
Using Large language models to generate and extract direct answers - More academic search systems - Scite Assistant , Scispace, Zeta Alpha

As expected more academic search engines are starting to adopt the near-human Natural language understanding and natural language generation capabilities of Large Language Models. This seems to be done in two main ways.
Firstly, it is used to help generate direct answers to questions. Secondly, where in the past the human researcher would skim the paper quickly looking for specific nuggets of information (e.g. methodology, sample size, limitations, dataset used), the newer academic search systems are utilizing large language models to extract and display this information upfront in the search result page for comparisons purposes. In fact, such capabilities can also be used to extract association or causal links between variables from papers which then can be indexed and browsed or searched through (more on that in future post)...
There is a third way, relating to how transformer-based embeddings allows really great relevancy reasoning that goes beyond pure lexical/keyword search. Under the hood, Elicit.org and some other search engines use this method sometimes called semantic search or neural search or possibly a hybrid algo of both methods. See section on Zeta Alpha below for more details
My blog posts in the past might be useful as well to set the context.
Q&A academic systems - Elicit.org, Scispace, Consensus.app, Scite.ai and Galactica (Nov 2022)
4+1 Different Ways Large Language Models like GPT4 are helping to improve information retrieval (Apr 2023)
In this blog post, I will cover relatively major updates to Scite Assistant, Scispace and Zeta Alpha and discuss similarities and differences in interfaces and suggest where things might be going in this space.
Not yet covered in this post, are the ChatGPT plugins like ScholarAI or Biblilography Crossref that use APIs from Semantic Scholar, OpenAlex, Crossref etc to pull in search results for use with ChatGPT
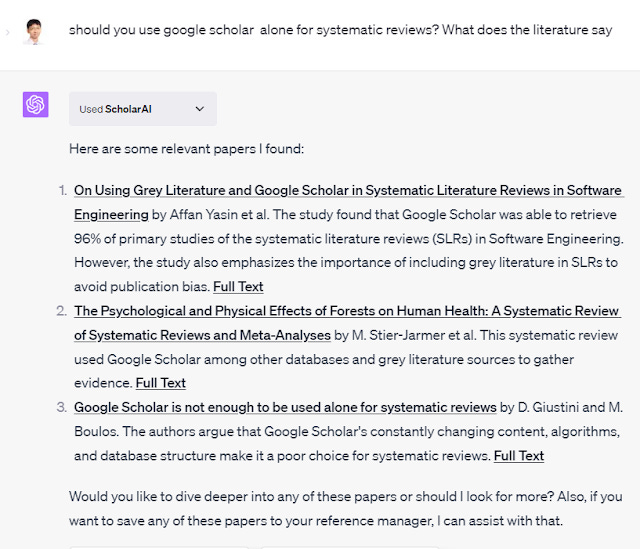
ChatGPT using ScholarAI plugin to generate answers
Scispace - gets generated answers from top 5 papers
When I first covered Scispace, in Nov 2022, it had a copilot feature where you could query selected papers (typically open access papers indexed by the system) with natural language prompts. You could not only ask the copilot to explain highlighted text from the paper but you could even ask it to explain tables and figures!
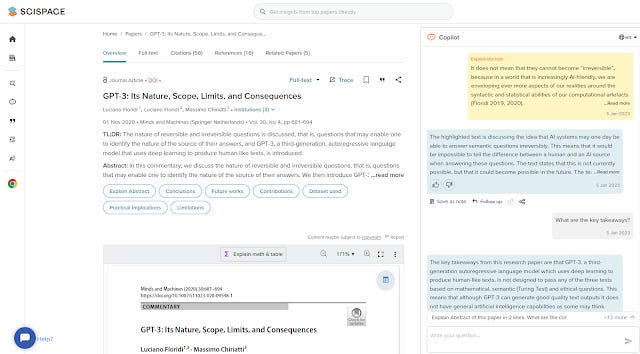
Copilot feature in Scispace
It was otherwise a typical academic search engine displaying results in the usual way. There has been a big update this month that adds on further to the feature set.
First off , if you go to the Scispace Literature Review page (the original Scispace search interface should exists and is default) and enter a query you get direct answers summarized from the top 5 ranked papers.
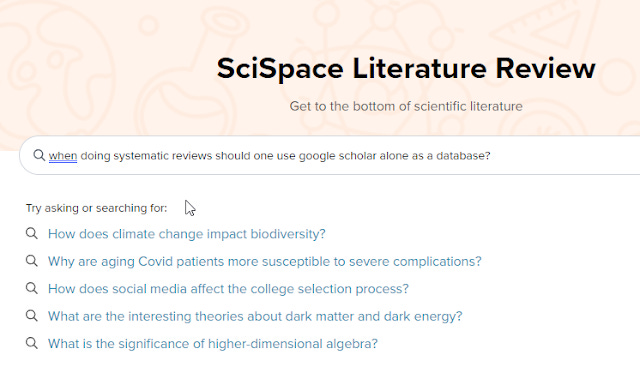
Scispace Literature Review page
In the example below, I queried "when doing systematic reviews should one use google scholar alone as a database?"
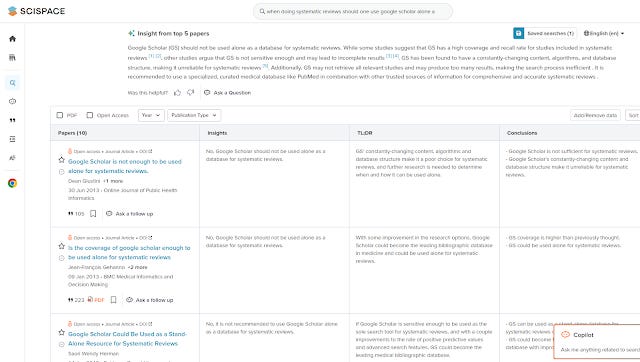
Generated answer from top 5 papers
Scispace calls this "Insight from top five papers" but it is basically similar to the answers (typical a paragraph long with a few citations) generated from Elicit.org, Consensus etc.
On top of that, the search engine results display is totally revamped. You get table of results, where each row represents a paper, with default columns for
"Insights"
"TL;DR"
"Conclusion"
How is such data extracted? Though Scispace doesn't say, its likely that most of it is obtained via Language model prompting of the article (chat with article).
It's hard not to notice how similar Scispace's interface is to Elicit.org, including the fact that you can "star" relevant papers and "show more relevant papers" and/or "remove unstarred".
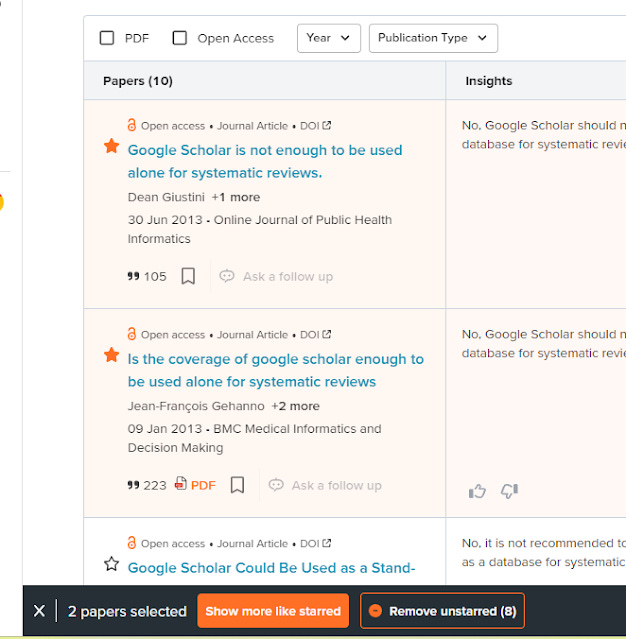
"star" relevant papers and "show more relevant papers" and/or "remove unstarred" in Scispace
We are not sure how the "show more like starred" works, though if it is similar to elicit.org this is simply done via adding citations from starred papers (both forwards and backwards).
That said Scispace's interface has some differences from Elicit.org.
Firstly, while like Elicit.org you can add or remove existing columns, in Elicit.org you are not restricted to just predefined columns.
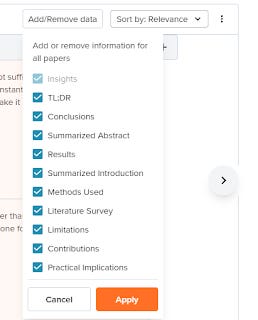
Predefined options in Scispace
For example, in Scispace you can add columns for
Results
Methods used
Limitations
Contributions
Practical implications
but you cannot create new columns on the fly like in Elicit such as dataset used. (Also the predefined columns in Elicit seem more granular and helpful)
More importantly, when utilizing such tools to extract information, we should not 100% trust the extracted answer. In Scispace, there is no current way to verify if the extracted information is correct.
With Elicit.org clicking on each piece of information gets you to the sentences which are used to extract the answer.
This and some other features that I find useful in Elicit.org like the ability to filter to systematic reviews, limit to keywords (because by default Elicit uses semantic search) are why Elicit is still better for me currently.
Still, I suspect Scispace will probably get similar features fairly easily.
Quick summary of the new scispace
Overall, the new interface and features of Scispace look promising. Of course, at the end of the day, the success and failure of such tools will be on the backs of how reliable and accurate such systems are at ranking and extracting information.
For example, to extract information on say "methodology" might involve a ton of careful decomposition and prompt engineering testing.
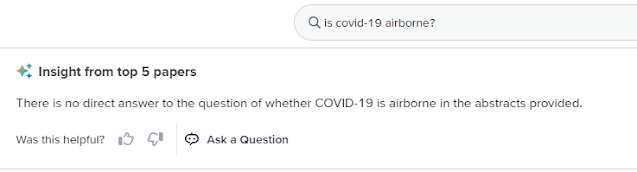
Also, while testing I noticed the following in response to a straightforward "Is Covid-19 airborne", which is odd to say the least.
Scite Assistant evolves- More from extractive to generative answers with more control
scite.ai is a fairly new and innovative citation index service that has been mentioned multiple times on this blog - as far back as 2019 when it first launched.
Currently available as a freemium service, scite's main unique selling proposition is that it classifies citations into three types, mainly "mentioning", "supporting" and "contrasting" cites using deep learning To do this it collects the citation statements/citation contexts or citances of papers to train on and classify using supervised machine learning (see technical paper)

Scite - what is a citation statement
As of June 2023, while there are other similar systems classifying citation types such as Semantic Scholar, Web of Science (pilot), scite is still by far the leading system in terms of size of index and citation statements available.
Besides citation classification types, the fact that they have probably the largest set of citation sentences available allows them to launch a specialized search mode that search and match only results in the citation context (this is defined as sentence before and after the citation statement) as opposed to full-text.
As I noted before citation statement searching is a promising new search technique
The Citation Statements often mention claims or findings of papers as stated by other researchers,and by limiting our search within it, we are getting an extremely focused search which at times is even better than an unlimited Google Scholar full-text search. Often it may even immediately give you the answer you are looking for.
I even marveled that such a search sometimes gave better results than a straight Google Scholar search. But if a search can "even immediately give you the answer you are looking for" isn't that suggestive of a basic or crude Q&A search? Could it be extended to be a real Q&A system?
And indeed scite.ai announced a new Q&A mode in Nov 2022.
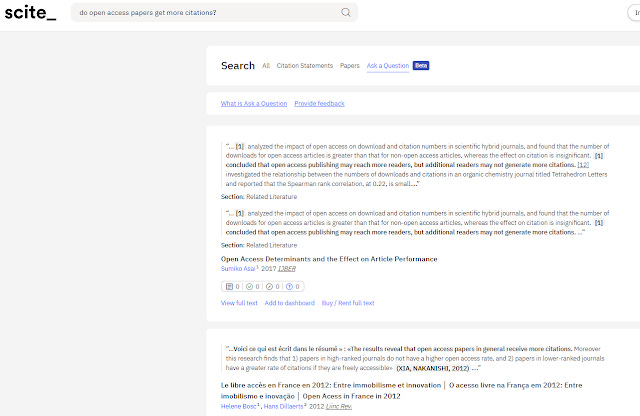
scite - example of Q&A function
This Nov 2022 Q&A function may look like the function in Elicit and Scispace but there is a significant difference. Unlike the former two, scite Q&A only "extracts" text verbatim from papers (title, abstract and citances) to try to answer the question, rather than paraphrase and generate answers.
As I covered about this Scite Q&A function at the time , this is the difference between extractive and generative answers.
This is akin to how summarization tasks consist of Extractive vs. Abstractive Summarization, where the former extracts text verbatim, while the latter will paraphrase or generate answers.
However, by Feb 2023, scite.ai shifted to producing purely generative answers using the ChatGPT (ChatGPT-3.5-turbo at time of writing) and now produces "full" answers using the brand name "Scite assistant".
As of now Consensus.app is the only academic search system I know of that still does extractive answers
scite assistant
The question then becomes is Scite assistant basically the same as Elicit.org, Scispace in generating answers?
The first major difference is often touted by Scite.ai, which is that unlike Elicit.org or Scispace, Scite.ai has partnerships with publishers which gives them access to content behind paywalls (See list of partners including Wiley, Sage, Cambridge University Press) on top of all the Open Access content available that Elicit.org has available via Semantic Scholar corpus.
It is important to note that in today's world - most academic articles have openly available scholarly metadata including title and probably abstract. The tricky bit is full-text , where the % of full text available via Open Access is rising and may hover at 50% depending on the discipline and years in question.
That said, systems like Elicit.org etc use the full-text of OA papers to generate answers while scite relies purely on citation statements/context (both of course use title, abstract as well) which is a subset of the full-text, it's unclear to me if only generating answers from citation contexts as opposed to full-text is a net positive or negative.
For example, imagine if I ask a question about the limitations of papers studying say effect X and there are three such papers. All three are open access and the answer can be found in the limitation section of the paper and let's assume these are very new papers and have no citations to them. While systems like Elicit.org (or even non-academic systems like Bing Chat or ChatGPT+web plugins) would certainly be capable of looking into the full-text and extract the answer it's not so clear to me scite assistant could since it doesn't have access to all the full-text exactly, but only abstracts and citation sentiments/context.
Or is this a far sketched scenario since the limitation sections would almost certainly have citations and the citation context would capture the limitations of the paper?
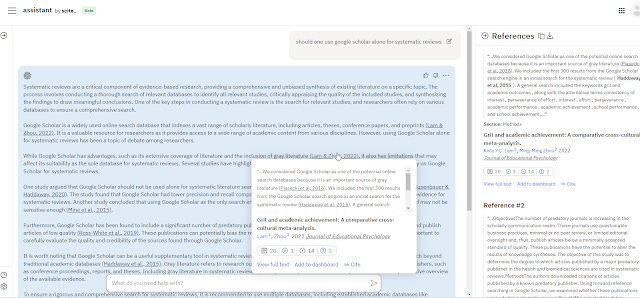
scite assistant cites answers from abstracts and citation context
Of all the academic related tool that produce generated answers, scite in my view currently has one of the best and most customizable interfaces for generating answers.
For example, I love the fact you can see what searches are being run to provide context for ChatGPT to answer the question. This is a very nice feature I liked in Bing Chat. Since this gives you some clues on what went wrong if the generated answer is bad. (i.e. Did the search just fail to find relevant results).
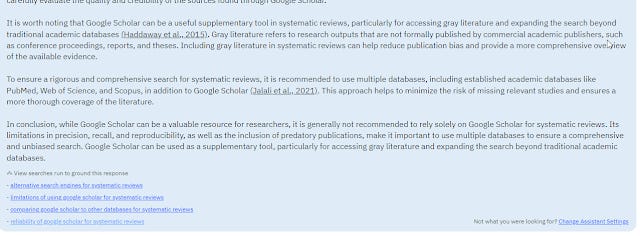
scite allows you to "View searches run to ground this response"
I also appreciate that mousing over citations shows you the text that was used to generate the answer. Allows you to verify the accuracy of the generated sentence against the text used. This is far better than just a link, and it's unclear which text was used to help generate the answer. This is very similar to a feature in Perplexity.ai
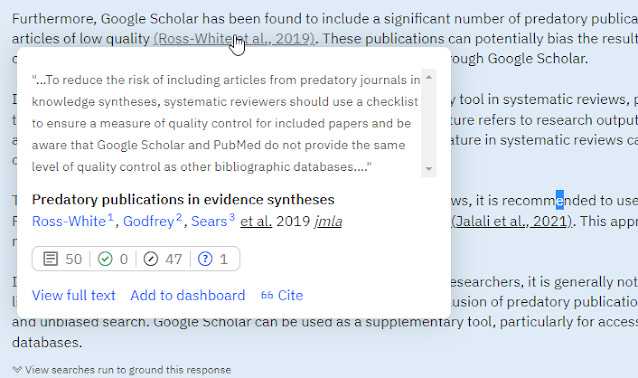
scite mouse over shows text from citation to text (abstract) used to generate the answer
My own personal issue with this is that if the citation is generated from an abstract , it is clear to me how to interpret the answer. However, if you mouse over the citation and it shows some citation sentence or context it gets really confusing for me.

scite mouse over shows text from citation to text (citation statement) used to generate the answer
For example, in the above screenshot, scite assistant cited (Mine. et.al, 2015), mousing over it you get
It is controversial whether it is sensitive enough to be used alone for systematic reviews or not. 56,57....
So should that text answer be attributed to the Mine. et.al paper or to reference 56,57 in Mine. et.al,2015?.
In this particular case, 56 and 57 in the paper refers to
Gehanno, J., Rollin, L., Darmoni, S. J. (2013). Is the Coverage Of Google Scholar Enough To Be Used Alone For Systematic Reviews. BMC Med Inform Decis Mak, 1(13). https://doi.org/10.1186/1472-6947-13-7
Giustini, D., Boulos, M. N. K. (2013). Google Scholar Is Not Enough To Be Used Alone For Systematic Reviews. OJPHI, 2(5). https://doi.org/10.5210/ojphi.v5i2.4623
So here it is fair to cite Mine et.al (2015) because it is his view it is controversial whether Google Scholar is sensitive enough to be used for systematic review though his judgement is based on these two opposing papers.
As an aside, IMHO if you have read both papers it is clear Giustini et.al (2013) refutes Gehanno et.al (2013) as the latter paper uses a methodology based on a flawed assumption. Any librarian who is familiar with systematic reviews and/or read both papers should understand why.
However, in other cases, the correct citation might be to the paper equivalent to 56/57 as what scite assistant is picking up is the equalvant of a secondary/indirect citation
So far, Scite assistant features are those seen in systems like Bing Chat and perplexity.ai, but it then goes beyond to provide pretty novel features to customize the answers generated.
If you click on the setting (gear button) on the bottom left of the screen, you will see the "Assistant Settings" popup.
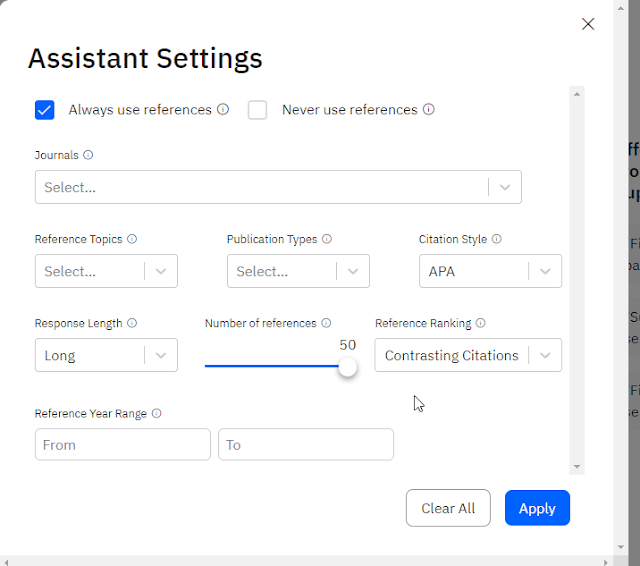
Assistant settings in Scite
This gives you a host of ways to customize the answer you can get from scite.
From specifying response length, number of years of publications, reference topics (disciplines), Publication type (e.g. book, article), journals and even priorizing whether it selects contrasting, supporting citations instead of just recency or relevancy.
Of these settings, I find the check boxes for "always use references" and "never use references" very intriguing.
By default, if neither check-boxes are checked "the assistant will only use references if it thinks it is necessary".
If you check "always use references" it will presumably add a reference at the end of each generated sentences. While the mutually exclusive "never use references" should do the obvious thing.
Before shows generated answer with the default setting, with neither box checked, and it will "only use references if it thinks it is necessary". In practice, I find it usually does include a citation except for what is sometimes called transition sentences at the start or end of each paragraph.
e.g. "One important factor that has been studied is the ownership structure of the bank." and "These studies highlight the importance of considering ownership structure and its impact on risk-taking."

scite assistant with default settings that adds a reference only if it thinks it is necessary
Interestingly changing the setting to "always use references" doesn't actually do that.

scite assistant with setting "always use references"
It is more likely to end paragraphs with sentences with citations but the starting sentences still don't have citations.
Finally, with the "never use references" , you get less references but they are not totally removed.

scite assistant with "never uses reference"
It's unclear what is happening here but perhaps the use of such settings is simply changing the prompt or system instructions and the Language Model (ChatGPT-3.5-turbo) does not always follow the prompt exactly.
Similarly changing settings such as "response length" (short/medium/long), number of references (up to 50), are of a certain reference topic (discipline), of a certain publication type (e.g. book, article) or year of publication does not lead to full compliance.
The only exception seems to be if you restrict by journals from which the citations should be from.
The interface for this is quite nice, you can just type a few words and it autosuggests journals!
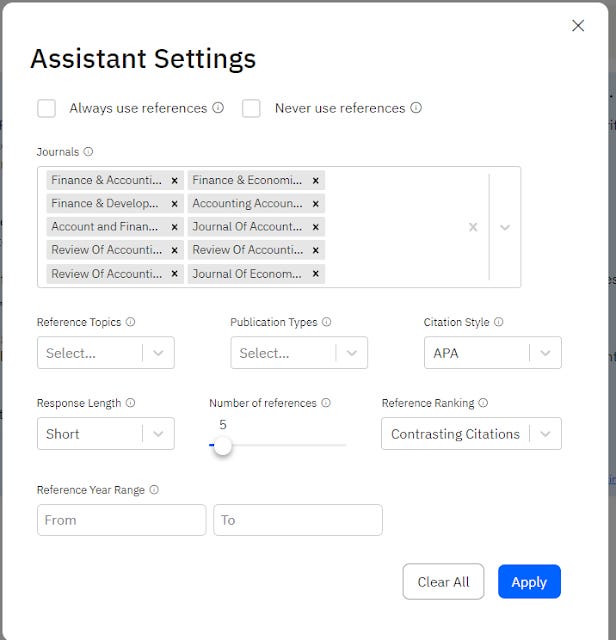
There is a suggestion from a user that in this particular case it tends to comply usually. To the point if it can't find suitable journals, I see it gives no answer. However even this isn't consistent.

scite assistant generates no answer because of journal filters
In conclusion while Scite assistant gives you tools in theory to nudge various aspects of the generated answers, they currently act like suggested guidelines rather than strict laws the system has to follow.
Zeta Alpha
I haven't had much experience with Zeta Alpha, but here's a quick overview.
This is how the help file describes it
Zeta Alpha is a platform which unifies many aspects of knowledge discovery and management during the research process. Our goal is to become a smart Personal Research Assistant for you and your team and to help you make the right decisions, save time, stay competitive, and achieve more impact with your research.
It goes on to describe how you can label and tag articles and the system will recommend and personalize articles based on what you tag.
Recommendations from Zeta Alpha
A 2020 paper that seems to describe an early version of Zeta Alpha suggests recommendations are partly based on Knowledge graph concepts together with the typical hybrid content-based and collaborative filtering method e.g. author based, citation based, popularity etc.
So off the bat, it differs from Elicit and Scispace in that Zeta Alpha seem to focus on recommendations. But let's focus on the direct answers it generates.
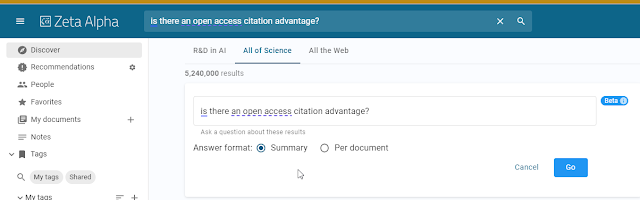
Zeta Alpha - Summary vs Per document formats
Interestingly, it offers two answer modes - Summary vs per document formats. The first gives what you might expect a direct answer.
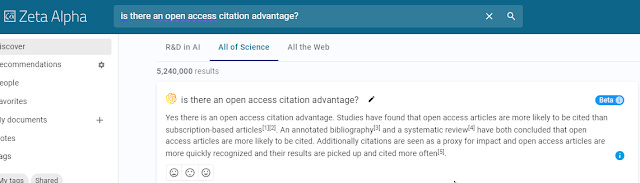
Zeta Alpha - Summary format, not in screencap normal search engine results below
Clicking on the "i" icon popups a screen that gives you a list of references used to support and generate the answer
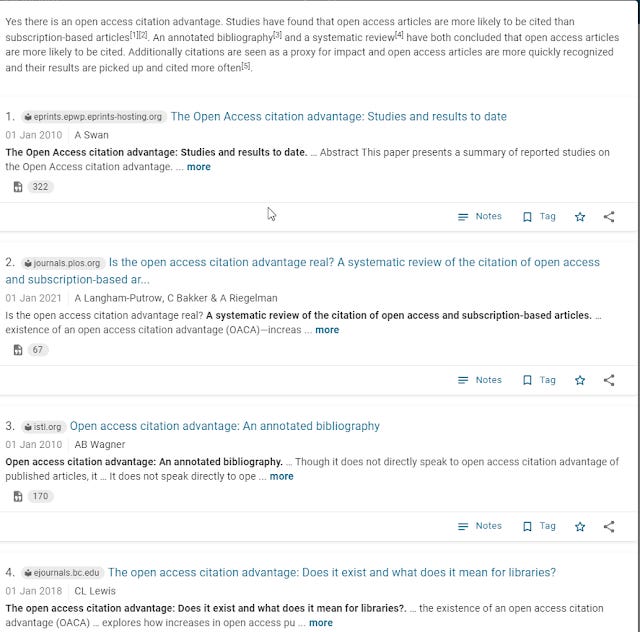
Zeta Alpha - Summary format - information
What about the per document mode? Below is what you get
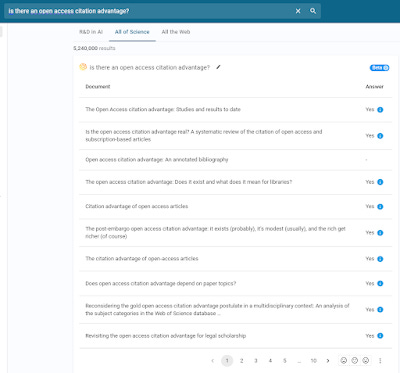
Zeta Alpha - per document mode
R&D in AI vs All of Science Vs All of Web options in Zeta alpha
Zeta alpha feels like it is a system meant for enterprise use with references to federating "your queries to multiple backend search systems" and I guess the idea is for you to upload your internal documents etc. I guess inhouse research teams might also feed it full-text of relevant papers in areas of their study.
In the free version though, when you first login you get three options
R&D in AI
All of Science
All of web
This is what the help file says about the differences
The 'R&D in AI' tab is the Zeta Alpha hosted search index. The search results in the 'All of Science' results tab allows you to find all academic papers in areas outside of our core AI and Data Science topics. Currently, this search tab is powered by Google Scholar, so you will get the same search results here as if you typed your query there.
It's somewhat curious that "All of Science" results are claimed to be powered by Google Scholar, since there is no API, but perhaps they are just scrapping the results. The features mentioned above I believe work regardless of whether you use the hosted "R&D in AI" or "All of Science", but you get additional features if the results come from documents that are fully hosted on Zeta alpha as they can be pre-indexed and various additional features become possible. (It's likely they can do it for R&D in AI, because most computer science/AI papers are freely available on Arxiv)
One obvious aspect of working with preindexed content of course is you can more easily offer facets for filtering.
But there are other interesting "AI" related features too.
For example, if you do the search in R&D in AI you get the option to choose between three search modes, "Neural Search", "Keyword and "Hybrid"

"Neural Search", "Keyword and "Hybrid" mode in Zeta alpha
As I explained in an earlier blog post, traditional lexical search or keyword search that we librarians are used to focus on matching keywords (or ngrams) from query to documents. Various techniques like stemming, lemmatization etc allow more flexibility in matching but the fundamental way of matching is still keywords.
TF-IDF or the slight improvement/modification BM25 are the most popular examples of lexical search algos used in popular systems like elastic search.
This is as opposed to "neutral search" (sometimes called semantic search) that involve the use of embeddings (which now tends to be transformer based "dense vectors" or embeddings). The query is converted into embeddings and then some algo is used to find the closest similarity match to appropriate text in documents (which have had their embeddings precalculated already and stored in a vector database).
Discovery of existing and new knowledge is provided primarily through the Search API. Zeta Alpha’s search layer provides both classical keyword-based search (with the usual boolean, phrase and field operators), as well as modern neural vector search. We call the latter Transformer Powered Search. Search is offered both at the Document, Passage and Sentence level, using a variety of filters and ranking functions. External data sources, such as social media mentions, author influence, or code popularity can be used as signals in the ranking.
When we use longer passages as input, the neural encoding methods will largely preserve the meaning implied by the sentence structure in the encoded vector space, and retrieve the most similar and highly relevant passages, where keyword-based methods have a very hard time retrieving anything relevant at all. This allows discovery and user profiling using natural language questions, or query by example from documents that the user has tagged...
In other words, one way to tell that you are likely dealing with a neural based search and not a strict keyword/lexical search is that it can find some results even if you enter a long query string and most of the words in the returned documents don't even match all or even most of the query (after removing stop words).
Without access to the algo it is hard to tell for sure if something is using neural search or lexical search that is modified to allow loose matching e.g. Even the earliest versions of Google or Google Scholar would occasionally drop the last keyword out of N keywords in the query and return documents with match only some of the keywords. This is further complicated by Hybrid methods that may trigger use of neural search when certain conditions are reached or is used for reranking. e.g Google now uses BERT (a transformer based language model) 15% of the time
What does the "hybrid" option do? Despite all the claimed advantages of neural search to "understand" your query (even taking into account words that in traditional lexical search would be ignored as stop words), they can be unpredictable compared to lexical keyword search. Some neural search methods can also be computationally costly, so hybrid methods do exist that combine the two.
In Zeta Alpha's case it says
Hybrid Search combines the results from Neural and Keyword Search in a mixed result list.
which I guess improves recall (you get both matches that are traditional keyword matches as well as extra matches that you normally wouldn't pick up via Neural search), though possibly at the cost of precision.
The other cool feature is that Zeta Alpha provides visualizations which to my eyes looks very familiar because I can immediately tell it is using VOSviewer (more specifically VOSviewer online)from the color scheme and design. In fact, I've seen systems like Dimensions do the same.
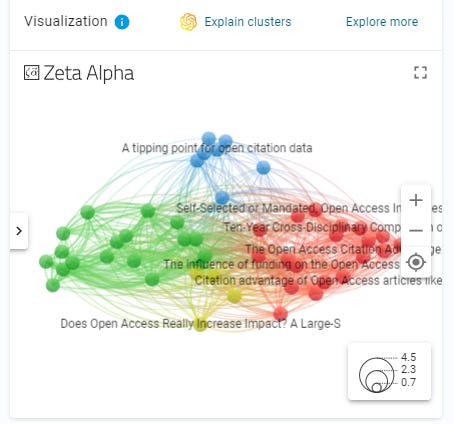
Vosviewer Online integrated in Zeta Alpha
That said Zeta Alpha implementation of Vosviewer seems superior to Dimensions.
First off there are options to "Explore more" which will increase the number of papers used to create the visualization.
More importantly, I always felt that such visualizations were very hard to interpret if you didn't have any knowledge of the literature to make out why papers were clustered the way they were. On the other hand, if you did know by just glancing at them, would you need such a visualization? So, it's a bit of a catch-21 situation, though to be fair there is probably a middle ground where you know enough to make out clusters but not be expert enough to gain nothing out of a visualization.
Still, I always liked that Citespace - a science mapping alternative to VOSviewer would try to label clusters using titles, abstracts or keywords using an algo. Even more recently, I realized an update added the functionality of using ChatGPT to label the clusters!
@CiteSpace now allows use of OpenAI GPT to label the cluster in 8 languages. Enter your API key as an environment variable. Video: https://t.co/g3a9SaFCEW . See FAQ 7.4 https://t.co/kG3sW2gn0Q pic.twitter.com/VZajyRvBBh
— Aaron Tay (@aarontay) June 27, 2023
So, imagine my amazement, when I noticed the visualization in zeta-alpha has a "Explain the clusters" which does this very function of labelling clusters (Using OpenAI's API
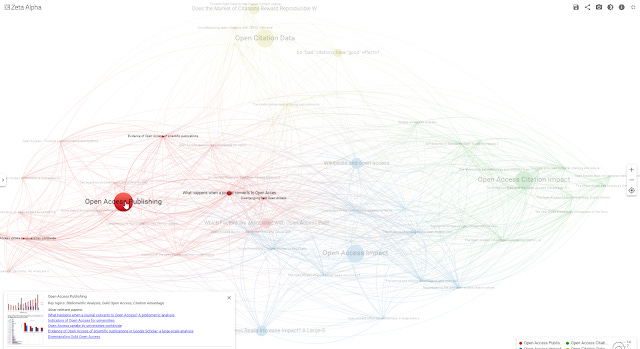
Visualization in VOSviewer online with clusters automatically labelled
Above shows an example where if you click on the cluster Open Access Publishing , you can see multiple papers making up the cluster (or more accurately the system creates a cluster node)
Conclusion
In this blog post, I covered Scite Assistant, Scispace and Zeta alpha, three new generation academic discovery search engines that leverage on the latest advancements from LLMs to either generate direct answers and/or to extract useful information for display.
I suspect these few tools together with Elicit.org etc are just a sign of what is to come. Eventually large traditional academic content and search providers will also eventually get into the act.
For example, we already see the academic content and services giant, Clarivate (which owns Proquest that supplies two of the four major academic discovery services used by libraries - Primo and Summon, announcing a partnership with AI company AI21 labs....
More important than the interface similarity or differences is how well they work. For example are the generated direct answers really useful? How accurate are the extracted table of studies?
I expect many researchers including librarians particularly in the field of evidence synthesis will be studying this closely in the years to come.