
Testing AI Academic Search Engines (1): Defining the tools

Introduction
How do you test a tool that promises to revolutionize academic research? With AI-powered search engines popping up everywhere—from startups like Elicit.com to giants like Scopus AI—librarians, researchers, and developers need a reliable way to evaluate them. This post kicks off a series on building a testing framework for academic search engines, starting with a critical first step: defining what an "AI academic search engine" even is. Without a clear definition, comparisons risk being vague or misleading. Here, I’ll break down the crowded landscape of tools, pinpoint what makes an AI academic search engine unique, and lay the groundwork for a practical testing method to come in Part II.
I notice I tend to use academic search tool and academic search engine inter-changably, but technically the later is a subset of the former, but it is the later that I typically focus on.
What are AI academic search engines?
Academic search engines are starting to incorporate "AI" in many ways. A non-exclusive list of features includes
Moving away from just keyword/lexical methods (Boolean/BM25) to "semantic search" methods
Generating direct answers to queries by summarizing or rephrasing content from multiple top retrieved articles with citations to used articles (via Retrieval Augmented Generation or RAG)
Generating TLDR summaries or key points of individual documents
Generating a synthesis matrix/table of studies from multiple documents
Identifying top authors, seminal & review papers, and emerging trends
But how does one test such AI academic search tools? Librarians are starting to test such tools and provide rankings and comparisons (see here and here), and this is encouraging as it is a way to learn and show expertise. But how can we make it better?
My main critique of some early comparisons or rankings is twofold. Firstly, many of these comparisons seem too subjective or "vibe-based." To be fair better comparisons would have at least two librarians rating criteria like "ease of use/interface," "help documents," or "relevancy." While some of the criteria have an inherent amount of subjectivity, some strike me as something that calls out for more formal ways of testing, like "relevancy."
My second critique is much more serious. Look at the following set of tools:
Elicit.com, Scite assistant*, Consensus, Scopus AI, Primo Research Assistant, Perplexity.ai
Connected Papers, ResearchRabbit, Litmaps*, Citation Gecko, Inciteful
Leaving aside whether they are academically focused or not, you can clearly see these are very different types of AI tools in terms of functionality, if not technology, and trying to test or compare all of them will be extremely difficult (despite all of them having some element of "search").
In this blog post, I will try to category the main types of AI tools used to help in discovery and explain why I focus only on one particular type that I consider AI academic search engines.
AI Academic Search Engines
The first group (Elicit.com, Scite assistant*, Consensus, Scopus AI, Primo Research Assistant, Perplexity.ai) is where I have been focusing on for the last 3 years and definitely qualifies as academic search engines. I track a list of such tools here.
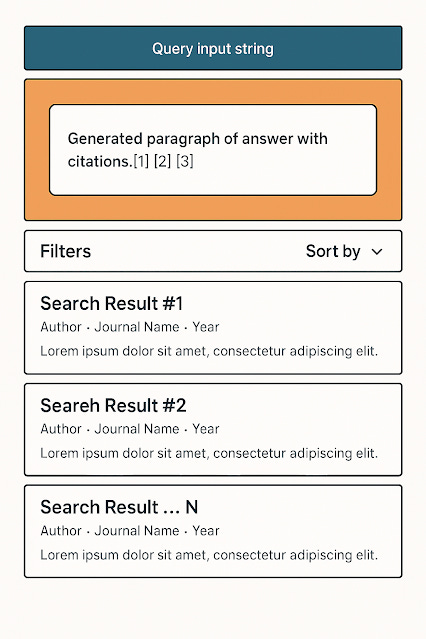
Belows show an example of such a search engine - Primo Research Assistant,

Compared to the others, they are pretty much designed as traditional search engines, but enhanced with "AI" (typically, but not always, capabilities unlocked from Transformer-based models).
The earliest of such tools were from startups or less familiar names like Elicit, Consensus, Scite assistant*, but by now the incumbent academic database vendors have responded with Scopus AI, Web of Science Research Assistant, and so on, as I predicted back in early 2023.
Today, most of them would, at the minimum, provide a direct answer with citations summarized from the top few papers retrieved. Most of them would also encourage the use of natural language queries (as opposed to keywords) and generally use a mix of semantic search and/or an LLM to convert the query to a Boolean search.
Large Language Models - finetuned as Chatbot with search capability
The second group of tools (ChatGPT, Microsoft Copilot, Geinmi, Claude, DeepSeek, Grok) is, of course, very mainstream.
These are Transformer-based large language models (technically decoder models), fine-tuned to work as chatbots. With the exception of Microsoft Copilot, they initially did not have the ability to search (Claude just received this capability last month!) and any answers they generated were not from searching. This led to the very famous and well-known situation where they would hallucinate facts and references.
All of them eventually gained the ability to search the web to retrieve documents or text chunks to help ground the generated answer. This makes them very similar to the first group, except they are still not designed to be search engines, though they can act that way. So, for example, if you input "How are you," ChatGPT and company will just respond like an LLM trained to be a chatbot without searching, while those in the first group will search "how are you." (typically the LLM "decides" when to search or not or you can force it to by turning on the option)
Below shows the ChatGPT with search button
This second group, while they are capable of searching, I do not consider them AI academic search engines, because that is not their main purpose. They are not just search capable but capable of carrying out all sorts of tasks, from summarization to data extraction, etc.
Citation based Literature Mapping Services/Recommenders
The third group (Connected Papers, ResearchRabbit, Litmaps*, Citation Gecko, Inciteful) is what I have been calling citation-based literature mapping services. I first started writing about them in 2019, when the availability of open scholarly metadata, particularly citation data, became high enough that tools based on them became useful. It seemed to me 2020 was the year these types of tools made the breakthrough, with startups like Connected Papers leading the way, followed by LitMaps and ResearchRabbit. None of these were the pioneers; I give this honor to CitationGecko, dating back to 2018.
Below shows Citation Gecko

These tools generally were based on technology that focused on citation/graph-based methods and generally do not use Transformer-based model technologies (though this might be changing with LitMaps having a mode that uses text similarity based on Transformer models). They generally work as recommender systems, where you enter one or more relevant papers (termed "seed papers") and they will recommend papers based on some citation-related techniques. The simplest include direct citation and less direct citation methods like co-citation and bibliographic coupling, as well as providing different visualizations. See here for a thorough introduction and analysis of these tools.
This third group is arguably more of recommender systems, not search engines. While they can be compared to search engines by evaluating their capability at finding relevant papers versus a traditional search engine, they are so different that I would analyze them separately from a search engine, even one with AI.
AI writing support tools
The fourth group (Keenius, Jenna,ai) I have the least experience with but are generally presented as AI writing or AI writing tools. The interface is generally presented as a document or canvas-like layout, where you type in your text and the tools will help you with the writing and often even with finding suitable citations. There are different degrees of assistance given depending on the product, and you also see elements of such features in ChatGPT's canvas and SciSpace's AI writer.
EDIT : Keenius barely falls into this class of tools, because it doesn't actually automatically insert citations. It's actually just using the text you input as a semantic search, which will display a list of possibly relevant articles in a panel, and you have to insert the citations your manually, but the affordance of the tool, feels very much like a writing tool.
Below shows SciSpace's AI writer.

This fourth group clearly consists of products with some search or recommender elements incorporated in (e.g., for finding citations from the citation statement, but see some concerns), but again, these are clearly not search engines.
Academic Search engines that may not count as "AI"
The last group (Lens.org, OpenAlex) consists of clearly academic search engines. The trouble is whether they can be considered "AI." Lens.org is probably the most clear-cut. While not well known to the academic librarian community, Lens.org began indexing academic papers as far back as late 2017/early 2018, leveraging the rising availability of open scholarly metadata that we mentioned earlier. While Lens.org was one of the most massive academic aggregators that brought together data from diverse sources like the now-defunct Microsoft Academic Graph, Crossref, CORE, etc., and boasts state-of-the-art visualization capabilities that exceed most commercial models, there is nothing "AI" about Lens.org.

Lens.org
I suspect calling Lens.org an AI search tool would be a surprise to the people behind it. As far as I know, Lens.org is a perfectly conventional academic search engine, supporting Boolean via Lucene & Elasticsearch. It doesn’t do semantic search, generate answers, or summarize articles, etc.
To a lesser extent, lesser-known academic search tools like Scinapse fall into this category, but I haven't looked into them closely, so they might have some minor "AI aspects."
While I would wager the OpenAlex people would not object as much to it being called an AI search tool, it is still strange.
The best argument I can give for why OpenAlex and maybe Lens.org count as AI search tools is that the “AI” here is more in the way they use machine learning or deep learning during the pre-indexing phase to label/classify data, e.g., tagging of concepts/topics/languages, doing author disambiguation, etc.
But that’s also done by good old PubMed! For example, we know that since April 2022, NLM has fully transitioned MEDLINE indexing from manual to automated methods, and the current 2024 tech used is called MTIX (Medical Text Indexer-Next Generation), and I will be surprised if most academic databases aren't already using such methods to auto-index various fields.
I guess there is room to debate whether these are "AI search engines," but it seems to me if everyone, even the most traditional databases and search engines, has been using this for a while, the semantic meaning of "AI academic search" is so diluted it means nothing.
This last group clearly consists of search engines, but it is the "AI" part that is lacking.
Why all this nitpicking?
I started with the idea of sharing my method of testing AI academic search engines, but I wanted to be clear about exactly what an AI academic search engine is. I generally find debating over definitions a waste of time since there is no inherent "correct" answer (see my discussion on why Open Access definitions are confusing), but in this particular case, I can state clearly what I am thinking about when I say "AI academic search engine."
I've essentially settled on my definition of an AI academic search engine as one that generates direct answers with citations from top retrieved items (almost always via Retrieval Augmented Generation). Basically the list here.
You can, of course, use Retrieval Augmented Generation in many contexts, but in an academic search engine framework, you typically end up with a result screen like this.
Why this definition? Mostly because most of our existing academic search engines are adding AI features in this very way by retaining the search engine layout.
Among all AI features that you could add to a search engine, RAG-generated answers are probably the most eye-catching change that you could make and are likely to impact users the most.
While RAG-generated answers are compatible with lexical/keyword search-based methods of retrieval, we typically see AI search engine vendors encourage users to input queries in natural language as opposed to keyword search, which typically implies the use of some "semantic search" method:

Either some dense retrieval methods (from Transformer-based embedding models)
Or
using an LLM to translate the query input into a Boolean search strategy
Or even both, either in parallel or in succession. We will discuss this further in the next blog post.
There are, of course, other AI features that can be added to search engines, but my testing will focus on only these two features.

Conclusion
By settling on a definition—AI academic search engines as tools that generate direct answers with citations via Retrieval Augmented Generation—we’ve set the stage for meaningful evaluation. But defining the field is just the beginning.
In Part II, I’ll build on this foundation with a suggested testing framework, including specific criteria, methods, and a sample test case to compare tools like Scopus AI, Primo Research Assistant and Web of Science Assistant and others. Stay tuned to see how we can move beyond subjective rankings and toward a rigorous, repeatable way to assess these game-changing technologies.