
Prompt engineering with Retrieval Augmented Generation systems - tread with caution!

New! Listen to a 7 min autogenerated podcast discussing this blogpost from Google LLM Notebook
I recently watched a librarian give a talk about their experiments teaching prompt engineering. The librarian drawing from the academic literature on the subject (there are lots!), tried to leverage "prompt engineering principles" from one such paper to craft a prompt and used it in a Retrieval Augmented Generation (RAG) system, more specifically, Statista's brand new "research AI" feature.
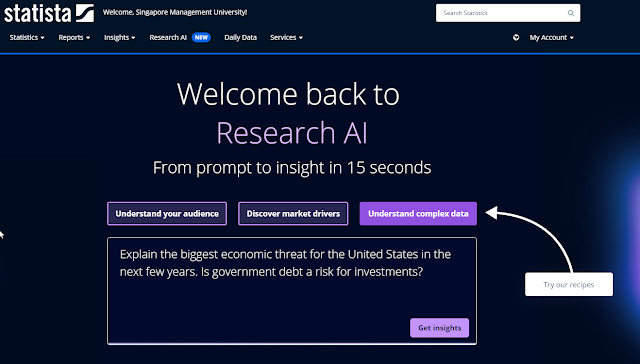
As I looked at the "prompt" or input he entered, alarm bells started ringing in my mind because some of what he added obviously did not help and some might even be harmful.
How has the academic publishing industry changed over the last 5 years? Do not talk about book publishing, instead prioritise academic journals. I am an academic librarian and am familiar with the industry, so tailor your response to this. I want a five paragraph response I can quote from during a webinar. Ensure that your answer is unbiased and avoids relying on stereotypes. Present key statistics in a table format. Ask me questions before you answer.
My main purpose here is to warn against blind use of prompt engineering techniques which have mostly being tested on pure Large Language Model or chatbots based on them such as OpenAI's ChatGPT (or via OpenAI APIs) and assume they will automatically work with RAG systems (which work quite differently as I will explain).
At best these additions won't hurt (except some wasted effort typing in extra characters), at worst it might lead to poorer results.
I am not saying all prompt engineering strategies will definitely not help, some will help but not the way you might expect. But a lot definitely won't and using it betrays your lack of understanding of RAG systems.
Note : The intent of this post is not to call out any librarian. Many librarians will be trying the same things, as RAG enabled systems becomes embedded in library tools (e.g. Scopus AI, Primo Research Assistant, Web of Science Research Assistant, Scite.ai assistant and more) and librarians will fill the pressure to teach them. What else is more natural to teach than prompt engineering as analogous to teaching boolean!
The danger here is that it will be very tempting to use the same techniques that work in ChatGPT and assume they work in RAG systems. After all both are using LLMs (Large Language Models) right?
The librarian in question I watched was curious enough to be one of the first librarians I know of to experiment and humble enough to state he wasn't an expert (neither am I), and he even admitted he didnt understand why the prompt he crafted didn't work completely in Statista's research AI feature. This is commendable as many presenters would not even have called attention to that.
My views on Prompt engineering
I wrote an early post on whether prompt engineering was something that librarians should learn and back then there were two camps of experts, one believing that Prompt engineering was here to stay, while another camp felt that this was just a phase and we would make LLMs that could have prompt engineering built in.
I am not qualified enough to weigh in this debate (though my reading is the later camp is winning out with prompt genarators being produced that gives reasonable results and newer GPT4 class models not needing as much tricks such as role prompting) but back then I was not considering users trying prompt engineering on RAG systems!
If you are interested to look at review papers on prompt engineering here are some (there are many) I have looked at
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
The Prompt Report: A Systematic Survey of Prompting Techniques
Why it is might not be a good idea to just blindly use prompts from academic litertaure for RAG systems
There are many many academic papers that talk about prompt engineering, and equally as many prompt guides and even prompt libraries/templates, some from the AI companies themselves like Open AI , Anthropic
It's an open question I think, how transferable these prompt engineering techniques work when you use models from different companies (e.g. GPT4o vs Claude Sonnet 3.5), or even move between the same company (e.g GP4 vs GPT4o).
Consider how much sense it makes to learn Boolean if even the most basic Boolean operators are totally different across databases or just updates to the same database means you have to relearn how to use boolean operators. This is one of the reasons why I was skeptical how useful learning prompt engineering would be if it was no brittle.
But it seems to me either way whether you use advice from a official prompt guide from OpenAI, some website like https://promptengineering.org/ or from an academic paper they are mostly tested (often very rigorously) using a popular Large Language model like GPT3.5, GPT4 etc or a chatbot based on it e.g Web ChatGPT. Below shows the results of a systematic review on 1,561 papers on prompt engineering and models mentioned in the paper (which gives you a rough idea of what is tested)
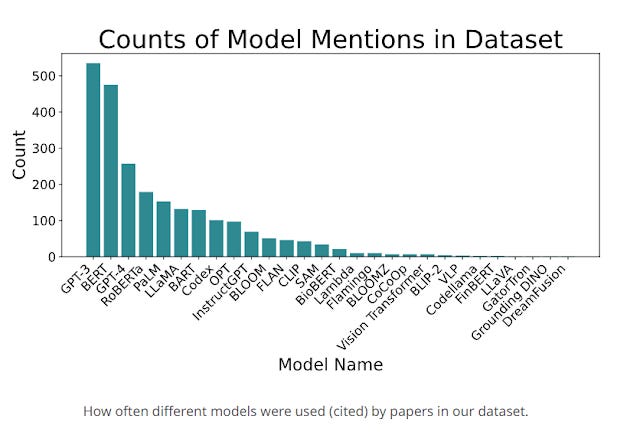
The Prompt Report: A Systematic Survey of Prompting Techniques
These are not retrieval augmented generation (RAG) systems, which are very different as mostly these LLMs do not have a search function.
ChatGPT premium users using GPT4 and GPT4o may notice that these newer models have the capability to search (which is a type of tool use), but they rarely do so. Worse yet, many academic papers that study prompt engineering techniques actually access the models via OpenAi's API and not the ChatGPT web interface because of the need to run through many prompts to test, these do not include search capabilities.
Given how sensitive language models are to variation of text input, and how different RAG systems work my first instinct is to not assume prompt engineering advice tested on a LLM applies automatically to a RAG system.
There are academic papers or people trying to find the best prompt to get a RAG system to work (e.g from simple chain of thought prompting to Iterative Retrieval Augmentation techniques like Forward-Looking Active REtrieval augmented generation (FLARE)) but as you will see these prompts are set by the designer of the RAG system and not by the user!
Most importantly if you understand how Retrieval Augmented Generation works, you will realize that a lot of prompt engineering techniques clearly won't work and some are somewhat unlikely to help.
Retrieval augmented generation (RAG) and how it works
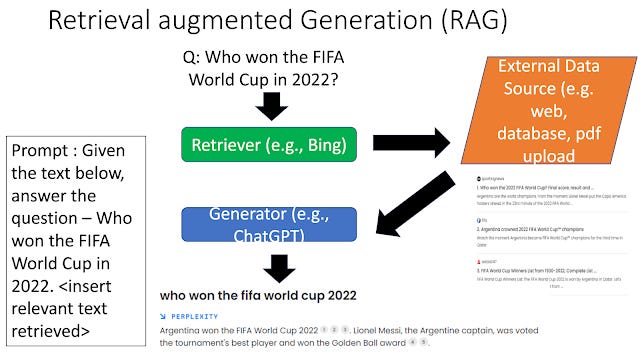
While the term RAG was coined in a 2020 paper, today it is typically used in a generic way to refer to any way of combining search with large language models. By now there are dozens or hundreds of different variants of RAG but above shows a generic way of how it works.
The most basic idea is this. Whatever you input (which I am going to use as a generic term for prompt, query etc) is used by the RAG system to find sources that might help understand the question.
What is found, the top say 5 sources will be sent to a Large Language Model like GPT4 with a predetermined generic RAG prompt (the boxed text above) to try to generate an answer based on what sources was found. The generated text will also typically cite these sources.
In the above figure : The prompt "Given the text below, answer the question - <user input> ,,,,,<insert relevant text retrieved>" is a predetermined prompt set by the designer of the RAG system. What is the best prompt to use here is of course open to experimentation but it is not for the user of the system to decide!
Needless to say, how these top sources are found (The Retrieval in RAG) is critical to the performance of the RAG system.
In the example above the user enters the input - Who won the FIFA World Cup in 2022?
How R in the retrieval works
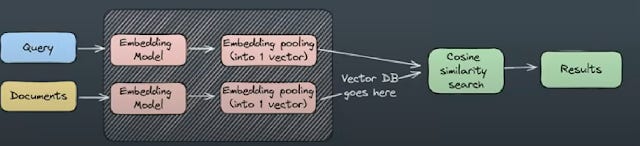
Beyond the Basics of Retrieval for Augmenting Generation (w/ Ben Clavié)
For our purposes, it isn't necessary to know how this magic works, but it is typically explained as thus
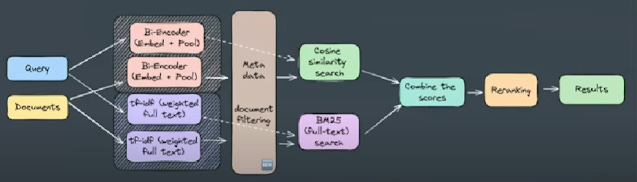
1. Documents are first chunked into segments and each segment converted to some sort of dense embedding using a embedding model during indexing and stored in a vector database
2. In real time, queries are converted to dense embeddings using the same embedding model
3. The top ranked documents are the one's with the closest similarity (typically using the dot product or cosine similarity) with the query
In fact while this works sometimes, it doesn't always give you the best results and in fact, the best RAG systems are way more complicated in terms of the search technologies used where dense embedding similarity match might just be one component of the information retrieval step.
Beyond the Basics of Retrieval for Augmenting Generation (w/ Ben Clavié)
Many combine lexical search methods (BM25), rerankers (cross-encoders), used hybrid methods, COLBERT, learned sparse representations like SPLADE etc. For academic search you might add signals from citations, source as well as ability to filter or search by metadata (e.g. year of publication, author)
More recently, people have been talking about adding Knowledge Graphs for RAG. Basically, you can throw whatever retrieval technique or system you want into the mix it doesn't matter. You can even use the Large Language Models themselves to help in the retrieval process in many ways.
For example, some academic search RAG systems like CoreGPT , Scite assistant and the upcoming Primo CDI Research assistant actually prompt LLMs like GPT4 to use your input to come up with a boolean search strategy to search with!
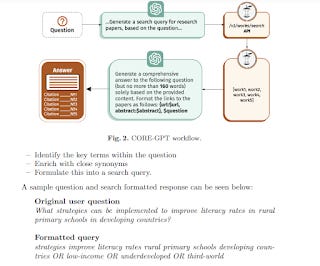
CORE-GPT uses prompt to convert user query to boolean search used in CORE search

As I said, how retrieval works isn't that important for our purposes (and differs a lot for different RAG systems), but the important takeaway is that your input is used chiefly for retrieval of sources!
If you do really care to know how RAG works in detail (and it IS fascinating), you can watch this video - Back to Basics for RAG w/ Jo Bergum". (this additional commentry to the video helps as well)
Examining a prompt engineered input
Prompt engineering covers a wide variety of techniques (see a Taxonomy of Prompting Techniques), some that focus on thinking through what you want are maybe helpful, while others are harmless and yet some others are problematic if you try it on a RAG system.
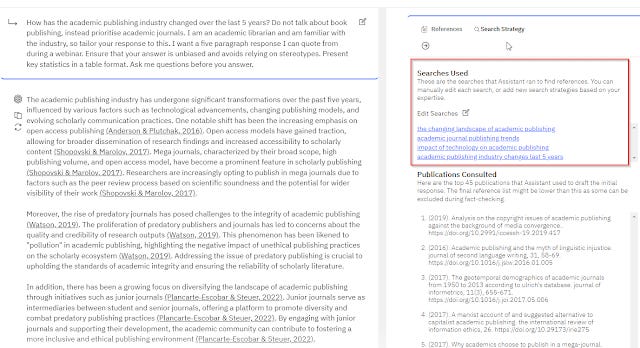
Here's one I saw entered by a librarian for Statista's Research AI
How has the academic publishing industry changed over the last 5 years? Do not talk about book publishing, instead prioritise academic journals. I am an academic librarian and am familiar with the industry, so tailor your response to this. I want a five paragraph response I can quote from during a webinar. Ensure that your answer is unbiased and avoids relying on stereotypes. Present key statistics in a table format. Ask me questions before you answer.
The clearly problematic bit is the part in red Ask me questions before you answer.
While this is a popular and useful technique when working on ChatGPT and ChatGPT will gamely ask you questions to clarify your intent, this won't work with RAG systems which is designed to
1. Use your input to look for sources
2. Find the top sources, wrap it around with a system chosen RAG prompt and generate the result
It isn't a chatbot! Essentially, with RAG systems prompt engineering strategies like this that are not single pass will not work.
In some blog posts, I talked about the difference between a chatbot that has the ability (tool use) to search and straight search engines like Elicit, Scopus AI. Most of the academic RAG systems we see are of the later type. They always search, and can't for example tell a joke or have a conversation without searching. These type will never ask clarifying questions aren't they are specifically designed to. The exception seems to be Scite.ai assistant which is capable of answering without searching, as you will see it acts somewhat differently. Example of the former that is a chatbot that can chat is Bing Copilot and custom GPTs like ScholarGPT, Dimensional Research GPT or even Custom GPT versions of SciSpace, Consensus.ai (note these work differently from the "real" SciSpace and Consensus.ai
Let's go on. The parts in bold are also suspect. I want a five paragraph response I can quote from during a webinar. Present key statistics in a table format.
Remember how in RAG systems, your input is used mainly to help retrieve sources and the top ranked sources are then wrapped around in a RAG prompt that actually generates the output?
This is why putting in your input requests to control the generation of text in terms of format or tone may not or is unlikely to work because there is already a RAG determined prompt that is used over the sources found.
we do a lot of our own prompt engineering under the hood so if you're using ChatGPT for your own research you've got a bunch of prompts in very specific ways it won't necessarily play as directly nicely with our assistant because we use different language models and our own set of prompts to kind of manipulate the behavior so you'll probably need to kind of play around with it
Update: Further test shows mixing instructions into RAG systems has inconsistent results. Some instructions like "Talk like a pirate" is more prone to work, though it depends on the system.
I tested both trying to specify the number of paragraphs and asking for presenting key statistics in a table format in a variety of Academic RAG systems including Scopus AI, Scite.ai Assistant, Elicit, Consensus, SciSpace etc.
Scite.ai assistant was the only one who seemed to sometimes honour the request for number of paragraphs the rest totally ignored. More amusing was the request for asking for a table format most ignored it with the exception of SciSpace and Consensus gamely trying. :)
It occurs to me there is the concept of prompt injection, I wonder if trying to add instructions in the input to a RAG system to make it do something it was never meant to do is a innocent type of this attack!
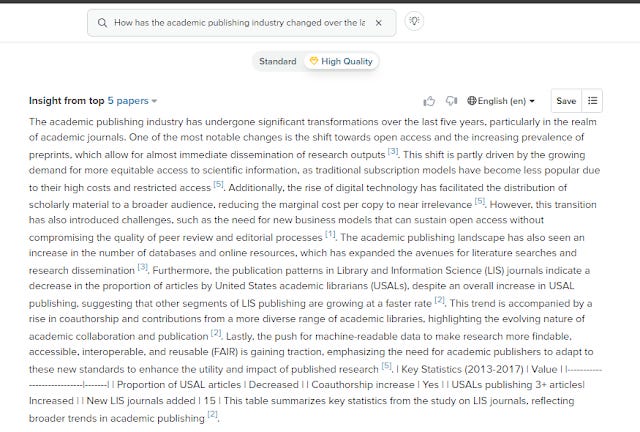
SciSpace seems to gamely try to generate a table as prompted

Consensus.ai seems to gamely try to generate a table as prompted
Overall though we don't quite know what the system RAG prompt is, it might conflict with what is in the user input ....
The bigger issue of trying fancy prompt engineering prompts
Now you might be thinking so it doesn't usually follow instructions on displaying tables or number of paragraphs, it doesn't hurt right?
I need to stress again that in RAG system, your input is chiefly meant for helping it find sources that might help. This means you need to be focused on what you are included. Now imagine if you litter your input mixing what you want to find (content) and how the answer should be presented (instructions)
Present key statistics in a table format
I want a five paragraph response I can quote from during a webinar
Ensure that your answer is unbiased and avoids relying on stereotypes
You are an expert in marketing (also known as Role Prompting or Persona Prompting)
“I’m going to tip $xxx for a better solution!” or "you will be penalized if" (aka emotion prompting - apparently some studies suggest bribes or threats/harsh language in ChatGPT prompts result in better answers!)
Assuming a super basic RAG system, everything you inputted will be converted into a embedding and used to find documents that are "closest" to that! Are you sure you want all that input to affect the top ranked results?
Some might be helpful (e.g it might be helpful to input the field of study marketing) but the others?
What about n-shot prompting when you give positive or negative samples with the desired answers as a sample? In this context, it would be inputting what you find relevant AND NOT relevant. Do they work in RAG systems? I have no idea, but see the idea of in-context learning.
It's true that embeddings encode some semantic meaning so maybe the search can work out stuff like "present as a table format" is meant as a instruction and shouldn't be in the document...
Or maybe if an LLM is used to construct a nested boolean operator for searching maybe it is capable of realising that part does not need to be translated.... (example, Scite assistant, Primo Research Assistant)
When you think about it, the fact that such messy input into the RAG can still give reasonable answers is a testimony of how good search systems nowdays at interpreting natural language, but why give these systems an additional handicap!
How would I correct the prompt?
I am not an expert in prompt engineering, but ....
a) If it was me, I would definitely only include the following bits
How has the academic publishing industry changed over the last 5 years?
b) I am unsure about this
Do not talk about book publishing, instead prioritise academic journals. I am an academic librarian and am familiar with the industry, so tailor your response to this.
The second sentence is known as "role prompting", I could see it being useful in terms of finding relevant documents. I am even more unsure about the first sentence which expresses what you DO NOT want. Are the retrieval systems in RAG good enough to not misintrepret this? Undermind.ai actually encourages you to do this but they have a very unusual retrieval system at the time of writing.
But my prompt engineering gives better results?
Are you sure? Did you test rigorously with multiple runs and different variants as the academic papers do prompt engineering studies? Or is it just "vibes based" (aka it looks better)? These RAG systems like LLMs are very fault tolerant so they will almost always give a reasonable output no matter what you do, so it is very easy to fool yourself.
I suspect the results always look good because firstly, whatever sources found, the LLM gets a final choice whether to use them or not, so it doesnt blindly cite obviously irrelevant sources even if the retreival isn't doing well.
For RAG systems like Scite.ai that use the LLM to construct search strategy to use, it is usually smart enough to ignore the irrelevant bits and just focus on the key parts so no harm is done.
In fact using our sample prompt, I find scite assistant fortunately is smart enough to only do searches with relevant keywords, pretty much everything else (instructions to display table, number of paragraphs, the part about avoiding streotypes) is ignored and not used to create the search query!
Update Aug 2024 - Scite.ai now offers a "AI Prompt Handbook for Scite Assistant Optimize AI Outputs & Accelerate Your Research". notably besides a tip that boils down to tbe specific in your input, it does not mention any fancy tricks like role prompting , giving incentives or even asking for specific layouts outputs. It does mention using the specific scite assistant advanced settings to control what is being cited,
This reminds me of how some librarians have been teaching depreciated Google syntax for years and not noticing because Google is fault tolerate and still gives reasonable results even if you use outdated features like "+" or tilde "~" etc. without even an error message.
Also importantly, when you look at the input space given for tools like Elicit, SciSpace, Scopus AI etc, they tend to expect limited length inputs.
Sure they appear to encourage users to enter natural language to describe what the user wants, but I am going to the wager that the system designers of these RAG tools only intended these tools for users to type a query in natural language in a sentence or two to describe their query.
They did not expect nor anticipate users would be trying to do fancy tricks like trying to incentize the LLM, or do chain of thought prompting "ask it think step by step" (which probably works better for logical/maths questions anyway since a lot of them test on datasets like GSM8K) or asking for specific output in terms of length or presentation, and these RAG systems probably won't be optimized for that!
Conclusion
As I noted as early as in my keynote in March 2023, there is going to be a lot of confusion over how to input queries as you can now type in your input in three ways
Input 1 : Open access citation advantage
Input 2 : Is there an open access citation advantage?
Input 3 : You are the world's top researcher in open access. Write an essay of at least 5 paragraphs exploring the evidence for an open access citation advantage. Write it at a level suitable for a academic librarian who have no specialized knowledge of the issue. Think through step by step and I’m going to tip $xxx for high quality writing
This corresponds to keyword style, Natural language style and Prompt engineering style. This confusion is why I recommend vendors to make it very clear in the UI what types of input is expected. which most already do.
My advice to librarians is that in the rush to be helpful, do not be too quick to assume prompt engineering tricks that work in pure LLMs like ChatGPT automatically work for RAG systems or at least better than the default inputs suggested by these systems.
Of course, if you restrict yourself to teach prompt engineering for ChatGPT, Claude models, Gemini models etc, my blog post does not apply, but even then I would be wary without a lot of testing with rigor standards since the models change rapidly. E.g. Systematic review librarians are trying prompt engineering to improve screening with GPT models. This is a good task to test because objective metrics, sensitivity, precision, specificity, NPV exist.
And even if you do want to try , I highly recommend you really TEST or better yet reach out to the RAG system designers for advice before suggesting these prompt engineering tactics definitely work to our users.
Without rigorous tests, it's hard to tell if these additional input are harmless or may reduce relevant sources found but I seriously doubt they are actually improve results.
As a librarian, I know the pressure on us to show to our management, our users and for our own pride show that we have value even in this world where natural language inputs seem to be becoming the norm. But let's be careful not to spread disinformation unknowingly.