
The Rise of Agent-Based Deep Research: Exploring OpenAI’s Deep Research, Gemini Deep Research, Perplexity Deep Research, Ai2 ScholarQA, STORM, and More in 2025


Synopsis (Grok 3.0 aided)
A new breed of "Deep Research" tools is reshaping how we tackle complex queries, moving beyond traditional search engines and quick AI summaries. From OpenAI’s Deep Research and Google’s Gemini counterpart to academic-focused players like Elicit, Undermind.ai and SciSpace, these agentic systems promise comprehensive reports and literature reviews—albeit with a much slower response. Launched in a flurry between late 2024 and early 2025, they leverage frontier LLMs to browse the web or scour pre-indexed academic corpora, often taking minutes rather than seconds to deliver. But what makes them "deep"? This post explores their defining traits—sophisticated typically iterative search methods and long-form output—while contrasting their approaches: general web versus academic-only, real-time versus pre-indexed, and varying degrees of human control. A obvious but tempting idea is that what ChatGPT began threatening - the future of undergraduate essays, these "deep research" tools will finish, though they still cannot be trusted blindly for seasoned researchers due to possible hallucinations. With implications for academic workflows, publisher pushback, and content access looming large, could these tools hint at possibly a large shift in academic search paradigm? Dive into the details and see where this wave might take us.
Note : As of time of writing, I have tried pretty much all the Deep Research type services listed here except OpenAI's Open Research, which possibly might be the best of the lot!
The rise of "Deep Research" search?
On 2 Feb 2025, OpenAI's launched a feature they called Deep Research which uses their new o3 model with "a new agentic capability that conducts multi-step research on the internet for complex tasks."
If you are a reader of my blog you are probably already familar with what it does, you essentially set a question, OpenAI's deep research will ask a few clarifying questions, then it goes off searching and browsing the web trying to find sources to answer your question and to finally generating a long form report or literature review with citations.
Incidently, two months before this in Nov 2024, Google also launched Gemini Deep Research with the exact same name and functionality.
And as you will see later, even Google probably wasn't first with precursors like Stanford University's STORM and arguably PaperQA2 and Undermind.ai
The major difference between OpenAI's and Gemini's Deep Research is that the later will present a "research plan" for you to agree or disagree.

Once you agree to it's plan it will go off to search a few sites and generate a report

Since then, we have seen attempts to both duplicate OpenAI's efforts from open source projects and with competitors like Perplexity responding with Perplexity Deep Research , just 2 weeks later.
While these products search the general web, which can cover academic use cases by searching PubMed, Arxiv etc, we cannot ignore our academic-only "verticals".
In the same span of time,
the Allen Institute for AI launched - Ai2 ScholarQA (Jan 2025)
SciSpace announced - "Deep Review" (Feb 2025)
Elicit announced " Research Reports" -a one-click option to generate a report. (Feb 2025)
While the timing of some of these seems to be a reaction to OpenAI, some of these predate OpenAI's deep research announcements, so it does seem the time for "Deep Research" has come.
What is "Deep Research"
But what is "deep research" and how does it differ from the usual Retrieval Augmented Generation results that we are now getting used to from Google's AI overview, Standard perplexity searches, Scopus AI, Primo Research Assistant etc.
I argue "deep research" products or features tend to have two main characteristics.
1. They tend to use relatively complicated agentic methods to search and/or generate and as a result have very slow response times (typically >5 minutes)
2. They are designed to generate longer full page reports or literature reviews as opposed to generating short answers (typically a few paragraphs) for Q&A tasks.
Note: Whether Undermind.ai and/or PaperQA2 counts as deep research can be a grey area. Both definitely employ agentic type search methods with long latencies that exceed typical search engines. That said, both are not designed to produce very long form reports
1. They tend to use relatively complicated agentic methods to search and/or generate and as a result have very slow response times (typically >5 minutes)
The idea of using LLMs as an agent is not new, since the launch of GPT4 in March 2023, people have been trying with projects like BabyAGI, AutoGPT, where the idea was you would give a LLM a goal, hook it up to tools and "long term memory" and add a chain of thought framework like ReACT framework and wrap it all around something like Langchain and it would "think" and "reflect" on it's actions to decide what to do.

General Agent framework
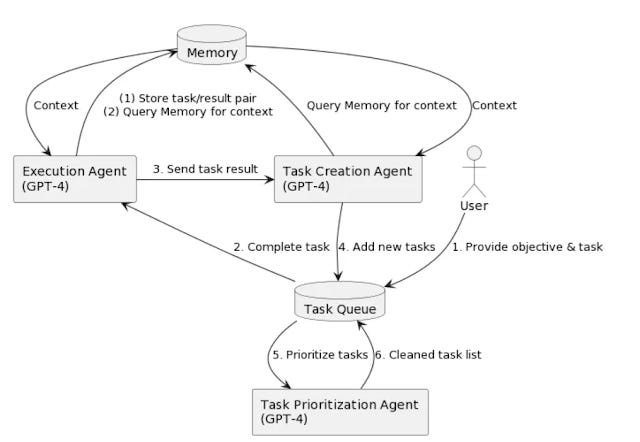
For search applications, even as far back as 2021, OpenAI themselves wrote about WebGPT, where they
fine-tuned GPT-3 to answer long-form questions using a text-based web-browsing environment, which allows the model to search and navigate the web
They would show GPT-3 typical search steps done by the human using a text based web browser and the model would learn to take different actions to search and find sources to answer.

https://arxiv.org/pdf/2112.09332
In fact, I remember the earliest versions of ChatGPT when you selected the browse option, you could see every step GPT did while browsing for answers! The experience was somewhat close to what you get from looking at "Reasoning traces" with deepseek today!
They eventually replaced it with a faster version.
Why did this idea die out? I suspect, the reason is the LLMs at the time just wasn't good enough and 2025 may be the year where LLMs get good enough (in reasoning, in following instructions and keeping coherent for long spans of time due to longer contextual windows).
EDIT: A Visual Guide to LLM Agents and A Visual Guide to Reasoning LLMs are super clear guides explaining the concepts.
Undermind.ai & PaperQA2 - the first academic search with iterative agent-like search
I myself, first appreciated the power of agentic search, when I first encountered Undermind.ai in 2024. I have reviewed Undermind on this blog early last year, and more recently here but suffice to say, a search tool that "takes its time" to do iterative searching (Undermind also does citation searching) and uses expensive frontier LLMs to evaluate relevancy directly is more likely to do a more comprehensive search and produce higher quality retrieval results, than search systems even "AI search" (that uses dense embedding similarity matching) which are constrained to give responses in less than one or two seconds.
Undermind instead takes about five minutes searching through it's own academic index (Semantic Scholar corpus).
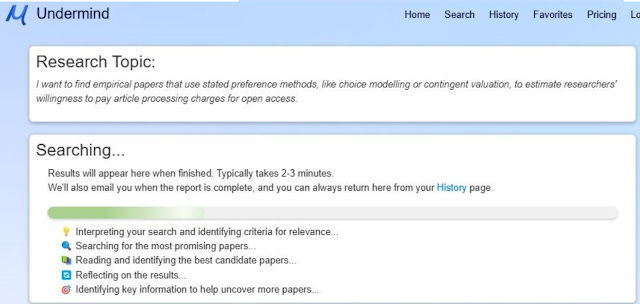
See sampe generated search results and summary of Undermind
The OpenSource PaperQA2 independently came up with a very similar system

The main characteristic of these "Deep" tools, is that they take some time to run. While traditional keyword/lexical tools execute in less than 1 milisecond, and even "AI search" that use dense embedding matching/"neural retrievers" typically do so in less than 5 or 10 seconds, these "Deep" tools take at least a few minutes to run.
2. They are designed to generate longer full page reports or literature reviews as opposed to short answers (typically a few paragraphs) for Q&A tasks.
Does having agentic or "deep" search (which takes a while to run) necessarily imply you need to be used to generate long technical reports? This is not necessarily true.
Note : Despite this definition stated here, Grok3 has "deep search" which is classified as "Deep research" using my terminology, because it produces a long report (sample here)
Jini.ai recently launched in Feb - Jini.ai "Deep Search". When you look at the result given it looks like this.

By now, one should be getting used to search engines both web and academic search, giving a direct answer, typically using Retrieval Augmented Generation which summarises the top N results and this looks like the same thing.
Below for example shows, RAG based answers given by Primo Research Assistant. though, they recently tried to switch it up a bit by showing the 5 results used to generate the result (with an option to look at the full search results) and THEN the retrieval augmented generated answer.

So how is Jini.ai's search "Deep" - when Google AI overviews, Brave summarised results, Primo Research Assistant, Scite assistant, Consensus.ai, Scopus AI, Web of Science Research Assistant are not?
Simply put, Jini.ai's search is "deep" because it employs a simple "agent", which will search, "Read" and "reason" and continue the cyle until it runs out of budget (in terms of tokens use). So you could in theory set a higher budget so it could give more "effort" and search more for your answer.
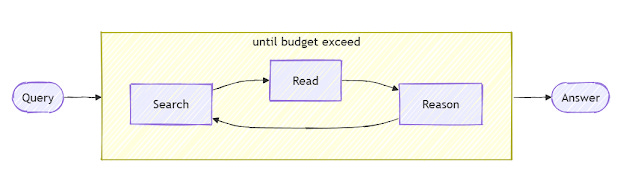
Jini.ai's deep search while loop
But just because it spends time searching longer and "reasoning", doesn't mean it need to generate a whole essay. In fact, to generate the above answer, one has to wait for a few minutes and you can even see the "chain of thought".

As they note

Of course, asking a system to generate a long technical report with many sections and achieving coherence is a much harder task than to just answer the question directly and there are many ways to try to prompt and design LLMs to create essays based on what is retrieved.
How exactly are they doing it? Beneath the hood most are using a combination of LLM generation + probably some form of retrieval augmented generation (and there are many variants), some are doing iterative type RAG processes , or Auto-RAG, where instead of just searching ONCE and then generating the result, it might go through many rounds as the LLM tries to search, generate and critique itself and search again etc. Others might work like Undermind, where the search process goes first but the search is done iteratively but once the search ends it will never search again and just use what it finds to generate. Regardless of the method used, it is likely to be very expensive in terms of computation done and time spent to generate the report.
There are many ways to get the LLM to create long form reports. One way is
1. Create table of content/sections to answer question
2. For each section, search->read->reason loop until budget finished etc - This can be done in parallel.
3. Consolidate and adjust each section taking into other sections

One way of implementing Deep Research
At this point, I suspect the results will be still quite raw but it can only improve.
For a more technical discussion see this post by Jina.ai or this post that tries to classify the different "Deep Research" tools among two dimensions:
Deep/Shallow - how much or how long the system searches iteratively
Handcrafted/trained - How much of the system is set up as agentic workflows (with handcrafted prompts) and how much is the system using LLM as agents that have been trained end to end using reinforcement learning.
For example, it is believed OpenAI's Deep Research is much more towards the trained end to end with reinforcement learning letting the o3 model do more of the steering of the search while others particularly academic ones like Elicit Research Report is likely to work by following handcrafted workflowed created by humans. Handcrafted workflows with LLM making decisions but following the workflow can work very well, but some think the former class of Deep Research tools are likely to be more capable in a larger variety of situations including outlier situations where the handcrafted workflow may not work.
This is somewhat remincient of how chess engines were mostly using handcrafted algos particularly evaluation functions used by the engine to judge if the value of positions vs AlphaZero that was only coded if rules of the game and used self play to learn it's own strategies via reinforcement learning. (As I write this in 2025, the leading chess engine is not a fully Neural chess engine, but rather a conventional Chess engine StockFish that uses traditional techniques but uses a neural trained evaluation function)
My first EARLY impressions of deep research products
Sample of reports from different - Deep Research products
Stanford University's STORM (free)
Gemini Deep Research (free)
Ai2 ScholarQA (free)
OpenAI Deep Research (plus or pro users)
Perplexity Deep Research (free)
At the time of writing, I haven't had a time to do a really deep dive of these products as they all flooded the market within a space of weeks (I have played with all briefly). So far, my superificial impression is while most of them are still prone to the usual issues of RAG systems including hallucinations under certain conditions (it must be even more difficult than usual trying to stay coherent while generating long reports), they are still likely to be above the level of freshman and many undergraduates with some light editing and they will be the final nail in the coffin for take home essay assignments.
So far, light testing of the samples above shows Elicit's solution is finding the most complete and relevant papers at least for one use case, and because of it's focus on data extraction, none of the other solutions are close in term of completeness of the table data extracted. The writing style of Elicit's report is a bit sparse, but is focused around the table data. So far, it is also the only "deep" solution, I've seen that makes it easy to verify the supporting citations. This really should be the standard by now! OpenAi's DeepResearch does seem to be the smartest and best of the non-academic deep research services (probably because it is using the still unreleased o3) but it's citing style particularly in-text citation is still odd.
While ChatGPT started us down this road, these Deep Research projects will finish it. If you are pinning your hopes on OpenAI's deep research being locked behind 200 USD monthly walls, Sam Altman has already announced he eventually plans to offer this feature even for free users (with limited quotas).
That said for now, all but the least experienced researchers should be able to produce literature review of higher quality current than the deep research products, particularly if they are already well versed in the area.
Update - here are some comparisons but note the source of the comparisons!
What are some earlier examples of Deep Research tools & how do they differ?
Now that we have defined what I consider Deep Research tools, I will discuss STORM and AI2 ScholarQA, two early examples of Deep Research. This will be followed by a section on how these tools vary among three main dimensions
1. Are there web general focused or academic focus only
2. Do they search or browse the web in real-time or rely on a preindexed central index
3. How much control or human in the loop control do they offer
Some earlier precursors to OpenAI's Deep Research
Stanford University's STORM- first Deep Research tool?
While both Undermind and PaperQA2 systems can use the retrieved articles to generate answers and summarises (typically using RAG) they weren't meant 100% to produce full articles. (PaperQA2 focused on producing wikipedia-like articles for a very constrained class of topics).
Possibly the first "deep research" system to really claim at generating full wikipedia like essay's, is Stanford University's STORM

Here's a generated sample
How does STORM work? From what I roughly can tell, STORM works by generating a couple of LLM agents to play different roles and for them to ask questions and discuss. The cool thing about STORM is that you can take a peek behind the curtain of the generated paper by clicking on "See BrainSTORMing procedure".
Storm actually has a STORM and CO-STORM mode, with the later mode allows you to "Start a Roundtable Conversation" with the agents but at the time of the blog post, CO-STORM was not available.
This gives you a page with 3 specialized agents used to generate the report and the 4th is I think always a "Basic fact writer".
For my question on the effectiveness of the use of ChatGPT and LLMs as title-abstract screeners in systematic review, you can see STORM spun up a
a) Natural Language Processing Researcher
b) Systematic Review Expert
c) AI in Healthcare specialist.
to ask questions

Allen Institute for AI's Ai2 ScholarQA
If you exclude Undermind.ai and PaperQA2 has academic deep research tools, I guess the crown for the first academic deep research tool goes to Ai2 ScholarQA

AI2 or Allen Institute for Artificial Intelligence is a non-profit founded in 2014 by the late Paul Allen and they are no stranger to you if you are a regular of this blog. Among their projects include Semantic Scholar search engine itself and the corpus behind it S2ORC which is open and popularly used by a large number of startups in the academic area, not least by "AI search" systems like Elicit.com amd Undermind.
Over the years, they have always been at the forefront of trying to combine "AI" with academic corpus, and with the LLM era, they have launched some of the most open LLMs models out there, with current models including OLMO2, Tülu 3 405B and multi-modal Molmo
These models go beyond other open models that just release the weights (open weights). Tülu 3 405B for example provides the training data and the training code!
Just like Google and OpenAI, they launched their version of Deep Research dubbed "Ai2 Scholar QA" in Jan 2025, just a month after Gemini Deep Research was launched and weeks before OpenAi's Deep Research.
Interesting they also launched AI's Open Scholar which compared to Ai2 ScholarQA generate Q&A short form answers only. Interesting according to this paper, they actually cover 45M papers more than Ai2 ScholarQA demo which claims to use only 8M open access papers (from Arxiv?).
You can see a sample of the results here
The main weakness with Ai2 ScholarQA is that it is a bit of a demo as it covers only 8M full text papers supplemented with a search of title+abstract of Semantic Scholar corpus.
How these tools differ - general web vs academic only
One clear difference of course between tools of course are general web search tools vs academic search only tools.

How important is this distinction? More critically, if OpenAI Deep Research can handle academic use cases as well if not better (assuming they always use the superior internal models that make a difference ) than the academic verticals, this does not bode well for the later.
After all, left to itself OpenAI/Gemini/Perplexity Deep Research seems to know how to search PubMed, Arxiv and the usual academic databases and platforms.
A lot hinges, I suspect on how well, you can steer these Deep Research, web search engines to only search and cite "academic content". My early experiments with Perplexity and Gemini Deep Research so far, show this isn't quite possible, and in one example, no matter how I prompted, it would cite libguides or a blog post my collegue wrote. I suspect, Perplexity Deep Research is looking at the domain these content are hosted on and considers edu.xxx domains as academic.
While it is logical to assume that in a academic search scenario, Academic specific deep search tools will always find higher quality results, I have found cases where this isn't true and occasionally Gemini or OpenAI Deep Research finds a totally relevant result their academic counterparts fails for some reason despite being a peer reviewed journal article.
A smaller issue is that the citations of tools that search the general web can be off. For example, Gemini Deep Search, cites papers found on the BMJ and PMC platforms like a webpage not a journal article! Also note, it cites a LibGuide!

Academic only tools that search only academic indexes obviously won't have this issue.
Is still early days, but so far, for academic search scenarios, some of the academic ones particularly, Elicit's seems a bit better at citing more of the academic sources despite most of their sources being accessible directly via the web.
How these tools differ - real-time or pre-indexed

Back in the 2010s, there was debate in the academic library discovery world. The question at the time was what is the best way to aggregate content from multiple academic sources to create a "one search".
On one hand, there was the "centralized index" approach, first introduced by Summon and quickly followed by Ebsco Discovery Service, Primo etc.
In this approach, one would try to preindex content from various sources, creating a normalized central index to search against.
On the other hand, there was the federated "Real-time" search, where one would setup "connectors" to search in real-time multiple sources. See here for a taste of some of the discussion.
Very quickly, the first approach of a Centralized index won out due to the superior speed and stability of such an approach. Trying to federate or search in real time for more than dozen sources was often slow and extremely unstable.
Another argument against centralized index was that real-time federated search would give more timely results. While this argument is true, today academic central indexes like ExLibris's Central Discovery Index (CDI) are so efficient, even newspaper articles are indexed only a few days late!
Even arguments of a hybrid system where you preindex what you can and do real-time for the rest died down quickly as most major content owners agreed to opt into these large growing indexes (e.g. Central Discovery Index (CDI).
See my 2013 coverage of these issues.
Today, we seem to have again the same two approaches, with OpenAI/Gemini/Perplexity using agents to search in real-time multiple sources such as Arxiv, PubMed etc.
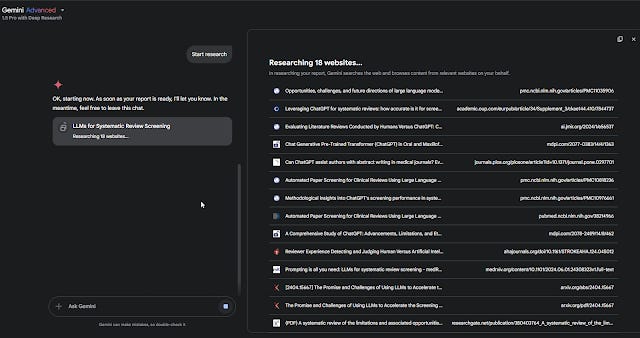
Gemini Deep Research searching multiple sites including academic sites
Again it seems to me the likes of Elicit.com, Undermind, SciSpace, Ai2 ScholarQA that searches their own pre-indexed content (typically something like Semantic Scholar Open Corpus or OpenAlex) should have the edge in terms of speed and reliabity as opposed to using LLMs to navigate and search the platforms!
Still, I can see a hybrid method working, where it would search a preindexed academic source like Semantic Scholar and as a secondary method search somewhere else.
Implication : Academic content/publisher response to this
Regardless of the method used by these "Deep Research" tools, I don't see academic publishers and content owners sitting ideally by as they get popular.
For one, some large academic publishers like SpringerNature and Elsevier are already sending takedown notices of abstracts from closed articles to OpenAlex, Semantic Scholar, and other large aggregators of academic content, and you can notice the impact when you use tools like Elicit.com or Undermind that rely on them and get messages like "abstracts withdrawn".
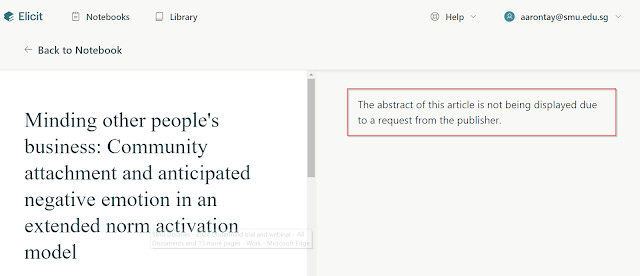
As Bianca Kramer suggests, this is probably due to the impact of the "increased commodification of abstracts - perhaps not surprising given their importance in GenAI." and as publishers sign licensing agreements to AI companies to provide content for training, they will want to protect their IP.
I can't see them being thrilled with the idea of agents browsing and accessing their platforms, given traditionally they have been against text data mining and bots crawling and scraping their sites. One of the reasons given is that such bots cause a ton of strain on their platforms, though some probably hope for institutes to pay more with the claim that the subscriptions institutions sign for are meant for HUMAN use only/
To be fair, towards the late 2010s, many of the big journal publishers like Springer, Elsevier started to loosen up a little on this matter, offering APIs for text mining for non-commerical use (see for example Elsevier's policy for TDM) but one wonders how long this will hold given the developments in AI and even that does not permit browser agent/bots to run.
Already academic libraries are sparring with academic content holders on what exactly can be done with the content they subscribe to. SPARC for example has already noted
Attempts by publishers to insert AI restrictions into licensing contracts appear to be widespread across the U.S. and Canada and across publishers.
Another elephant in the room is full-text availability. Whether you search a pre-indexed central index, or use an agent to search and browse around, you will be limited to full-text of open access papers only.
But, most academic users of "deep research" products will have access to paywalled full-text articles due to institutional access. Right now, many academic systems enhanced with AI such as Elicit.com, Scite.ai, SciSpace allow users to upload full-text to get around this problem, but this is not very automated and secondly as noted above, the legality of such actions is still unclear.
Ideally, we should work towards a system-wide mechanism where our "deep search" systems are aware of our full-text entitlements and are allowed to automatically use them when necessary. This should be a cross-publisher approach similar to Crossref's TDM , SeamlessAccess and GetFTR, but of course as it stands the last two were meant only for humans.
No doubt some publishers might need to be enticed with additional payments from institutions.... but between this and rising open access levels, we may actually start to maximise the power of these systems.
How these tools differ - degree of human in the loop

A major difference between these "deep research" tools and typical retrieval tools is the investment in time you make when you click run.
A typical web search engine like Google Scholar or Google aims to return a response in less than 0.1s. "AI search engines" that use heavier dense embedding based ways of matching and/or retrieval augmented generation to generate direct answers from retrieved answers are a bit slower but still generally take no longer than 5-10s.
"Deep Research" tools, generally take a few minutes at least and depending on the settings can even take up to an hour.
This difference in latency in response makes using such tools a very different experience.
Given how long it takes for the response to take, an obvious idea is for the system to ask clarifying questions before running off to do the job.
For example, both Undermind.ai and OpenAi Deep Research asks clarifying questions.
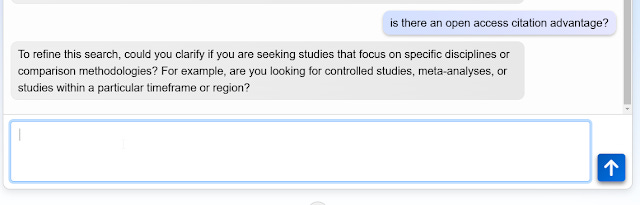
Similarly, SciSpace "deep review" also asks for clarifications.

Gemini Deep Research, goes one step further with transparent and presents a "research plan" that you can modify

Interestingly, clicking on "edit plan" does not allow you to edit the plan directly, but rather you type in things you want to change, similar to Undermind/OpenAI deep research.

This is nice and all, but even with Gemini Deep Research, I have found situations where after I approve the "research plan", it goes off and comes back with a report that is off.
Is there a tool that gives more human in the loop control?
There are two. Firstly, I already mentioned Stanford University's STORM. Recall that by default STORM creates up to 3 three specialized agents playing different roles to discuss and come up with the content.
In CO-STORM mode, you have the ability to join in the conversations with these specialized agents to ask questions and even comment on answers given!

Elicit - Systematic review and Technical Reports - a different kind of "Deep" Research
Yes. Recently Elicit.com launched two new features - "Research Reports" and "Systematic Review"
On the surface, "Research Reports" seems like a typical deep research product focused on academic only content where you can get a long form report with tables with your query.

Elicit Technical Report (sample)
The major difference is that unlike a typical deep research product, Elicit's technical report is built up using a Systematic review proccess!
How does Elicit Systematic review work? Think of it as offering a even more controllable "research plan" where you can intervene at the following points
1. Where are the papers retrieved from?
2. What are the criteria set before a paper is considered relevant? (Inclusive criteria) and how many needs to be included
3. Of the included papers, create a matrix of papers with key findings and other metrics relating to the paper.
With "technical report", Elicit will just automatically go through all the steps (for the first 10 included papers) but you can always go back to adjust steps #1, #2
Elicit.com Systematic Review vs Technical Reports
As at the time of writing, Elicit only offers these two features to the pricy Pro accounts. A Pro account gives you 200 "extractions" a month. With either process, you can do unlimited retrievals that go through step #1 and #2 above and then extract the papers that are included.
However, if you want to generate a full report this will cost extractions.
If you want full control from the very start, you would use "systematic reviews". Here are the steps, first enter your query.

Elicit will evaluate your query and can suggest more specific queries. Say I click on "Outcome measurement" and it suggests to make my search more specific.

Once I have accepted this, the next step asks me where I find the papers to come from.

I can upload PDF, use papers I have already uploaded into the Elicit library and/or the most likely method, just ask Elicit to search and look at the top 500 results.

Elicit has 126M papers from the their extraction from the Semantic Scholar corpus. The main limitation is that you get full-text only from open access papers and will be limited to abstract for others.
Okay so Elicit has loaded up the 500 top results, how then does it decide which of them are relevant?
Most deep research products at this point will just ask the agent to figure it out itself based on your query. This is nice and all but there are many ways to interpret a query.
Elicit because it is based on a systematic review workflow gives you more control. If you are unaware with how systematic review works, you should know you will need to define certain specific inclusion critera for a paper to be considered relevant. So for example, you might say an inclusion criteria is
a) Paper needs to use randomized control trial
b) Be done in a developing country
c) Covers seniors above 65
Elicit allows you to do this yourself of course, but I guess most people would just let it autopopulate the criteria it thinks make sense based on your query.

It even tries out the criteria on a sample of 100 papers, so you can get a feel of how your criteria works out (technically this is called piloting your search).
You can of course change any criteria you disagree with or even add new ones. e.g. you may want to broad or tighten your crieria depends on what you see in the impact.

Next based on the accepted criteria, it will start screening and show you the results.

In the example above, based on the score threshold, 33 papers are considered relevant, if this is too loose you can increase the score threshold so few papers qualify.
The final step involves defining the information you want to extract from each included paper. Similar to the earlier screening step you can create your own extraction criteria, or Elicit can do it for you.
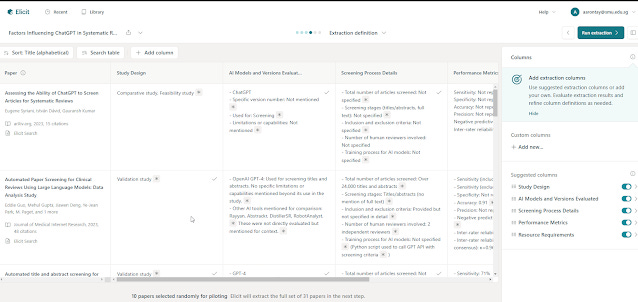
Again Elicit will do it on a sample of 10 included papers, to give you a sense of how it looks like, and you probably should check if the extraction is accurate and refine the instructions to extract if not.
Again if you are happy you can go ahead and it will try to extract from the remaining included papers.

The final step is the generation of the report, this oddly enough does not allow any human input.

While all this sounds amazing in terms of control, too much human in loop takes effort, and some might feel defeats the purpose of an automated system!
Take even the relatively lightweight practice of asking for clarifications. Perplexity CEO actually notes Perplexity was one of the first to actually ask clarifying questions if needed but was turned off due to negative feedback.
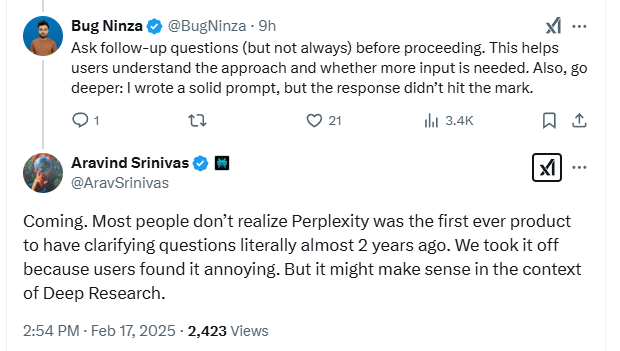
Interestingly, even Elicit's systematic review only gives you control for the search process, and once it has found relevant papers, you have no control over the generation process!
Currently, if you want full control over the generation process, you want rely on "Ai writing
tools like SciSpace AI writer, Jenna.ai and even OpenAI's GPT4o with Canvas are "human-in-loop" for generation
Conclusion (with the help of Gemini 2.0 Flash)
So, where does this "Deep Research" thing leave us? After diving into OpenAI's Deep Research, Gemini's and Perplexity's equally named counterpart, as well as the more academically grounded efforts like AI2's ScholarQA and Elicit's offering that offer more human-in-the-loop Systematic review workflows and even the interesting historical precursors like STORM (and yes, I'm still debating if Undermind and PaperQA2 really fit that label), a few things become painfully clear.
First, the hype is real, but the devil, as always, is in the details. At their best, these aren't just spiffed-up RAG systems; the agentic element run using state of art frontier models like o3, while slow and computationally expensive, promises to unlock a new level of complexity. But the "Deep" isn't just about longer runtimes, it's about a shift in the kind of output: from snippets to syntheses.
And here's where things get really interesting. Given how long these reports take to generate, questions arise about how much guidance and control should be given to humans and how much should be in the hands of the agent. The black box "give me the report" approach of the original OpenAI offering (with one clarification) , differs somewhat with Gemini's presentation of a "research plan", and even more dramatically with Elicit's "systematic review-lite" workflow.
The real question, though, is how sustainable this is. Will academic publishers, already twitchy about their content being used to train these models and being scraped for abstract for RAG search (which is affecting academic systems using preindexed sources like Semantic Scholar), now tolerate agents endlessly browsing their sites? I suspect we're on a collision course. And speaking of sustainability, the dependence on open access full-text is a gaping hole. Are we really content to let the research landscape be shaped by what's freely available? Sure, some solutions currently offer "upload a PDF" as a solution but the legality is unclear.
We need to think seriously about a system-wide solution—something beyond piecemeal agreements. Can we create a mechanism where these "deep research" tools can intelligently and legally access the content our institutions already pay for? Maybe Crossref TDM or GetFTR/SeamlessAccess type infrastructure (but for bots!), and yes, potentially needing to pay publishers for the privilege? It might be the only way these systems truly unlock their potential.
Ultimately, while these are exciting times, I remain cautiously optimistic. We've seen promising tools come and go before. The real test will be whether these "deep research" tools can deliver on their promise of truly accelerating research without reinforcing existing inequalities, creating new legal minefields, or breaking the bank. It's up to us, as librarians and information professionals, to make sure they do. Or at least, to ask the hard questions along the way.