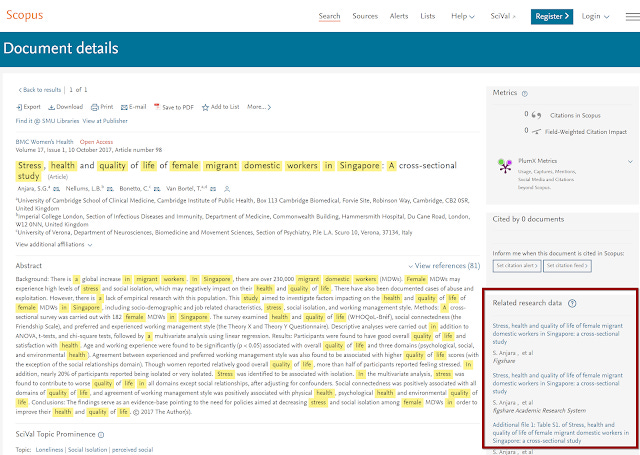
As Scopus is known to have implemented Scholix, we know Scopus uses the DOI to "query the DLI (Data to Literature Link) service for links between that publication and any datasets" and to display a “Related Research Data” box in the sidebar with the dataset’s author, title, publisher, and identifier with an external hyperlink.
I speculated that the data citation link was either deposited by article publishers at the time when the paper was submitted (and there are two ways to do this via either as a bibligraphic reference or asserted as a relationship. See this for more details) or it was linked later on the other end by the Data repository that accepted the data deposit.
It was the later part that I found murky and it was unclear to me which of the major data repositories such as Zenodo, Dryad, Figshare, Mendeley Data, Dataverse or IR modified systems like Dspace properly supported this.
One thing was for sure, after some testing, I realised simply seeing a reference on the data repository page of say Figshare or Dataverse did not necessarily mean that the data citation would be captured.
For example, simply entering a doi of the article that cited my dataset when depositing the datatset into Figshare was not sufficient.
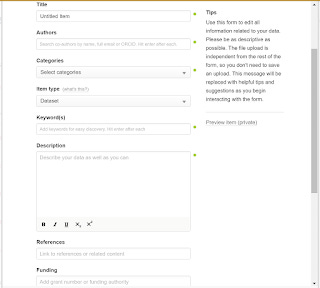
Adding the doi of the article in the references field of Figshare form is not sufficient to ensure the creation of a machine readable citation that will be picked up by systems like Scopus.
Just because a reference to the paper citing this dataset is showing, it may not be captured
Looking at cases where the link between article and dataset could be found in Scopus or DLI Service - Data-literature linking service, I figured out the key was that in the case of a Dataset with a Datacite DOI, the DOI has to be registered with the right metadata.
But what is the right metadata?
The Crossref and Datacite joint webinar explains all
Last month, Crossref and Datacite held a joint webinar that basically confirmed my theory.
https://www.youtube.com/watch?v=U-k6cuNvLms&feature=youtu.be
Data citations when depositing to data repositories
Let's talk about data deposits from the data repository end. Firstly of course you need researchers to include associated publications in the dataset metadata. But how should the metadata be formatted?

As noted below you need to deposit appropriate metadata with Datacite using the fields "relatedIdentifier", "relatedIdentifierType" (e.g DOI) and "relationType".
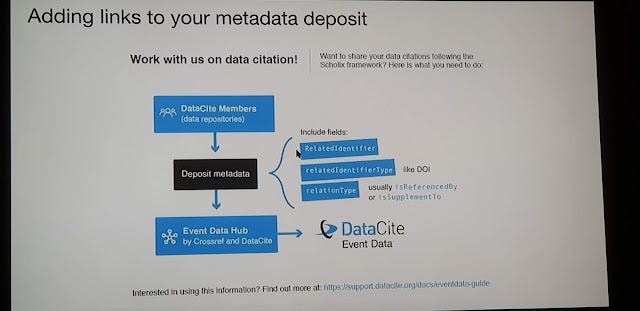
Below shows a typical example where there is a "IsSupplementTo" relationship between a Crossref doi (article) and a datacite doi (dataset) deposited at Figshare.
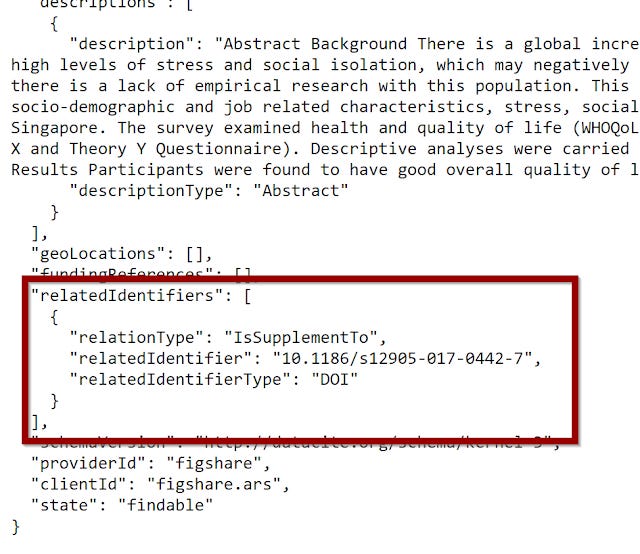
This basically says that the dataset (which has a Datacite DOI) in question "Is supplement to", 10.1186/s12905-017-0442-7
Data citations when Publishers deposit to Crossref
Ideally, data citations should be captured by journal publishers at the point where the article is published. Though for various reasons they don't e.g Dataset was not ready (or even certain) to be shared at the point in the time when the article was submitted and/or there was no reserved doi for the dataset. But assuming the ideal scenario where publishers are getting the data citation.....

As mentioned journal publishers can capture data citations in two ways . Firstly as a normal reference (the usual way they handle article references, encoded in XML) or by creating relations. Also see this blog post by Datacite.

Option 1 below shows data citations captured by publishers as normal reference
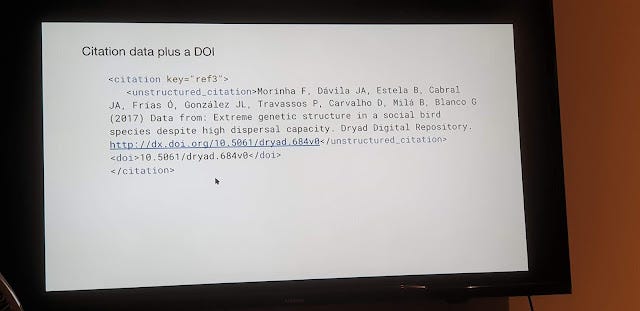
Option 2 below shows data citation tagged as relations by publisher

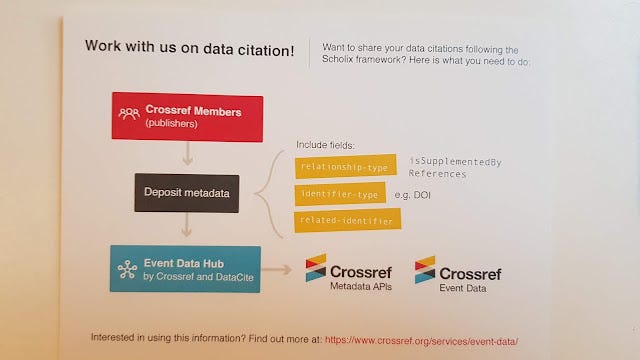
Interestingly enough journal publishers can do both as well. During the webinar, someone asked how many publishers now do data citations properly, and the speaker wasn't sure except to say probably not that many right now.
Looking at "A data citation roadmap for scientific publishers", it seems to me quite a lot of work needs to be done beyond just capturing and processing technical metadata, this includes educating editors, peer reviewers and authors on the requirements, listing acceptable repository domains etc.
That said, I happen to know quite a few journals do have requirements or instructions about depositing datasets and the need to produce data availability statements which can be seen as a specific type of data citation? Are all these not captured by Crossref? Seems like a waste.
What if the references are deposited closed by publishers?
A somewhat interesting question popped into my mind. What if the journal publisher decided to use #1 to encode data citations in references but kept the references closed (e.g. Elsevier, ACS, IEEE) what impact would that have?
Hi @aarontay, whether the references are open or not does not affect whether references with DataCite dois appear in event data. This is the same if the information is linked via relations. The data citation information is the same on both sides in Event data.
— DataCite (@datacite) February 1, 2019

Combined with above slide it seems to me that even if the journal publisher is depositing data citations with references closed while you cant query the Crossref metadata API directly to see the citations, you can still see the citation to Datacite dois via event data?
How to check if the link is done properly

There are 3 ways to check if the reference is done correctly and can be picked up by machines. You can either query the New Crossref Event Data API, the Datacite API or Scholix API (or search any database that supports Scholix like Scopus , Scholexplorer, Europe PMC though some might update periodically).
In the example below, I'm using the Scholix API to confirm that my dataset in Zenodo at 10.5281/zenodo.1414634 is correctly linked to my article at 10.1108/lm-07-2012-0047

How well do the main data repositories particularly those used by institutions eg Figshare, Dataverse support data citations?
It's tricky to figure out which data repositories e.g. Figshare, Dataverse, Tind, Mendeley Data etc support data citations properly as it's hard to tell if the metadata is generated and passed properly and there seems to be no easy way to tell until you deposit and do the checks as noted above.
One clue that helps though I suspect is when you deposit datasets, you are given the opportunity to not just add a citation reference but also specify the type of relationship such as "is supplemented by"
So far I have noticed Zenodo and Mendeley Data having the option to define the relationship type ("relationType")
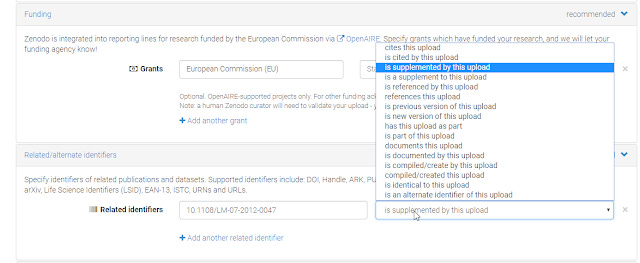
Defining relationship between citations in Zenodo
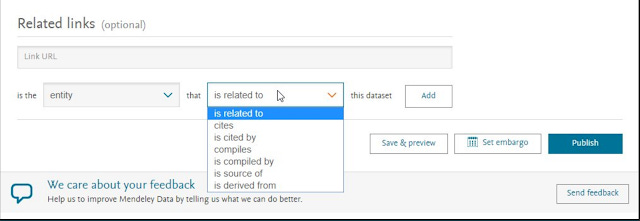
Defining relationship between citations in Mendeley Data
As noted in my earlier blog post, I suspect quite a few data repositories run by institutions are missing a trick here. In many cases it probably requires some setup option or plugin to be added because the data captured from the fields entered when depositing datasets etc are not automatically captured or mapped in the metadata deposited to Datacite.
e.g. From what I understand based on a conversation with tech support last year, Figshare for institutions installations can choose to turn on additional fields for data citations to be properly captured and processed but it is not a default option (though there might be some drawbacks to doing this).
Conclusion - more questions than answers and talking Dataset usage
This is still very early days when it comes to datasets. But it is great to see organizations like Crossref and especially Datacite take the lead here.
Of course, there are still many issues to considered. Take data discovery by keywords in Google Dataset search. Simply being indexed is just the bare minimum. What other fields should be included to enhance discovery in the ranking algorithms? Can schema.org be further enhanced to allow dataset search engines to standardize indexing of Code books, column fields of datsets etc. How should Web scale discovery services like Primo, Summon, EDS intergrate dataset discovery? All in all, what are the features needed and desired by users of dataset search engines?
Besides discoverability, measuring use of datasets is also critical, and this is where the Make Data Count Project (supported by Datacite, Dataone and CDL) is important as well.
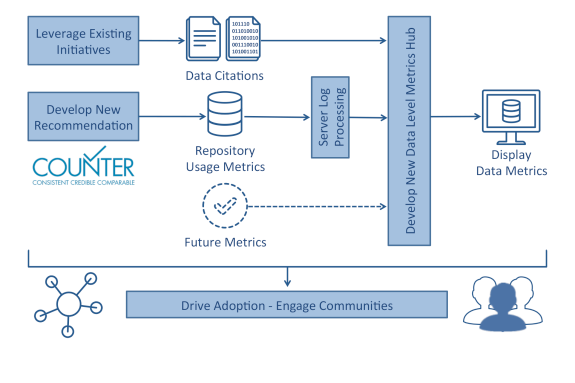
Among some of the goals are
1. to publish a new COUNTER code of practice regarding how data usage and impact should be meaningfully measured and reported;
2. to deploy a data-level metrics (DLM) aggregation and publication service based on the open-source Lagotto software and hosted by DataCite
3. to integrate the DLM service with new exemplar data sources and clients; and
4. to perform advocacy and training regarding the importance and use of DLM to develop engaged communities of practice and support.
I'm particularly excited by the idea of a aggregation service.....
Data discovery is definitely an interesting area to watch.