
Retrieval Augmented Generation and academic search engines - some suggestions for system builders

As academic search engines and databases incorporate the use of generative AI into their systems, an important concept that all librarian should grasp is that of retrieval augmented generation (RAG).
You see it in use in all sorts of "AI products" today from chatbots like Bing Copilot, to Adobe's Acrobat Ai assistant that allow you to chat with your PDF.
Restricting to just products in academia/library industry, RAG or variants of it is used everywhere from early adopter systems by startups like Elicit.com, Scite.ai, Consensus etc to products by large established companies, like Elsevier (Scopus AI), Clarivate (Web of Science Research Assistant, Proquest Research Assistant, Primo/CDI Research assistant).
Generating a direct answer with citations? RAG. Using it to "chat with PDF" or extract answers? RAG again.
It seems almost every month, we see some new academic search or existing database embrace the use of RAG to generate direct answers with citations. This month it is statista, the business statistics database. I am still trying to keep track of them all, but given how easy it is technically to implement this feature (though not necessarily well), I think we are on track within the next year or so to have such a feature of generating direct answers with RAG becoming almost standard in academic search
Learning about RAG
While the term RAG was coined in a 2020 paper, today it is typically used in a generic way to refer to any way of combining search with large language models. By now there are dozens or hundreds of different variants of RAG but below shows a generic way of how it works.
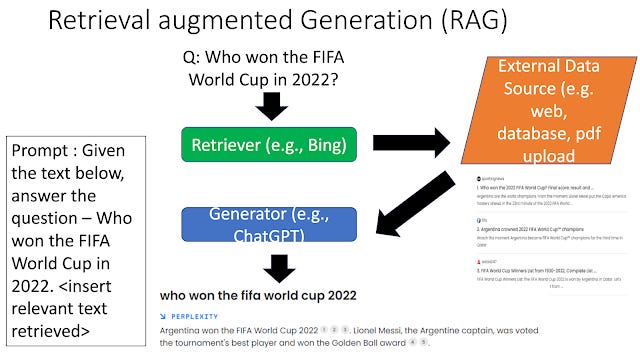
Why has RAG taken the industry by storm? Besides the fact that implementing this technique isn't difficult, RAG is claimed by some to be the solution to "hallucinations" but of course things are not that simple.
You may not have the time to read and keep up with the latest research on RAG but this FAQ provides a pretty good summary of some of the research covering topics like
How often do hallucinations occur?
In what type of situations hallucinations occur
Is RAG really the 100% solution against hallucinations?
What happens when the context fed to the LLM via RAG conflicts with the pretraining data
Of course, this FAQ is by a company trying to sell their own product and so may not be 100% neutral. They advertise their own solution which they call "Safety RAG", which as far as I can tell roughly involves using knowledge graphs as a kind of detector to flag answers that look like hallucinations. I have no idea if this is a 100% solution (or as likely a solution that is relatively "safe" but ends up flagging a ton of answers that reduces the utility of the system).
Suggestions
As someone who has been watching this class of product from even before ChatGPT emerged in Nov 2022 and have spent some effort looking at numerous products that incorporated this feature, here are some of my thoughts and suggestions of what I like to see.
UI suggestions 1- Making it easy to verify citations
By now various search engines and academic databases have tried to implement RAG generated answers in multiple ways.
But I think given how important validation of citations is in RAG generated answers, systems should prioritize making it easier to check citations.
For example, mousing over citations and overlaying the context/text used to support the generated sentence (e.g. Scite assistant),
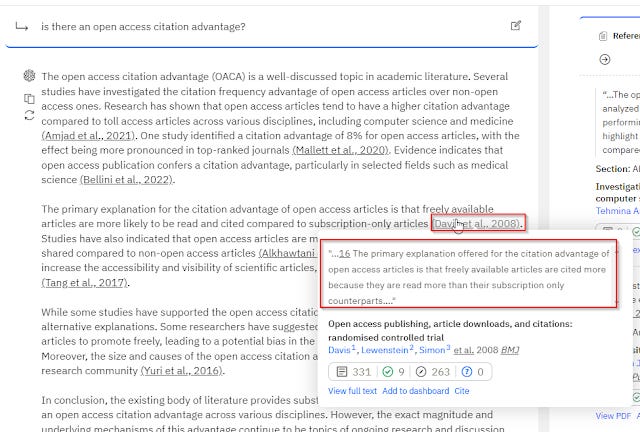
or for validating extracted data (e.g. Elicit.com) making it easier to verify against the source should be a standard feature.
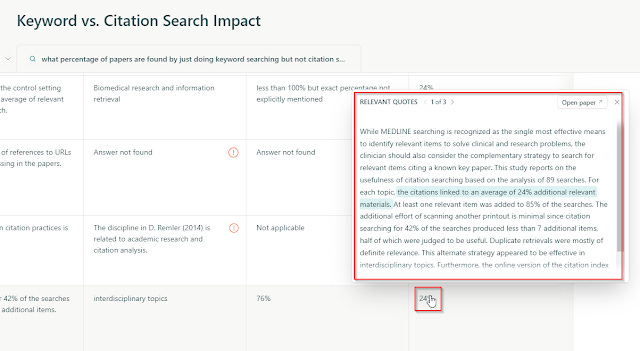
Contrast this to RAG systems that just cite a paper, and you have to try to quickly skim the full paper to check....
Unfortunately, this type of UI design seems to be rare (and getting less common? for example the earliest Bing Chat used to do so but no longer), and I am not sure why, unless systems are using variants of RAG that make it not possible or hard to do (e.g. with larger context windows they are chunking the whole document)?
UI suggestions 2- Transparency - Making it clear what RAG is really searching over
That said, I suspect, most academic systems using RAG systems are mostly drawing only from abstract not full-text, which makes it easier to check. Which brings me to my second suggestion, please state explictly what you are using to do RAG over! Is it just abstract? citation statement/context/full text (if available?).
Knowing that RAG covers only abstract rather than full-text helps with the type of queries users can use.
In fact, most librarians or researchers would probably want as much transparency as possible on what is going on.
Scite.ai assistant does this to a greater degree than most and you can find a 1 hr video that goes fairly in depth on what is going on beneath the hood.

While knowing more detail on Scite assistant helps understand why it is relatively slow at generation (it does additional fact checking of answers which leads to additional calls to the LLM to verify answers/consistency in hopes of improving accuracy), I am not sure telling the end user more detail typically helps. For example, we are told Scopus AI uses "patent-pending RAG fusion" and I even more or less understand what RAG fusion is, it does not help me much in the use of Scopus AI.
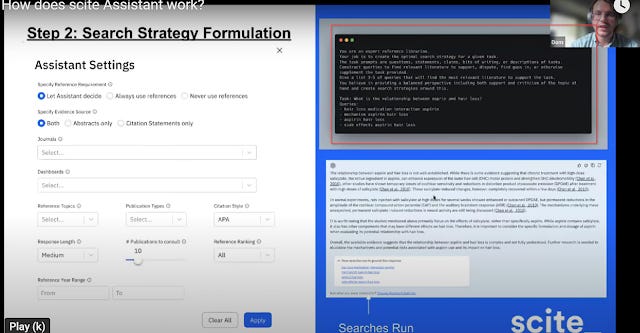
I much prefer features that help with transparency. For example, Scite assistant shows the search strategies used and the initial list of publications consulted before "Fact checking" step removes them.

New! Additional note on searching.
As of 2024, natural language queries are converted to searches in one of the two ways.
Firstly, a Large Language model itself is prompted to created a boolean search query based on the natural query and this is then run by the search as per normal.
Currently, it is known CoreGPT , Scite assistant and the upcoming Primo CDI Research assistant do this. It is likely many other AI tools (possibly Undermind.ai) do this too.
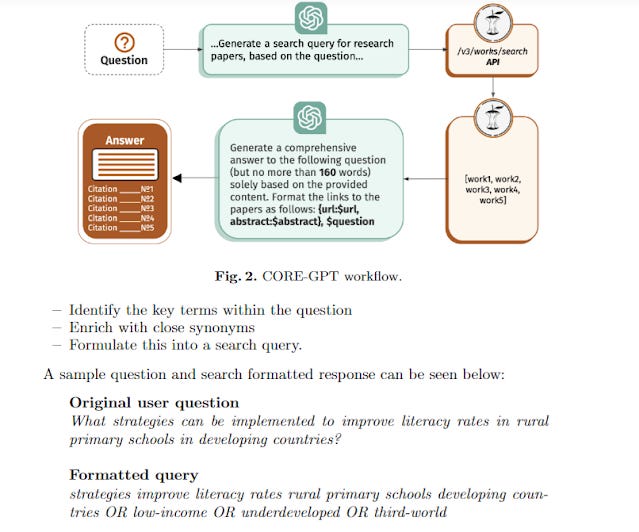
CORE-GPT uses prompt to convert user query to boolean search used in CORE search

The advantage of this method of converting natural language queries to search compared to the next method is that it is relatively cheap to do.
All you need is to prompt a Large Language model with the natural language query and a search string emerges!
Another advantage is that it is more transparent or at least explainable, as you can display what was the search used to retrieval the results. Some like Scite.ai assistant even allow you to edit the search if you are not happy with what it does!
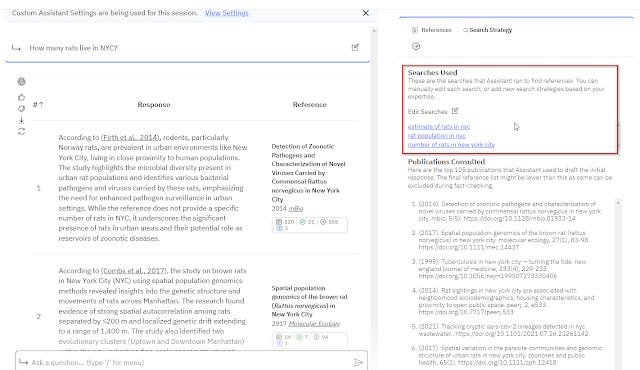
Scite.ai assistant allows you to edit search strategy, notice it uses multiple simple keywords not one complicated boolean search
The chief disadvantage of this method is that I am skeptical off the shelf large language models like GPT4 can actually create good search queries. Particularly if they try to create one off long boolean search queries like what Systematic review librarians do.
Early experiments to test if ChatGPT can create good boolean searches have generally had disappointing results, at best the search strategy produced has decent precision but poor recall.
That said, these were early experiments with off the shelf ChatGPT, perhaps fine-tuning with proper examples, either a GPT model or a BERT model might give better results?
This is particularly so because these papers generally compared with long complicated boolean strategies painstakeningly created, piloted and tested by systematic reviews in the biomedicial field and one of the obvious findings is that OpenAI models generally do not understand MeSH, which seems to be a something fixable by feeding it data on MeSH, or adding some subsystem designed to handle MeSH.
Another argument is that to do relatively well for the purposes of RAG, comparing with high recall, relatively high precision complicated searches created by Systematic review experts is a red herring. As long as the search strategy has decent precison to feed the LLM with appropriate context, all is well.
In any case, my suspicion is that if you want to use LLMs to generate search strategy, it might be better to do what scite assistant does which is to run multiple keyword searches, combine and rerank (though this increases latency and reduces transparency), rather than to use the LLM to create one super complicated boolean search and rely only on that, as that can be brittle.
The second method of converting natural language queries to search which is very popular nowdays is to implement embedding-based search. Typically this involves converting query to embeddings, doing the same for documents presearch and finding the closest documents using some measure of simiarity like cosine similarity (typically implemented with some aproximate nearest neighbour match).
Below shows the very popular Bi-Encoder type models typically used. (Cross-encoders are reserved typically for reranking step because they are more accurate at the cost of being very slow).
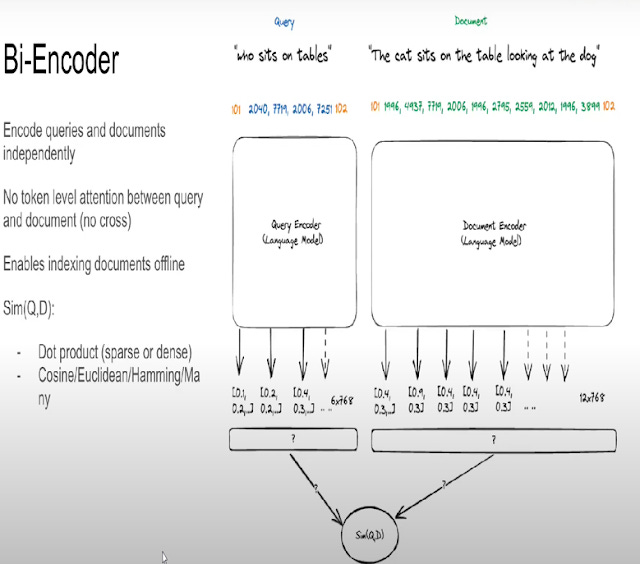
Talk by Jo Kristian Bergum, Vespa
In practice, tools like Elicit, SciSpace probably combine this type of embedding search/semantic search with standard lexical keyword search (typically BM25, a improved version of TF-IDF) followed by reranking (typically with a more accurate but much slower cross-encoder model) to gain the advantages of both methods of search.
See for example, this Code4Lib article studying the impact of adding embedding semantic search to lexical search over austrlian newspapers from the 90s. This paper shows how for some searches lexical search shines over semantic embedding search and vice versa.

https://cameronrwolfe.substack.com/p/the-basics-of-ai-powered-vector-search
Overall I suspect this second method gives better results than just asking a LLM to generate a search query, but it is of course costly to do as you need to pretty much change your search infrastructure! This includes converting all your documents to embedding and then during the search pay the cost of computing the nearest neighbour match, reranking etc.
From the user view, transparency is much less of course, because embedding search at least typically done using bi-encoders are totally not transparent, and all you get is similarity scores...
UI suggestions 3 - Show examples of what type of queries or prompts should be entered
Another good practice which to be fair is done quite frequently is to show users what type of queries should be entered.
This is needed because many users are still conditioned to search using keywords.
This might be overthinking but it might also be useful to show users queries that should NOT be entered. For example, users may try to do long prompt engineering style inputs, and if your tool does not support that it might be a good idea to clarify that as well.
Functionality suggestion 1 - add options to control RAG search
I find users love features that can control what RAG uses. For example, input a list of journals and restriction citations to come from those. Again Scite assistant has the most number of such options...
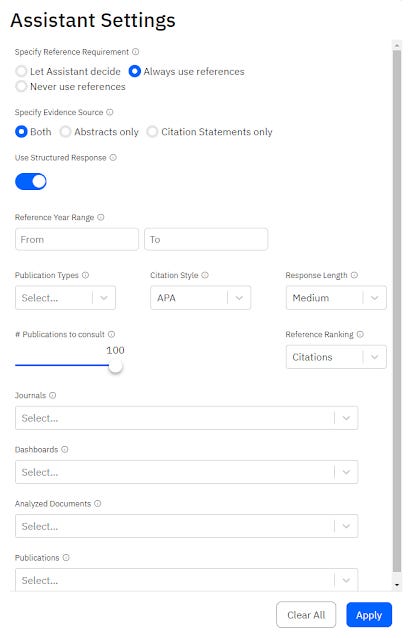
I've heard feedback that some users really appreciate being able to restrict by journals so that all citations come from specific journal titles for example. Similarly being able to point to a set/list of 200 papers say and ensure the citations come from there to answer a question is also very interesting if you benchmarking evaluating say a small department of 200 authors etc.
However, users have to be warned to be careful with over use of such filters, since overuse of them can lead to no valid citations available or worse yet increase hallucinations as the LLM tries to fit the results found to try to answer the query....
Functionality suggestion 2 - Err on the side of saying I don't know/no answer
I understand that it is possible for LLM+RAG systems to "refuse to answer" which safe guards against wrong answers or hallucinations, but users hate it when systems does it a lot. So there is a tradeoff here to make.
For academic search, I think such systems should definitely err on the side of safety and refuse to answer more if it reduces mistakes.
Similarly if there are RAG or otherwise techniques that can improve accuracy but takes a bit more time to process, it should be added or at least be an option, because I think I wouldn't mind waiting a bit longer for higher quality answers.
Functionality suggestion 3 - Search should take into account more than just topic similarity
This pertains more to doing information retrieval using dense retrieval methods (which is a LLM application) , however since RAG systems tend to use the top ranked papers to generate answers this has implications.
The main issue I notice is that RAG enabled systems like Elicit.com, SciSpace etc, often combine
a) A broad inclusive index - typically Semantic Scholar, sometimes OpenAlex, Lens.org etc
b) Relevancy rankings based purely on semantic/topical match
This is a problem, as it often results in results that may be semantically relevant but not necessarily the most highly cited, or from most prestigious journals ranked highly.
This leads to an issue where researchers look at the generated answer, and feel that the answer is bad or odd because it does not cite the obvious important/seminal papers, because the top papers it uses int he answer doesn't take into account such factors as citation counts.
Part of this problem is also because Google Scholar is so dominant as a tool, and we know they weight citations heavily in the rankings, so most people are used to results which rank the most well known and influential papers
Even if the default ranking does not take into account citations, it might be a good item to have a filter or sort ranking that takes that helps with this. For example, SciSpace has a "top tier journal" filter (that filters to results from Q1/Q2 journals using Scimago journal ranking)

Marketing suggestions
To any vendors doing marketing, for the love of god, do not say your product is 100% (or 99%) hallucination free!
I know the standard obvious line is to constrast your commercial RAG enabled product against the free ChatGPT 3.5 and claim that the product produces 100% hallucination free answers.
But leaving aside that OpenAI has now released GPT4o for free users which also does RAG which weakens this argument (though even with GPT4o or GPT4, the model does not always choose to search), it is also extremely misleading because RAG does not solve the hallucnation problem completely.....
Getting asked and called out for that, and retreating to the more defensible position that "hallucinations" here means citing "made up" documents and conceding that even with RAG, generated statements might still not be correctly supported by citations does not help anyone!
I personally find such marketing a bit dishonest.
Conclusion
Search systems with RAG are still in their infancy, a lot more real world testing is needed before we know what is the right design pattern.. What features do you currentlylike or dislike in RAG search systems? What are some features you would like tha are not in such systems?