


On Microsoft academic, predatory journals, algorithmic fairness and Machine learning learning resources

It's not big secret that Machine learning and AI is an increasingly important topic to study. But I was again reminded of this again when I recently attended a talk on Microsoft Academic , entitled "What Can We Expect from Machine Cognition "
at Microsoft talk... pic.twitter.com/9aRtVpX704
— Aaron Tay (@aarontay) October 30, 2018
The talk began simply enough, recapping some of the latest triumphs by AI in conquering games like Go and Video games like DOTA, Pacman. The speaker then went into a introduction of the new version of Microsoft Academic currently in preview (see my blog post about it here)
While the features introduced by the speaker were not new to me, it was interesting to hear how Microsoft viewed Microsoft Academic. One point made was that it was not meant to be used the way you used Google Scholar or even Bing as it was a semantic search.
How does it work? At the risk of misleading people, here's my understanding.
Like Google Scholar, Microsoft uses bots to crawl papers, extracts entities including authors, institutions, journals, topics (field of study) and relationships by used advanced techniques like NLP (Natural language processing e.g. word2vec), generating knowledge graphs for "inference and learning" and does ranking using eigenvector centrality (sounds similar to the Eigenfactor which takes into account cites based on how prestigious the citing articles are) with results that feedbacks by reinforcement learning
thought academic papers are clean but Microsoft found predatory papers. Train machines to understand which ones are, "like a credit bureau" using citation behavior pic.twitter.com/iMRuawfGeG
— Aaron Tay (@aarontay) October 30, 2018
The talk was interesting in many ways. For instance on a question about how much "better" Microsoft Academic was compared to Web of Science, the speaker started asking what "better" meant and went on to say that it is used in Microsoft Research to evaluate the work of their staff (presumably by citation counts). It was also mentioned that the rankings in Microsoft Academic line up well with what experts consider the top papers in their field.
As the World champion beating Alphago was brought up a lot, someone queried on whether Microsoft Academic was comparable to it. The answer was perhaps. In the validation test with experts, expert often found that Microsoft Academic found papers that they forgot to list in their top classic papers. The implication here is I guess that Microsoft Academic was as good if not better than expert humans in selecting top papers in their field.
Microsoft Academic graph is Open data - ODC-BY
Another thing that was mentioned at least twice was that the data generated and used by Microsoft Academic - the Microsoft Academic Graph (MAG) is open data and could even by used for commerical purposes. Indeed the data seems to be available under Open Data License: ODC-BY (there are multiple ways to access this, including via Azure resources, APIs and dumps ) and I expect more and more services will start using this.
Notably, Lens.org has intergrated MAG data into their search and earlier this week, they have merged MAG citations with Crossref and Pubmed data (among other improvements). More on this in the next blog post.

Lens release 5.11.0 adds unpaywall intergration, Scholarly citations from MAG, CORE full text for search snippets, COins for Zotero support and more
Potential benefits of machine learning of millions of text
The part I didn't fully grasp was how machine learning as applied to reading and reasoning of content of medical articles could make a big difference.
In the example given during the talk, the system could read all the articles known to Microsoft Academic on diabetes, extract entities corresponding to diseases, symptoms, causes and treatments and more importantly and make inferences about them.
Among other things this I imagine could be helpful for diagnosis tasks (who has the time to read and understand every medical paper on every diseases?), and could be used to see possible connections.
Someone from the audience, opined that what Microsoft Academic does is correlation not causation and the speaker agreed. The potential of AI used this way is to sieve through the millions of papers and narrow down the things worth studying (if there is no correlation, there will be no causation) and added "human jobs are still safe".
Detection of predatory journals - a machine learning problem?
While describing how Microsoft Academic was constructed, the speaker mentioned almost as an aside that they found that there was an issue of predatory journals which he described briefly as like "Fake news".
In typical machine learning fashion, the system was taught to detect them, rather than rely on human curated lists because there were just too many. The same reasoning was used to for classification of article topics (field of study).
When I tweeted this, there was quite a lot of interested on the detection of predatory journals. The author of Lazy Scholar asked me if there was an API for this , no doubt thinking to leverage this for his extension. A couple of librarians including Lisa Hinchliffe were wondering how machine learning could do this and the pitfalls of using machine learning for this.
The speaker didn't go much into this if I recall, but I'm sure one of the factors mentioned was that predatory journals generally aren't cited a lot by the core important journals, so that's one important signal.
It's unclear to me how Microsoft academic detects predatory journals , but if it is based on supervised machine learning technique where the system learning from labelled examples of what is a predatory journal and what isn't, the logical question is where were the labelled cases coming from?
The problem I see here is unlike typical supervised learning tasks like learning to identify digits or picture of cats, deciding which journals are predatory is to some extent subjective.
The now infamous Beall's list calls them "Potential predatory" for legal reasons perhaps, but there is also rarely a time where you can tell for sure a journal does not do proper peer review, so at best you can judge something is potentially predatory.
So all you can do like Beall used to do is to look for suspicious signs, for example some of these lists consider things like the lack of proper spelling, suspicious addresses (PO boxes or addresses that don't match up with where they are claiming to be from) etc.
This makes knowing what labelled examples were used by Microsoft to train the system critical.
To be fair, there is another type of machine learning called reinforcement learning used by Microsoft , I'm not sure how it could detect predatory journals alone, but it's interaction with supervised and unsupervised learning might make my musings overly simplistic.
Learning more about machine learning
As you can see, machine learning & AI is getting into more and more of our domains. Publishers are already considering the impact on their business, the legal profession is as well. Librarians are of course trying to learn as well.
I've been looking recently at some good resources for learning for a while and recently started looking at the ones offered by Google at https://ai.google/
In particular, the education part of the site provides really great courses.
Currently, I'm looking at
Introduction to Machine learning Problem Framing (Probably good for managers)
The core of it is of course Machine learning Crash Course with Tensorflow API and I'm half way through it and I'm in shock at how clear it is. For instance the explaination of gradient descent and reducing loss is the clearest I have read and I've gone through quite a few "gentle introductions...." to it.
You do need a bit of Python but not a lot. It's a fairly short course 15 hours long, uses videos and you code using cloud based Colaboratory platform. If you are unfamilar with Colaboratory it functions as cloud based Jupyer notebook environment , so you can run code using Tensorflow in your browser.
Btw if you haven't heard Tensorflow is Google's open source machine learning tool kit with high level APIs to make machine learning as learn as possible.
The key thing to note if you are unfamiliar with all this , is that it is a snap to do Machine learning using Colaboratory because zero setup is needed, everything is in the cloud and everything is just a browser load away.
The best thing I like about the course is it's interactive "playgrounds" where you can play around with parameters like learning rates to get a feel of how different parameters affect machine learning results. Below is a interactive playgroun showing the impact of learning rate on loss.
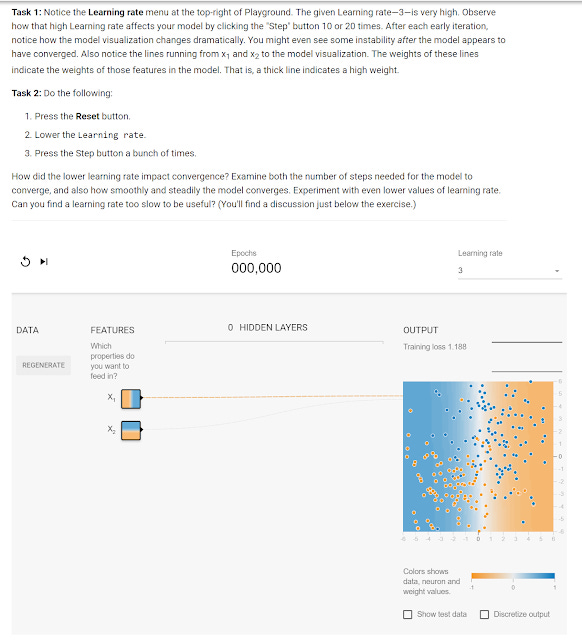
https://developers.google.com/machine-learning/crash-course/reducing-loss/playground-exercise
Information literacy - how do machine learning algothrims work?
Beyond the nuts and bolts of coding, one of the new pushes in Information literacy is to train librarians to be able to understand how algothrims work and their impact on systems. The discussion earlier on how predatory journals is an example of how understanding how supervised learning works can be helpful.
Another area of great interest is the idea of "algorithmic fairness". While looking around I stumbled upon a very interesting tool called a What-if Tool by google for this
As I understand it , it is basically a tool used for sensitivity analysis of machine learning.
It can do basic things like generate confusion matrices and ROC curves (if you are unfamilar with them, think of these as measures for levels of false positive and false negatives). edit data points to see their effects or conversely select a data point and see what needs to be minimally altered for the judgement to change and more.
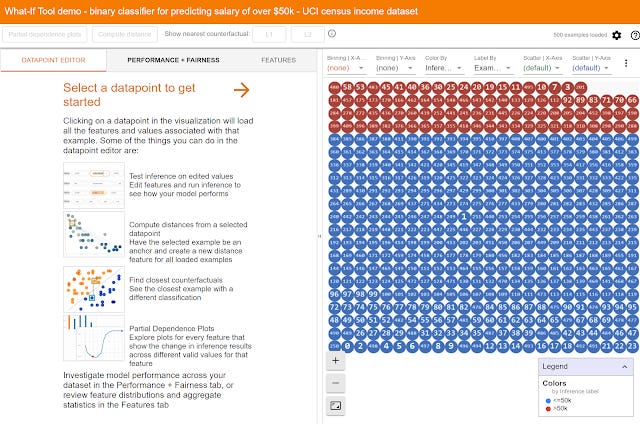
In particular the Test algorithmic fairness constraints feature was quite amazing.
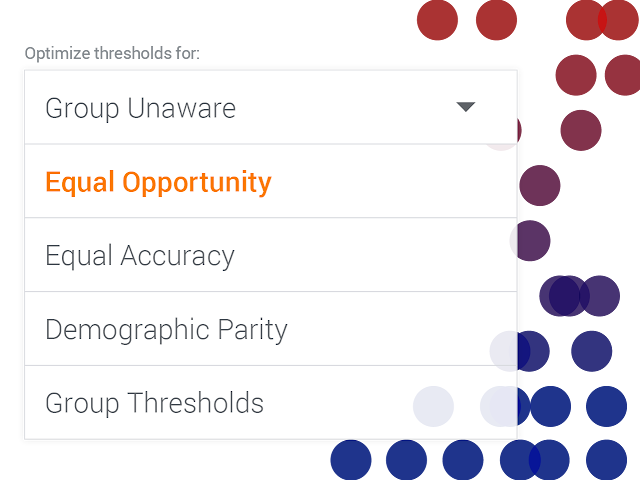
There's a lot of talk about how "fair" algorithms that make decisions are.
For instance what should or should not machine learning algorithms consider when granting loans. Should it be race blind? How should it create cutoffs when distributions of variables are different between say genders? What is fair anyway?
Google talks about different types of fairness and better yet you can use them as criteria for the machine learning to furfill, in the interactive what-if tool.
Of course the drawback is this tool only works if the machine learning was done using Tensorflow, but as a teaching tool on the effects of algothrims this seems to be amazing!
Conclusion
All in all, machine learning & AI is a very interesting field to keep our eyes on. I admit to loving to read about how everything works though I confess to wondering if I will ever have the chops to really use them for work. Still understanding how they work and their limitations is key to future trends for information literacy.