


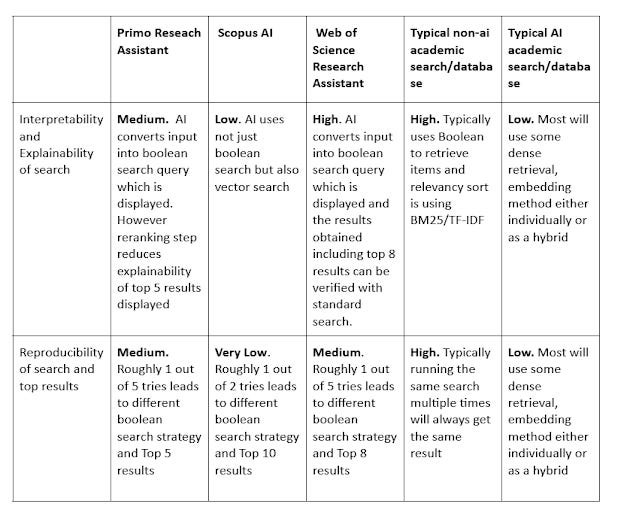
The reproducibility and interpretability of academic Ai search engines like Primo Research Assistant, Web of Science Research Assistant, Scopus Ai and more

I recently compared three academic AI search tools: Primo Research Assistant, Web of Science Research Assistant, and Scopus AI for a review article.
Why these three? Mainly because they are add-ons to extremely well-established academic search engines or databases:
Primo: Owned by Exlibris (a Clarivate company), Primo is one of the four major discovery systems used by universities, often serving as the default library search box. It is also, the only one of the three bundled in "free" with Primo.
Web of Science (WoS): Provided by Clarivate, WoS is the pioneer and oldest of the "Big Three" citation indexes.
Scopus: Developed by Elsevier, Scopus is a major competitor to Web of Science and is currently used in important global university rankings, such as the Times Higher Education (THE) World University Rankings and the QS World University Rankings.
(Note: Summon, the sister discovery service to Primo, also from Exlibris/Clarivate, launched its Summon Research Assistant last month. From all appearances, it seems identical to Primo Research Assistant, but I will not discuss it further here.)
I won't delve into a full comparison of how these three tools are similar and different from each other or from other academic AI search tools in this post. Instead, I want to focus on the reproducibility and interpretability of the search results they provide.
Reproducibility of the Search results vs Retrival Augmented Generation Answer
In general, Retrieval-Augmented Generation (RAG) answers use a Large Language Model (LLM) to synthesize information from top retrieved documents. Because LLMs are involved, the generated answer can vary slightly even if the underlying search consistently retrieves the exact same top items.
The non-deterministic nature of Transformer-based LLMs is well-known to anyone who uses ChatGPT, where the exact same input prompt can yield slightly different responses. Advanced users employing LLM APIs know you can reduce this randomness by adjusting settings like temperature, Top P, and Top K. However, even with settings aimed at maximum consistency (e.g., temperature=0, Top P=0, Top K=1), some small degree of variability often remains. I understand this is caused by factors like parallelization in computation, rounding errors in floating points and more
Of course, if the retrieved results themselves differ, the RAG-generated answer will almost certainly differ as well. As you will see unlike keyword search based retrieval techniques, non-keyword search based techniques often bring interpretability and reproducibility issues.
High level view of how retrieval works in Academic AI Search Engines
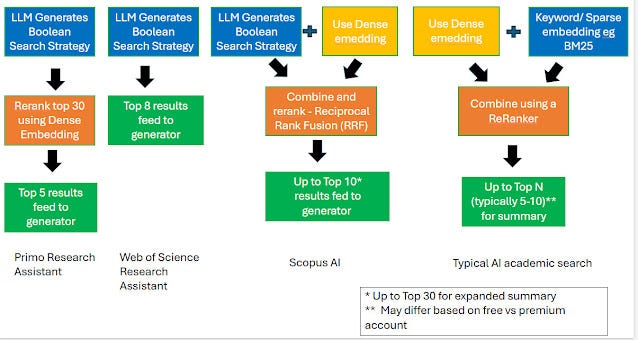
Let's consider how various academic AI search engines might use your natural language input to find relevant literature. The above image shows my best understanding of how Primo Research Assistant, Web of Science Research Assistant and Scopus Ai work based on the documentation and some tests.
The approach taken significantly impacts the reproducibility and interpretability of the results. This generally depends on the search mechanism(s) employed.
This can look very technical, if you having been looking into details of information retrieval but let me try to explain.

Technical Note: Gusenbauer & Haddaway (2020) distinguish and test both "Reproducibility of search results at different times" and "Reproducibility of search results at different locations." In this post, reproducibility refers to the first meaning – getting the same results when running the same search again, whether seconds apart or in different sessions.
1. Keyword-Based Methods (e.g., Boolean + TF-IDF/BM25 Ranking)
Description: This is the traditional method used by most conventional academic databases. It relies on matching keywords from your query within the documents. Most common is Boolean for matching items and relevancy ranking using TF-IDF/BM25
Interpretability: High. With strict Boolean logic (AND, OR, NOT), you can understand precisely why a document is included or excluded. Standard relevance ranking algorithms like TF-IDF or BM25, while technical, are somewhat intuitive – you can often grasp why some results rank higher by looking at the frequency and placement of matched terms (e.g. title matches worth more).
Reproducibility: Generally high. Running the exact same Boolean query usually yields the exact same set of results (assuming the underlying database index hasn't changed).
2. LLM-Generated Keyword/Boolean Search

Example of Web of Science Research Assistant using LLM to generate Boolean Search
Description: An LLM takes your natural language query and translates it into a structured Boolean or keyword search strategy, which is then run against a traditional database inverted index.
Interpretability: Remains high, assuming the system displays the generated Boolean query. You can see exactly which terms and logic were used to retrieve the results.
Reproducibility: Lower than pure keyword search. Because an LLM is involved in generating the query, the non-deterministic nature of LLMs means the generated search strategy itself might differ slightly even when given the exact same input query. This variation in the search strategy directly affects the reproducibility of the final result set.
3. Non-Keyword / Embedding-Based Methods (Knowned as Vector Search, Semantic Search, etc.)
Description: These methods generally convert both your query and the documents into numerical representations (vectors or embeddings) in a high-dimensional space. The system then finds documents whose vectors are "closest" or most similar to the query vector. Terminology varies: you might see "vector search", "(dense) embeddings", "neural search", "dense retrieval", or "semantic search." There are many technical variants (e.g., bi-encoders, cross-encoders, late-interaction/multi-vector approaches like ColBERT. Also learned sparse methods like SPLADE.)
Interpretability: Generally low. These methods often function as "black boxes." It's hard, if not impossible, to explain precisely why a specific document is retrieved or ranked higher than another, beyond pointing to a calculated similarity score between the query and the documents. Some advanced methods (like ColBERT or SPLADE) have the potential for more interpretability by showing which components contribute most to the relevance score, but they are not yet widely implemented or exposed in interfaces. (To my knowledge, Elicit is one academic AI tool using SPLADE, but its interface doesn't currently break down the score components for users).
Reproducibility: Often lower than keyword methods. Several factors contribute, but a major one is the common use of Approximate Nearest Neighbor (ANN) algorithms. ANN speeds up the computationally intensive process of finding similar vectors in massive datasets but often introduces some randomness, meaning results can vary slightly even for identical queries.
Let's now examine how our three example tools blend these methods, leading to differences in their interpretability and reproducibility.
Web of Science Research Assistant
This is perhaps the most straightforward of the three. Based on my testing and the available documentation:
1. It feeds your natural language query into an LLM (at the time of writing, likely a model like GPT-4o mini).
2. The LLM is prompted with instructions to generate a complex Boolean search query suitable for Web of Science.
For example, if you enter:
"impact of climate change on biodiversity"
The Assistant might generate a query like this:
(climate change OR global warming OR climate variation OR climatic changes OR climate variability OR climate crisis OR climate emergency OR greenhouse gases OR anthropogenic climate change OR carbon emissions) AND (biodiversity OR species diversity OR ecosystem diversity OR biological diversity OR ecological diversity) AND (impact OR effect OR influence OR consequence)
While we don't know the exact prompt used, observing examples suggests instructions along these lines:
1. Extract the main concepts from the user query.
2. For each concept, generate relevant synonyms and related terms, combining them with OR.
3. Combine the resulting concept blocks using AND.
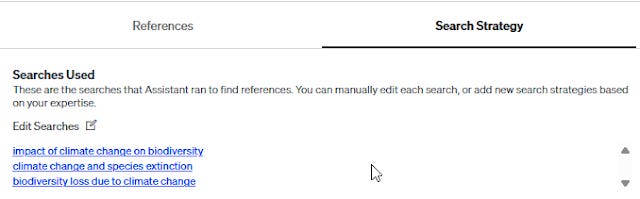
Crucially, the Web of Science Research Assistant displays the generated Boolean query and provides a link to run it directly in the standard Web of Science interface.
Testing confirms that the top 8 results shown by the Research Assistant are exactly the same results, in the same order, as running the generated Boolean query directly in Web of Science using the default relevance sort (which likely uses BM25/TF-IDF).
Interpretability: Very high. You know exactly which Boolean search query was used. You can also understand why the top 8 results were retrieved and ranked as they are – they directly correspond to a standard WoS search using that generated query and default relevance ranking.
Reproducibility: Moderately high for an AI system. Since an LLM generates the Boolean query, some non-determinism is expected. In my tests, running the same natural language query multiple times resulted in a different generated Boolean search strategy roughly 1 out of 5 times. While this indicates variability, it's notably more consistent than some other AI search tools.
Primo Research Assistant

Boolean search generated by LLM for Primo Research Assistant
As I explained in a previous post, Primo Research Assistant functions similarly to the WoS tool in that it also uses an LLM to construct a Boolean search strategy. However, the style of the generated query and the subsequent processing differ.
Using the same example query:
"impact of climate change on biodiversity"
Primo RA might generate a query structured like this:
climate change biodiversity impact) OR (effects of climate change on ecosystems) OR (biodiversity loss due to climate change) OR (climate change species extinction) OR (impact of global warming on wildlife) OR (effects of climate change on ecosystems and species diversity) OR (how climate change impacts wildlife and biodiversity) OR (climate change consequences for biological diversity) OR (relationship between climate change and loss of biodiversity) OR (climate change threats to flora and fauna diversity) OR (impact of climate change on biodiversity)
Based on documentation and observation, the LLM appears to be instructed to:
1. Generate multiple query variant strings based on the original input.
2. Do it 10 times
3. Combine these 10 generated strings and the original query input using the OR operator.
So far, it seems analogous to WoS RA, just with a different query generation strategy. However, Primo RA adds another layer: it reranks the top 30 results retrieved by the generated Boolean query. This reranking step uses embedding models – a form of the less interpretable dense/vector retrieval discussed earlier.
PubMed also works similarly, though it runs a standard keyword search (BM25) first followed by reranking the top 500 using a machine learning-based reranking method - LambdaMART, making results somewhat less interpretable if you want to explain the order of results.
Because of this reranking step, the top results displayed by Primo Research Assistant will not necessarily be in the same order as those you'd get by simply running the generated Boolean query in the standard Primo interface.
Furthermore, the results might differ because Primo Research Assistant searches Primo's Central Discovery Index (CDI), with specific exclusions (e.g., content owners opting out) that might not apply identically to a user's standard Primo interface search configured by their institution.
Interpretability: Quite high, but slightly less than WoS Research Assistant. Like WoS RA, it displays the generated Boolean query, so you understand the initial retrieval logic. However, the final order of the top results is influenced by the embedding-based reranking step, which is harder to interpret. You can still understand why an item was retrieved at all (it matched the Boolean query), but explaining its exact rank among the top results is more difficult than with WoS RA.
Reproducibility: Similar to WoS Research Assistant in terms of the generated Boolean query. In my tests, the generated query also changed roughly 1 out of 5 times for the same input. The reproducibility of the final ranked list might be slightly lower due to potential non-determinism in the reranking step, although this is harder to isolate.
Scopus AI
Scopus AI employs the most complex retrieval mechanism of the three.
Like the others, it uses an LLM to generate a Boolean search strategy. For our example query:
"impact of climate change on biodiversity"
It might generate something like:
("climate change" OR "global warming" OR "climate crisis" OR "climatic change") AND ("biodiversity" OR "species diversity" OR "ecosystem diversity" OR "biological diversity") AND ("impact" OR "effect" OR "influence" OR "consequence") AND ("conservation" OR "preservation" OR "protection" OR "sustainability") AND ("habitat" OR "ecosystem" OR "environment" OR "biome") AND ("adaptation" OR "mitigation" OR "resilience" OR "response")
Interestingly, this query seems to incorporate more concepts (perhaps 4-6 distinct blocks) compared to the WoS RA example (3 blocks). The Scopus AI documentation mentions a "Copilot" that ensures "complex queries are broken down into their component parts," hinting at some initial query analysis or expansion (which add new aspects or concepts) before the LLM generates the final Boolean query.

Scopus AI does both "natural language search" and keyword Boolean search
The major difference, however, is that Scopus AI also performs a "natural language search" simultaneously with the Boolean search. The documentation describes this as a Vector Search. Unlike Primo RA's reranking step, Scopus AI uses vector search as part of the initial retrieval.

In the documentation the natural language search is described as a Vector Search. This is akin to the reranking step down by Primo Research Assistant, except this is done at the initial retrieval step.
In essence, Scopus AI uses a "hybrid search" system:
1. It runs the LLM-generated Boolean query against the Scopus index.
2. It runs the original natural language query (or a processed version) through an embedding-based vector search against the Scopus index.
3. It takes the top results from both searches, deduplicates them, and combines/reranks them (likely using a method like Reciprocal Rank Fusion) to produce the final list.
Interpretability: Clearly much lower than the other two. While the generated Boolean query component is displayed and interpretable, the simultaneous use of vector embedding search during initial retrieval makes the overall results significantly less interpretable. The vector search part acts as a black box; there's no straightforward way to explain why certain results were retrieved via that path or how they contributed to the final ranking, beyond abstract similarity scores
Reproducibility: Very low, based on my testing.
The generated Boolean search query itself is highly variable. It changed almost every other time (roughly 1 in 2 times) I ran the same natural language query. Potential reasons include randomness introduced by the initial "Copilot" query analysis step, or the LLM generating the Boolean query might be configured with parameters allowing for more variation (e.g., higher temperature).
The reproducibility of the overall search results (the final list) is also very low. This is likely due to the combination of the variable Boolean query and the inherent non-determinism of the vector search component (potentially using ANN algorithms). Even if the Boolean query happened to be the same between two runs, the vector search part could still return slightly different results, leading to a different final combined list.
Other Academic AI Search Systems & General Trends
My tests here are informal. Eventually, we will hopefully see formal evaluations of AI search tools, similar to Gusenbauer & Haddaway's (2020) study of 26 academic search systems ("Which academic search systems are suitable for systematic reviews or meta-analyses?"), but adapted for these new complexities. For now, let me speculate based on available information and trends:
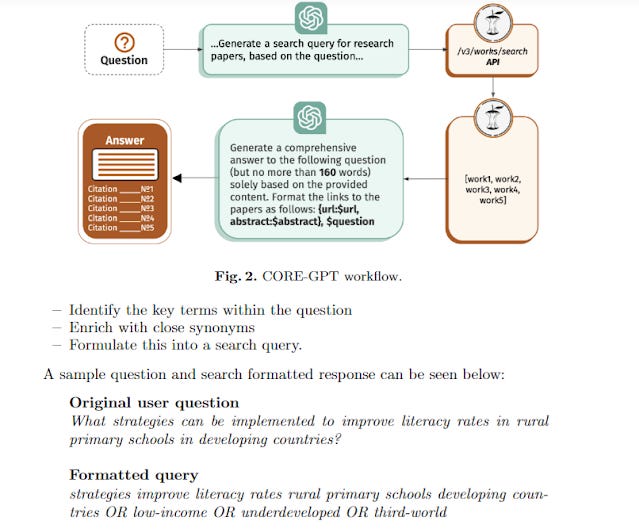
Earlier tools like Scite.ai Assistant and the experimental CORE-GPT also use LLMs to generate search strategies. Scite.ai's generated queries sometimes resemble Primo RA's style (multiple OR'd phrases), while CORE-GPT might lean towards the WoS RA style (concept blocks with synonyms). Their specific reproducibility and interpretability would depend on their exact implementation (e.g., do they rerank? do they also use vector search?).
Typical "AI Academic Search": It's often hard for us as librarians to know precisely what's happening under the hood, as vendor documentation varies in technical detail. However, based on informal discussions and industry trends, my guess is that many newer academic AI search engines, especially those from startups, are implementing hybrid search similar in principle to Scopus AI (running keyword/Boolean and vector searches in parallel, then combining results).
Beyond the use of LLMs to generate Boolean search strategies, LLMs can and have been used in other aspects of retrieval including being used outright to evaluate relevancy of the papers (e.g. Undermind.ai, Elicit Research Reports)
Incumbent Vendor Choices: Established vendors with massive, existing, highly optimized keyword-based indexes (like Exlibris/Clarivate with Primo/Summon and WoS) might initially prefer the "LLM-generates-Boolean-query" approach seen in WoS RA and Primo RA. The main advantage is likely cost and infrastructure. Building, maintaining, and constantly updating a parallel vector database for billions of items to support embedding search is significantly more resource-intensive than leveraging their existing infrastructure with an LLM front-end. This might explain why Exlibris/Clarivate have adopted this method for tools searching huge indexes like Primo's Central Discovery Index (containing 5 billion records - but of course not all records can be used in Primo Research Assistant).
Interpretability: Many emerging "AI academic search" tools that heavily rely on embedding-based vector search (especially in hybrid models) suffer from lower interpretability compared to traditional keyword search or even the LLM-generated Boolean approach (when the query is shown). Complex multi-stage retrieval pipelines used by some systems can make it even harder to understand precisely why you're seeing the results you get.
Reproducibility: While variable, the reproducibility of typical academic AI search engines is generally expected to be lower than that of traditional, deterministic keyword-based academic search. The degree of reproducibility varies significantly depending on the specific methods used (LLM settings, use of ANN in vector search, hybrid ranking strategies, etc.).
Conclusion: Beyond Reproducibility and Interpretability – The Challenge of Bias
The advent of modern AI in search presents multifaceted challenges extending beyond the interpretability and reproducibility issues discussed here. Perhaps the most profound, and certainly harder to investigate thoroughly, lies in detecting and measuring algorithmic bias.
As platforms increasingly replace explicit keyword control with AI-driven relevance judgments—often using neural networks for ranking or retrieval—they risk reflecting and potentially amplifying biases inherent in their underlying data and design.
While known biases can sometimes be mitigated with effort, it is the unknown biases that pose a more significant concern. Detecting these hidden skews remains a formidable challenge, particularly in the current dynamic landscape. Is there a way to detect them? I certainly have no clue.
Currently, no single AI academic search tool or algorithm dominates (with the possible exception of Google Scholar). We are in a 'Wild West' phase where the information retrieval field lacks consensus on optimal ranking methods, leading to a variety of approaches. This situation is both a boon and a curse.
It's a curse because, without consensus, biases identified in one tool might be specific to its unique implementation, making systemic solutions difficult. Conversely, it's a boon because the diversity of tools means users aren't locked into a single potentially flawed system, and employing multiple tools might help mitigate the impact of any one tool's specific bias.
This inherent opacity presents a significant challenge. If the inner workings of these AI systems remain largely obscure, and unknown biases are difficult, if not impossible, to detect definitively, what practical approach can librarians and users take? Perhaps the most crucial skill we can currently cultivate and teach is fundamental skepticism.
On the other hand, navigating information systems with opaque algorithms and potential biases isn't entirely unprecedented. Librarians and researchers have long relied on tools like Google (which as far back as 2019 already incorporated BERT neural rankings for 10% of queries!) and Google Scholar, despite limited insight into their ranking mechanisms and awareness of potential commercial or systemic biases influencing results.
However, the context and claims of dedicated academic AI search tools arguably raise the stakes. These tools are explicitly marketed for scholarly discovery, potentially leading users to place greater trust in their outputs. Therefore, while the challenge of dealing with black-box systems isn't new, the need for active skepticism might be even more critical now. This translates into practical strategies: consistently questioning surprising results, habitually comparing outputs across different AI search tools (leveraging algorithmic diversity as a necessity), and remaining acutely aware that these systems are prone to biases, even if invisible.
Edit: Article was written by a human but edited with help of Grok3 and Gemini 2.5 pro