
Navigating the literature review - metaphors for tasks and tools - How do emerging tools fit in?

Synopsis : I summarise some of my favourite literature review tools that have emerged in the last 2 years or so and the use cases I see them fitting in. In particular I briefly cover tools and techniques I like that help
to record what has been found - basically reference managers [Zotero]
to efficently check and gain access to full text - basically browser extensions like Libkey Nomad possibly other methods of access (SeamlessAccess, GetFTR etc).
to find review papers, systematic reviews, meta-analysis, [2dsearch+Lens]
to use citation related techniques to create graphs of similar papers [Connected papers, Citation Gecko, InCiteful [New!] and many more]
to aid citation browsing by classifying citations by citation contexts which help you make sense of citations and to decide which citations to follow next [Semantic Scholar, scite]
Not all these tools will be useful and will take some experimention to see which works best for you!
One of the more interesting ways to think about the research process particularly for novices is to describe it using more engaging metaphors.
For example, librarians have framed and mapped the research process as akin to Joseph Campbell’s “hero’s journey”
Some librarians have even created a whole tutorial of games along the whole conceit.
http://adventuresofsirlearnsalot.blogspot.com/p/sir-learnsalot-and-sorceress-librarian.html
However, if you prefer a slightly less fanciful metaphors, how about seeing doing literature review through the lens of an explorer in the "literature" jungle- perhaps a collector of rare flowers or plants?
Earlier this year, I stumbled on a blog post , where the author talks about different metaphors for literature review and below is some of the most evocative writing I have seen that I feel accurately describes the process and uncertainty one faces when first trying to make sense of the literature in a new unfamilar area.
"I’m fighting through thick jungle, at any point I may be tripped by a creeper that I haven’t seen, or ambushed by a wily jungle animal. I’m collecting plants and flowers for my museum collection – I am distracted by those that look or smell most beautiful, but it’s important that I make a representative collection and can justify each specimen."
Beautifully put. The overwhelming infomation overload, the confusion of plunging into the thousands of results you get when you enter a keyword in Google Scholar it is all captured beautifully. He continues...
"At almost every step, there is a tantalising byway where I see glimpses of plants that I have not yet collected – but are they important? I need to compare them with all the others, but my bag is so full I can’t easily look through them all. Perhaps I should collect them just in case …. But the weight of all the specimens is slowing me down and I wonder if I will ever find my way out and be able to make sense of the collection."
Indeed, how do you know what is important to collect? How do you know you have collected the right things? Have you missed something critical? So many papers, books and reports to read, so little time. How do you make sense of it all....
As a academic librarian with an interest in literature review and in helping post graduate taking their first steps into research and literature review, I am very always looking for ways to help reduce this initial stage of confusion as much as possible.
Also as I write this in 2020, we are also witnessing the emergence of many new research tools (spurred partly by the availability of open scholarly metadata and full text) that use machine learning smarts, can any of these help? How should we position these bewildering array of new tools in the literature review process?
The researcher tool kit metaphor
Back in 2012/2013, there was a series of interesting workshops on the then relatively new library discovery tool - Summon. Librarians were still grappling with how to position such tools and one idea was to describing various use cases metaphorically - e.g. "Summon as a telescope" or "Summon as a microscope" etc.
Of course, on reflection it now seems to me now it is unlikely any single tool could be that flexible, but the idea is one that I will steal here as I classify all the various techniques and tools I am familar with along such lines.
The collecting kit - Reference Managers and Full text finders
Even before I talk about literature review tools, I usually find it useful to ensure that our users have the fundamentals down so that they can obtain, collect and record what they find in a efficient manner. This is what I call the "collection kit".

I usually advise new users that before they go plunging into the "literature jungle" - throwing keywords at Google scholar and databases to think about how they want to keep track of the literature they have already found.
Using the "log book" or "backpack" metaphor , you need a way to record the papers you have seen or collected and in most cases it means using a reference manager.
While there are many reference managers out there , I find it hard currently to recommend anything else except the free and opensource Zotero due to it useful list of plugins.
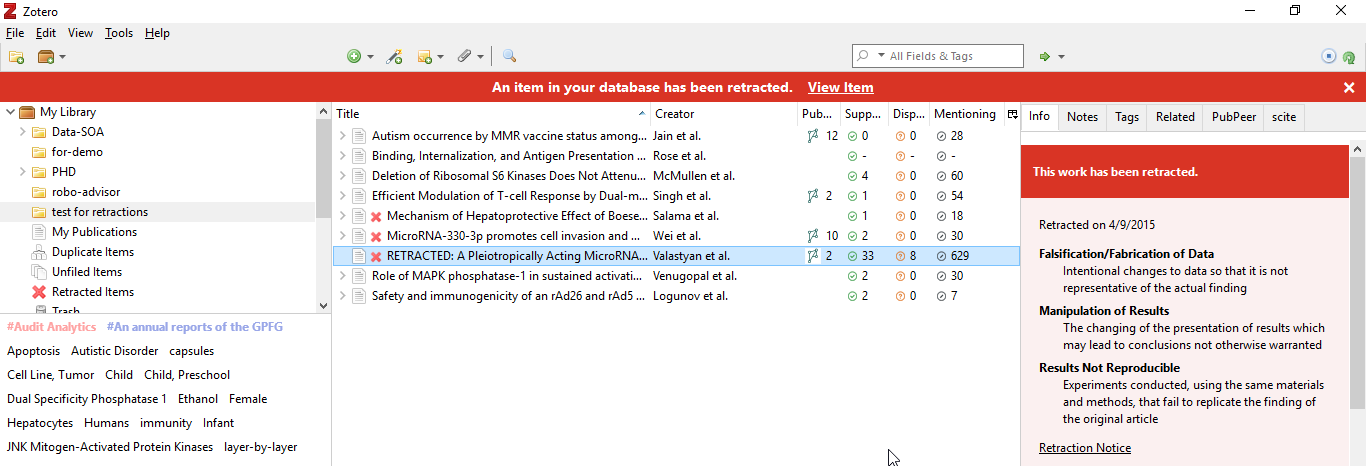
Zotero - my currently favoured reference manager
That said, I find some researchers still prefer to use their tried and tested system with Excel or Word setup which is fine. But the next thing I recommend is usually something they do adopt.
It's one thing to find the citation of a paper that is interesting, another to be able to quickly and efficiently get to the full text (or request for the item to be purchased or borrowed by your institution library if necessary).
I use the "shovel" metaphor here, tools or techniques that can quickly allow you to dig up to get the thing you want.
Typically I cover Google Scholar library links just in case even though this is pretty well known.
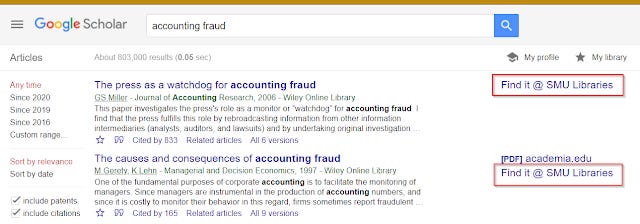
Library links in Google Scholar is IMHO always worth a brief mention
That said the methods for authenication and access of resources are getting more varied. Currently, Access Broker browser extensions such as Kopernio, Libkey Nomad, Lean Library etc are one of these options that most institutions have started to support.
Awareness of these tools are generally low, so it is usually worth showcasing briefly (I usually show either Google Scholar button and/or Libkey Nomad), other methods like SeamlessAccess, GetFTR might be worth showing in the future.

Some Access broker browser extensions - including free ones
Once this is done, we can focus on the actual meat of doing the literature search.
Note: Sometimes when I have a time, I will make a brief note about "current awareness" tools, typically search alerts as well.
Exploring tools

I must admit when I was doing my MLIS, I did not encounter the classic - The Oxford Guide to Library Research and I only came across it much later when I noticed it was one of our most accessed ebooks (thanks to an assigned reading for a 101 sociology course of all things). I then blew through it in a weekend , and found it interesting the way it classified the various methods doing library research.
It's an impressively comprehensive listing of techniques but obviously, there is little point in going through every single technique/method with users.
Instead I focus on these 3 techniques
a) Keyword searching - "the Binoculars" metaphor
b) Starting with a review paper, systematic review etc -" the map of the landscape" metaphor
c) Using citation trails - the "following tracks" metaphor.
1. Keyword searching - the Binoculars metaphor
Keyword searching of course looms large in the mind of our users and this is what they expect us to teach and focus on.
Given limited time to talk, I tend to not focus on this because this is rather well known and success in keyword searching often comes down to A) Searching the right sources and B) Searching the right keyword.
I tend to compare keyword searching to that of using a Binoculars (which fits the Jungle explorer metaphor better) or telescope.
This is a powerful tool/technique if you know where to point the "binoculars" at which translates to knowing the right keywords.
But like a binocular or the even more limited Telescope using such tools gives you a very limited field of vision so if you point at the wrong thing (use the wrong keyword), you will miss out a lot of relevant items.
Newer search engines, incorporate some features to help reduce this "limited field of vision" problem by not taking slavishly what you enter and try to extrapolate to what you really want...
From basic stemming which almost every system does now to less commonly seen synonym/keyword expansion (perhaps using knowledge graphs), dropping of keywords and to the extreme incorporation of full blown latest NLP techniques like BERT (e.g. in Google) we see various approaches that trade-off "smarts" against predicability of search results
Still in the academic space, even the more "Semantic" search engines such as Microsoft academic, Meta still rely heavily on the right keyword being entered.
It's hard to give specific advice that generalise for keyword searching besides stressing the importance of iterative searching or going into use of subject specific indexing terms, so let's move on to the next area. \
2. Starting with review papers - the guide/maps metaphor

When people ask me for help with literature review, you can broadly divide them into two categories. There is the "I can't find anything on the topic I am looking for" people and the "I got too many things, I don't know where to start" people.
The later group in particular can benefit from the technique that tries to look for review papers, systematic reviews, meta-analysis, and other rich sources of references as a starting point to kick start your result.
I usually describe this with the metaphor of having in hand a rough map/notes of the lay of the land from a past explorer. Review papers , Systematic reviews etc are particularly useful in area where there is a ton of literature and having an expert provide his mental map of the area has often proven invaluable to me.
It is hard to overstate the time you can save by finding the right review paper, which is why I focus a lot on techniques for finding them.
Of course the simplest way that works fine is simply, typing <topic> review in Google Scholar, but because of the value of finding even one extra review paper, I have experimented with other techniques.
This includes a systematic way of finding such reviews by using a canned boolean search in 2Dsearch + Lens.org to using controlled vocab in subjects (e.g. "Review article" field of study in Microsoft Academic, "Review" Document type in Scopus) and even software that try to detect such reviews using citations (e.g. "Derivative works" feature in 2D search)
These techniques are not purely theortical. For example, I was working with this phd to map out new areas that was cross disciplinary and I noticed she was sharing wth me a lot of review type papers. I used the 2Dsearch + Lens.org technique to easily find a couple more and she was surprised and asked me how I found them.
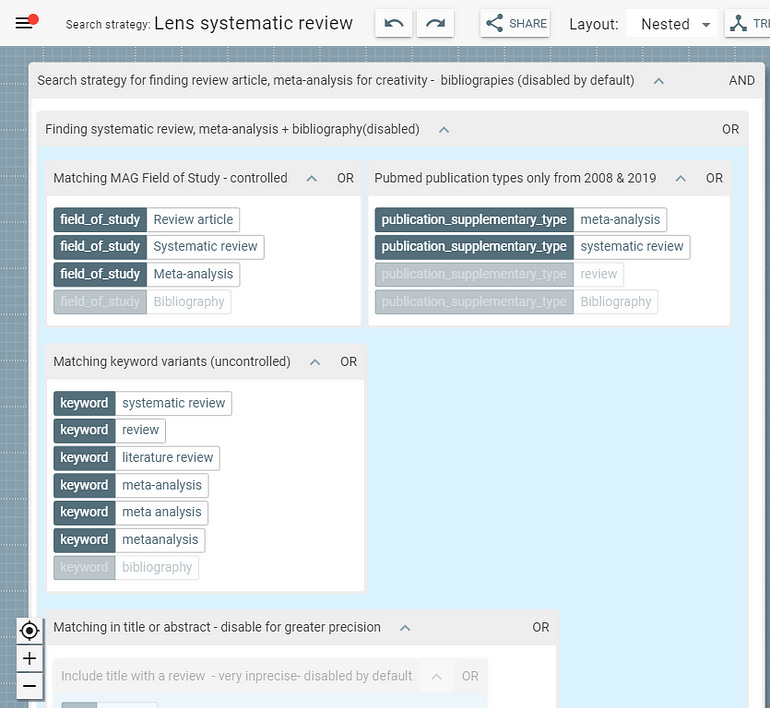
Canned search template to find reviews in 2Dsearch for Lens.org
3. Citation trails - retracing the trails/footsteps metaphor
The earlier technique can be useful for finding other related literature which can help with the "I can't find anything" issue. They help with keyword searching by suggesting other keywords to use, allows you to go further down the citations trails of the papers identified etc.
But in many cases, such researchers tend to be looking for either something really specific or something that is pretty new or novel in which case it's unlikely a review paper exists.
This is probably the most tricky situation. If you do your best and can't find anything at all on X, is it because X doesn't exist (which can be good) or simply you are not searching the right way?
Since you can't really prove a negative, I find this leads to a lot of anxiety sometimes and I can't tell you the number of times someone (typically a undergraduate) come to me to tell me X "must" exist.
While you can't be 100% sure something does not exist, you can reduce the chance of missing it.
When you think about keyword searching, there are only two reasons you miss something.
Firstly, the index you are using does not have it. This is discipline specific but I think compared to 20 years ago or even 10 years ago this is a much smaller problem.
Mega-indexes like Google Scholar, Lens.org, Semantic Scholar supported by trends like open access , electronic thesis and dissertations, online preprint servers means that for many fields you don't have to search a dozen search indexes to have a fair coverage of the area.
Sure, not everything is online or for older pre 2000 content digitized (or digitized in full text/properly), nor is every grey literature in tools like Google Scholar, Google books and all bets are off if you move away from article type content but generally adding some subject specific databases like Psycinfo will help cover for that.
The bigger issue these days, is you are missing out something relevant because you you got unlucky with the keyword.
This could be because the area/topic is still new and people are using diverse terms to describe the same thing, or in the case of older content, the terms used might have shifted.
If you were using controlled subject terms you could mitigate this issue a little, but it presumes that the search system you are using supports it and the librarian has properly done subject/index cataloging and you know how to use it - in most cases this applies to users of PubMed.
This is particularly common for statistical and research techniques that have a long history, I remember being surprised late in one research project by finding a 1980 paper on the very topic I was doing research on because of that reason.
So how did I find that paper? Simple by followng the citation trails. This is akin to following footsteps or trails left behind by prey or other hunters.
Again this technique is generally well known and intutive to most researchers and they intutively follow references of relevant papers, or used "cited by" functions in GS.
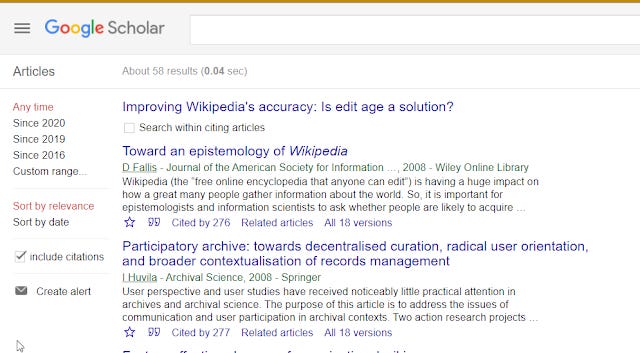
cited by function in Google Scholar
Enhanced/smart citation trails
While the idea and practice of finding papers by following citation trails of relevant papers in either direction has a long history (sometimes known as pearl growing search strategy), there has been throughout the decades recommendations of ways to go beyond this.
For example, there has been increasing interest in classifying citations by "citation contexts" in the literature to aid researchers when they follow citation trails.
Informally citation context can be viewed as describing how a paper is being cited. So for example, one could classify a citation as a "mentioning" cite, a "supporting" cite (where the citing paper has findings that "support" the cited paper) or a "disputing" cite (where the citing paper has findings that "dispute" the cited paper depending on how the citation link was made between the citing paper and the cited paper.
A Citation Typing Ontology , CiTO even exists .
But how can such a system be made practical? while there has been suggestions to encourage authors to type the citations they made, this seems unlikely to take off.
The solution of course is to use machine learning.
In general this would require a training set consisting of not just citations but the citation statements which can be defined as the chunk of text (e.g. 2 sentences before and after) just before and after where the in-text citation is made.

Citation statement of a paper - displayed in Scite
One would then create the training set by manually classifying these citation statements into categories one would be interested in. So in the above example, humans would classify such statements into "mentioning" , "supporting" and "disputing" cites. This training set could then be used to train a classifer to classify other citation statements.
As I write this, two cross-disciplinary systems with reasonable coverage of citation contexts and statements exist. One is Scite, the other is Semantic Scholar.
I have reviewed and mentioned both Scite and Semantic Scholar many times, so I won't go into depth.
Of the two Scite is the more foused tool, concentrating on what it calls "smart citations", trying to build a ecosystem around the new citation metrics with dashboards, badges and visualization features and even display them in Zotero.
However what I consider it's core use is the ability to look at paper and search by the type of citation context. For example, one could search for papers on a certain topic and sort them by the most disputed citations.
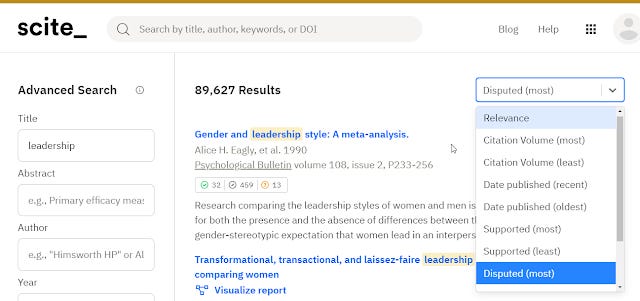
Sorting papers by most disputed
For interesting seminal papers or review papers with a lot of cites, it is often difficult to decide which of the 1,000+ citations you should follow, this is particularly true for citations of review papers. With scite, you can filter quickly to those papers that have engaged with the paper more, by looking only at "supporting" or "disputing" cites as opposed to those that merely mention.
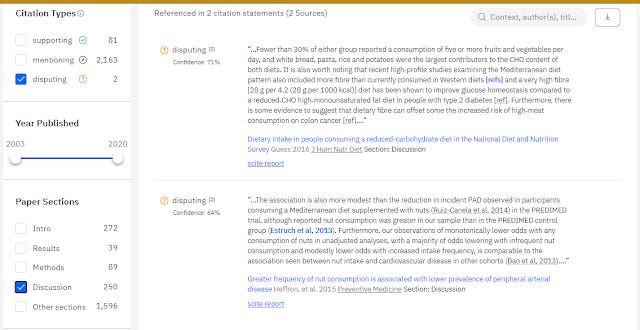
Filtering to disputing cites of a paper
scite also allows you to filter to cites by the section the in-text citation was made. For example, in-text citations made in the methods section have different implications from those made in the discussion section vs those in the intro section.
Of course, scite's classifications are based on machine learning so there is a possiblity of error. But I have found that even if you ignore the classification and just look at the citation statements, it helps a ton to decide whether it is worth downloading the citing paper to investigate further.
In some ways, that might be worth more than the classification itself!
A similar tool is Semantic Scholar by AI2 (Allen Institute for AI), which is a new emerging feature complete academic search engine comparable to Google Scholar and Microsoft Academic.
For the purposes of this blog post, we focus on the citation features.
On first glance when you look at citations of a paper in Semantic Scholar, it looks similar to what you get on Google Scholar allowing you to "search within" the various citations (though unlike Google Scholar this searches within metadata usually not full-text).
You can also filter them by various criteria such as "Field of Study" (look under "more filters") and "date range" which again is useful if you are looking at a review paper which typically has a lot of cites.
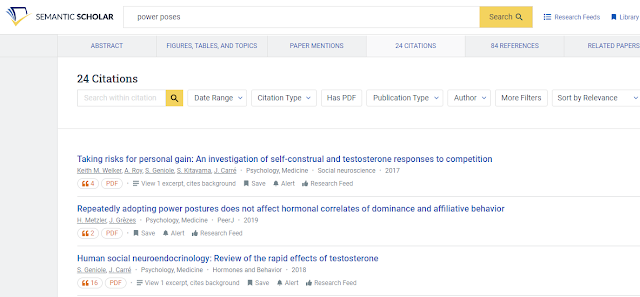
Search within and filter citation pages in Semantic Scholar
I find for papers with a lot of citations, "field of study" is a pretty good filter to see how many citations come from different fields.
Semantic Scholar allows provides it's own type of machine classification of citation context. It classifies citation by whether a cite
a)cites background
b) cites methods
c) cites results
and this is something you can filter by too under "citation type"
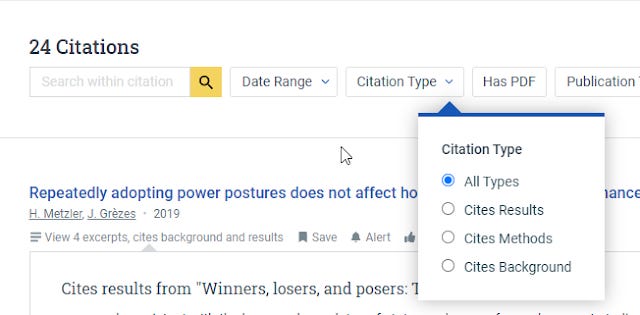
Filtering by citation type in Semantic Scholar
"Our system indexes billions of citations, using AI models to classify the intent and predict the influence of each. We’ve identified three classification types; cites background, cites methods, and cites results. You can find citation type by scrolling to the citations listed for any paper and using the citation type filter to identify papers that cites background, cites methods, or cites results."
My understanding is this classification isn't just based on the location of the in-text citation.
On top of that it tries to identify cites that are “Highly Influential" , instead of incidental, giving you a hint of which citations to look at first.
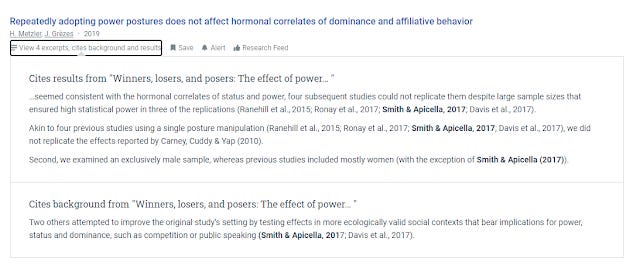
Citation context in Semantic Scholar, showing citations that cite results and background

Citation identified as "highly influenced" by Semantic Scholar
How useful are citation context in pratice?
While all this sounds good on paper in reality how helpful are they? I have had more experience with scite but essentially i think it boils down to two things.
Firstly how accurate are the classifications? Secondly how complete is the data in the system?
In terms of accuracy of classification, in the case of scite my experience is that it is actually pretty good. They have reported high recall precision rates in general of 0.8-0.9, but with lower recall rates. In particular they try to err on the side of caution particular for "disputing cites" which are also fewer in number.

scite confidence score
scite also displays a probability score, I have found in general when it is anything above 80% , it tends to be right , anything below tends to be wrong or at times ambigious, to the point that even as a human reading the citation statements, I can't decide either.
I think it is harder to judge for Semantic Scholar's judgements particularly for "highly influenced" citations (subjective?) but probably the accuracy is in the same ballpark.
The main issue with these tools now is not so much accuracy but completeness of coverage.
After all, they require not just citations (which are increasingly made open, due to efforts like I4OC and I4OA) but the citation statements which in effect means having the full text to extract the necessary text.
scite currently claims 23 million full text articles processed and 811 million citation statements extracted and analysed, which unfortunately means there is some way to go. (e.g. Scopus is typically pegged at around 60 million to 80 million articles).
Because scite only shows citations that they have citation statements extracted you might not notice that not all citations to a paper are displayed. You will typically see a paper having far less citations in scite compared to most citation indexes because scite does not display citations where it has no citation statement/sentiment.
Semantic Scholar has a similar problem, and it is much more obvious there, because they will show all citations that are available but only a smaller subset they will have data to do citation contexts.
Below for example show a list of citations, where Semantic Scholar knows the 5 citations was made but could not determine the citation context for 2 of them (the first and third).
All but the last citation has a citation context in Semantic Scholar
Hopefully this coverage will improve, as both scite and Semantic Scholar are signing up partnerships with publishers to supply them with full text to analyse.
Semantic Scholar, recently announced partnerships with Cambridge University Press, while scite signed up Wiley and CUP as well.
Semantic Scholar in particular has a pretty good lineup of partners including Sage, Wiley, Springer-Nature and Taylor& Francis, 4 of the 5 biggest academic publishers, with Elsevier the only hold-out.

Publishing partners of Semantic Scholar
This I think implies they have the full text from these sources and are able to do citation sentiment analysis for citations coming from these papers?
Tracing citations at scale
As you start doing citation trailing by following references and citations, you may find the number of papers you need to trace starts to explode. Even with the help of "smart citations" to prioritze which papers to follow, it may become too much.
Is there a way to do this at scale?
Indeed, I have been tracking the rise of tools that use citation relationships in bulk to help find or recommend more relevant literature from identified relevant papers.
I think this splits into two different types of tools.
In the first group we have tools like VOSviewer, Citespace etc. Strictly speaking such tools are bibliometric mapping tools, they are more designed to give you a bird's eye view of a certain area of research.
A typical workflow would involve uploading a set of papers into these tools via export a set of results from a search index by keyword like Scopus, query apis by keywords etc) and the bibliometric tool would then map and cluster relationships (typically citation based) among the papers and provide a visualization.
CiteSpace auto clustering and labelling of papers from Scopus on topic Team Creativity
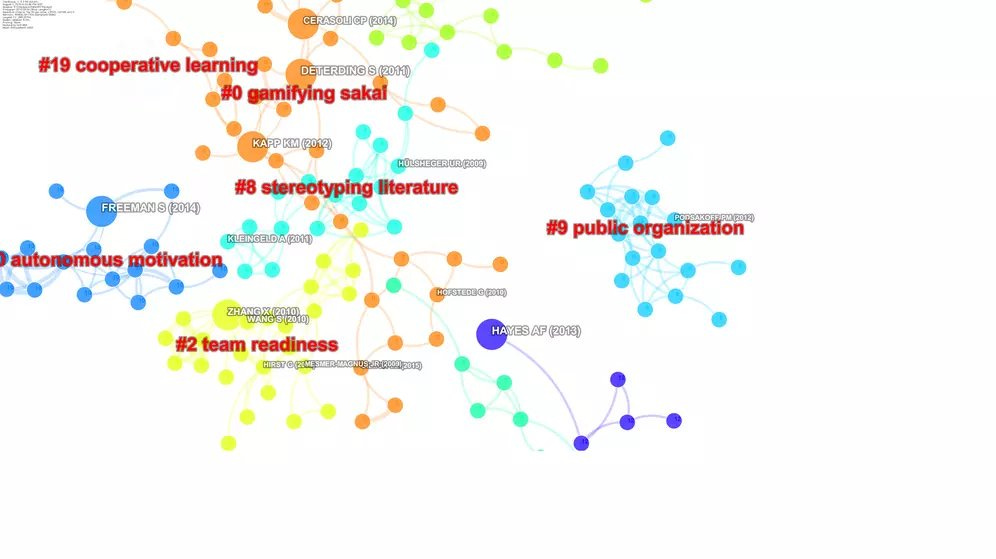
In the above example, we see CiteSpace ingest papers found by using the keyword Team creativity in Scopus and auto-cluster and auto-label the papers.
Another visualization methods available includes creating a term occurance map by mining the words in titles and abstracts of papers and clustering the results, which can help with keyword selection for searching.
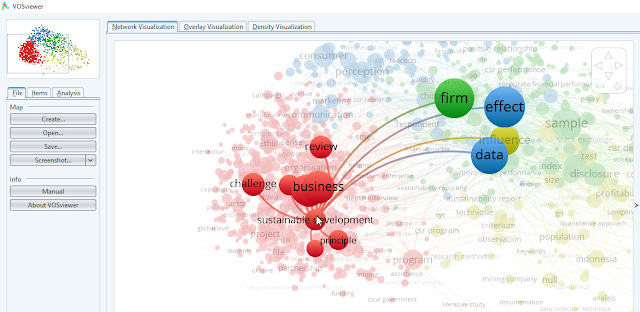
VOSviewer - Term occurance map - Title/abstract - Corporate Social Responsibility 2015-2020 from Microsoft Academic Graph data
For more see - Dimensions & VOSViewer Bibliometrics in the Reference Interview
These tools were designed more for bibliometricians rather than researchers doing literature review, but have been adapted to aid literature review mapping by helping to make sense of the literature and how the clusters of different literature are related to each other.
Beyond bibliometric mapping tools - Citation Gecko, CoCites, Connectedpapers, Inciteful and more
That said while these tools help you see the forest for the trees, they generally wont help much if you can't really find any suitable "trees" in the first place.
They also tend to be kinda obscure to use, you need to do odd things like exporting files from citation indexes and/or running APIs as well as understanding of bibliometric terms.
How about tools that are designed for the researcher that take the simple approach where you input one or more relevant papers and it automatically generates a citation map of related/relevant papers and/or recommends related papers?
The first in this new class of tools, I could identify was Citation Gecko [2018] which allowed you to enter x number of relevant "seed papers" and it would identify promising papers that were possibly relevant because they were cited or citing "the seed papers" a lot. You could add those papers as seed papers and iterate the proccess , growing the citation map step by step.

Citation Gecko - finding related papers from seed papers
Today just 2 years later there are many more now (see my list), from CoCites which is specially designed to work with life science disciplines (Pubmed index) to one of the current favourites Connectedpapers a slick tool that takes one paper as an input an generates a graph of 20-30 related literature papers.
The graph is generated using a similarity metric that uses a combination of bibliometric coupling and cocitations. As such it can work on even new papers with zero citations (as long as there are papers with similar references - the bibliometric coupling part).
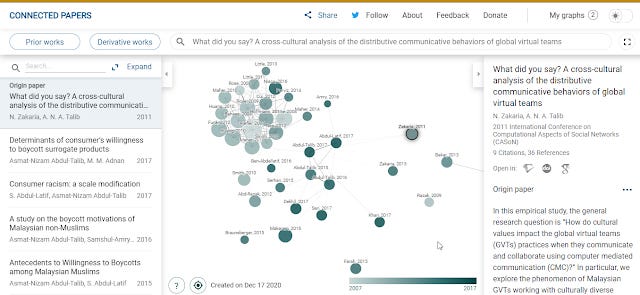
Once it has generated the list of related papers, you can exploit this graph to try to find "Prior works" (basically seminal papers) and "Derivative works" (basically survey and review papers) based on the logic if this paper cites a lot of similar papers in one area it might be a review paper, which links nicely to the earlier method.
As I write this, I am just aware of yet another tool called InCiteful , which draws on a large pool of data including (though some used abstracts, rather than the citations e.g. Semantic Scholar).
Crossref
Microsoft Academic
Semantic Scholar
OpenCitations
It's pretty quick and fast with advanced options (you can view and edit SQL!) and has been described by the author as sort of an Connected Papers for power users (though the defaults are fine too).
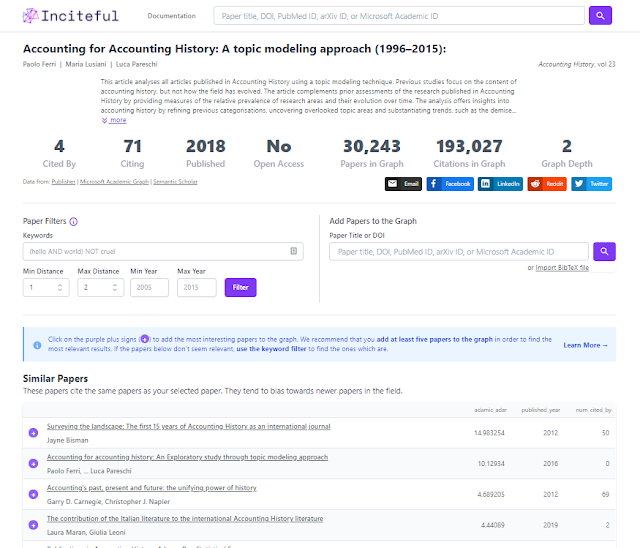
It's detailed documentation papers, give you a lot of detail on how it works.
Essentially, when you enter one seed paper, it will look for papers that cite that paper and those that it cites. This will continue for one more cycle (up to 150k papers)
When you start with a paper (we call it the seed paper), Inciteful builds a network around the seed paper by finding all of the papers which that papers cites and which cite that paper. The we do it again with all of those papers we found in the first search.
With the sets of papers found it uses various algos to sort and rank "similar papers", "most important papers in the graph" using Adamic/Adar and PageRank respectively. As mentioned you even have some minor ability to change the results using SQL.
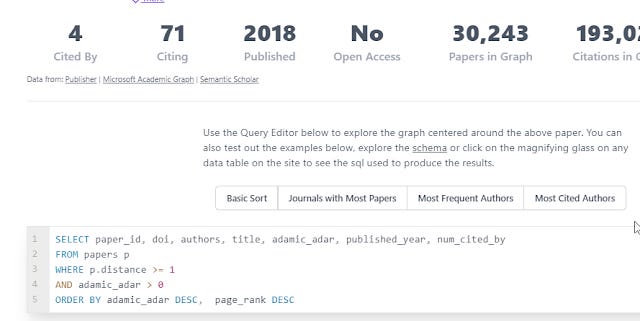
Inciteful SQL editor
I find often that using one paper alone does not give good results, but you can consider to filter the papers found and add them to a super set before redoing the graph. According to the documentation, when you select multiple paper, the system will act as if there is a fake seed paper that cites all the papers you have selected and continue accordingly.
Of course like all the tools like this, InCiteful allows you to export the results to reference managers in bibtex.
Note : There are also other tools like IRIS.ai that I am less familar with that adopt a model where you enter long sentences which it uses to generate promising paper canadiates etc that might be worth looking into.
How good are such tools?
My impression so far is that bibliometric mapping tools are not likely to be useful at first, but might become more useful at the later stage of research, where you wish to see if there are unexpected connections you missed between papers you want to cite.
Tools like Citation Gecko, Connected Papers and InCiteful on the other hand are easier to use and promise to find relevant papers given some relevant ones, usually by generating a similarity graph and have potential to change the way literature review is done.
These tools are still in a very early stage of development (Citation Gecko dates back to only 2018), so it's unclear currently how much advantage one gets by using them versus just doing a lot of keyword searches. As use of these tools improve, I am sure algothrims will get better.
The other major factor that will affect the effectiveness of such tools is the availability of article metadata and particularly citation data. While this is a lower bar than the need for citation statements (which usually implies full text) we still run into issues here.
I have written quite a bit about the state of open citations and many of these tools draw from these open citation sources. Some examples
Connected Papers (Semantic Scholar)
InCiteful (Microsoft Academic Graph)
CoCites (Pubmed)
Citation Gecko (Crossref)
While Microsoft Academic Graph probably has the most complete scope in terms of metadata and open citations, such data is obtained by web scraping with the expected inaccuracies. I am less clear about the Semantic Scholar data (the latest is called S2ORC), but it is likely to be similar.
Probably the cleanest source of citations/references would be from the sets deposited by Publishers themselves in Crossref.
Unfortunately despite the tireless work of I4OC that has increased the number of open citations to 51% by getting most of the big publishers to make their citations open, there are still a couple of major holdouts.
Among the biggest 5 - Sage, Wiley, Springer-Nature and Wiley have pledged to open citations, with one major hold-out Elsevier.
This has created a big gap for tools like Citation Gecko that only use Crossref citations. Essentially any cites that come from Elsevier journals (which by volume are the 2nd or 3rd largest) will not be seen! This is why I tend not to recommend Citation Gecko for this reason at least until yesterday.
However I am happy to say as of yesterday 16th December this reason is no longer true and Elseiver has agreed to make all their citations from their journals that they already deposit into Crossref open!
This is a big deal. As noted even this doesn't solve everything (there is a difference between opening up closed citations in Crossref and making them available in the first place) it's still a big move, when this occurs.
Yep. There's a lot of work to be done to get more of the references into the system, particularly from smaller publishers with limited tech (Crossref doing lots of work on that)
But this is still a big jump, it'll open up around 74% of the references that weren't yet open.— CⓐmeronNeylon (@CameronNeylon) December 16, 2020
Conclusion
This ends my lengthy piece on the latest emerging research tools and techniques for literature review. Not all of them will be useful in all cases and many will require a lot of experimentation to see what scenarios they work best.
As time progresses more and more tools are starting emerge. For example Summarization technology is starting to emerge, from tools like Scholarcy and Paper Digest that can summarise papers (and possibly write) with key findings to Semantic Scholar TLDR feature that summarises papers as a single sentence!
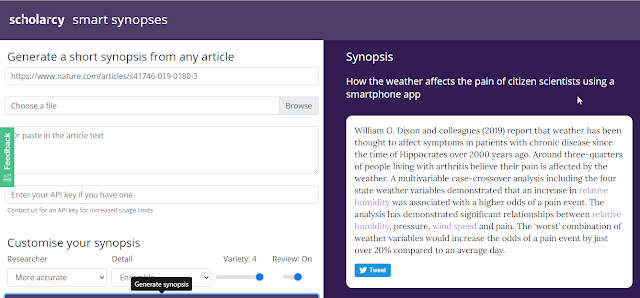
Scholarcy synopsis - "review mode" summarises paper