


Things I am still wondering about generative AI + Search in 2024 - impact of semantic search, generation of answers with citations and more..

Earlier related pieces - How Q&A systems based on large language models (eg GPT4) will change things if they become the dominant search paradigm - 9 implications for libraries
In the ever-evolving landscape of information retrieval and library science, the emergence of large language models, particularly those based on the transformer architecture like GPT-4, has opened up a Pandora's box of possibilities and challenges.
As someone who first started playing around with GPT3 in 2020, I started focusing even more on large language models especially focusing on the concept of Retrieval Augmented Generation (RAG) in 2023.
My journey has been a blend of academic rigor and tech enthusiasm, combing through research papers, absorbing insights from YouTube videos and Substacks (Cameron R. Wolfe's pieces are particularly enlightening, such as this one on AI powered/Vector search though requiring some technical understanding), and exploring the blog posts of companies like Vespa.ai, Pinecone, Cohere, Hugging Face, LlamaIndex, Langchain that provide frameworks or search infrastructure for running RAG.
Still, there are many things I wonder about and most of them are not relating to technical issues.
1. Will Academic search engines producing direct answers with citations be the norm? What are the implications? Will it slow down open abstract and open scholarly metadata movement?
As I look at all the new "AI powered academic search" (see my list) features , whether those added into existing academic databases like Scopus, Dimensions.ai, Primo or from brand new search engines like Elicit.com, Scispace etc, the most common feature by far is the system generating a direct answer to the query backed-up with citations from multiple documents.
This is not a particular technique used by academic search, everything from Bing Chat/now Copilot, ChatGPT+ (including the older plugins and Custom GPTs) , even Google's Search Generative Experience all use the exact same technique.
This as I have blogged many times already is build on the paradigm of RAG and typically involves a two stage process of
Retrieving documents or more usually chunks of text (context) that might be "relevant" to answering the question (typically relevant chunks are identified using vector or embeddings based similarity search)
Feeding the chunks of text /context to a Generative AI model like GPT3.5 or GPT4 with a prompt to answer the query using the context found
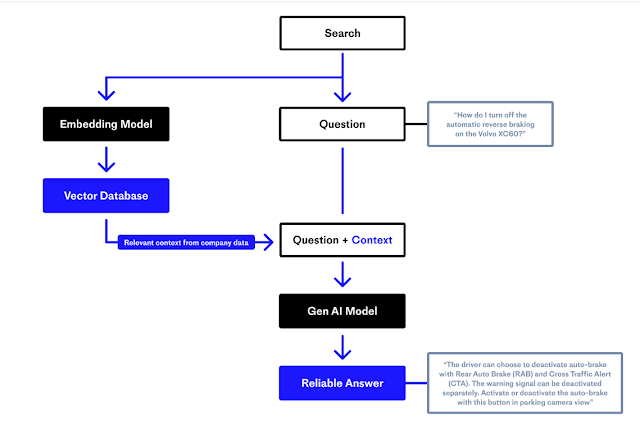
https://www.pinecone.io/learn/retrieval-augmented-generation/
From the information literacy point of view - I wonder if most users will automatically trust the citation and will not verify.
Some tools help with highlighting of contexts that were used to generate the answer which makes it easier to verify but many do not.
It is important to note that unlike generated answers and citations from asking a pure large language model alone, answers that are generated using RAG will almost always generate real citations that were found by the search.
However, there is no guarantee that the generated statement and the accompanying citation will match. In the technical literature this is sometimes called citation faithfulness etc.
Below shows an example from Scite assistant, where the generated staments and citations do not match.
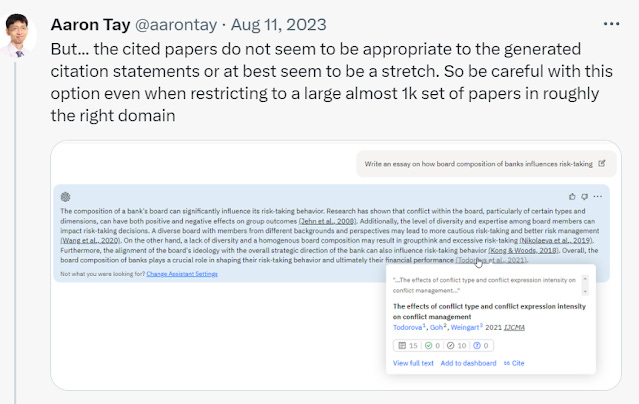
scite assistant generated statement and citations do not match
I've notice this problem gets particularly bad for systems where they are no context that can answer the question (which occurs more often if you can restrict what the system can cite like in scite.ai assistant) and this tends to force the system into a corner, where instead of refusing to answer, it tries to force fit a citation into the generated answer, leading to poor citation faithfulness.
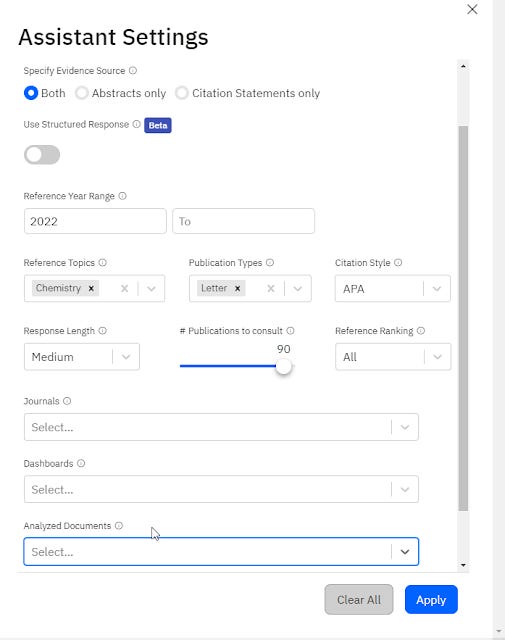
with Scite assistant you can force citations to come from very limited set of papers, above forces it to cite only letters in Chemistry from 2022!
This has been verified in many studies, for example in a recent study, they mantipulated the context to be sent to the generator, all documents that did not answer the question. The generator was prompted to reject the question, if the context it found did not answer the question. This is called the negative rejection test and hopefully these Q&A systems will refuse to answer.

For example, this is an example of Scite.ai assistant refusing to answer, when forced to try to answer a query with no good context/documents found.
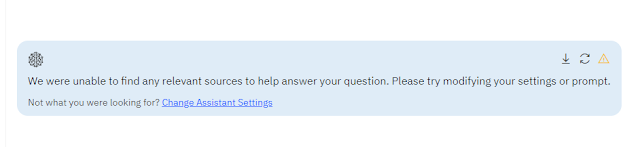
Unfortunately, this isn't that common.
In the above study, despite being instructed to not answer if no context answered the question, the generator still tried to answer most of the time and failed to reject the answer. Using ChatGPT as the generator model it rejected or refused to answer only 25% of the time!
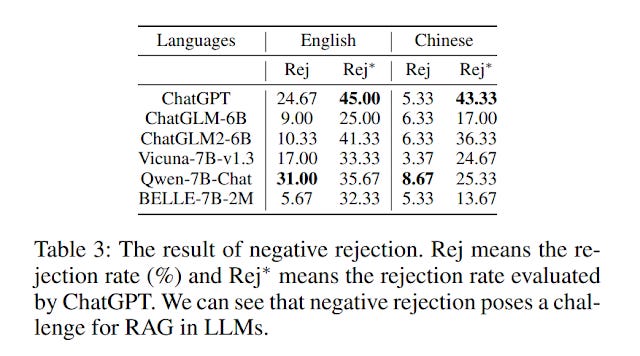
Though the study above was searching through news stories this applies to academic search too.
A related problem is when "backed into a corner" with no good context that answers the question a RAG system which still "decides" to generate statements that have faithful citations, in which case the generated statements do not seem to answer the question, resulting in poor "answer relevancy". This is a less serious issue since humans can clearly see this happening.
All this is covered in my talk here which also points to another worrying emperical finding , that people tend to rate generated answers that have a low citation accuracies (whether recall or precision) with high fluency and perceived usefulness.
This makes a lot of sense when you think about it, but is still extremely worrying.
In fact there is a lot of research emerging since 2022, that pretty much shows the numerous reasons RAG can fail (e.g. difficulty of combining information from multiple context, reranking issues) and a bewildering series of proposed techniques at all parts of the pipeline to try to mitiage this from both academic and industry sources.
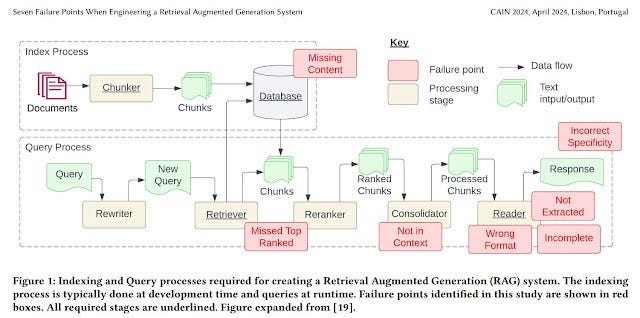
Seven Failure Points When Engineering a Retrieval Augmented Generation System
Want to do some technical reading on the issues, here are some
Benchmarking Large Language Models in Retrieval-Augmented Generation
Seven Failure Points When Engineering a Retrieval Augmented Generation System
Evaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering
From the point of view of a supporter of Open Scholarly metadata and Open Access, one also needs to realize that the value of Open Acesss full text has increased. This might lead Publishers to push up the price to make publications Open Access.
One commenter even suggests
The companies could also pull back from OA altogether, to keep a larger share of exclusive content to mine.
This is the flip side of naive proposals like this librarian who wonders- Are we undervaluing Open Access by not correctly factoring in the potentially huge impacts of Machine learning?
But one need not even go into open access to worry about implications of Openness. While being able to extract answers from full-text is clearly ideal, it is very computationally expensive (even now I think only Elicit does so for open access papers, Scite assistant uses a subset of full-text ie. the citation statements from partners) and no one source (except maybe Google Scholar!) is likely to have a comprehensive set of papers.
But this is not true about abstracts. As I write this, Scopus AI is launched out of beta and their generated answers are extracted only from abstracts. Their rival Dimensions' equalvant AI assistant I believe does the same.
Clearly, you can extract quite a lot of value just from abstracts!
This does not abode well for the people behind the push for Open Scholarly metadata, in particular the Initative for Open Abstracts (disclosure I am a signatory of this group). While there has been some progress to convince publishers to make abstracts freely available and Open in a machine readable format, progress has been slower than her sister movement the Intiative for Open Citations.
While that fight for open citations was eventually won, Elsevier was one of the last major publishers to give it up and make their citations open. Why were they dragging their feet? The obvious guess was that Elsevier was aware doing so would enable the creation of more compete citation indexes based on open data, which would reduce the value of their citation index product Scopus.
Would the same calculations but this time with open abstracts and AI generated answers lead to the same issue?
2. Will Academic search engines use Semantic Search as a default? What are the implications?
The potential shift from lexical keyword searches to semantic search in academic search engines might seem subtle and less interesting than the ability to generate a direct answer, yet its implications are vast.
I won't recap the differences between Lexical keyword search (or even Boolean) and Semantic Search also known as vector/embedding based search, see
Boolean vs Keyword/Lexical search vs Semantic — keeping things straight
Sentence Embeddings. Introduction to Sentence Embeddings & Sentence Embeddings. Cross-encoders and Re-ranking
This change suggests a move towards interpreting the intent and context of queries, rather than merely matching keywords.
It is important to realize that a system can implement semantic search/emedding search and yet not use RAG to generate direct answers over multiple document (for example as of now, JSTOR generative AI beta has semantic search but does not generate direct answers over multiple documents). It is even possible for a system to do RAG without doing Semantic Search but this is less likely. This could be done for example by asking a LLM to translate a query into a Boolean query, and then run it through a conventional search to find relevant abstracts. CoreGPT is an example of this.
If you are like me who has been asked to try cutting edge "Semantic Search" tools for over a decade, this feels like just hype. I was also skeptical initially when I saw earlier adopters claim tools like Elicit had better relevancy ranking than Google Scholar but in the last 2 years, I kept running into situations that made me realize there might actually be a real improvement here.
Part of the reason why it is hard to notice this improvement is that usually, standard keyword or lexical search works pretty well. Also two decades of searching using keyword has trained us to a) search in a way that masks the limitations of keyword search and b) lower our expectations of what is possible when we should demand more (e.g. search for very specific things) and have higher expections (on what counts as a false drop).
Currently, I am testing a tool called Undermind that claims to outperform Google Scholar by x10, however did only applies if you search with very specific requirements of what should be included and what shouldn't be.
Take for example, a recent challenge I had, I was looking to find a study referenced in a news story, and as typical in such things, the exact study was not referenced and only certain findings was mentioned.
It took me a long while to finally confirm the study based on the clues in the news story. This was despite using tools like Google Scholar (which had indexed the full-text of the study).
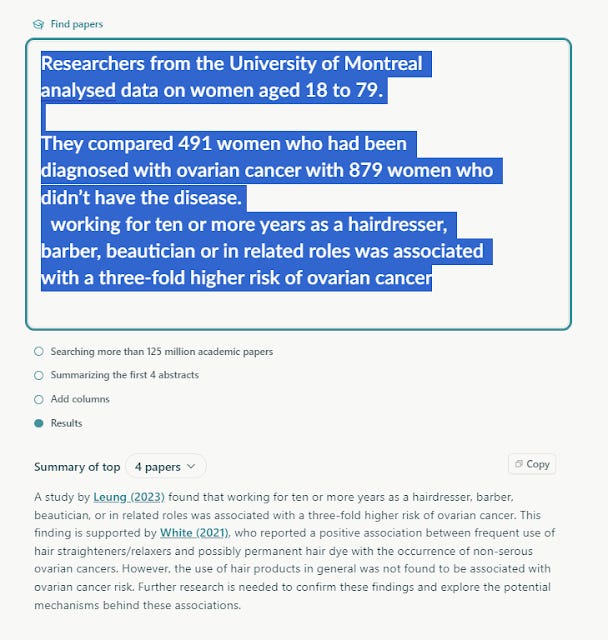
I then realized that what I could do was to just copy and paste long text chunks from the story that described the study for example the following chunk
Researchers from the University of Montreal analysed data on women aged 18 to 79.They compared 491 women who had been diagnosed with ovarian cancer with 879 women who didn’t have the disease. working for ten or more years as a hairdresser, barber, beautician or in related roles was associated with a three-fold higher risk of ovarian cancer
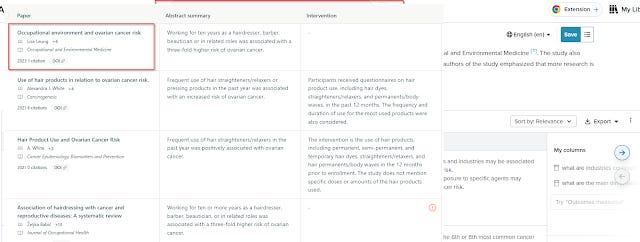
and throw it into a system using semantic search (vector based/embedding search) like Elicit.com and SciSpace and the very first result - Leung (2023) was the correct study!
Note : I am not saying it is NOT possible to find the paper using keyword searching. For example, I was initially tripped up by Google Scholar, because here it's size and index of full-text worked against it and a simple keyword of say the occupations + cancer gets you a lot of results and because of it's weighting algo that favours higher citation and hence older papers, you would never find the needed paper, unless you were smart enough to guess the cited paper is likely to be new! Ironically the search is probably easier in a title+abstract only database like Scopus!
And as a nice side effect, the papers after the first paper were semantically similar.
I remember years ago in the late 2010s to early 2020s, trying tools that encouraged you to type in long sentences describing your topic and it would use "Semantic search" to find relevant papers. On hindsight these tools were probably using the earliest BERT type models or possibly even GPT - GPT2.0 models but I remember not being super impressed by them.
To clarify what is happening, I wasn't just lucky with the choice of these text chunks, I could paste more or less or even different chunks from the news story describing the study and it would still work almost all the time!
Technically search engines like Elicit or Scispace typically will have some maximum character limit for a query so it may be that beyond a certain length it might ignore everything beyond a certain length but I did not test for this.
Why? Because the search wasn't actually doing a keyword or lexical match but a similarity match in semantics and the meaning of the query is more or less similar even if you vary a little the text chunks used, and I believe it will almost always rank some paper as "most similar"
Prior to this I was actually copying single sentences with what I told was unique information like <topic> + sample size of control and test sizes etc into Google Scholar and I just couldn't find the paper despite it being indexed full-text. Searching keyword style by dropping stop words didn't help either.
Essentially the wording in the new stories are so paraphrased that Google Scholar has trouble matching them unlike a actual semantic search system. This and the fact that Google seems to perform better (see later) gives us a hint that Google Scholar is still mainly a lexical search system.
Made me curious if I got lucky, so I tried the same thing over a few news articles that go "A study found....". Firstly, I noticed that for the most recent news stories it would usually be referencing a very new paper that was not indexed in tools like SciSpace but leaving that aside it worked almost all the time!
Interestingly, I found that Google itself performed much better than Google Scholar when you entered long chunks of text. Given we know Google also uses BERT (since 2019) , this explains why it can find the study.
That said, using Google was not as good because often it would rank other news stories that referenced the same study before surfacing the actual paper or even just fail and list only those news stories. This makes sense because news stories that reference the research article are probably more written in a more similar style than the actual research article!
This evolution in search technology brings new challenges in search methodologies. It raises questions about the most effective way to search: Should we rely on keywords, natural language queries, or even complex prompts akin to prompt engineering?
Keyword style : Open citation advantage?
Natural language style : Is there an open access citation advantage?
Prompt engineering style : You are an expert in academic searching with deep domain knowledge in the domain of Open access. Search for papers that assess the evidence for the existence of an open access citation advantage.
As far as I know there is little to no formal study on whether a keyword style search or a Natural language style way of searching is superior particularly in a new Semantic Search style search engine.
Theory suggests that because Semantic Search can and does take into account order of words etc, you should search in natural language to take full advantage of this and not drop stop words in the way keyword style does.
For what's it's worth Elicit does indeed suggest it is better to type in natural language, particularly phased as a question.
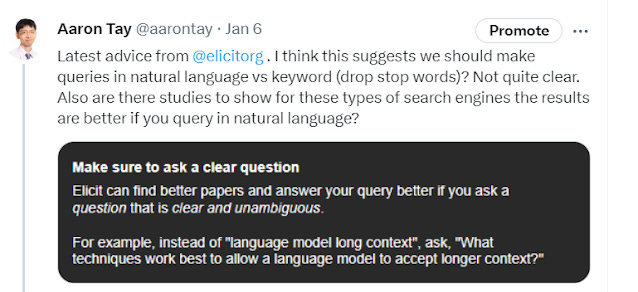
When queried further, Elicit Machine Learning engineers made a further interesting clarification, that does so not only helped the generation of a direct answer with citations (known as summary of top 4/8 papers in Elicit) but also the ranking of papers found.

I've noticed that for many of the newer AI powered search engines, including the new Scopus AI, the examples you see all use natural language queries....
Going even beyond natural language searching, with the increased use of ChatGPT and similar chat style interfaces, we may be seeing a generation of users who are used to doing prompt engineering! Would it be productive to do it for new AI powered search?
For this, I think it's much clearer.
In general there is a distinction between
a) Search engines that only searches and uses Large Language Model capabilities to do things like rank results, generate answers with RAG etc
b) a full blown Large language model (typically generative, autoregressive decoder/GPT type) where search is just one of its capabilities or tools. These are sometimes called "Agents" (if they have unlimited number of steps) which can choose to generate text or use tools it is capabilty of using.
About agents: A standard RAG pipeline tends to have a fixed number of steps but an "agent" is given more autonomy, eg in the context of searching to answer questions, it may be allowed to "reason" and decide whether to stop searching or continue searching to get more information, while a standard RAG pipeline would tend to be more predictable.
Essentially, you can tell the difference between the two by trying to have a general conversation or asking the system to try to do different tasks like telling jokes, summarise text etc. If it does so it is the latter type.
Essentially if you are basically a search engine (the former), prompt engineering will not work. Examples of this includes Elicit.com, SciSpace. Non-academic example is perplexity.ai
However, if you are a LLM that can but does not always search, prompt engineering techniques might work. A academic example is Scite.ai assistant, non-academic examples include Bing Chat, ChatGPT+, various GPTs and plugins.
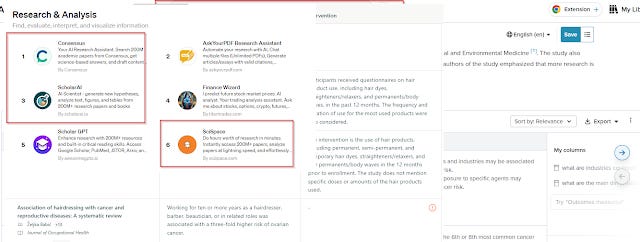
Custom GPTs that search including Consensus, Scispace, Scholar.ai etc
In a sense, search interfaces will help to reduce confuse on how to search by just giving examples of expected types of input and users should just follow these cues.
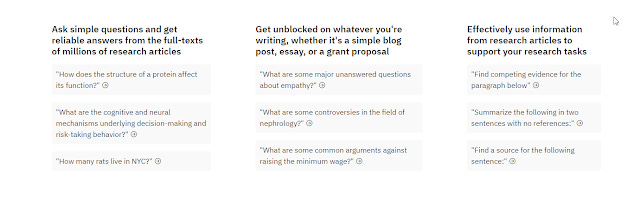
scite assistant giving examples of prompt that you can use, showing it is not just search
The implications for this shift is pretty obvious.
First given our heavy focus as the people who need or know how to search, we need to quickly reeducate our librarians on what Semantic Search means, how to identify when one is being used (or at least know enough to know what to ask our vendors) and how to change our search style when necessary.
I also think given that there are now three potential ways to obtain results - Lexical search, Semantic Search and Citation searching, there could be interesting ways to expose these three capabilities in the search interface. For example, being able to decide when you want to run a precise Lexical search only or when you want to add results from Semantic Search strike me as useful function. Ideally, these set of results shouldn't be "mixed in" but each "layer" would show the new unique results found.
Secondly, evidence synthesis librarians who are worried that lexical keyword style searching (and even Boolean search which is a subset) might go away in favour of Semantic Search should be able to not only articulate the weakness of Semantic Search compared to lexical search but show evidence of this.
For example, the obvious strength of lexical search vs Semantic Search is that the former lacks control.
This isn't just a theorical issue. For example, if you look at both Elicit and Scispace which both implement Semantic Search, you see this filter which allows you to filter down to keywords.
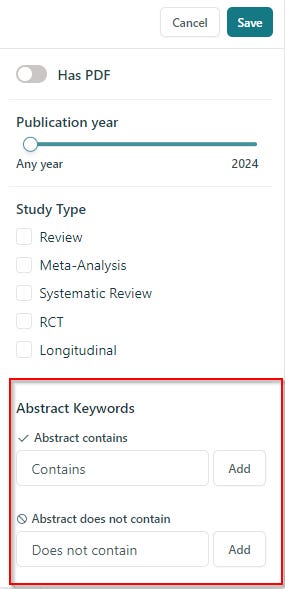
Why do you need such a function? This is because by default, the search is semantic and it may surface papers that don't have the exact keyword you want. This can be important if you are looking say for an exact gene, technique etc and you don't want the Semantic Search giving you closely related terms.
This shows clearly the weakness of Semantic Search.
Whenever I give talks about Semantic Search, I get worried evidence synthesis librarians worried that search databases will eventually remove traditional search functionality in favour of only Semantic Search.
In fact, I believe currently a common industry practice for such "AI search" tends to be to run both Semantic Search AND traditional lexical/keyword search (often with BM25 algothrim which is a slightly improved version of TF-IDF), combine the top few results from both methods and then rerank for a final listing so in many of these searches you might get a combination of both sets of results. So the fear is more the functionality is likely to be there, but it may not be independently made available?
I suspect though Semantic Search can become the third major technique , next to keyword searching and citation searching that can be used to help improve recall and precision for evidence synthesis searching.
At this point, it's still unclear how much Semantic Search techniques help more once you have done proper keyword searching AND citation chasing, but this is an interesting area of study (hint : I am interested in working on a study on this).
3. What will be the business model for established players and new entrants?
Business dynamics is an area I am very naive about but even I know many of the smaller players will be acquired by bigger ones probably publishers. While the smaller startups might be more agile and have a lead from starting earlier and having more refined systems (RAG refinement is more an art than science at this point and the earlier innovators like Elicit have more feedback from earlier adopters), they are not necessarily going to come up on top. This is particularly so when the bigger publishers have advantages in terms of access to large pools of meta-data and full-text beyond open sources.
But the main thing I am wondering is about the pricing model.
I understand that unlike typical IT systems or even conventional search systems, where the marginal cost of running a query is relatively low or even near zero, with the current AI powered search the cost of running each query is relatively high due to the need to make Large Language Model calls. Whether companies use OpenAI APIs or use their own opensource models, each search is going to cost $$$.
This might be why Elicit and Scispace are currently doing a charging model by usage. If this model applies to institutional access this would make things somewhat tricky as librarians will have to deal with allocation of credits/usage.
As a librarian, I am reminded of the time in the past early 2000s (slightly before I joined the profession) when it was common for systems to charge by time or usage like Dialog systems. Because searching online was so costly, librarian did mediated searching and searched on the behalf of users which feels unthinkable in today's world.
We could of course give a fixed quota per user but this would still be a big adjustment for users. Because we are used to living in a world where search queries are essentially free, we get very sloppy and inefficent with searching doing more iterative searching than precise controlled searching...
I would like to say this might push users back to carefully crafting and running nested boolean search strategies, but I think by now the ship has sailed and nobody but evidence synthesis librarians and librarians doing search demos in freshman classes do that. Plus, I'm pretty sure boolean functionality isn't even in tools like Elicit!
Of course, as times goes by, technology costs will get cheaper and eventually we will eventually get back to the current "all you can eat" model but for now one wonders how it will work?
Or will be the big players like Scopus be able to absorb the costs and give such "all you can eat" models to institutions?
4. How useful will all these new features be?
I believe the current knee jerk reaction of many librarians eg information literacy librarians is to warn against AI powered tools because they read that generative AI tools "hallunicate".
On the other hand, many of the people I speak to who create these new AI search tools, generally take it as an artifact of faith that the error rate of their tools will naturally reduce as large language models improve from year to year.
Of course all this is just an article of faith, LLMs could hit a plateau (for example Google's DeepMind Gemini models don't seem to be much better than GPT4 has led some to speculate we might have hit a plateau) or even if LLMs improve they may not translate to aims for the RAG type capabilities (though I think this is unlikely).
My wild speculative view is the ability of systems to extract direct answers with citations in short paragraphs will probably be less impactful than expected at least for academic use.
It seems to me after playing with these tools for longer than many, I find typically you tend to run into two situations. Either you already know the domain well, in which case, the system's one paragraph direct answer is likely to be clearly inferior to what you know.
I find many of these systems even on the best of days when they cite relevant papers don't quite choose the ones I would cite (when there are many close alternatives) or would cite a paper for odd reasons that no human would. But i think this can be fixed.
On the other hand, if you are new to a domain, you can't trust what is generated and even if you CAN, you probably won't because you need to read and internalize the knowledge yourself, so at best it gives you a start.
But of course if the technology progresses to the point you can ask it to write VERY SPECIFIC and GRAINULAR one page reviews that you can dump into a study all bets are off...
Conclusion
This like many pieces I have written in the past is as I expect going to read very cringy and dumb a year or two from now. But it is nice to pen this down to capture my thoughts on this subject as of 2024.