
The era of open citations and an update of tools- Citation Chaser, Wikicite addon for Zotero with citation graph support and more

In this blog post, I will report on some major progress I believe have been made in the push for open citations
Firstly, the recent announcement by Elsevier followed by ACS that they will finally support open citations is pretty earthshaking news as they are among some of the biggest hold outs among publishers
Secondly, I continue to report on the emerging ecosystem of tools that are building upon open citations (from both publsher/Crossref derived sources and via other crawled sources).
Lastly, even if all major publishers pledge to support open citations, we will always have a lot of items that will not be available in Crossref with references either because the items are old, the publishers lack the resources to extract and deposit the references or the items are not given DOIs.
Can crowd sourcing solve this? I will mention a upcoming Zotero extension that I am watching closely- the WikiCite addon for Zotero with citation graph support which I think has the potential to solve the incentive problem around crowdsourcing for citations.
Edit: 23th Feb 2020 - Just after I posted this, news broke about a new Shared Citation database prosposal by Wikimedia, which extends the work of Wikicite. I'm still trying to fully grasp the full implications of the proposal but this and this might help. The envisoned use cases do look exciting and go beyond the current altmetrics we have on wikipedia (Crossref event data, various altmetrics providers) and covers more than just typical doi/journal content.
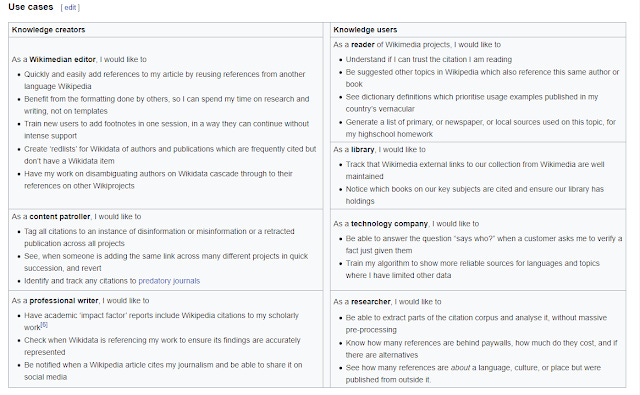
Use cases for the proposed Shared Citations Databases
Correct, and also:
• support sister projects beyond Wikipedia (Wikisource, Commons, or even Wikidata itself)
• include more granular statistics about edition cited, pages referenced etc
• include links to Wikidata items about authors, topics, publishers etc.
See mockup below: pic.twitter.com/rOGrTd20Bk— Dario Taraborelli (@ReaderMeter) February 23, 2021
The (brief, layperson) story of open citations so far
I've been a big fan of the idea of open citations since 2018 and I'm happy to report we have had big news on this front in the last few months.
Here's the story so far.
In April 2017, the Initiative for Open Citations I4OC launched , aiming to encourage Scholarly Publishers to both deposit their reference lists into Crossref and to make them open to the public.
As it so happened many of the publishers, particularly big publishers were already depositing their reference lists into Crossref ( as part of their participation in Crossref’s Cited-by service) but were keeping it closed, so many of them were able to make the list open to the public by simply allowing Crossref to do so, which would make such data available to the public via free APIs and data dumps.
I4OC was able to achieve amazingly quick progress and in less than a year (Jan 2018), they had managed to open 50% of articles with references that were deposited into Crossref , up from 1%.
By 2019, this rose to 59% with publishers like IOP joining, by then most of the major publishers had joined I4OC or committed to open citations including Wiley, Sage, Springer-Nature, Taylor & Francis, however there were still some major holds out including Elsevier, American Chemical Society, IEEE and Wolters Kluwer Health.
Elsevier in particular was a serious problem because they were by far the largest single factor holding back open citations. For example an analysis by OpenCitations in Nov 2017 suggests that
of the 470,008,522 references from journal articles stored at Crossref that are not open, 305,956,704 (65.10%) are from journals published by Elsevier.
More importantly, as Elsevier is also the provider of an A&I service - Scopus. the general thinking was that they would be particularly wary of the rise of open citations. As such, many including myself, believed it would be extremely unlikely for Elsevier to support open citations for this reason, leading to a Elsevier size gap in open citations (i.e. citations made from Elsevier Journals would not be reflected if you just used open citations), which would limit the usefulness of just using open citations from Crossref.
Attempts were made to work-around this problem by crowdsourcing (citations are facts and hence cannot be copyrighted), but it is fair to say that this was hardly likely to be the complete solution. A proposed WikiCite addon for Zotero with citation graph support has been funded that, looks promising to solve the incentive problem, but we shall have to see.
Elsevier and ACS joins the fold!
I'm glad to report, this thinking that Elsevier would never support open citations has proven to be false.
Elsevier gave us all a small Christmas present last year in December 2019 by signing Declaration on Research Assessment (DORA) which includes the requirement to make reference lists of all articles openly available via Crossref
As a member of I4OA (Initative for Open Abstracts), a sister organization of I4OC (Initative for Open Citations), I can't tell you how thrilled I am by Elsevier's decision.
By early 2021, Elsevier had indeed kept their promise and the Crossref participation reports below, do indeed show they have made all their reference lists open.
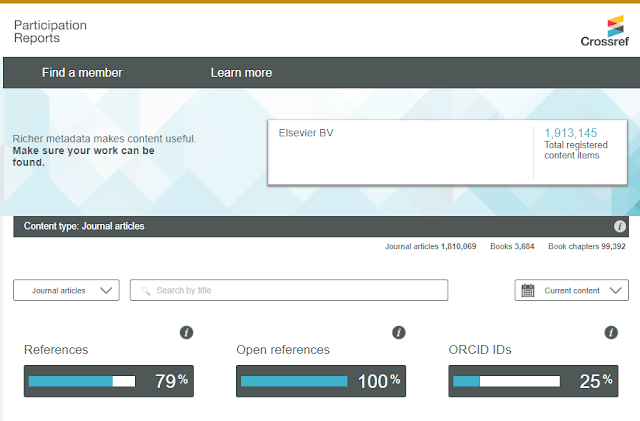
Elsevier Crossref participation reports - 100% Open References
This post by Ludo Waltman gives you a brief overview of the implications of the move. but this might be the crux about the implications of the move by Elsever to open citations
"The most important reason seems to be that Elsevier considered open citations to be a threat to its Scopus business. By keeping its citations closed, Elsevier used its strong position as a publisher to protect its Scopus business. The increasing pressure on Elsevier to support initiatives focused on promoting responsible research assessment (e.g., DORA) and open science (e.g., I4OC) has led to a change in its policy. While opening citations may indeed result in more competition for Scopus, it may also help Elsevier to shift its focus from monetizing data to providing value-added services, which in the longer term may be expected to be commercially more attractive."
My gut feel is that while this strengthens the open citations pool and is a shot in the arm for citation discovery systems like Lens.org that use such data, Elsevier will not see much fall-out in terms of institutions cancelling Scopus for such systems at least not for the forseeable future due to it's importance in University ranking systems as well as other value add features. This probably holds for it's competitor Web of Science as well but I could be wrong.
I also wonder if such a move to support open citations can be easily taken back (DORA commitments not withstanding), if it turns out such a move does indeed affect their A&I service, I guess we will wait and see.
What about the remaining big hold-outs? As expected with Elsevier joining the fold it is harder for the remaining ones to hold out.
On Feb 19, 2020, ACS announced a similar move by signing DORA which commits them to making their reference lists open.
With all these developments, I guess it is not too optimistic to expect that some of the remaining hold-outs IEEE etc will be joining the fold soon.
So what does all this mean?
I understand from the point of view of many researchers and even librarians, this push for open citations seems very abstract or exotic. What good does open citations do for me they would say?
Among many reasons to care, open citations opens up the possibility of many useful and interesting use cases for tools, many of which are open source. I first covered this in a 2019 post - The rise of new citation indexes and the impact on Science mapping tools - Citespace, VOSviewer , Citation Gecko and more and various other posts after that.
This section of the blog post will provide an update on these and many tools
The rise of innovative literature mapping tools

As noted in The rise of new citation indexes and the impact on Science mapping tools - Citespace, VOSviewer , Citation Gecko and more , tools that benefit the most from the dividends of open citations include the newer citation indexes like Lens.org that use such data , as well as bibliometric mapping software like VOSviewer, CiteSpace, CitNetExplorer as well as tools like Citation Gecko which I believe represent a new brand of software tool targetted at researchers who are not bibliometricians but who nevertherless want a way to explore and map the literature using traditional citations (among other techniques).
Since then we have seen a whole host of mostly opensource and free tools emerge in a similar vein as Citation Gecko including
I have created a webpage to track and compare these tools here.
In the case of Citation Gecko while I had always liked the interface, I had always been held back by the knowledge that it relies solely on the open citations available via Crossref and this meant using Citation Gecko alone would give a incomplete picture. With Elsevier and ACS joining the fold, such misgivings are reduced.
It is important to note that while some of these tools like Citation Gecko benefit directly from Elsevier and ACS making their reference lists open in Crossref, some of these other tools draw from other source of open citations.
Besides Pubmed (used by CoCites), the two biggest sources of open citation data besides Crossref are Microsoft Academic Graph and Semantic Scholar Open Research Corpus (or the newer S2ORC) and these are indeed used by Location Citation Network (which uses Crossref as well) and Connected Papers respectively.
Other tools like Papergraph use Semantic Scholar Open Research Corpus , while Inciteful uses a blend of sources.
The main difference between using such citation sources like Microsoft Academic Graph as compared to Crossref is that Micosoft Academic Graph data is based on data extracted from crawlers. Similar to Google Scholar, the crawler will download the webpage or PDF, parse the data (which is semi-structured at best) and attempt to work out what are the citation (among other Scholarly metadata)
The coverage using such methods tends to be larger than publisher supplied metadata but at the cost of some inaccuracy and reliability.
That said, use of both data from publisher provided sources and data obtained from crawling are not incompatiable. Also, even if the publisher provided data is not used directly, it is possible that the more clean publisher data in Crossref is available, the more these can be used as the gold standard to train better algothrims to extract the data, indirectly improving results from such sources.
Some latest developments with Connected papers
These tools are very early in their development and people are still figuring out their potential, but currently Connected Papers seems to have some traction.
A slick user interface, combined with innovative features to try to identify seminal papers and survey/review papers are some of their selling points.
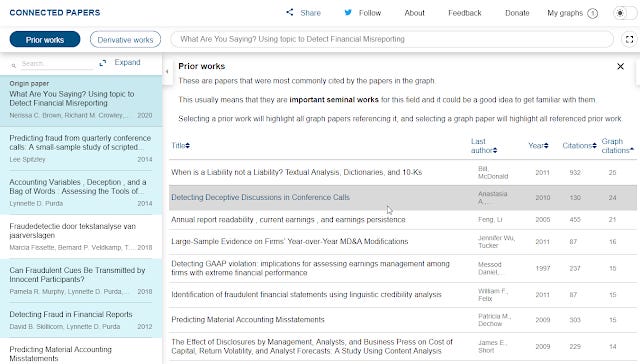
Prior works detected by Connected Papers
They have also tied up with partners like Paperwithcodes and started partnering with conferences like EMNLP2020 to display their visualization graphs on conference sites.
The biggest high profile win so far is their tie up with Arxiv.
A feature of arXivLabs, a visitor to any Arxiv paper page can chose to go down to "the related papers" tab and look at the Connectedpapers visualization.
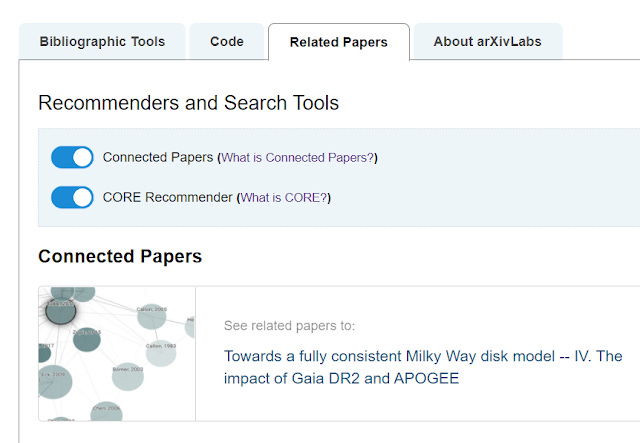
Example of ConnectedPapers in Arxiv
Lens.org and Citation Chaser
I've mentioned earlier that some of the new citation indexes like Lens.org benefit from open data including open citations and it is expected moves by more publishers like Elsevier and ACS to support open citations may improve the quality of Lens.org results.
I've always been a fan of Lens.org due to it's slick interface, powerful search and filter features, best in class visualization features all wrapped around the combination of a large number of the biggest open sources. In the case of citations, it uses both Crossref (which as noted is now strengthened by Elsevier and ACS) and Microsoft Academic Graph among other sources.
I have often wondered
(1) Why Lens.org isn't used more in systematic reviews
(2) Why we haven't seen tools similar to Connectedpapers or Citation Gecko plug into Lens.org's data particularly since an API is available for free (with limits)
The first such tool - Citaton Chaser, an R package has been created by Neal Haddaway. indeed uses the Lens API to achieve both goals.
If you are like me rusty in your R, no worries Neal has you covered as you can use the Shiny app he has created here.
So what is citation chase? The tool is designed as a supplement to support systematic review by pulling in papers based on paper that have already been screened to be relevant. Citation Chaser uses the Lens API to extract either papers that cite or are referenced by these screened papers ,which can be then exported in RIS format for further deduping anf screening.
Step 1
The idea is to import a series of papers that you have already screened to be relevant using articles IDs used in Lens.org (DOIs, PubMed IDs, Microsoft Academic Graph IDs, CORE IDs and even titles).
Enter those articles in a comma seperated way into the shiny app - tab "article input". Also add the Lens.org API key (free with some limits) and click check my input articles.
In the example below, I tried with only 4 articles. I have tried with as many as 50 with no issues.
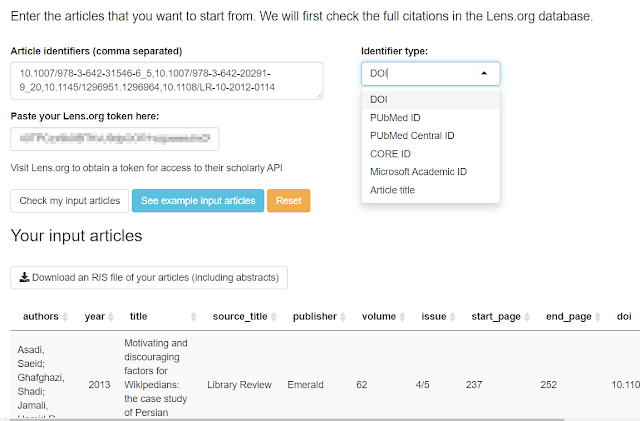
The input tab in Citation Chaser
Step 2: Once the articles you inputted are loaded, click on the "citations" tab and click "search for all citating articles in Lens.org.
In the example below, this gives you 47 unique article IDs that you should potentially screen. Some of these might be dupes of the papers you have already found or even might be dupes that Lens.org has mistakenly considered unique.
As such you should export these records in RIS and import them back to their reference manager to do deduping.
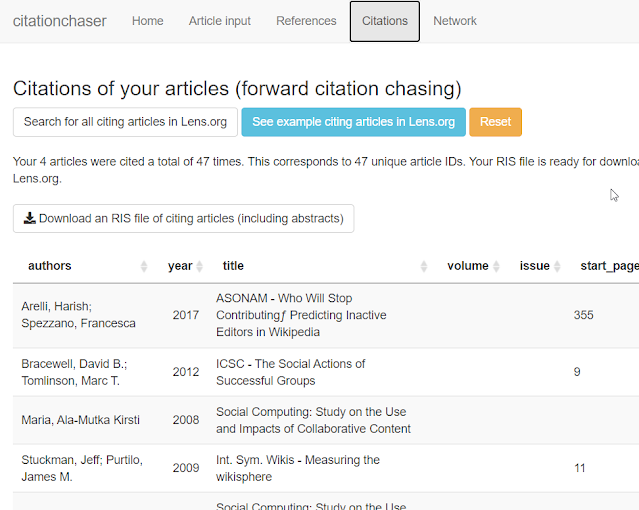
The citation tab in Citation Chaser
Step 3 : Repeat the similar step for the references tab. Again you should export this in RIS to your reference manager for deduping and screening.
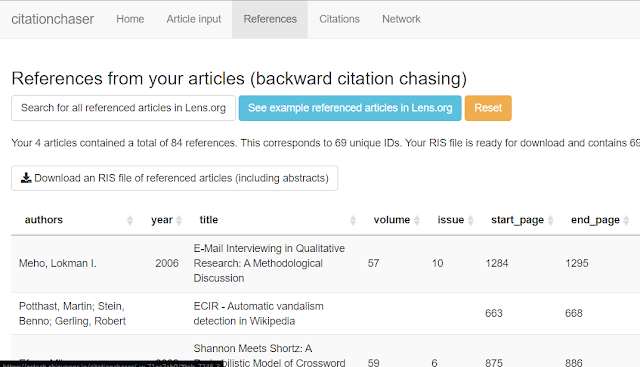
The reference tab in Citation Chaser
Step 4 : Visualize the citation network
People like visuals, this is where the new visualization feature in Citation Chasers come in.
As I write, this feature is still in development in the "network" tab. I must admit, I currently don't quite understand how to interpret this graph.
Open Citations Plugin for Zotero
Lens.org, Citation Chaser, Connected papers, all these tools are pretty much niche tools.
However, many researchers would be familar or have at least heard of the open source reference manager Zotero.
Would it surprise you to know that are useful extensions for Zotero are emeging that are related to open citations?
First up is Zotero Open Citations plugin by Philipp Zumstein. It is a more complete answer to, how can i use Zotero to not just download the papers I want but also download the papers that cite that first mentioned paper.
You can kind of get cited papers of a paper without the extension if the article you are looking at has a seperate page listing papers that cite it and using the native Zotero plugin to grab all dois on the page
Typically when you look at the article online in HTML, you can right-click on Zotero --> Save to Zotero (DOIs) and Zotero will pick up all references with DOIs. Try e.g. on https://doi-org/10.1016/j.amjsurg.2009.02.010
Doesn't appear to work on ACS, though 1/2— Sebastian Karcher (@adam42smith) February 19, 2021
But as noted this doesn't always work.
Instead you can use Philipp Zumstein's experimental Zotero Open Citations plugin , which allows you to pull citations for every item in Zotero using open citations sources.
Hack for a Zotero Plugin for Open Citations https://t.co/LrSlCvmj9x #WOOC2018 . Feedback or ideas in any form are very welcome. pic.twitter.com/702Qbiv3IA
— Philipp Zumstein (@zuphilip) September 5, 2018
Currently
"a DOI lookup in the OpenCitations COCI service is implemented, the result is added as a note, and the latest references are saved in a special collection in Zotero"
OpenCitations COCI or more formally the OpenCitations Index of Crossref open DOI-to-DOI citations is produced by the OpenCitations organization and is derived from Crossref data.
Again with the latest news from Elsever and ACS, these plugin will become much better at providing a complete picture.
Solving the incentive problem around crowdsourcing? WikiCite addon for Zotero with citation graph support.
Note: an early v0.02 is available that has implemented the wikicite syncing portion only is available.
Given the belief that some publishers are never going to support open citations and/or the understanding that some small publishers will not be capable of doing so even if they wanted to, there has been some ideas about crowdsourcing such information (allowable by law since citations are facts and can't be copyrighted) and perhaps even pushing the data back to Crossref (I can see a lot of problems here).
But will crowdsourcing really take off? Wikipedia did, but crowdsourcing of citations seems way more exotic.
I thought not, but a couple of years ago, I was showing the newly developed Citation Gecko to a group of researchers and I mentioned that one major drawback of Citation Gecko was the missing data in Crossref due to holdouts by som publishers.
I was stunned by a researcher asking me if there was any way to contribute those missing citations. This lead me to realise that Crowdsourcing citations was not as hopeless an idea as I thought.
Of course, OpenCitations eventually came up with the idea of CROCI format for the Crowdsourced Open Citations Index where researchers could submit simple files with article DOIs and reference lists in them, but that does not seem to have gotten much traction so far.
CROCI is a good idea, but on it's own it sounds really abstract and does not seem to answer the question of incentives (note in my story above, we were discussing Citation Gecko first....)
So can we do better to encourage crowd sourcing of citations?
One upcoming Wikicite funded project I am watching closely is the WikiCite addon for Zotero with citation graph support.
As the name suggests it is Zotero plugin that allow you to visualize a citation graph of your Zotero's collection. It is stated it will adapt work from Local Citation Network (one of the innovative mapping tools mentioned above and uses both Crossref and Microsoft Academic Graph data) for visualization as well as allow exporting to a format that can be used in VOSviewer.
Exciting! But where does the information of the citation graph come from?
It will fetch information from WikiData and "uses this information to easily show how the items in the user's collection connect to one another".
But WikiData is a fairly new project and like Crossref is likely to have a lot of missing data (it uses scripts to import from sources like Crossref), so this doesn't sound that useful.
But here is the master stroke, it will also do automatic extraction of citation information from PDF attachments in your Zotero library and if the user chooses can add this back to Wikidata adding to the source of open citations!
It is also planned exporting in CROCI format, enabling submission to the Crowdsourced Open Citations Index, helping expand open citation sources beyond Wikidata/Wikicite.
As I wrote in support of the extension back then
I strongly support this. This might be the missing link in incentivizing researchers to contribute to free the remaining citations that remain closed. I4OC https://i4oc.org/ have done amazing work but now seems to have mostly stalled at 50% open citations mark due to hold outs from remaining publishers e.g. Elsevier who are unlikely to relent. So incentizing resarchers to free the citations themselves seems to be a good way to close the gap. Even if this doesn't happen at scale, the individual researcher can still benefit from the plugin
While since then Elsevier has relented, there is still a big mass of papers and items that are not in Crossref for various reasons e.g. older items, items from small publishers who do not have the know how to provide reference lists to Crossref and even items with no Crossref DOIs.
The fact that this will be done in the widely used Zotero is also important.
While I have seen open source tools that allow librarians to extract citations from pdfs and contribute to open citations, the fact that this tool is meant to be used with the widely familar Zotero reference manager reduces the learning curve and makes it more likely to take off.
And the fact that doing so may help the Zotero user himself helps provides incentive to do so. Would researchers start to use Zotero to extract citations from papers that cite their own papers (but are missing)??
Conclusion
The future of open citations currently looks bright, looking forward to see how all this will develop, In particular, many of the tools currently offered seem to me to be built because they simply can be but how much real value they bring to researchers is a big question part and I forsee big evolution in these tools.
Though the current status of open citations look bright, it's not impossible that some back sliding may occur in the future, particularly if the impact of open citations turns out to be negligible.