
Why entering your query in natural question leads to better result than keyword searching with the latest AI powered (Dense retrieval/embedding models) search

One of the tricks about using the newer "AI powered" search systems like Elicit, SciSpace and even JSTOR experiment search is that they recommend that you type in your query or what you want in full natural language and not keyword search style (where you drop the stop words) for better results.
So for example do
Is there an open access citation advantage?
as opposed to
open access citation advantage?
You also see many of the new AI powered search tools like Scopus AI, Dimensions researchGPT showing examples when the query is done in a natural language query way.
Such tools certainly are capable of interpreting queries whether you type in natural language or keyword. For example, as a silly example of a simple way to handle natural language search, is to simply drop all stops words in a query before searching which means there is no difference either way of searching but they are obviously doing more advanced things.
There is a distinction between tools that are pure search engine that interprete all input as search (e.g. Elicit, SciSpace) and LLM style chatbots that use search as a tool (e.g. Scite assistant, Dimensions ResearchGPT), the later certainly are designed to handle natural language.
But which is better? Or is there a difference?
Ranking of documents vs direct answer from RAG
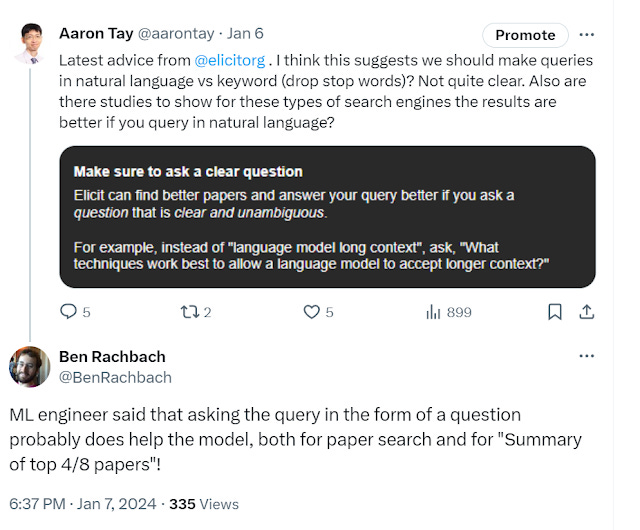
In the above tweet, the Elicit engineer talks about how asking queries in a form of a question helps both the "paper search" and "summary for top 4/8 papers".
Many of these new "AI powered" or embedding based search (or neural search or dense retrievial method etc..) , these days also combine search results with a Large Language Model autoregressive decoder like GPT4 and use RAG (Retrieval Augmented Generation), to generate a direct answer.' In elicit this section is called "Summary for top x papers".
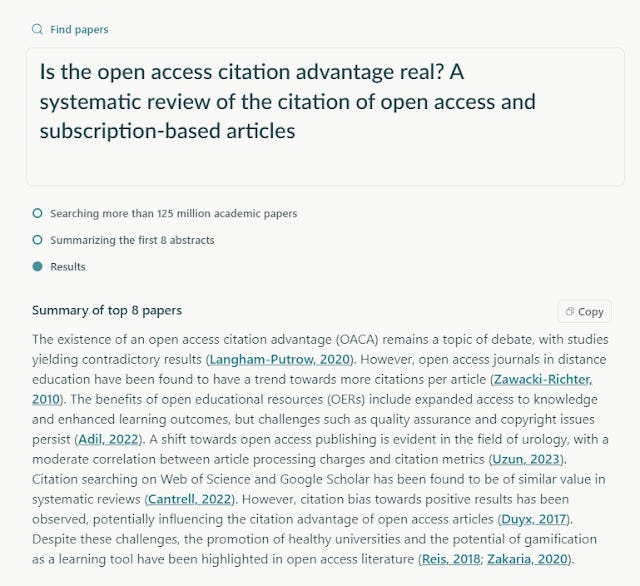
But not every "AI powered search" will offer RAG style form of answers, many will still return a conventional list of documents but they will often now be ranked (at least partly) using embedding based type searches to do "semantic search" (via dense embedding search) and not just lexical based (typically BM25) approaches.
JSTOR's experimental search is just one example.
So the question to be clear is , for such searches do we expect "better results" in terms of better relevancy for the ranking of the documents surfaced when searching using natural language as opposed to keyword searches (by dropping stop words).
Using purely theory we indeed expect that to be the case because unlike standard bag of word/lexical search methods, these new embedding type search ( BERT type in the 2020s) are able to take into account order of words using self-attention mechanisms , in particularly for words that are seen as stop words.
Below shows a simplistic example of how embeddings can "understand" words in the context of a sentence rather than just by individual words.
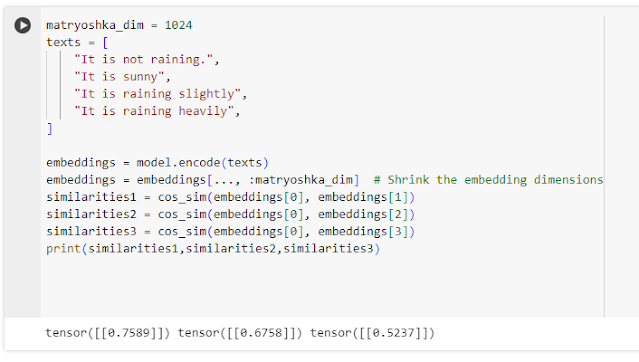
Above shows that when you embedding the above four sentences in a state of art sentence embedding model and try to compute cosine similarity, the system knows that "It is not raining outside!" is most similar to "It is sunny" (score=0.7589) as opposed to "It is raining slightly" (score=0.6758) and "It is raining heavily (score=0.5237).
It seems to "understand" the "not" in that sentence modifies "raining"...
But is there any evidence that shows doing query in natural language as opposed to doing keyword style searches where you drop stopwords leads to better results in term of recall , precision?
Ancedotally, I have found, this is true when playing around with Elicit, JSTOR experimental search where searching with natural language gives better results but do we have more rigorous evidence?
Will academic searches adopt (dense) embedding based search?
It's unclear currently how many traditional academic search are using these new methods dense embedding retrievial and reranking, but the newer ones that incorporate RAG almost certainly are because it is a natural fit.
That said it is possible to implement RAG without dense embedding search or vice-versa implement dense embedding search without doing RAG.
I think it is likely that more and more academic search in years to come will do so as their effectiveness becomes recognized (Google has already been using BERT sentence transformers since 2019!) and or the pressure to incorporate RAG type searches, naturally encourages the use of embedding search
Evidence from BERT type models in the early 2020s
When the first transformers became popular, the encoder only transformer model - BERT was employed as a reranker (also known as cross encoder).
The typical setup was to do a first stage retrievial using a lexical search method, BM25 (an evolved version of TF-IDF) and do a rerank of the results using a BERT model known as monoBERT.
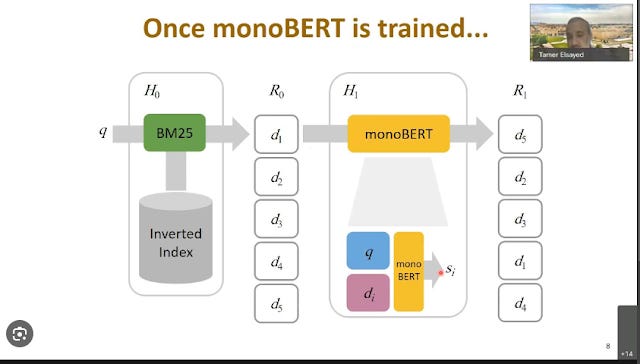
In information retrieval tests, people traditionally focus on TREC test runs to run experiments.
Below is a topic example from the famous TREC tests.

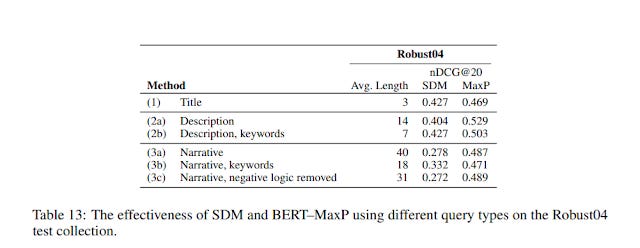
The question is how well do BERT type models do when one enters, "title", "description", "narrative" as the query. Note that in TREC, "Title" is actually just keywords for the topic, while "Description" and narrative" are single sentence and multiple sentence labels for the topic.
Before is from the work of Dai and Callan [2019b] as reported in Pretrained Transformers for Text Ranking: BERT and Beyond
The "Narrative" even includes a sentence on "negatives" (negative logic), what is NOT relevant.
Focus on the column MaXP (this is technically BERT–MaxP, a variant of BERT). But what is MaxP?
Because of limited contextual windows of BERT, you need a way to break up documents into chunks of passages. This means each passage will have a different score and you will need to find a way to score a document that is made of different passage scores. BERT-MAXP is a variant that "take the maximum passage score as the document score". There are other variants that take the sum of passage scores etc.
The first thing you notice is that MaxP has the highest nDCG@20 for "Description" (row 2a) = 0.529, much higher than "Title" (row 1) -0.469. In other words entering the query as a full longer natural language query (average 14 words) gives better results than just a short query (average 3 words).
But you may think well maybe "Title" (row 1), just have too little query terms. But if you take the "Description" (row 2a) = 0.529 and just take the keywords or removed the stopwords you get the "Description keywords" (row 2b) = 0.503 and compare you notice the score drops.
Interestingly entering the "Narrative" (row 3a) = 0.487 doesn't do as well. But even then if you just do keywords, "Narrative, keywords" (row 3b) = 0.471, the score drops a little.
Removing tne "negative logic" (row 3c) = 0.489 gets roughly the same results as just the narrative.
So it seems, removing stopwords hurts BERT type models but you might still be not convinced that this is a characteristic of BERT models. This is where the comparison column for "SDM" comes in.
SDM is a standard bag of word approach, and "contributes evidence from query bigrams that occur in the documents (both ordered and unordered)".
You can see for this standard bag of words approach, the best score comes from "Title" (row 1) =0.469. If you enter the full sentence query from Description" (row 2a) = 0.404 , the score drops. But if you drop the keywords in the Description, "Description, keywords" (row 2b) = 0.427, the score jumps back.
You can see the same pattern for "Narrative" (row 3a) and "Narrative, keyword" (row 3b). In other words, SDM a standard bag of word approach tends to do better with keywords and gets "confused" by longer sentences with stop words!
Some authors tried to look at the attention patterns in the BERT model and they noticed specific ways in which the "stop words" helped. For example for the query
“Where are wind power installations located?”, a high-scoring passage contains the sentence “There were 1,200 wind power installations in Germany.” Here, the preposition in the document “in” received the strongest attention from the term “where” in the topic description. The preposition appears in the phrase “in Germany”, which precisely answers a “where” question. This represents a concrete example where non-content words play an important role in relevance matching: these are exactly the types of terms that would be discarded with exact match techniques!
Clearly if you dropped the "in" as a stopword here, the results would be worse.
The cool thing is the work of Dai and Callan [2019b] was successfully replicated by Zhang et al. [2021] on a different dataset showing that for BERT type models, dropping stop words worsen results.
Evidence from query expansion techniques
The age old problem of Information Retrieval, is always around the issue of "vocabulory mismatch". The fact that when we issue a query we may express or represent it in a different way than what is expressed or represented in a document. This is worsened by the fact that there is an asymmetry between the length of a query which tends to be short and the document which is much longer.
There are two broad ways to try to reduce this problem
Query expansion (query will expanded at search time)
Document expansion (document is enriched with more terms during indexing time)
Query expansion techniques are easier to test than document expansion techniques because you don't need to do indexing of documents with every change. Document expansion techniques have "more to work with", because documents are far longer and richer than queries and have more context to work with, which helps state of art NLP techiques".
But here we are discussing query expansion, and as the name suggests you expand the query to increase the chance the query will match documents that are relevant.
For example if you query with "heart attack" it might expand your query to match "Myocardial Infarction" (typical example that made it rounds in the library industry in the 2010s).
Technically speaking query expansion can not only add new query terms (query rewriting) to the search but change the weight of query terms (query reweighting) and may do one or other or both.
There are bewildering number of ways to do query expansion for example, you could expand queries based on traditional methods like therasus, ontologies all the way to using the latest LLMs to prompt for synoymns or query terms for expansion or even the idea of Hypothetical Document Embedding (HyDE).
This is a technique where the LLM is asked to generate N hypothetical documents(responses) that answers the user question, they then encode the n hypothethical documents into embeddings, and average the embedding and use that as the query embedding!
Another way to think of query expansion is to think of them as global vs local document analysis strategies where global analysis expand queries independently of the results returned from it (analysis is on the global corpus) while local analysis will expand the query based on what documents are returned.
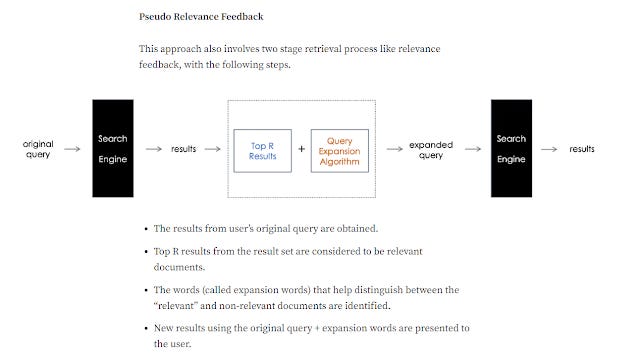
Local document analysis methods tend to be Pseudo-relevance feedback. Relevant feedback is an old idea, where the search engine will let the user give feedback on what is relevant. For example, the user may be prompted to select which of the top 10 results are relevant and that info will be used to adjust the search. One simple method is to just look at what the user indicates are relevant document and use that to do query expansion (e.g. use some of the words in those documents).
Pseudo-relevance feedback just dispenses with the actual user feedback , it may for example assume the top N ranked documents are relevant and use those to do query expansion. While this can sometimes be a bad idea (if the top ranked results happen to be bad), it generally helps more than hurts using standard lexical bag of word strategies.
https://kode-r.medium.com/search-deep-dive-query-expansion-f30183c2a564
One of the most popular traditional (Pre-BERT) query expansion psuedo relevance feedback method was RM3.
However,
As we’ve seen in Section 3, BERT often benefits from using well-formed natural language queries rather than bags of words or short phrases. This makes traditional query expansion methods like RM3 a poor fit, because they add new terms to a query without reformulating the output into natural language. The empirical impact is demonstrated by the experiments of Padaki et al. [2020] (already mentioned in Section 3.3.2), who found that expansion with RM3 actually reduced the effectiveness of BERT–MaxP. In contrast, replacing the original keyword query with a natural language query reformulation improved effectiveness
In short, because traditional query expansion methods just add keywords to expand rather than natural query, they actual hurt results rather then help for new BERT/LLM style systems.
Conclusion
In short it seems. "BERT can exploit linguistically rich descriptions of information needs that include non-content words to estimate relevance, which appears to be a departure from previous keyword search techniques."
Even though the evidence from this papers come from systems that used BERT as rerankers after a first stage retrievial BM25 search, and newer systems are likely to use a blend of lexical/sparse and dense retrieval matters at the first stage followed by perhaps rerankers using either Cross encoders (or even more advanced hybrid methods like COLBERT or new learned sparse representation methods such as SPLADE), it is likely the same conclusions apply.
It's unclear currently how many traditional academic search are using these new methods of retrievial and reranking, but it is likely they will be more and more in years to come as their effectiveness becomes recognized (Google has already been using BERT sentence transformers since 2019!)