
When is a Hallucination Not a Hallucination? The Role of Implicit Knowledge in RAG

Summary (summarised by Gemini 2.0-exp)
We often think of AI-generated 'hallucinations' as blatant errors, but what happens when a RAG system produces information that's factually true but not explicitly stated in its sources? This post delves into the murky world of 'source faithfulness' in Retrieval Augmented Generation (RAG) systems, exploring how implicit knowledge and common-sense assumptions blur the lines between helpful inference and problematic fabrication. We'll examine real-world examples, look at evaluation benchmarks of some of the latest LLM models, and ultimately question whether our traditional definitions of 'hallucination' are as clear as they appear to be. Prepare to rethink what it means for AI to be truly faithful.
What does Factuality mean in Retrieval Augmented Generation (RAG)?
The term "factuality" is used for many Natural Language Processing (NLP) metrics and it can be confusing as they can be defined quite differently based on the NLP task. Similarly the term "hallucinations" can be confusing depending on the NLP task context (e.g. summarization, text generation using LLM, RAG) it is used in.
First, let us recap what Retrieval Augmented Generation (RAG) is.

Essentially basic RAG involves
1. Searching for relevant context (document or text chunks) to answer the query
2. Passing the relevant context to a LLM with a prompt to answer the query with the context retrieved
3. LLM generates answer.
While there are many RAG specific evaluation metrics to consider including (answer relevancy, context recall, context precision), for this blog post, we consider that the retrieval is done with a given set of documents found and focus on Step 2 to 3. This generally narrows it down to a type of summarization task, Query-focused Multi-document Summarization (QMDS)
Factually true vs Faithful to the source
So let's consider what could be meant by "factuality" in that context
Definition 1 - A generated statement/answer has high factuality if it corresponds with the state of the real world or current world knowledge (answer is "true")
Definition 2 - A generated statement/answer has high factuality if it is supported by the retrieved context (answer is "faithful" to sources)
There is actually Definition 3 - generated statement/answer has high factuality if it is aligned or semantically equalvant to the gold standard/ground truth RAG answer (see next blog post). This in some frameworks like RAGAS is called "answer correctness" or "answer similarity", but we will assume there is no ground truth RAG reference answer for now.
Clearly 1 and 2 can differ. A RAG generated answer can be "true" (corresponds with the state of the real world) and yet not be faithful or consistent because either the retrieved context has false information or is silent about the generated answer.
Imagine for example, a RAG system that has
Query : "Where is the Eiffel Tower?
Context retrieved : "The Eiffel Tower, was completed in 1889 and stands 330 meters tall. It is one of the most famous landmarks in the world.".
Generated answer : "The Eiffel Tower is in Paris and was built in the late 19th century."
In this case, while the generated answer is "true", it is not "source faithful"since the retrieved context says nothing about where the Eiffel Tower is. In this case, it is likely the LLM is using it's own inbuilt implict world knowledge from it's LLM pretraining step to answer the question.
I've actually seen metrics and benchmarks that use the word factuality to cover both concepts, which is why I prefer to use other terms like source faithful.
Intrinsic hallucination vs Extrinsic hallucinations.
Some authors also use the term Intrinsic hallucination vs Extrinsic hallucinations. I've seen varying definitions but generally, Instrinsic hallucations are when the generated answer is not consistant (aka contradict) with the source/retrieved context. Extrinsic hallucinations are when the generated answer cannot be confirmed by source.
Query : "Where is the Eiffel Tower?
Context retrieved : "The Eiffel Tower, was completed in 1889 and stands 330 meters tall. It is one of the most famous landmarks in the world.".
Generated answer (Extrinsic hallucination) : "The Eiffel Tower is in Paris and was built in the late 19th century."
Generated answer (Instrinsic hallucination) : "The Eiffel Tower finished completion in 1850"
For this blog post, I will not make the distinction between instrinsic and extrinsic hallucination. Instrinsic hallucinations that contradict the source are probably more serious but I think from the point of view of RAG systems, generating statements that are not supported by retrieved text is also problematic. But as you will see later, what counts as an "extrinsic hallucination" can be sometimes hard to figure out.
We prefer RAG systems that are source faithful
I think it is fair to say that for those of us who use RAG systems for academic search, we prefer our systems to generate answers that are source faithfulness over just being factually true. This is because as academics we like to have citations that we can verify against and ideally they should be faithful.
Even this isn't as clearcut as it seems, does every generated sentence in the RAG generated answer needs to have a citation (as done in this paper)? While it is clear you shouldn't need to cite "common knowledge", there is still some freedom to choose what not to provide citations
This is true even if the source or context retrieved has factually wrong information.
For example, I had feedback from a user of Undermind.ai that Undermind identified a paper that was relevant based on the abstract but unfortunately, the abstract was just making false statements! Still the user was not unhappy, just sharing his experience as at the end of the day, this was something that could be verfied.
From the point of view of Retrieval Generated Benchmark (RGB), Undermind.ai lacked "Counterfactual Robustness" but personally I don't think this doesn't seem to be a metric I would like to optimise on.

Retrieval Generated Benchmark (RGB)
Which are the systems that seem to be most source faithful?
There are multiple benchmarks that claim to be measure factuality (in the sense of consistent/faithful to source) and/or hallucination rates.
The first one I liked was LLM Confabulation (Hallucination) Leaderboard for RAG. One nice thing about this leaderboard was that the questions were purely human generated and vetted and most importantly did not use LLMs as a judge at all to evaluate the LLMs.
How was this done?
They cleverly created a suite of questions with
A query
A source/context
such that if you only used #2 and nothing else, you shouldn't be able to answer the query (This is testing negative rejection in the Retrieval Generated Benchmark (RGB))
As such if the LLM even after being instructed to stick strictly to the source still generated a non-null answer it was definitely hallucinating! There was no need to check anything else. As such if an LLM generated a non-null answer in say 10% of the questions, it would have a Confabulation rate of 10%
But it didn't stop there. In theory, a LLM could score very well in this test, by just being super conservative and refusing to answer anything.
One of the things, I was told when I asked academic RAG system engineers why they didn't tune the system to be more conservative in generation of text from retrieved context by refusing to answer more often when "unsure" but was told this was a tradeoff that many users would not want.
As such, there was another set of questions, where the paired query and source but this time, they definitely could answer, and the benchmark measured how many % of questions it refused to answer (non-response rate).
Is there a trade-off between Non-hallucination rate and non-response rate?
I took the data and plotted all the tested models, with y-axis as the non-hallucation rate (1-Confabulation rate) and x-axis as the non-response rate.
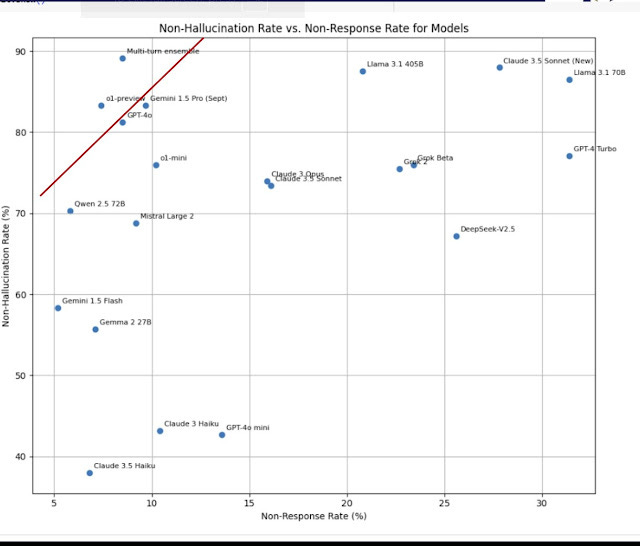
Plotting them this way, the best models are on the upper left corner, because they have the highest non-hallucination rate (high rate of correctly refusing to answer for the first set of questions) and also lowest non-response rate (low rate of wrongly refusing to answer for the second set of questions)
Interestingly,you can see in the graph above, a pareto-optimal frontier, going from Qwen 2.5 72B on the lower left to GPT4o to Gemini 1.5 (pro) to Llama 3.1 405B and Claude 3.5 Sonnet (new) in the upper right.
Put it another way, using GPT-4o as a baseline, it has a non-hallucination rate of 81.2% and non-response rate of 8.5%. While there are models with higher non-hallucination rates like Gemini 1.5 pro (83.3%), Llama 3.1 405B (87.5%) and Claude 3.5 Sonnet (88%) it is at the cost of higher non-response rate! For example, Claude 3.5 Sonnet new has a non-response rate of 27.8% almost 10% more than GPT4o, showing a tradeoff.
Note these rates are not reflective of the real world hallucination rates you will see as the question sets have been included only if at least one of the models fails ("hard questions"). As such, we can expect that in the real world, the non-hallucination rate would probably be even better than shown here.
At the time of writing there are only 2 models that are strictly better than GPT-4o. These include
a) GPT o1-preview - which has a lower non-hallucination rate of 83.3% and lower non-response rate of 7.4%
b) Multi-turn ensemble model - which "utilizes multiple LLMs, multi-turn dialogues, and other proprietary techniques" - this has the lowest non-hallucination rate of 89.1% and non-response rate of 8.5% - clearly combining different LLMs and techniques leads to extremely good results.
At the time of this benchmark it seems some of the latest models, Gemini 1.5 pro, GPT-4o, Claude Sonnet 3.5 (new) and o1-preview seem to be the best. Interestingly all "thinking" models do not necessarily do well, and 01-mini seems strictly worse compared to GPT-4o!
Edit : Update as of 15 Feb 2025

The newer reasoning models like DeepSeek R1, Gemini 2.0 Flash thinking (though this might be a "mini" model) seem to do better compared to their non-thinking counterparts (DeepSeek V3 and Gemini 2.o pro respectively) with DeepSeek R1 being one of the best overall!
That said the "mini models" from OpenAI, both o1-mini and o3-mini seem to be not as good.
Two more benchmarks - FACTS Grounding benchmarks & Vectara's Hughes Hallucination Evaluation Model.
The next two benchmarks are more conventional, they attempt to automate the process of detecting hallucinations in outputs using LLM as a judge. This method is increasingly popular despite the known fact that LLMs tend to favour outputs from their own family of models but there was ways to migitate.
A similar benchmark on RAGs Factuality was the FACTS Grounding benchmarks

This benchmark shows the Gemini models on top of the leader board, particularly the new Gemini-2-flash-exp and the various Gemini-1.5 models. Surprisingly, it shows not only o1-mini but also o1-preview at the bottom of the pack. In fact o1-mini and o1-preview is even worse than GPT4o-mini!
That said, given this benchmark is by Google Deepmind it is reasonable to be skeptical of the results, perhaps they just know how to get better results from the Gemini family of models?
Moreover, unlike the earlier benchmark, it like many others, uses LLM as a judge to evaluate the outputs for hallucinations. The judges used are Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet (new) and scores were averaged.
The last benchmark we will look at is Vectara's Hughes Hallucination Evaluation Model.

This is yet another leaderboard which is auto evaluated, this time using their own fine-tuned HHEM-2.1 hallucination evaluation model. See method and FAQ
Interestingly, this shows the power of the thinking models with OpenAI o1-mini just 0.1% off Gemini 2.0-flash (which is at 1.3%)
More amazingly, o3-mini-high which was just released at the time of this blog post is clear #1 at 0.8%, with the hallucination rate dipping below 1% for the first time!
Do thinking models reduce hallucinations or increase source faithfulness?
Looking at the three benchmarks LLM Confabulation (Hallucination) Leaderboard for RAG, FACTS Grounding benchmarks and Vectara's Hughes Hallucination Evaluation Model , the results are somewhat mixed.
Vectara's Hughes Hallucination Evaluation Model. seem to indicate "thinking models" may hallucinate less with the o3-mini being clear #1 and o1-mini in the top #4. On the other hand, Google's thinking model Gemini 2.0-Flash-thinking-exp is worse than Gemini 2.0-flash-exp by 0.5%
LLM Confabulation (Hallucination) Leaderboard for RAG which has tested only 2 reasoning models- o1-preview and o1-mini , also gives mixed results, showing top performance for o1-preview but with poor results for o1-mini.
FACTS Grounding benchmarks seem to show thinking models are by far the worse with o1 and o1-mini right at the bottom!
My own ancedotal testing shows mixed results. Sometimes when there are many conflicting or wrong context found, o3-mini is able to reason it's way out to decide which sources to use.
Other times it will "overthink", e.g. once it decided during it's thought process that listing all members of a certain library department extracted from a public website is morally wrong bcause it is privacy invading! This did not happen with a typical GPT_4o search.
The excellent source faithfulness of Gemini 1.5/2.0 pro
Leaving aside the thinking models, it does seem Gemini 1.5/2.o pro models are quite good at avoiding hallucinations and/or being source faithful in all three benchmarks. I in fact had noticed this while playing around with Google notebookLM before I even looked at a single benchmark.
In the example below, despite asking GPT4o to answer only strictly from the abstract (this instruction sometimes helps), it still leaps to the conclusion neural embedding will retrieve more papers coauthored by males when in fact, the paper only looked at the amount of "gender-related concepts" rather than looking at the gender of authors.

This particular issue seems quite widespread and I tested on various RAG systems like Elicit.com, Undermind, SciSpace, GPT4o etc and they all "jumped to the conclusion" giving the answer "yes".
The first system that I saw avoided this issue was Gemini 2.0 in NotebookLM

Like many I started playing with NotebookLM mainly because of the viral "audio overviews" (see my review here).
But as I played with it, I noticed how good it was at data extraction.

While many tools like Elicit.com, SciSpace, Scite.ai assistant can generate table of studies, Google NotebookLM was the first i noticed that could create multiple rows for individual papers if there were multiple experiments in the paper!
But then I also started noticing how source faithful, NotebookLM (which was using Gemini 2.0) was. You didn't even need to ask it to answer only from the source (I suspect it is in the system instructions).
In fact, up to recently, no other LLM or RAG system I tried could avoid hallucinating on this except GPT-o1.
Interestingly, even GPT-o3-high and DeepSeek-R1 gets this wrong, even though the reasoning trace says it recognises the gender bias is not in coauthorship specifics but it still says yes.

LLMs fail to be source faithful because they make jumps/connections based on implict knowledge

In the above example using o3-high you can see the LLM make an unwarranted assumption and as a result gets it wrong (more male concepts in the text does not imply paper is authored by males!).
I suspect, most people would agree this is a unjustifed assumption to make.
Given that Gemini 2.0 in Google NotebookLM was the only system I find that does not jump to conclusion, I had a hunch it was very source faithful. But was there a trade-off? Would it be too faithful that it would refuse to make logical implicit assumptions that any reasonable human would do? I tried to find out in the next scenario.
Taking office of Prime Minister vs birthday
First, I loaded a new Google NotebookLM with just one sentence
Lee Kuan Yew was Prime minister of Singapore from 1959 to 1995
I then asked - Was Lee Kuan Yew born before 1959?

Logically, to be Prime Minister, one would be of a certain reasonable age, and based on the source, most humans would safely conclude he was almost 99.99% likely be born before 1959.
But okay so maybe this was a bit ambiguous without the exact dates.
The most airtight scenario I had stated
a) Lee Kuan Yew was Prime Minister from Jan 1, 1959 and
b) Asked if he was born after Jan 2, 1959.
Logically, the answer has to be No! unless one can be PM before one is born!
But Google NotebookLM still fails yet GPT-4o passes this one.

How well do reasoning models do?
Reasoning models like o3-mini are interesting. For scenarios, where it was logically possible but unlikely for someone to be born just before taking office, they are able to reason that while this was possible it was extremely unlikely.
In the summary of the reasoning trace below, it seem to assume to be Prime Minister one needs to be 18! (Not a bad guess, In actuality in Singapore as of now, you need to be 21 to be a MP and the Prime Minister has always been chosen from an MP, so you need to be at least 21 to be Prime Minister).
Trying some other date ranges and playing around I find DeepSeek-R1 makes different but usually reasonable assumptions (e.g. one time it assumed you had to be in your 30s to be PM).

DeepSeek R1 unsurprisingly is typically capable of reasoning similarly.

Use of Implicit World Knowledge vs source faithfulness
This question about how much implicit world knowledge should be used to generate an answer before a RAG system is considered unfaithful is a tricky issue that some other researchers have also noticed.
For example in this paper that constructed RAGTruth - a corpus used for testing of hallucinations for RAG system the author noted the following
Implicit Truth- The extensive world knowledge and ability of LLMs is a significant advantage in open-ended generation scenarios. But in the context of this paper, which focuses on the relatively strict RAG scenarios, we have labeled information that is not mentioned in the reference but may be truthful as hallucinations. For instance, mentioning a local officer’s name not present in the reference or claiming that a restaurant accepts credit card payments without any basis
In other words, if the RAG generates a statement that mentions something that is fairly common sense or likely to be true -e.g. a restaurant accepts credit cards but yet is not in the sources, should this be considered a hallucination?
The RAGTruth paper avoids making a ruling on this by annotating such sections of text as "implicit_true".
Most of the evals or benchmarks we consider here like RAGTruth cover fairly layperson topics. In the case of RAGtruth the main tasks tested included
a) news summarization and
b) Generation of an overview from businesses in the restaurant and nightlife categories from the Yelp Open dataset (in Json)
With academic RAG, these issues get even more serious because what is "common sense/external knowledge" for one person might not be so for a expert in the topic.
For example, there was this interesting point made on X with regards to what is "common external knowledge" for medical topics.

https://x.com/artur_nowak/status/1868213722063523952
At the start of this post, I mentioned how some authors distinguish between "Intrinsic hallucination" (where LLM generated answer contradicts the retrieved sources) vs "Extrinsic hallucinations" (where LLM generated answer is not supported by retrieved sources but neither does it contradict the retrieved sources).
So in the above example, the generated answer clearly isn't a instrinic hallucination since it doesn't contradict the source but is it a extrinsic hallucination? Your answer, might depend on whether you think it is "obvious" what the retrieved source implies!
Conclusion
I have spent a lot of time researching, reading and thinking about the practice of doing evaluations of RAG systems and it is a complicated!
One way to think about RAG is to see it has
a) A retrieval task
b) A summarization task of retrieved context
While measuring and comparing performance of information retrieval systems is hardly trival, we have decades of experience and thinking to fall back on. From the solid foundations going back to the Cranfield experiments in the 1960s, followed by the Text REtrieval Conference (TREC) competitions in the 90s until today on how to evaluate relevancy of results.
Somewhat tricker and less familar to me is the evaluation of the summarization task and evaluation of the whole RAG task that encompass both retrieval and summarization. We will discuss this in the next blog post.