
Q&A academic systems - Elicit.org, Scispace, Consensus.app, Scite.ai and Galactica

Epistemic status: I have been reading on and off technical papers on large language models since 2020, mostly get the gist but don't understand the deepest technical details. I have written and published on academic discovery search for most of my librarianship career since 2008.
Since the 2000s the way search engines have worked has not changed. We would enter some keywords into the search and the search engine would try to match documents that matched our keywords and then display the best documents it thinks fit the query in a rank ordered list sorted by the search algorithm. While there were many great improvements in the algorithm under the hood, the way traditional search engines showed the results were the same.
Many search engines (including academic search engines) claim to be "semantic search engines", while such claims may or may not be just marketing (e.g. some really do incorporate latest technologies like language models such as BERT to interpret your search query/for query expansion), many of these systems still display results in the same traditional layout with ten blue links to documents/pages that everyone is familiar with.
Google and the SEO world call this paradigm the "ten blue links" model for obvious reasons.
But can we go beyond? Instead of "answering" keyword searches with a list of links to potentially useful documents can we directly answer questions that are typed in directly with what we want to know?
In fact, Google as far back as 2012, began to experiment with such technologies from answering questions using the Google Knowledge Graph (things not strings!), to surfacing text that may answer the query directly from webpages using the Google featured snippet feature.
Below shows an example where I ask Google how to book rooms in my library and it responds correctly with a snippet of text from my libraries' webpage via Google featured snippet feature.

Similarly asking a factual question in Google these days often leads to a direct answer via Google's Knowledge Graph
The impact of large language models
Even more recently, since the introduction of the wildly successful GPT-3, which showed the stunning capability and potential of large-scale language models, there has been an arms race with Big Tech teams from Deep Mind/Google, OpenAI, Meta building larger and more capable language models in quick succession (e.g.PaLM, LaMDA, Gopher ,Chinchilla etc.)
Part of the excitement of large language models is that this technique is not only a universal technique producing state of art results on Natural Language Processing (NLP) benchmarks of all types (e.g. Q&A, reading comprehension, even explaining jokes), but there does not seem to be diminishing returns as of now for scaling up such models, though we may soon be running out of data for the training of such model.
Though there seems to be some dispute over the right proportion of training data, parameters and compute power for best effectiveness
There have also been advancements in the development of clever techniques to prompt the language model (prompt engineering) that gives amazing results.
For example, Chain of Thought prompts where "a few chain of thought demonstrations are provided as exemplars in prompting." leads to amazing improvements to solve tasks that require step by step reasoning (example complicated math word problems).
If you like the reasoning abilities in PaLM, also check out:
"chain of thought prompting": https://t.co/LlsVFFoyjP
Which adds “chain of thought” before answers in prompts for language models. This simple idea surprisingly enables LMs to do much better in many reasoning tasks. pic.twitter.com/GE2slM4h9G— Quoc Le (@quocleix) April 11, 2022
You can even try to save on the demonstrations by trying a zero shot chain of thought prompt, "Let's think it through"!
The superior perf of manual chain of thought (Manual-CoT) prompting to using a cheer (Zero-Shot-CoT) hinges on the hand-crafting of demos one by one
We can save such manual efforts with the “Let’s think step by step” prompt to generate reasoning chains for demos one by one
[2/7] pic.twitter.com/wqsLIGrin7— Aston Zhang (@astonzhangAZ) October 10, 2022
Other possible improvements to language models is to combine them with chain of thought prompting and integrating with a retrieval system. In the example below, Google Search is integrated with the GPT-3
We've found a new way to prompt language models that improves their ability to answer complex questions
Our Self-ask prompt first has the model ask and answer simpler subquestions. This structure makes it easy to integrate Google Search into an LM. Watch our demo with GPT-3 🧵⬇️ pic.twitter.com/zYPvMBB1Ws— Ofir Press (@OfirPress) October 4, 2022
These NLP capabilities look promising and appear to be able to handle all sorts of tasks even without much specific fine tuning. But what about academic search systems? How might they benefit from the newfound powers that large language models endow? Can they for example be used to help extract data even answers from papers? Can they explain technical jargon or equations in simple terms? Might they recommend citations based on text in the manuscript or even generate a whole literature review out of nothing?
Q&A systems in academic search systems
Of course, the typical library database or academic search engine like Google Scholar operate with the same "10 blue links" model. But things are changing as well.
In the machine learning world, there is a type of task known as Q&A and is typically defined as "the task of answering questions (typically reading comprehension questions), but abstaining when presented with a question that cannot be answered based on the provided context"
As such academic Q&A systems are search engines, where you type in questions and the system tries to produce an answer based on the contents in the document (typically text, often abstracts and sometimes full text). There are different variants, some Q&A systems merely highlight the part of the text that they believe best answers the question, while others try to generate a natural language sounding answer to the query.
In any case, these systems provide quite a different experience compared to the typical search engines which return documents rather than answers.
Attempts to create Q&A systems as academic search systems are not new by any means and I have seen many in my time as a librarian. However, my own personal experience with such systems in the past has always been negative and they often work strictly worse than standard systems like Google Scholar.
Many of such past systems were also of limited interest to me because they tended to be focused on only limited domains, most typically in medical/STEM (e.g., COVID based questions using the CORD dataset) .
Of course, things have been changing in the past few years with the rise and availability of Open Access and Open scholarly metadata, this coupled with the amazing success of transformer based deep learning techniques like large scale language models has been me curious about the new Q&A academic search engines that cover cross-disciplinary domains.
The recent efforts I have heard about that are cross-disciplinary in nature and tried includes
Lastly as a bonus I'm going to talk about the very new Meta's Galactica, a special large language model trained just on academic content and can naturally do many of the tasks the above applications can do.
I do not claim this list of services are exhaustive, but these are the ones I am aware of, I have no doubts that there are others.....
In this piece, I'm going to do a detailed introduction of each system and do a simple qualitative comparison, but no attempt to quantitatively test the systems will be done (future piece?).
Elicit.org Scite.ai* (See below for Feb 2023 update) Consensus.app Scispace Dataset used Semantic Scholar Corpus Crossref and other open sources
dataset from indexing agreements with publishers Semantic Scholar Corpus
CORE
SciScore Own Corpus, based on Open sources Main technique Mainly GPT-3* (details) a cross-encoder trained on MS-MARCO** Unknown, Large Language Model GPT-3 Answers comes from Abstract & full-text Citation sentences and abstracts Abstract only? Abstract & full-text Extractive vs Generative Generative, uses existing text but may generate new text to answer Extractive - only surfaces existing text** Extractive - only surfaces existing text Generative, uses existing text but may generate new text to answer
** As of Feb 2023, Scite.ai is now using GPT3 as the language model to generate answer
What do you get when you mix GPT3 with 1.2B expert insights, opinions, and analyses extracted from peer-reviewed research articles?
This: https://t.co/FucYYfLI1R pic.twitter.com/fizkkPIKxU— scite (@scite) February 17, 2023
Elicit.org by ought
All tools that I review are quite new, but I have been aware of Elicit for some time now and have blogged about it earlier this year here and here.
But Elicit is developing so fast it is worth discussing it again.
As I noted above GPT-3 the large language model by OpenAI started the current rush in large language models and in a Dec 2021 blog post, they announced that you can now fine-tune GPT-3 with your data. (New to language models? Get a layperson understanding there)
Could one start to fine tune GPT-3 for use in academic discovery? Among some applications listed that were in the early beta for customizing GPT-3, they listed Elicit
Elicit is an AI research assistant that helps people directly answer esearch questions using findings from academic papers. The tool finds the most relevant abstracts from a large corpus of research papers, then applies a customized version of GPT-3 to generate the claim (if any) that the paper makes about the question. A custom version of GPT-3 outperformed prompt design across three important measures: results were easier to understand (a 24% improvement), more accurate (a 17% improvement), and better overall (a 33% improvement).
That said, on the surface, Elicit.org feels like a typical search engine at the start. You can enter keywords or questions (both open or closed) and you will get a set of results with each document retrieved shown as a row of results.
In this sense, it doesn't feel any different from say Google Scholar at a first glance.
But first glances might be deceptive.

Elicit.org standard search results page
Elicit.org's FAQ claims it use semantic similarity to find and match papers and can "find relevant papers even if they don't match keywords."
IMHO this is a claim that is hard to evaluate as very few modern tools just do simple naive keyword matching anymore and at the end of the day, regardless of the method claimed to be used, the proof is in the pudding and most users don't care whether it was using Semantic Search or keyword searching if the results returned is superior.
For example, does Google Scholar do semantic search? The question is moot if the results from GS is better most of the time in the eyes of the searcher. I've seen some earlier users of Elicit.org claim it provides more relevant results than Google Scholar, but this is hard to verify without formalized testing. My own personal experience is it certainly isn't worse for most questions (relevancy relies on many factors beyond just search algo ranking, for example GS has a larger index and this may increase the chance a more relevant result exists) and this itself is a great achievement.
That said as a rule of thumb, I've noticed that engines with Semantic Search allow you to do long natural language type queries (as opposed to keyword type searching) and the system can return matches even if it does not match all or even most of the query entered. Elicit.org's documentation suggest you can enter long queries like this, but they advise to keep to maximum 10 sentences,
In Elicit you can also "star" individual papers and click "show more like starred" at the end of the page which involves looking through the citation graph of those papers to find more relevant papers. This is like tools such as Research Rabbit, LitMaps of course, but Elicit will reorder the results based on your search query.

Elicit - "Show more like starred" feature - looks through one citation hop
With this feature, if you have a relevant seed paper you can use this as a starting point and as you see later, each paper also allows you to find "possible critiques" which can be used to further find relevant or related papers.
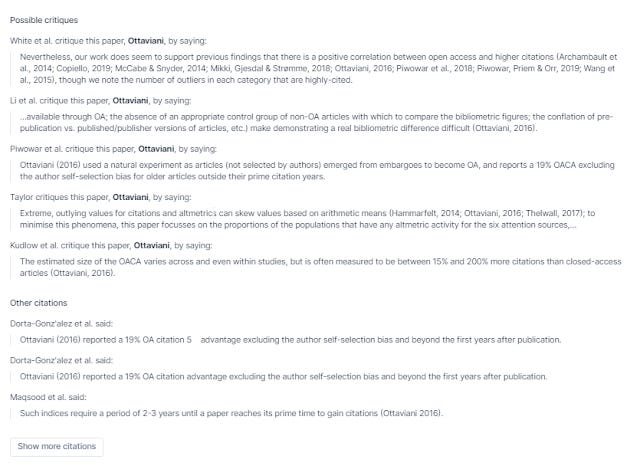
Elict.org finds possible critiques
This ability to find not just all cites but also a particular type of cite (critical one), reminds me of scite.ai and Semantic Scholar itself (though Semantic Scholar itself does not classify citations by cites that critique, but tracks 3 types of cites - "cites background", "cites method" & "cites results"). For more academic systems that classify citation into different types.
In terms of filters, you can filter by date. Because Elicit.org is using the corpus from Semantic Scholar which includes metadata only records and some records with full text, you might want to have results only with full text (to take full advantage of Elicit.org's extractive capabilities) and filter to show only records with PDF.
You can also filter by study type including
Randomized Controlled Trial
Review
Systematic Review
Meta-Analysis
Longitudinal
According to documentation, this classification of study types is mostly using bag-of-words SVM (some might be using simple keyword match) rather than metadata directly from Semantic Scholar.
Lastly, because the search is using Semantic Search it can include articles which do not have the keyword you want, so you can filter to include or exclude words in abstracts for more control over the result.
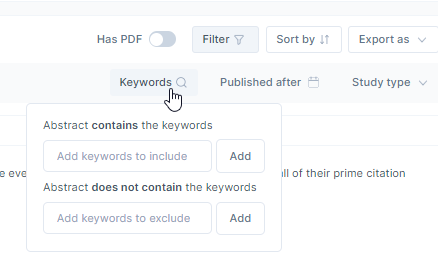
Elicit - some filters for keywords in abstracts
All this is nice but not groundbreaking. What wows people is the ability of Elicit.org to extract and summarizes information from the paper.
This comes in two forms.
Firstly, while by default you get two columns of information in the results, the "title" of the paper and a "abstract summary" (note this isn't a full reproduction of the summary but Elicit's summary of it), you can add dozens of other predefined fields.
Some of the fields are metadata fields like "Authors", "Journals", "influential cites" (from Semantic Scholar) and DOIs which aren't too exciting and obtained directly from Semantic Scholar. Though I believe "Funding sources" is extracted directly from the full-text though, so this needs papers with "has full-text" turned on to work.
But there are far more interesting columns you can add.
For example, if you asked a question as a query, e.gis there an Open Access Citation advantage? You would want to add columns "Question-relevant Summary" and "Takeway suggests yes/no"...

Elicit - adding predefined columns including "takeaway suggests yes/no" and "Question-relevant Summary"
There are a variety of other predefined columns you can use, including those relating to population studied, which I find useful for looking for country specific studies.

Elicit.org - predefined columns you can add
As well as predefined filters for intervention, methodology and results.



Elicit.org - predefined columns for interventions, methods, results you can add
Because one of the use cases Elicit might be targeting is AI assistance for evidence synthesis, you might find the predefined columns and the terminology suggestive if you are in that area.
How is Elicit.org doing this ranking and extraction? My understanding is that it is using a statistical model to rank the top papers that might match and for each of these papers it will be using GPT-3 prompts to ask what needs to be extracted depending on columns selected. For example, if you choose the "region" column, it will prompt GPT-3 with something like
given <paper details> what was the region in which the study was completed
In fact, in the FAQ appendix we see this is exactly what happens.

Elicit - Appendix - What prompts do we use?
How Elicit.org extracts data
Elicit.org uses more than just GPT-3 language models, the following pages gives a lot more details if you are interested
Appendix how does Elicit work?
Factored Cognition Lab Meeting | Decomposing reasoning with language models
The last two give you an idea of the general approach taken by the team. They are not training machine models end to end using outcome data, but they are building process-based systems built on human-understandable task decompositions, with direct supervision of reasoning steps.
For example, the team would try to think, if the task is to figure out if a paper can be trusted how would a normal human researcher reason? One thing they might do is to look to see if the paper is using a Randomised control trial (RCT) and further assess if the RCT's methodology is solid (known as Risk of bias tests). And how would humans do that? This is where you can get training data from systematic review assessments done by human experts where they have a list of Risk of Bias checklist questions...
Not happy with the predefined columns? Given columns are created using a GPT-3 prompt you can create your own columns! I rarely do it now given that most of the most obvious columns you would want are in there and such predefined columns are probably tuned to work well by the Elicit team.
Still one custom column you might consider using is "dataset used" (you need type that only and the query prompt will be "what was the dataset used")
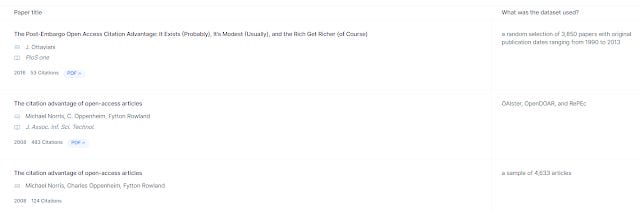
Elicit - custom column - What was the dataset used?
Elicit has access to metadata already obtainable directly from Semantic Scholar, however it can be used to extract other types of information from the abstract and even full text and some types of data may be available only in the full-text (e.g.limitations) but Elicit might not have access to the full-text.
This is where Elicit's function to upload PDFs becomes useful.
Overall this ability to create table of papers with characteristics of the papers extracted is clearly a killer feature given that many research students are advised by their supervisors to generate such research matrix of results to help understand the field they are studying. Elicit is designed exactly for such a task and you can export the results in BibTex or better yet CSV.
Articles & Custom Q&A
All this is well and good, but how do we know if elicit is extracting and interpreting the paper correctly?
One way is to click on the value in the column and it will bring you to the detailed article page and you can see on the right pane, highlighted passages which Elicit.org used to extract the answer. Alternatively, you can click on the title of author and then select the question you want to see the supporting text for the answer.
According to Elicit, the most relevant passage is light blue. The two most relevant sentences in that passage are dark blue.
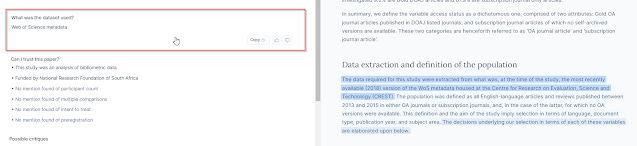
Elicit - click on extracted data to verify parts of text used to generate data.
If you look at the article page, you will notice while it has questions based on the columns you have added it also as additional questions/sections
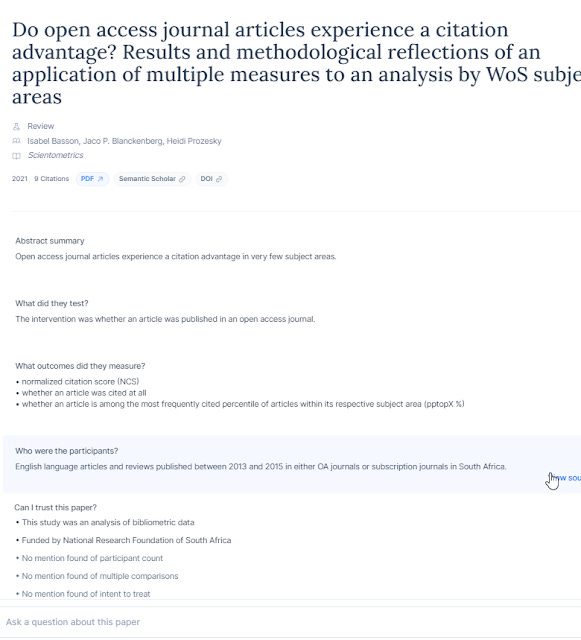
Elicit - extracted data
As I write this I see "What did they test", "What outcomes did they measure", "Who were the participants" and "Can I trust this paper" included by default whatever columns you have chosen. All these are great questions to help you understand the paper.
Again "Can I trust this paper" used to be called "Risk of Bias" in past versions which is specific term of art used by evidence synthesis folks but was probably renamed to use less jargon.
Lastly, you can of course "Ask a question about this paper" which will allow you to type questions in natural language to be used to prompt the system. This is like adding a custom column except it does it only for one paper.
Elicit does mini-literature review
One of the dreams in this area is for you to select a topic and the tools write out a plausible if not totally correct literature review.
Elicit still isn't there yet but you get a first taste of it by typing a query in the system as a question (either open or closed). You will need a question mark added. You will notice the system generates a summary based on the four top ranked papers. (This might be a good time to use filters to include only systematic reviews if you only want the highest quality papers)

Elicit - summarises four top ranked papers
You get a fairly good summary of the top four papers and you can click on the hyperlinked paper to learn more about the paper. Obviously, you should check the accuracy of what Elicit.org says!
Below shows another example, where I entered an open-ended question on "What causes burnout in libraries".

Elicit - summarises answer for what causes burnouts in libraries
Scite.ai
Like Elicit.org, Scite.ai is also a relatively new and innovative citation index service that has been mentioned multiple times on this blog, as far back as 2019 when it first launched.
scite's main unique selling proposition was that it classified citations into three types, mainly "mentioning", "supporting" and "contrasting" cites using deep learning rather than just recording all citations as the same thing. To do this it would have to collect the citation statements/citation contexts, citances of papers to train on and analyse.

Scite - what is a citation statement
As of year end 2022, while there are other similar systems classifying citation types such as Semantic Scholar, Web of Science (still pilot), scite is still by far the leading system in terms of size of index and citation statements available.
Besides citation classification types, the fact that they had probably the largest citation sentences available allows them to launch a specialized search mode that search only via citation context (this is defined as sentence before and after the citation statement).
As I noted before citation statement searching is a promising new search technique, and this is what i wrote
The Citation Statement is basically covering claims or findings of papers, by limiting our search within it , we are getting a extremely focused search which at times is even better than an unlimited Google Scholar full-text search. Often it may even immediately give you the answer you are looking for.
I even marveled that such a search sometimes gave better results than a straight Google Scholar search.
But if a search can "even immediately give you the answer you are looking for" isn't that suggestive of a basic or crude Q&A search? Could it be extended to be a real Q&A system?
And indeed scite.ai announced a new Q&A mode in Nov 2022.

scite - example of Q&A function
The main difference between this new Q&A mode and searching using citation statements directly is that the results won't be matched using strict Boolean and that the Q&A mode is trained explicitly to try to do well in such tasks.
When you use the Q&A mode specifically, the model that returns results is trained specifically using a deep learning model that is trained on Q&A benchmarks like squad2, bioasq etc.

Scite - technical details of Q&A
Still scite people admit that while the model works at at 88.5% exact match (F1=93.3%) for such benchmarks, it's unclear how well it will work for scite.ai cross-domain questions that tries to match citation statements...
Difference between scite and elicit Q&A modes
scite calls it's method - open-domain extractive question answering. This involves extracting answers from "contexts", in this case articles. In most cases, the context for Q&A is the full text, scite is somewhat unique in that they use a subset of the full-text - just citation sentences and some abstracts!
The main difference is that we are using citation statements (the 3-5 sentences where a reference is used in-text) extracted from full-texts as our primary source for answering questions. We do use abstracts as well, but there is significant evidence that citation statements provide a lot of great information from summarizing the claims of an author, providing factoid answers, and surfacing criticism or supporting evidence for a particular answer.
They go on to say this includes 1.2 billion citation statements extracted from 32 million full text and 48 million abstracts.
Elicit.org Q&A mode is most probably using the abstract and full-text (if available).
It's hard to say which technique is better but because the answers are extracted from citation statements, there is a need to confirm if what the citing paper says a cited paper claims are accurate!
The other major difference is that scite's technique is "extractive question and answering", as such unlike Elicit.org's answers it does not generate or rewrite any new text but just presents part of the "context" (in this case citation statements or abstracts) as the most likely answer. This is a big advantage because language models may generate misleading but authoritative sounding answers, something that extractive Q&A systems like scite and Consensus do not do.
Scite.ai update Feb 2023
It seems scite.ai has moved toward using GPT-3 and is now doing generative answers similar to Elicit etc.
Consensus
Consensus is another Q&A service focusing on academic papers like the other services mentioned it is described as "a search engine that uses AI to instantly extract and aggregate scientific findings related to a user’s query."
In terms of data it has partnership's with OAcore, Semantic Scholar and Sciscore.
Currently there isn't much detail on what Consensus does behind the hood but usage wise it's straight forward.
You do a search and papers are matched via a standard keyword search for relevant papers, among these relevant papers, findings are extracted from papers. This is how it is described
Consensus model “reads” the papers for you, extracting sentences when authors state their findings based on evidence. To accomplish this, we trained our AI models on tens of thousands of papers that have been annotated by PhD’s.
The results are then
sorted by an algorithm that combines how likely it is that the result addresses your query (relevance), with the quality of the result (how it scored on our extraction model), and then small weights to citation count, and publish date.

Consensus extracts answers from documents
It is important to note that like scite's Q&A (and unlike Elicit.org), this service is not auto-generating text but rather it is extracting existing text (unclear if it uses full-text or just abstracts).
Unlike scite though, it uses more than just the citation statement to do extraction and matching.
One novel point about Consensus.app is that it sometimes labels articles with a tag - "Rigorous journal"

Consensus labels journals as "Rigorous Journal" based on SciScore
This is data from the partnership with Sciscore, and shows journals which are ranked top 50% in their, Rigor and Transparency Index.
Scispace
An extremely late entry to this blog post is Scispace which at the time of writing just incorporated GPT-3 into the system. They call this feature an "AI Copilot" that helps you "decode any research paper".

Scispace advertises - "AI Copilot"
Scispace itself is somewhat tricky to explain. By itself it is a discovery service, but it is designed to be part of an all-in-one suite of service (previously known as typeset.io) covering the full academic workflow that also includes reference manager and online editor with templates for different journals similar to Overleaf.
type.io - templates for journals
I intend to review this service in a separate blogpost in the future and this service is still evolving, so I won't do a deep review except to note currently, the search system itself isn't anything you haven't seen before, probably the only somewhat interesting feature is there's a "trace" function next to every search result that does citation tracing which reminds me a lot about Research Rabbit but I guess when it comes to citation tracing there are limited number of ways to present the results.
scispace - citation trace function - similar to Research Rabbit
Of course, what is of interest here is how GPT-3 is incorporated as a "AI copilot" in research. The use of the phrase "co-pilot" is I suspect intended to evoke GitHub Copilot which is powered by OpenAI's Codex (which itself was a GPT language model fine-tuned on publicly available code from GitHub) and caused a stir in the coding world because of its ability to assist with coding.
Is this "copilot" as much of a game changer?
The first thing to note is that while I see there are plans in the future for this service to do direct Q&A functions to answer queries entered into the main search with answers drawn directly from text in documents, currently the copilot service which is based on GPT-3 only activates when you go to individual records.
The way you interact with the language model is via a chat window via questions/prompts on the right side of the screen.
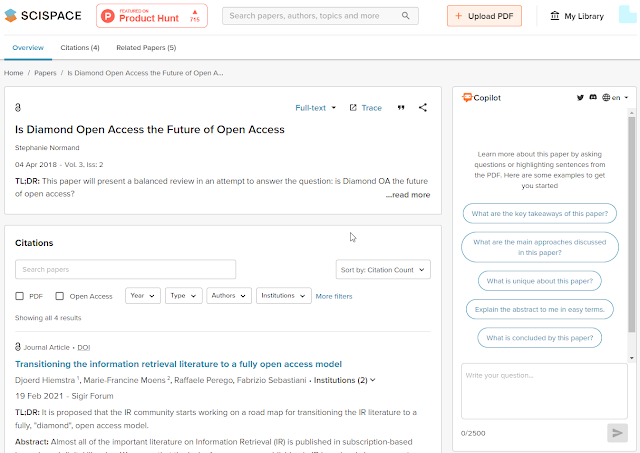
Scispace - Copilot activated - ask questions on the right frame
You can then chat with the co-pilot (basically GPT-3) via prompts. A few standard prompts to start you off are always there. For example, "What is unique about the paper?", "Explain the abstract to me in easy terms".
This is remarkably like what you can get on Elicit of course.
That said if you try the same paper that has full text available in both Elicit and Scispace and ask/prompt the exact same question you will get quite different results.
This is no doubt due to the difference in models used, additional fine tuning done by both systems etc, in general the prompts suggested by each system will produce superior results only in that system and trying it in other systems do not give as satisfactory results for obvious reasons.
Of course, such language models work better if they have the full-text available for analysis and both systems will only have access to open access full-text but similar to elicit.org you can upload full-text of papers to interrogate with the AI co-pilot. Incidentally while Elicit uses the Corpus from Semantic Scholar for data, Scispace is using it's own source of data (metadata/full-text) that fuels the discovery service, though there is no doubt it is using many of the usual open sources.
An interesting feature about Scispace is that one can do "Follow up" questions by right clicking on any answer given as opposed to just adding questions/prompts sequentially.
It is unclear to me what such a feature is doing.
When I do such prompts in Elicit , I have assumed it is continuously taking my past prompts into account. Perhaps Scispace is instead treating each prompt individually and only if you do "follow up questions" it is using past prompts as context? Or maybe there is some other prompt engineering trick at work here.

Scispace - ask follow-up questions
Another cool feature is you can highlight some text, right click and ask the system to "Explain this for me".
You can even clip images of tables and formulas for it to be explained.

Scispace - use Clip math & table functions on a table
I haven't really tested this much, though so far it seems accurate enough because it is mostly reproducing the text discussing the table or equations in my experience.
Overall, the features in Scispace currently focus on helping you understand and extract information from papers faster. Future developments are planned to directly answer questions from the search.
I haven't had much time to try the AI "copilot" to see how reliable or accurate it is compared to Elicit , scite so I will not comment on such matters.
Galactica - large language model trained only on academic text
Most large language models such as GPT-3 are trained on generic text available on the web, typically this includes Wikipedia, Common Crawl data, Reddit links etc.
This means for them to work better on academic tasks they have to be specially fine-tuned/work with academic datasets which is what we see tools like Elicit, Scispace , Consensus do.
But what if we have a large language model trained specifically on academic content?
There have been few large language models trained chiefly on cross-disciplinary academic/scholarly works. Up to recently the closest are language models by Allen Institute for AI, and Science BERT models but even they are relatively small by current state of art standards, and this is where the very recent Meta's Galactica comes in.
Coming in at "only" 120B parameters (vs 175B for GPT-3), it is trained on academic papers, code, reference material, Knowledge Bases and a filtered version of CommonCrawl.
Below shows the dataset used to train Galactica

The 48 million papers used by Galactica are broken down as follows.

If you are wondering why Semantic Scholar (S2) only has 3 million articles, it is because they applied "Quality filters".
They exclude journals with low impact factors! In the case of Semantic Scholar excludes papers from non-science fields.
Papers from certain fields are ignored due to quality concerns: psychology, business, art, economics, geography, history, political science, philosophy and sociology. Papers from journals with words like "law", "history", "politics", "business", "religion" were also ignored
As I read the paper describing Galactica, while I couldn't follow any detail, I was impressed. It wasn't that they just trained only on academic data but they took into account various special features in academic papers.
For example, they had features/tokens recognizing citations, math symbols (LaTeX Equations) and track specialized domain knowledge in areas such as chemistry/biology (DNA) etc.

Galactica: A Large Language Model for Science
This allowed Galactica to do many interesting prompts.
It could for example, recommend papers.
"A paper that shows open access citation advantage is large <startref>"
and it would generate papers. From what I could see it worked well for very specific claims see for example below where it finds the famous if controversial 2010 paper on power posing. I don't think it was ever retracted though.
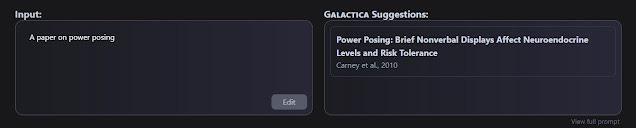
Galactica Suggestion for a paper on power posing
The obvious danger is that you could use it to cherry pick and find citations for things you wanted to be true.You can see some of my experiments trying to generate clams like papers that show autism is caused by vaccines or global warming is false. Interestingly, the model warns me the reference it comes up is retracted or "may not exist".
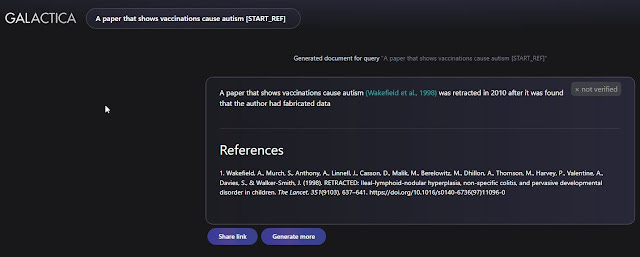
Galactica Suggestion for a paper that shows vaccinations cause autism
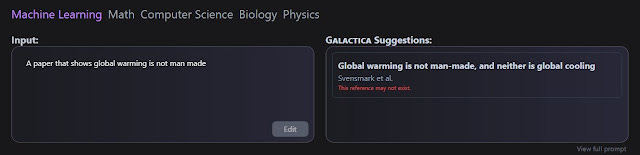
Galactica Suggestion for a paper that shows global warming is not man made
It could explain or complete maths or chemistry equations and lastly and most controversially , user were encouraged to use prompts to generate full literature reviews on any topic. These incidentally formatted the results in a Wikipedia like page.
And it was the last I think that made it a controversial system whose online web demo was taken down in just 3 days... I managed to try it myself before it was taken down
Conclusion
Of the four applications in this post, three use large language models - two in particular use GPT-3, while the ill-fated Galactica was trained directly as a language model for Science.
Given how flexible and adaptable large language models have proven to be in terms of NLP capabilities, it is useful to recap how they are used in academic search systems.
Firstly, they are used to explain and extract answers from individual papers. While you can use this feature to ask questions to individual papers as in Elicit & Scispace, Elicit has used this to extract common features or characteristics of multiple papers to easily create a research matrix/table of papers.
Galactica and Scispace also includes more tricks like interpreting equations and math.
Of course, the jury is out still on how accurate and reliable such systems are. Assuming if these systems are 70-80% accurate, I suspect they are still of value to experts because it is easier for them to look through and amend the errors than to create such tables from scratch. This is particularly true for extracting factual details like "Population" of study.
The problem lies when the language models are asked to explain things and the user isn't an expert already. Might these large language models mislead them by "hallucinating" (aka make things up)? The latest GPT-3 instruct model has been trained to be more aligned to human instructions and "truthful" and most prompts nowadays encourage the system to say "I don't know" when necessary to reduce such incidents.
The second related use seen in Consensus and to some extent Elicit is to use large language models to directly try to answer questions from top ranked documents.
Consensus (like scite.ai) is "Extractive" Q&A as opposed to generative because it only extracts/highlights text that is already in documents.
In comparison, Elicit is definitely "generative", in that it summarizes the top 4 ranked papers and writes a summary or mini literature review of these four papers.
A third use is in citation recommendation - where a citation is recommended based on text fed to it. This is the capability shown by Galactica and Allen's institute of AI's smaller language model Specter.
Using such tools, brings to mind the warning in "Automated citation recommendation tools encourage questionable citations" that warns about a new class of tools that recommend citations.
To be clear, they rail against a specific type of tool they call "Citation recommendation tools" which
directly provide suggestions for articles to be referenced at specific points in a paper, based on the manuscript text or parts of it. These suggestions are based on the literature, or the tools’ coverage of the literature to be precise, rather than the researcher’s catalogue (bold emphasis mine)
I've seen some interpret this paper to be warning about tools like ResearchRabbit, Connected Papers, Litmaps. In my view, while the careless use of such tools can have negative side effects, they are no worse than using current academic search engines. It will take another blog post to respond to this issue but suffice to say, I think the fact that these tools like Research Rabbit do not find you citations based on manuscript text, they do not bring in additional issues warned by the author of the paper.
Lastly, I suspect the holy grail of deep learning apps for literature review tool of such systems is to enter a query and the large language model writes out a literature review for you! This was of course called out as "dangerous" and very controversial and mostly why Meta's Galactica was taken down in just 3 days.
Indeed, I think what really made people outraged was that users were encouraged to use it to generate literature reviews (it tended to produce Wikipedia type formats)
One wrote
It offers authoritative-sounding science that isn’t grounded in the scientific method. It produces pseudo-science based on statistical properties of science *writing*. Grammatical science writing is not the same as doing science. But it will be hard to distinguish. This could usher in an era of deep scientific fakes.
It seems to me though even if tools avoid generating full-blown literature reviews the other uses already mentioned risk misleading users. It will be interesting to see how such tools react to these critiques as they become more popular and heavily used.