


What Academic "Deep Research" Is Really For
Orientation, not copy-paste prose.

TL;DR Deep Search is the measurable engine that lifted retrieval quality substantially. Academic Deep Research earns its keep when you use it to orient fast—not to replace your literature review. Ghost references are largely solved in academic DR; source faithfulness is the ongoing hard problem, but manageable when your goal is to get a sense of the field and then read.
Introduction
In my last post, I argued that Deep Search—iterative retrieval that blends keyword, semantic, and citation chasing with LLM-based relevance judgments—is the real breakthrough behind today’s “Deep Research” tools. It consistently beats one-shot embedding search in recall/precision, and in hindsight, it’s what I loved all along (the “generation” step just came bundled).
The price? Waiting for more than a few seconds for a much better retrieval result. Most academic researchers would happily pay for it!
Thought experiment
Imagine Google Scholar with Deep Search: AI2 PaperFinder/Undermind-style iteration and LLM ranking across the full corpus. No long-form prose, no fabricated references—just outrageously good rankings. Academics don’t need sub-second latency; they need better ranking or top-k.
Generation is trickier. Academic tools have largely eliminated ghost references, but source faithfulness—whether a cited source actually supports the generated claim—remains hard to guarantee, especially in scholarly contexts where misinterpretation is easy even for humans.
What does “source faithfulness” mean? Imagine your Deep Research system spits out this statement.
The Earth is flat (Tay 2022)The citation is “source-faithful” only if the document (that was retrieved) Tay (2022) actually says the Earth is flat somewhere in the document. A claim can be source-faithful but still wrong—faithfulness measures whether the source says it, factuality or answer correctness measures whether it’s true. Various academic studies on Deep Research suggest faithfulness or citation accuracy/precision of best Deep Research tools is around 80% (of cited claims are actually supported by the citation) at best. [1][2][3]
If you think modern LLMs with search do not hallucinate much, you should look up what OpenAI’s released themselves just yesterday on the launch of GPT5
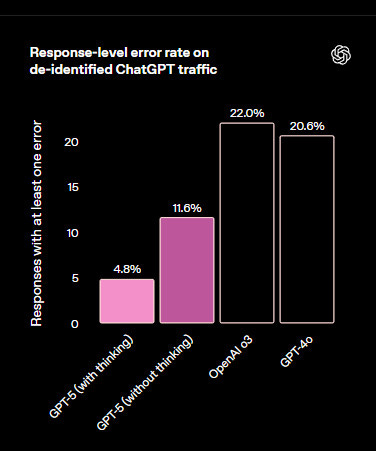
OpenAI’s own data (pre-GPT-5) showed >20% error rates in typical ChatGPT traffic, and RAG studies often report 20–30%. Even with GPT-5, the rate is closer to 5%—still roughly one error in twenty statements. For a 10-page Deep Research report with 50 claims, that’s a few mistakes to track down.
Note that unlike artificial benchmarks on factuality e.g. SimpleQA we are unsure if the test questions are easier or harder than what is seen in the real world, here we get a statistic based on actual ChatGPT traffic! (See other comments by me on this issue)
Given this, it’s tempting to ignore generation altogether and just trust the retrieval. I used to think that way—but I’ve since realized the real value of Academic Deep Research isn’t churning out a ready-to-submit literature review—it’s creating a map of the territory so you can read and think more effectively in a new field.
Used this way, occasional unfaithful statements are a manageable cost of faster understanding.
A sidenote on General Deep Research (OpenAI, Gemini, Perplexity) vs Academic Deep Research
You might have tried OpenAI/Gemini/Perplexity “Deep Research” and come away unimpressed. I agree, I don’t use those for academic work when I have academic Deep Research tools.
Note: This section was written before GPT5 launched, and o3 which is used in OpenAI DeepResearch was renowned for being particularly bad at hallucinations. GPT5 for sure has improved on hallucinations but in my view, it should should be in the same ballpark as Gemini 2.5 Pro and Claude 4.0 models.
One thing that isn’t well appreciated I think by some librarians is the gap between a top-level Academic Deep Research tool and these other general tools. I personally would not use the general tools for academic research when I have academic Deep Research.
Similarly, in my experience, some faculty—especially in competitive fields—adopt academic Deep Research tools (but not general Deep Research) readily once they see the retrieval quality, often integrating them into their workflows without prompting by librarians. Yet I still meet librarians who doubt their utility; that gap between perception and actual use is worth closing.
Note here I am talking about people doing narrative literature reviews not evidence synthesis which is a different story as we all know.
Why?
Let’s leave aside the fact that academic deep research automatically focuses only on the retrieval of academic content, while general deep research might struggle to focus on what to retrieve even with prompts to use only academic content. Many of these general Deep Research tools are also not specialized for academic research and output in strange non-standard citing styles.
The main issue here is that OpenAI, Gemini, and Perplexity Deep Research are extremely prone to fabricating fake references and often even offer broken links. In comparison, top-class academic deep research tools like Undermind, Elicit, and SciSpace will almost never fabricate references.

In fact, a 2023 thesis has shown that even basic academic RAG systems like Scopus AI, Elicit, SciSpace do not make up references at all. While you might see some minor errors in the citation, they are more likely due to issues in the source they rely on.
Think about how Google Scholar metadata errors can often be off for the year of publication as a result of merging different versions of the paper (e.g., preprint vs. version of record).

From "Deep Research Agents: A Systematic Examination and Roadmap"
Why are academic RAG systems, including Deep Research tools, extremely unlikely to make up citations compared to more general web + RAG/LLM systems?
There are many different reasons for this, but it comes down to differences in the retrieval method, the inherent boundedness of the domain of academic content versus the general web, and differences in the RAG process with post-hoc validation checks.
Most academic deep research tools use offline retrieval methods where they look up vector embeddings in their own vector database. They have full control of what is returned and besides the advantage of speed they can easily verify if a generated citation exists in the vector database.
On the other hand, many general Deep Research tools are not only handicapped by the fact that they are using a browser to browse the web like a human rather than using an API, but webpages are also inherently unstable, and there is also no easy way to tell in advance if a certain webpage exists or not.
One “fool-proof” way academic RAG/Deep Research tools might be using to prevent fabricated citations
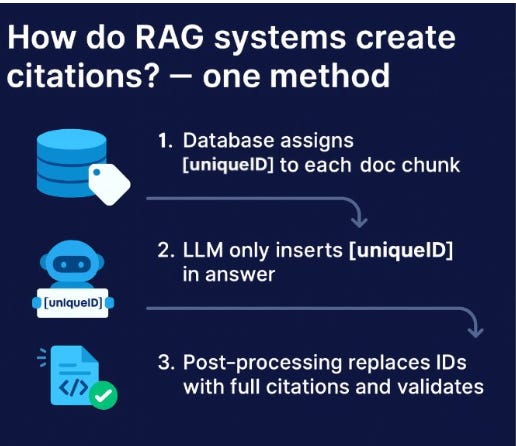
LLMs do not naturally have the ability to cite the text chunks they have retrieved. There are many ways to achieve this, but here is one way that can pretty much guarantee no fabricated citations.
First, the database assigns a [uniqueID] to each doc chunk. The doc chunks that are retrieved are sent to the LLM with the [uniqueID] as well as the text.
Second, the LLM is prompted and fine-tuned to generate citation statements with the [uniqueID].
So, for example, it may generate:
Singapore’s oldest public library is in Queenstown [uniqueID].
The key here is that the LLM is instructed not to generate the full citation, just the unique ID. The [uniqueID] is replaced by a non-LLM method, for example, regular expressions.
This is important because if the LLM hallucinates and generates a [uniqueID] that does not exist or match against the [uniqueID]s of the text chunks retrieved, it will be flagged and can be handled separately! This post-hoc check pretty much ensures there will be zero ghost references, though it can still generate unfaithful statements. Though do note that this does not guard against faithfulness issues (which does have a slew of methods, e.g., entailment methods to detect, but none are foolproof).
I suspect many of the best Academic RAG/Deep Research systems do post-processing checks, which greatly reduces the chance of a fake citation being generated.
An insight about Deep Research and what it is for
Edit: I have been reviewing the literature that has sprung up quickly around “Deep Research from June 2025 . Most of these papers test OpenAI/Gemini/Perplexity Deep Research often comparing with their own homebrew version of a Deep Research Agent using an existing LLM (often reasoning) model. There are also many proposed Benchmarks for Deep Search or often called agentic search like Mind2Web 2, Deep Research Bench (DRB)(most updated), ResearcherBench, LiveDRBench, DeepResearch Bench, DeepResearchGym etc.
While there were similarities e.g. they all focused on relatively long horizon tasks (e.g. >30 minutes) but their task sets and evaluation methods (typically LLM as a judge) are quite different.
Some like Mind2Web 2 was mostly not on academic tasks, others like Deep Research Bench (DRB) covered a bunch of tasks from “find number”, “find dataset”, “find original source”, “Validate Claim”, “Derive Number”, “Gather evidence”, “Populate Reference Class“, “Compile dataset”.
ResearcherBench covers only academic but tasks was broken down into “Technical Details”, “Literature Review”, “Open Consulting” -
LiveDRBench which cover searches for novelty like “Find a dataset matching unique characteristics”, “Retrieve peer dataset papers in the same problem space based on a high level description.“, “Find research papers that use all datasets specified in the query.” and “Find materials that match all specified measured properties.”
In short, we can see from all this heterogeneity in the different benchmarks, the idea of what DR is supposed to do seems to go beyond just creating a Literature review even if we stay in the academic real,
Despite the fact that academic Deep Research tools are better than general Deep Research tools, I was still lukewarm about using the generated report from these tools.
It took me a while to realize the real reason why. Sure, there was always the threat of hallucinations and the amount of effort it takes to check 10 pages of a literature review generated by OpenAI Deep Research made such use of these tools unappealing.
But even after I went through the effort of checking for errors, I still likely wouldn’t use it directly because when I write a literature review for a paper, I tend to angle the literature review in a certain direction to subtly (hopefully) support my research question.
It was not until much later that I realized that a good academic Deep Research tool main use shouldn’t be to generate a literature review for you to use wholesale but rather its primary goal should be to produce an artifact that included features to help the researcher orient themselves in an area where they know a little bit or nothing at all. If you already knew the area, why would you use the tool, beyond using it as a test?
This confusion was why I was initially unsure about including Undermind as a “Deep Research” tool because it didn’t produce a traditional literature review report but had sections like “Categories” and “timeline visualizations” that you don’t find in a typical literature review.
What Academic Deep Research should produce
Today, I believe Undermind.ai actually got it right, and I see many of the new Academic Deep Research tools, like the just-launched Consensus Deep Search, follow the same path.
Once you drop the idea of copy-pasting the generated review, the value clicks: the best academic Deep Research tools produce orientation artifacts—surfaces that help you form a mental model fast.
Timeline / historical development (clusters, labs, key people)
Foundational / seminal papers (often from citation patterns among relevant papers found via deep search)
Adjacent work (near the frontier, sometimes just outside scope)
Top contributors & venues
Suggested reading paths (with reasons and alternates)
Claims & evidence tables
Research gaps
Open questions

Consensus.ai Deep Search - Claims and evidence table
In fact, I could imagine such tools having two modes, a strict Literature review mode and a “helping you orient” mode.
Counter Argument - Isn’t it dangerous to use Deep Research in an area you don’t fully understand? While I believe there are risks, this way of using Deep Research is less sensitive to individual errors because you are using it to get the gist of an area, or to try to grasp the Gestalt of the area. Individual source faithfulness errors should not hurt you as much, particularly seen you were going to read anyway, right?
Trends in Academic Deep Research I’m watching (and want)
We are still in the earliest days of Academic Deep Research, and it’s still the wild west as we try to figure things out. Here are some early trends and things I wish to see.
1. More Transparent search flows(e.g., Consensus Deep Search, Elicit Systematic Review, SciSpace Deep Review, AI2 PaperFinder, AI2 ScholarQA, etc.)
More tools expose PRISMA-style flows: how many iterations ran, which queries/citation chains contributed, what each step added. Not Systematic review-grade disclosure (that’s fine), but visibility builds trust. For example, this shows how Consensus Deep Search presents the search process.

They also have some more transparency into what each step is doing, the number of searches at each step, and the new eligible papers found.
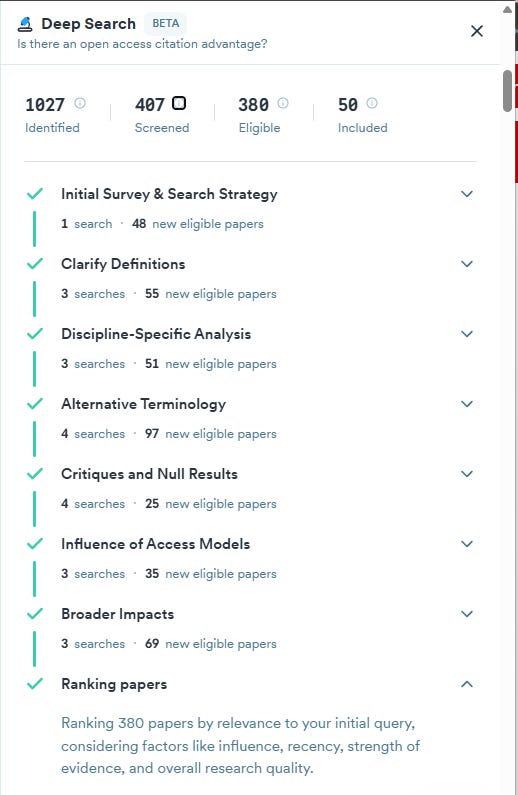
This is SciSpace DeepReview, which has a methodology section that tells you the general queries it used, the number of papers found from the queries, and even the papers found from forward and backward citation chaining.

Other tools that have more transparent workflows are AI2 PaperFinder/Scholar QA and Futurehouse’s PaperQA2.
A systematic review expert seeing these may not be impressed by the amount of disclosure, but these tools were not designed to be used for systematic reviews, unlike Elicit’s systematic review flow.
My thoughts: I understand the need for Deep Re(Search) vendors to hide the secret sauce behind their search algo, but this should be counterbalanced against the desire for some researchers to want more transparency.
2. Specialized Sections that help the reader understand the area faster
In theory, a good literature review by default should help the reader orient themselves to a new area quickly. In practice, not all of them do so, and one way for the Deep Research tool to do so is to by default focus on certain sections that are useful to (almost) always be generated. Deep Research vendors might even customize special visualizations to make these sections more digestible.
What sections are we talking about? Nothing too crazy, sections on seminal papers, key authors, research gaps, open questions, etc.
In fact, I suspect academic Deep Research tools might be converging to the same few sections. I will just content myself with talking about two Deep Research tools I have been playing with recently.
Undermind.ai, for example, has three main sections besides categories of papers:
Timeline (including historical development, clusters of research groups, or key individuals)
Foundational Work
Adjacent Work

On top of that, Undermind has the following available pre-canned prompts to use with a LLM model that will combine references already retrieved with a web search.
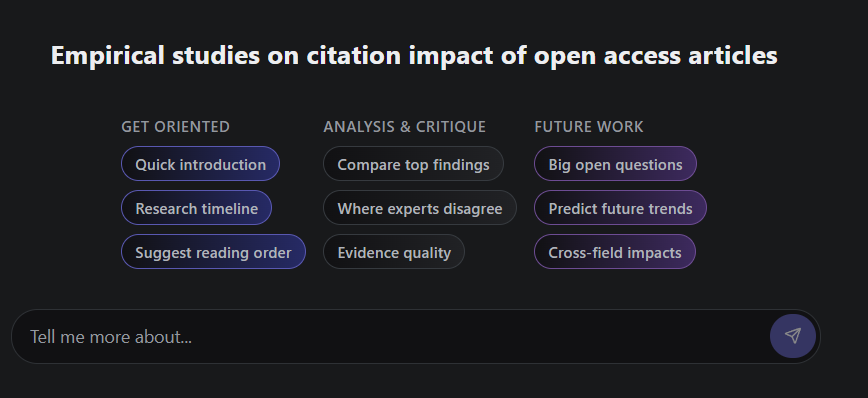
They include:
Suggest reading order
Compare top findings
Where experts disagree
Evidence quality
Big open questions
Predict field trends
Cross-field impacts
Some are interesting—take “Suggested Reading Order”.
On top of suggesting a reading order and why, it even gives alternative paths!
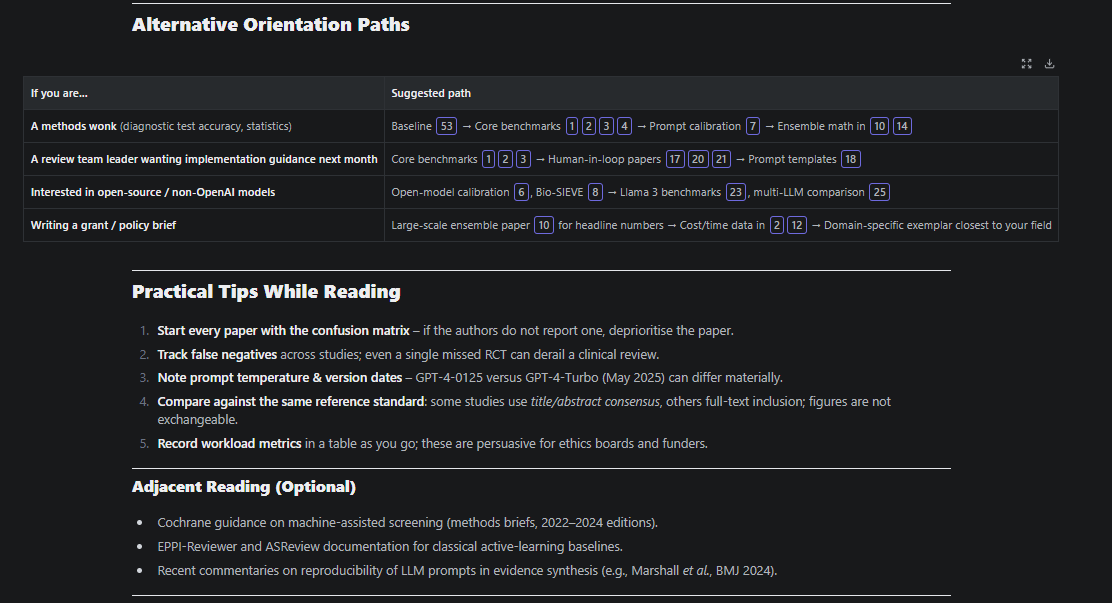
Below shows a section of the generated text when you click on “Evidence quality.”

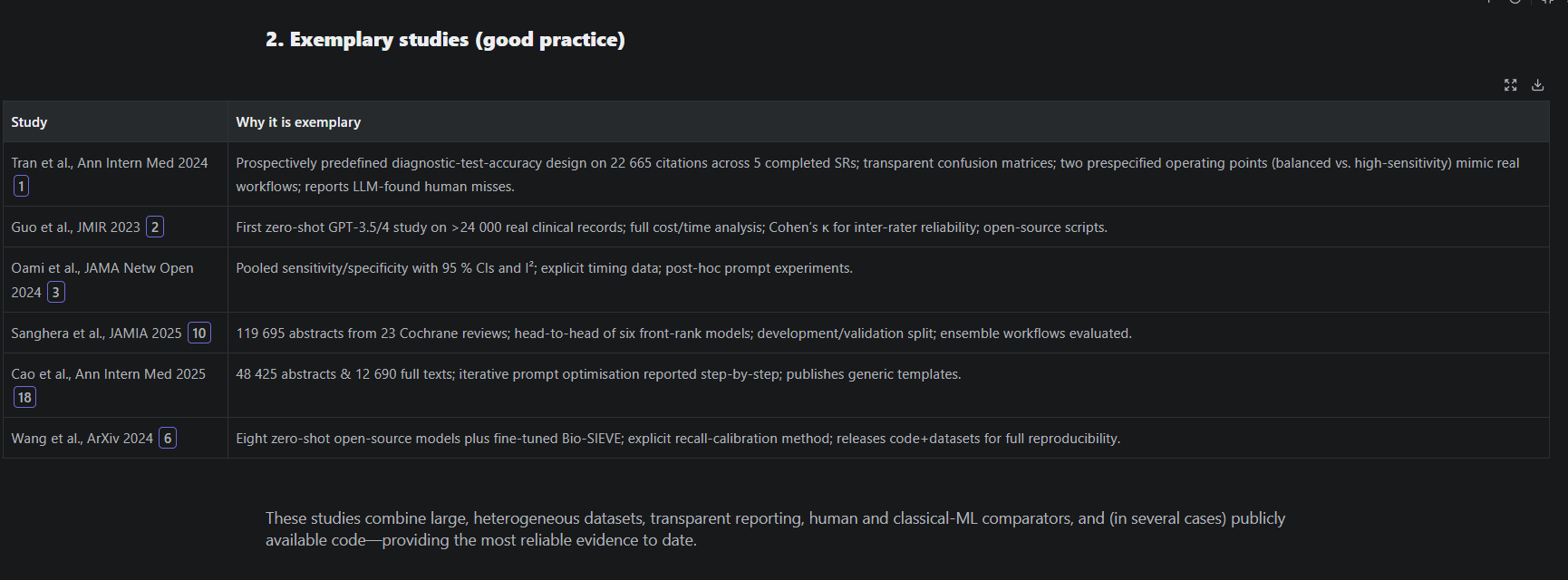
Consensus Deep Search is similar, with sections on
Top Contributors
Key Papers
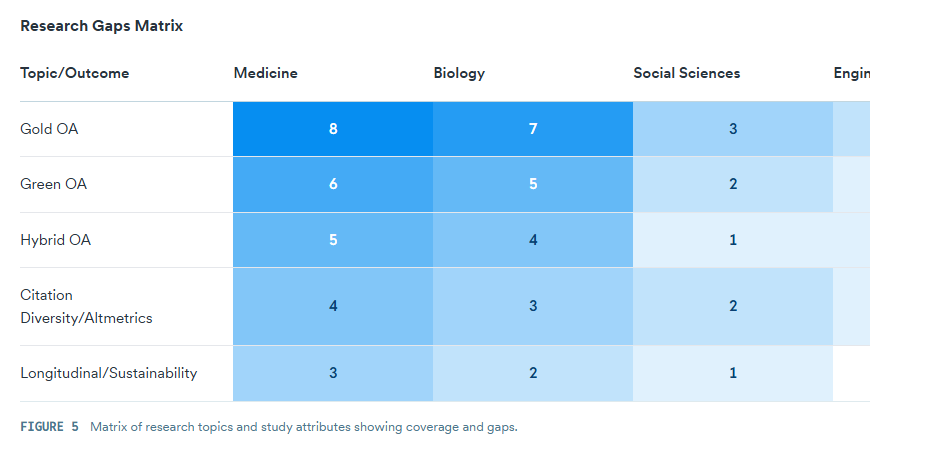
Claims and Evidence Table
Research Gaps Matrix
Open Research Questions
Very similar, right?
Consensus also has a unique distinctive feature that is activiaed if you ask a yes/no question.
Not only does it have its unique “Consensus meter” which allows you to see the “direction of scientific consensus” - the documentation says
For “Yes/No” questions, the Consensus Meter uses large language models to instantly classify the results as indicating “yes”, “no” or “possibly” in a clean, aggregated interface
While the original Consensus meter would do so for the top 20 ranked documents, Deep Search version seems capable of doing it for far more papers.
Consensus Deep Search also color-codes the citation in the same way, green if the evidence in the citation weighs toward the “yes” side, red if towards “no” etc.

My thoughts: There is definitely a lot of room for innovation here. What are some cool visualizations or sections that one might generate to help researchers more quickly grasp what is going on in an area?
3. The merging of citation-based methods and semantic deep search
It is fair to say that tools like Undermind, Elicit, and Consensus could not have existed without the freely available scholarly metadata from sources like Semantic Scholar, OpenAlex (both of whom themselves benefited from Microsoft Academic Graph, PID infrastructure such as Crossref, ORCID etc), etc.
However, this new RAG academic search was not the first beneficiary of open scholarly data.
As I have blogged in the past, what I called citation-based literature mapping tools like Connected Papers, ResearchRabbit, and LitMaps were also based on most of the same sources used by Elicit, Undermind, etc.
As I noted on my blog, these tools date back to the late 2010s, with perhaps the earliest pioneer being Citation Gecko (2018), which used the (at the time) fast-growing amount of Crossref reference data to suggest papers to grow the seed paper used.
These days, popular tools like ConnectedPapers and LitMaps are routinely used and promoted by librarians as “AI-powered literature review tools.” While they are great tools, most of them were fundamentally not based on LLMs, and their recommendation algorithms use more traditional concepts of bibliometrics and network analysis.
Among all of them, LitMaps is the only one confirmed to have a mode based on semantic/vector embedding similarity search. Connected Papers appears to rely mostly on citation networks only, while Research Rabbit has various recommender features that are not transparent about how they work. Still, it is likely that up to recently at least, these tools used algorithms based more on citations than text similarity. Studies tend to show that papers found by them tend to have higher citations than those found by semantic search tools like Elicit and SciSpace (which often do not weight citations as much or at all), a hint at what is going on in the background.
The question is, why not combine both citation-based methods and more modern deep semantic search?
Indeed, I am seeing signs that the top academic deep research tools are indeed doing that.
For example, Undermind’s Foundational Work is based on finding the most cited papers based on the relevant papers found by the deep search on the subject!

In some ways, this is similar to how Connected Papers detects “prior papers.”
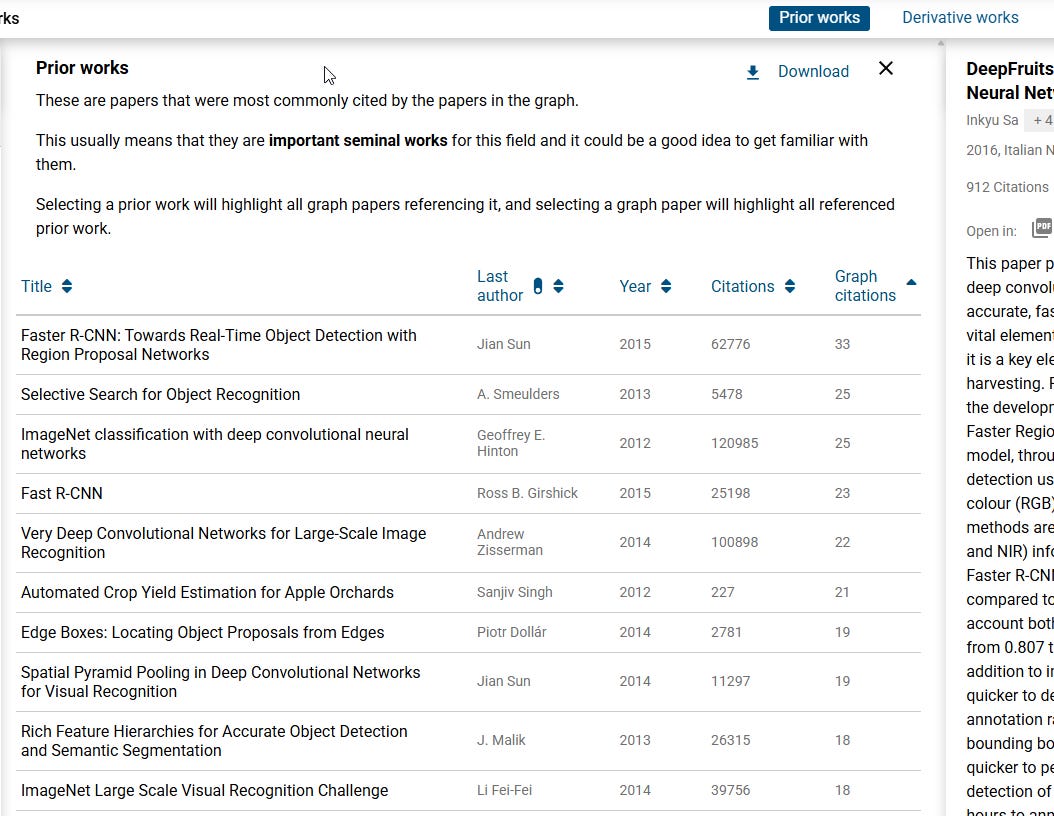
The idea is the same—use relevant papers in a topic to detect the most cited papers.
The main difference, of course, is how Undermind versus Connected Papers got to the set of “relevant papers.”
Connected papers relies on you to put in one “seed” paper and then creates a similarity graph using a similarity metric “based on the concepts of Co-citation and Bibliographic Coupling”. The top 40 or so ranked papers are then used to detect seminal papers by looking at which items are cited the most among them.
Undermind seems to have a similar process, though the papers it uses to detect Seminal papers are obviously obtained using Undermind’s own deep search + semantic topic match.
I generally find Undermind’s detection of seminal papers superior to Connected Papers, basically because Undermind’s deep search typically finds more of the relevant papers in an area, and this allows it to detect seminal papers more accurately.
I suspect many of the academic RAG tools like Scopus AI and Web of Science Research Assistant that can find foundational work, etc., are likely doing something similar to Undermind, i.e., using semantic search (but not Deep Search) to find relevant papers, then using citation patterns of all found relevant papers. However, given they are not Deep Search, the base of articles they use to find seminal papers may not be as complete.
Undermind even has “Adjacent work,” which again is based on surfacing papers that cite the foundational papers, but the Undermind evaluation has judged as not relevant to the topic searched.

While adjacent work is not exactly what you want, I have found from experience (search alerts) that it is often still very interesting.
My thoughts: Similar to human researchers, a top Deep (Re)search tool should have citation chasing or searching in their toolkit to increase recall, though currently not all Deep Re(search) tools do it yet. But there are many creative ways to blend citation chasing with search…..
4. Blending web search with academic search results
Undermind, like any academic deep research tool, searches academic content first and foremost. But as important as this is, sometimes you want or need to blend results with a web search. Indeed, selective web pulls help with recency (e.g., policies) or coverage gaps (monographs, textbooks).
The chat window shown above includes precanned prompts that not only searches within the references already found, but when appropriate, it is also capable of doing a web search.
This can either help plug gaps in the academic search (e.g., the Semantic Scholar corpus which it uses can have holes in terms of indexing of monographs and textbooks) or can be useful in cases where you need more current knowledge.
In particular, the pre-canned prompts for “big open questions,” “predict future trends,” etc., benefit a lot from searching the web to blend results from the most current happenings.
For example, when doing “predict future trends,” it has the great idea to search for information about the OSTP memo, a recent government mandate affecting open access.
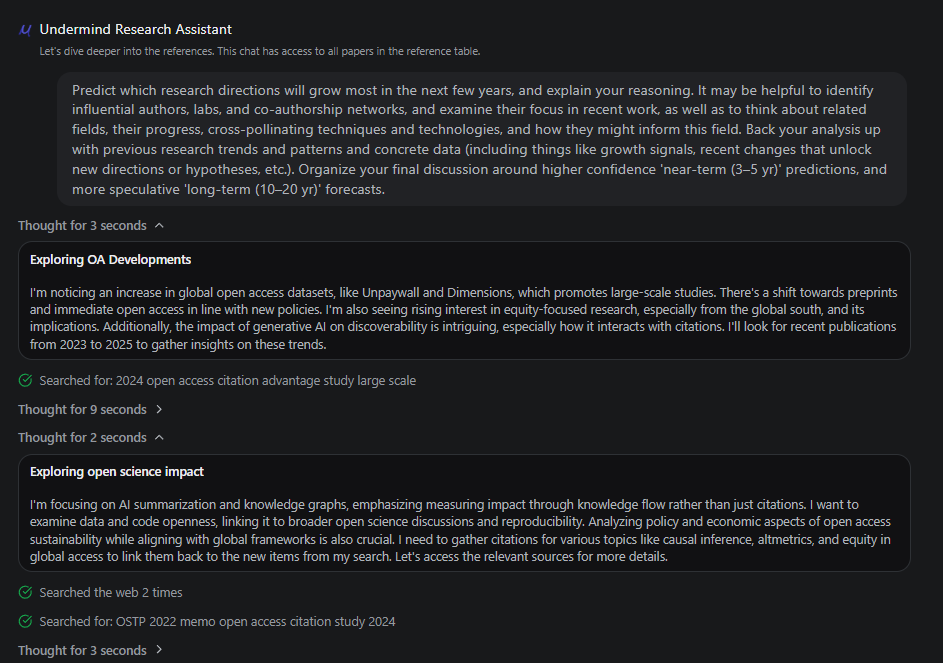
My thoughts: Undermind currently leans on the LLM model’s tool calling of web search. While useful, this is just a fairly quick search of the web. Would a more advanced version of Deep Research allow you to also do a full-blown Deep Web Search similar to how OpenAI Deep Reseach does it on top of the usual Academic Deep Search. This can be done either via API or better yet via browser (see next section).
5. Agentic Search with computer/browser use
In my past writings, I have used deep search and agentic search interchangeably, and this is a common definition, though some disagree with it.

Some differentiate deep research tools by whether their workflow is handcrafted/tuned by humans or whether they are trained via reinforcement learning with the “freedom” to decide what to do, with some suggesting agentic search is something belonging more to the trained model’s side of things.
I am not sure if this is a good way to think, especially my impression is that most academic deep research is more towards the handcrafted/tuned by human side as compared to OpenAI Deep Research and its peers.
One other major difference that is salient, I think, is that OpenAI Deep Research (and probably Gemini Deep Research, etc.) searches by literally simulating a user clicking and typing on a browser as opposed to using an API. To some this is the true definition of agentic search.
While this sounds cool and general, it is extremely slow compared to an Undermind or Consensus having direct access to content in an indexed database.
To give you an idea of how slow agents using browsers directly are, OpenAI states that the agent will take screenshots of the screen and use its image recognition capabilities to decide what to do.
I will write a future post on agentic search, but my earlier tests with OpenAI agents are that while you CAN use it to search paywalled resources like Scopus and EBSCOhost databases, I have found it terribly slow, and it can be easily confused by complicated interfaces and waste time. So far, the best I saw was it trying to summarize the top 10 article abstracts before it stopped after 30 minutes.
That said, SciSpace launched SciSpace Research Agent, which is distinct from SciSpace Deep Research and seems to work quickly as an agent.
I suspect the optimal use of such agentic search is to blend search using APIs, direct access to indexes whenever possible, and only use agentic search via live browsing when necessary, e.g., using user entitlements to download full-text or search specific sources that is not indexed.
Essentially, we are looking at a similar idea to the federated search approach - index what you can and federate the rest?
My thoughts: Fast developing area, much more to say about this in the future.
6. Capability-aware prompting & warnings
At its core, Deep Research is still a RAG based system, so most of what you expect in a good RAG system should be present as well. Most importantly, there would be features to help you check for source faithfulness. A good example would be AI2’s ScholarQA where it shows the evidence from the paper used.
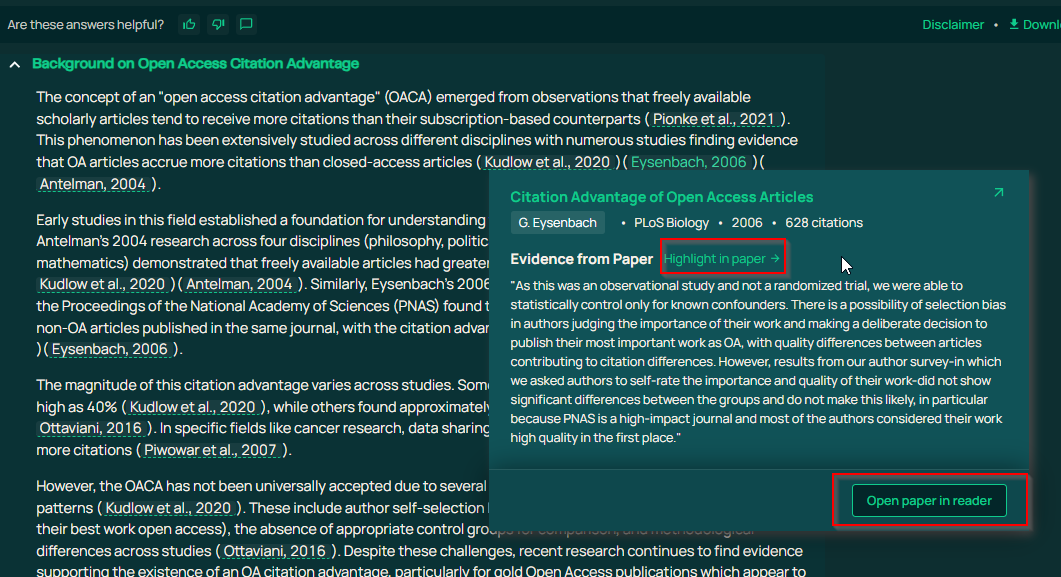
Being clear, what is being searched over is important as well.
For normal RAG systems, I suggested that the RAG vendor “Show examples of what type of queries or prompts should be entered”. With Deep Research, the system has an opportunity to detect with the type of query being entered would not be likely to do well and suggest improvements (e.g. Elicit calculates “question strength” and gives suggestions for guiding the user towards a query that is likely to do well.
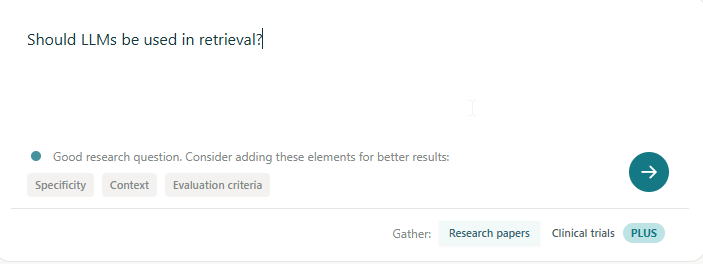
This question check tool should be aware of its own capabilities and shortcomings. For example, if the vendor knows their product can’t handle prompts like “filter to only review articles” (because their source does not tag papers by review article type), the Deep (re)search tool should be able to warn the user when these types of queries are entered.
Lastly, as you know, one of the big limitations of Academic Deep Research tools is its lack of access to paywall Fulltext. Could the Deep Search system help warn users of this when it is particularly problematic? Example when a query is asking something where the answer is most likely in a field with mostly paywalled journals.
Future use cases of Academic Deep Research
Once I saw past the idea of using Academic Deep Research just to produce a literature review, I started to see if I could use such tools creatively. For example, I used it to find papers that all used various Nielsen Datasets, and Undermind did very well.
In fact, now that I think about it, could you do any of the following?
Give it a paper, ask it to go through the references, and then check if there are any highly relevant papers found by the deep search but not cited by the initial paper.
Given two papers from two different areas, find the shortest path between the two papers and summarize how the papers in between are linked.
Retrieve all papers by a certain filter (e.g. from a given institution or journal) then analysis and cluster the papers
Essentially if you have a deep research tool or agent that can keyword search do citation chasing and assuming you feed it enough metadata and i alsot knows how to filter by metadata, the tasks above and more could be done!
Aaron, this is very deep to me. Thank you.
Aaron, you mentioned that top-class academic deep research tools almost never fabricate references but do they make unfaithful statements? How can one check on this issue in general? is there any empirical data on unfaithful statements for each of these tools? Would you mind to share?
I've found OpenAI Deep Research very useful for a lot of orientation-type tasks, especially in the humanities; a common prompt is "I'm beginning graduate-level research in _________. Can you provide an overview of the seminal and current work in the field, and propose an initial reading list to orient myself in the literature, and summarize any special skills I would need?"
Some tests I've done on that in humanities subjects have done especially well compared to the academic deep research tools, I think because the humanities are thin enough in Semantic Scholar that the tools don't reach enough literature, especially monographs.
For articles, Undermind is of course tremendous and is probably . I agree that if this can be paired up with tools that can reach monographs and gray literature we'll really be onto something.