
How should academic retrieval augmented generation (RAG) systems handle retracted works? (II)
I test with a low-profile retracted paper and consider yet another blind spot - uploaded PDFs of retracted papers into LLM systems

Introduction
In my previous post I tested eight academic RAG or RAG‑like tools—Elicit, scite assistant, SciSpace, Primo Research Assistant, Undermind, AI2 Scholar QA, and several "Deep Research" modes from OpenAI, Gemini, and Perplexity—to see how they handled a well‑publicised 2020 paper that has since been retracted: “The association between early‑career informal mentorship in academic collaborations and junior‑author performance.”
Turning the paper’s title into a question and feeding it to each system causes the RAG system to retrieve—and summarise—the retracted study.
Some platforms (e.g. Elicit’s Find paper mode, AI2 Scholar QA, and the various web‑based Deep Research tools) did way to flag the retraction and even contextualize the studies.

Ai2 ScholarQA did well in the last test
Others like scite assistant, SciSpace, Undermind, Primo Research Assistant did badly and summarized the work without mentioning its retracted status in the generated text.

Undermind.ai failed by just summarizing the study and not mentioning the retraction
A few services, like Scopus AI, quietly filtered the paper out of the results entirely.
That led me to wonder: was the test simply too easy? The Nature Communications paper is famous; it has been dissected on Retraction Watch, PubPeer, and in formal commentaries in journal articles. Some of these tools like AI2 Scholar QA may have been using the citation context/statements in other articles to flag the retractions.
A tougher test: a “quiet” 2020 retraction
To find out, I picked another 2020 article that was retracted without much fanfare (a single Retraction Watch post and one brief PubPeer comment - pointing back to the Retraction Watch Post but zero mentions in other journal articles). In this case, what happened was a reader spotted analytical errors; the authors and journal moved quickly, and the paper quietly retracted in June 2021.
The example I chose was the following also 2020 paper

How did the tools cope?
With much less discussion on the retraction how did the Academic RAG tools do?
Short answer: much worse than before.
AI2 Scholar QA that did well the last time by not just describing the retracted paper but also mentioned the critiques of the paper and its eventual retraction. But here it failed and just cited and summarized the retracted paper without any mention of a retraction.

Primo Research Assistant failed same as before.

In this test case, Undermind.ai was the only one that passed by mentioning the study was retracted.

It’s interesting to note that while Undermind failed in the last blog post, it succeeded here. Looking at the reference lists of both reports, you can see that this comes down to the metadata available to Undermind. When Undermind’s metadata includes RETRACTED in the title, Undermind can and often does succeed in using that information.

When it doesn’t, it definitely fails

General Web Deep Search worked well as usual
As before, OpenAI and Gemini Deep Research which searches the general web easily picked up on the retraction notice from the Retraction Watch post.

OpenAI Deep Research mentions paper is retracted

Gemini Open Research mentions paper is retracted
Elicit.com, SciSpace, Scite.ai assistant side-stepped the test (sort of)
In my earlier test, with another retracted paper, I had zero problems getting the retracted paper retrieved in each Academic RAG’s Top N results and hence used in the RAG answer.
This time around, I struggled, I could not initially get Elicit.com, SciSpace or Scite.ai assistant to retrieve the retracted paper that I was testing! Let’s see what is going on….
Playing Hide and Seek with SciSpace
SciSpace simply refused to surface the retracted paper I was looking for using the usual methods of either converting the title to a question or just straight out entering the title of the paper.
In the end, I searched the title, filtering it to 2020 and finally filtered it down to the journal before the result appeared!

The Strange Case of Scite.ai Assistant
Scite.ai was particularly puzzling, since I confirmed the paper was indeed indexed in the normal scite.ai search, albeit it was noted to be retracted (see below).

Yet no matter how I tried the scite.ai assistant would never surface the paper! This is so even after setting it to try to use 100 publications and filtering it down to the year of publication and publication title!
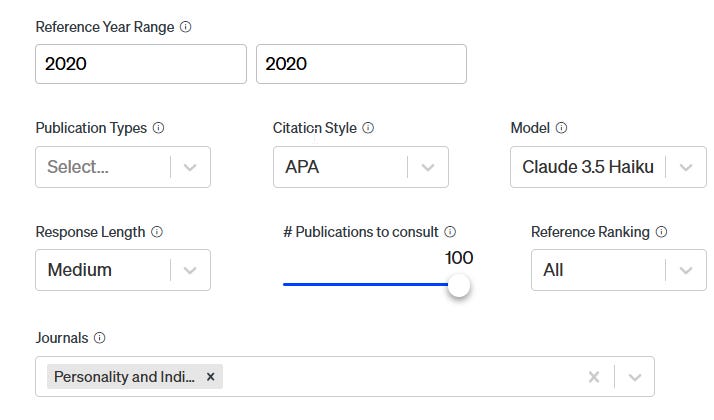
Perhaps, it was filtering out retracted works like Scopus AI? This seems unlikely because in the earlier test, the same thing was happening (paper flagged as retracted) yet scite still happily surfaced the paper.

In the end, I created a custom scite.ai dashboard with that paper in it and forced scite.ai assistant to use it.
Missing paper in Elicit.com
Elicit, which impressed me last time by being the only non-deep research tool to contextualising the high‑profile retraction, could not find this low‑profile retracted at all—even with use of Elicit’s advanced title/journal filter queries! Was it simply not indexed? It might be some error on my part!
[Speculation] High‑profile vs. low‑profile retractions
In fairness, SciSpace, scite assistant, and Elicit deserve a pass or borderline pass as it took heroic searching attempts to push the retracted article high enough in the ranking for their RAG pipelines to use it.
My working theory is that some of these tools apply a steep relevance penalty to any paper flagged as retracted, which is why they are so hard to surface and are unlikely to be used in RAG. Perhaps, it might be better to follow the approach of Scopus AI and Web of Science Research Assistant and take the more blunt‑instrument approach to simply exclude such papers altogether?
So why did the Nature Communications study in my previous post surface so easily? My guess is that the other paper had other signals that compensated for the penalty. For example, Scite assistant lists that retracted paper has having 40+ citations.
Uploading PDFs: another blind spot
Many RAG tools (like Elicit, SciSpace, Scite assistant) and general LLM chatbots let users upload PDFs. If the PDF shows no obvious watermark or header, the system may not know the paper is retracted.
Note: Many Publishers now have license terms that forbid uploading of their content into public AI cloud systems
As you might expect, if you upload a PDF of the retracted paper that does not indicate it is retracted these systems will not be able to know the paper is retracted either.

PDF of Retracted paper - with no sign it was retracted.
A sharp‑eyed human could click the tiny Crossmark “Check for Updates” badge on the right of the title and learn the paper was pulled—but most readers never do, and a RAG pipeline certainly won’t.
Google NoteBook LLM
Notebook LM sticks strictly to local content, so it never alerts you if you upload a retracted paper.
What if instead you uploaded the PDF that has the words RETRACTED IN BOLD across the whole page?

Surely the LLM will “see” the words “RETRACTION” in bold?

Unfortunately, even a bold “RETRACTED” stamp often slips past the parser in the LLM unless you explicitly ask if the paper is retracted!
ChatGPT & Gemini
Using OpenAI’s top o3 model of the time (which has search capabilities), if I upload the PDF of the paper (without the obvious retraction stamp) and ask it to summarise, it happily summarises without “noticing” the paper is retracted.
Sadly, like Google Notebook LM even if you upload the PDF that is obviously retracted (with the big retraction stamp) it will not think to warn you.
Gemini 2.5 Pro is the same for both cases.
Scite assistant, Elicit, SciSpace
Nothing much to report here, they too don’t “realize” the paper is retracted as well if you upload the PDF (with or without retraction stamp).
Interface labels aren’t enough
While drafting this post I stumbled on a mini‑study by another academic library that examined retractions in Elicit, Consensus.ai, and SciSpace. Their scope was narrow: do these search engines visibly label retracted articles in the results list? The answer was sometimes.
My tests, however, show that surface‑level badges are only the first hurdle. A RAG pipeline can ingest the very same correctly‑flagged record—scite assistant and Primo both do—and still quote or summarise it without passing the warning through to the answer. Labelling at retrieval is therefore necessary but not sufficient: the retraction status must travel intact through the entire cite‑and‑generate chain.
On the other hand, Undermind.ai seems to be quite reliable at using the retraction information if available. Others like Ai2 ResearchQA seem to be relying on the citation context/statements made by citing papers.
Why citing retracted work can hurt you
Not every citation of a retracted work is problematic—scholars may cite it BECAUSE it is retracted and say so, or in a context where the citing work is not reliant on the retracted cited works.
However, if your work has dozens of citations to retracted works or if your citing work relies centrally on the retracted cited works there might be an issue and tools like Feet of Clay detector can potentially detect such works.
Recommendations for RAG builders
Sync with Retraction Watch. The database is now freely accessible via API or CSV —no excuse not to ingest it.
Default filter retracted works at the retrieval stage (à la Scopus AI / Web of Science Research Assistant).
Optional “red‑flag” mode: if a retracted work is retrieved (e.g. for historical analysis), mark it clearly as retracted in the in-text citations (ideally using non-LLM methods like regexp) and feed the retraction notice to the generator to provide context.
PDF uploads: attempt DOI extraction → lookup → retraction check. Warn the user if the paper is retracted, even if the PDF itself is silent.
Conclusion
High‑profile retractions generate enough noise that many academic RAG systems can detect them—sometimes by sheer popularity. For low‑profile cases, most academic RAG tools might surface it without any warning. Until they integrate systematic retraction data and build explicit safeguards, we risk letting discredited science creep silently back into the scholarly record as use of Academic RAG systems rises.