
The AI powered Library Search That Refused to Search
From Clarivate's Summon to Primo Research Assistant, content‑moderation layers meant mostly for chatbots are "quietly" blocking controversial topics from being searched

Disclosure : I am currently a member of Clarivate Academia AI Advisory Council but I am writing this in my personal capacity.
Imagine a first‑year student typing “Tulsa race riot” into the library search box and being greeted with zero results—or worse, an error suggesting the topic itself is off‑limits.
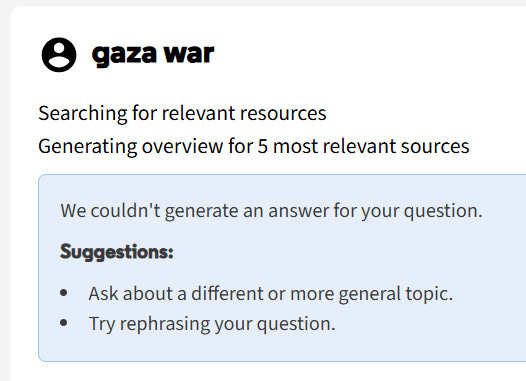
That is exactly what Jay Singley reported in ACRLog when testing Summon Research Assistant, and it matches what I’ve found in my own tests with the functionally similar Primo Research Assistant (both are by Clarivate).
Primo Research Assistant and Summon Research Assistant use LLMs to generate search strategies from your inputs - for more details.
The problem was first highlighted with queries like "Tulsa race riot" and "Tulsa race massacre" but further investigation shows it affects a wide range of topics, from historical atrocities to current events.

ACRLog post “We Couldn’t Generate an Answer for your Question”
Before we jump to conclusions that this is deliberate censorship, we should remember to “Never attribute to malice, what can be attributed to….”
Note: I am seeing conspiracy theories based on the location of the company's HQ. I will simply note that query phrases that include “holocaust” are getting errors as well…
According to Ex Libris, the culprit is a content‑filtering layer imposed by Azure OpenAI, the service that underpins Summon Research Assistant and its Primo cousin. Microsoft’s filter uses neural classifiers to score every prompt input and text generation across four categories— “hate and fairness”, “sexual”, “violence”, “self‑harm”—at four severity levels (safe → high).
Below are some of the topics under the four categories that might be flagged
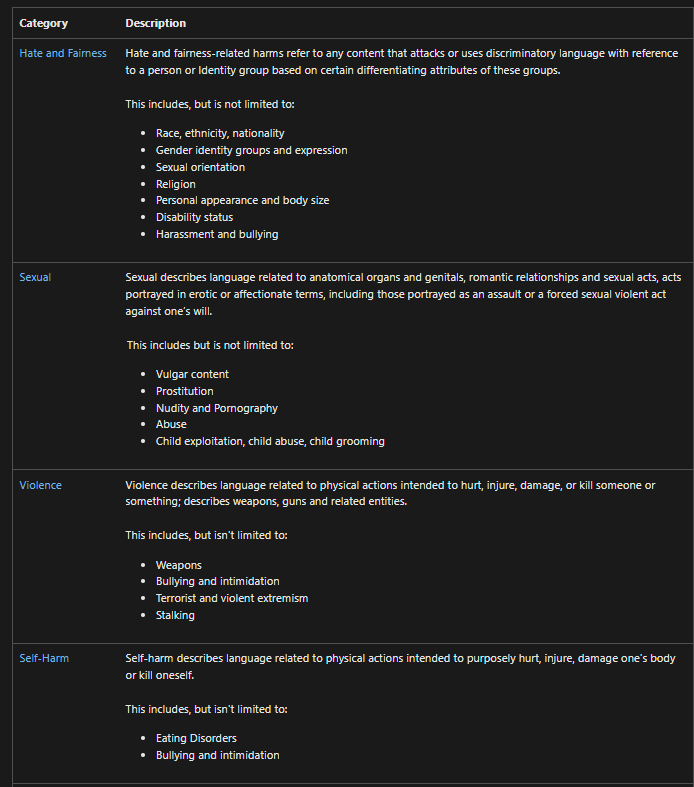
These filters are not pattern‑based but rely on “neural multi‑class classification models aimed at detecting and filtering harmful content,” which makes it difficult to predict exactly which inputs or outputs will be filtered. We are also told in the documents these content filters primarily work in English, German, Japanese, Spanish, French, Italian, Portuguese, and Chinese.
Test results with Primo Research Assistant
In my own testing, Primo Research Assistant was especially sensitive to the word “massacre” Entering
<something> massacre
almost always triggered errors, though the search itself sometimes still ran.

By contrast, entering
This is a massacre
worked fine without errors.
Errors are frustrating enough, but even worse are the cases where Primo Research Assistant returns zero results, such as with the query
Gaza War
This cannot be true—Primo Research Assistant is searching the entire CDI (with few exceptions), which contains over a billion items.
The difference in behavior might be related to the severity level flagged by the filter. In lower‑severity cases, the LLM generates text but includes a warning; at higher severity levels, it simply refuses to work.
To illustrate again that these filters are not rule‑based, a small wording change from “Gaza War” to
War in Gaza
is enough for the query to pass without even a warning.

How widespread is this issue?
Quick checks with Scopus AI and a variety of other “AI‑powered” academic search tools such as Scite Assistant, Undermind.ai, SciSpace etc showed seemingly no issues with terms like
Gaza War, Tulsa Race Riot or Massacre
But testing for LLM use in AI‑powered academic search tools is challenging because these models are now integrated at multiple points in the pipeline. For example:
Expanding input into Boolean search strategies: Scopus AI, Web of Science Research Assistant, Primo Research Assistant, EBSCO Natural Language Search etc.
Suggesting search terms: ProQuest Research Assistant etc
Clarifying query intent: Undermind.ai, OpenAI Deep Research etc
Summarizing single documents: EBSCOhost AI Insights, ProQuest/Ebook Central Research Assistant etc
Generating answers from retrieved documents: All Retrieval‑Augmented Generation (RAG) systems
Deciding what and how to query: Deep Search tools
Evaluating relevance directly: Deep Search tools
I won’t go into every test here, but Clarivate‑related products seem more affected than most, while other AI‑powered academic search tools remain largely unaffected.
1. Web of Science Smart Search - seems to give an error.
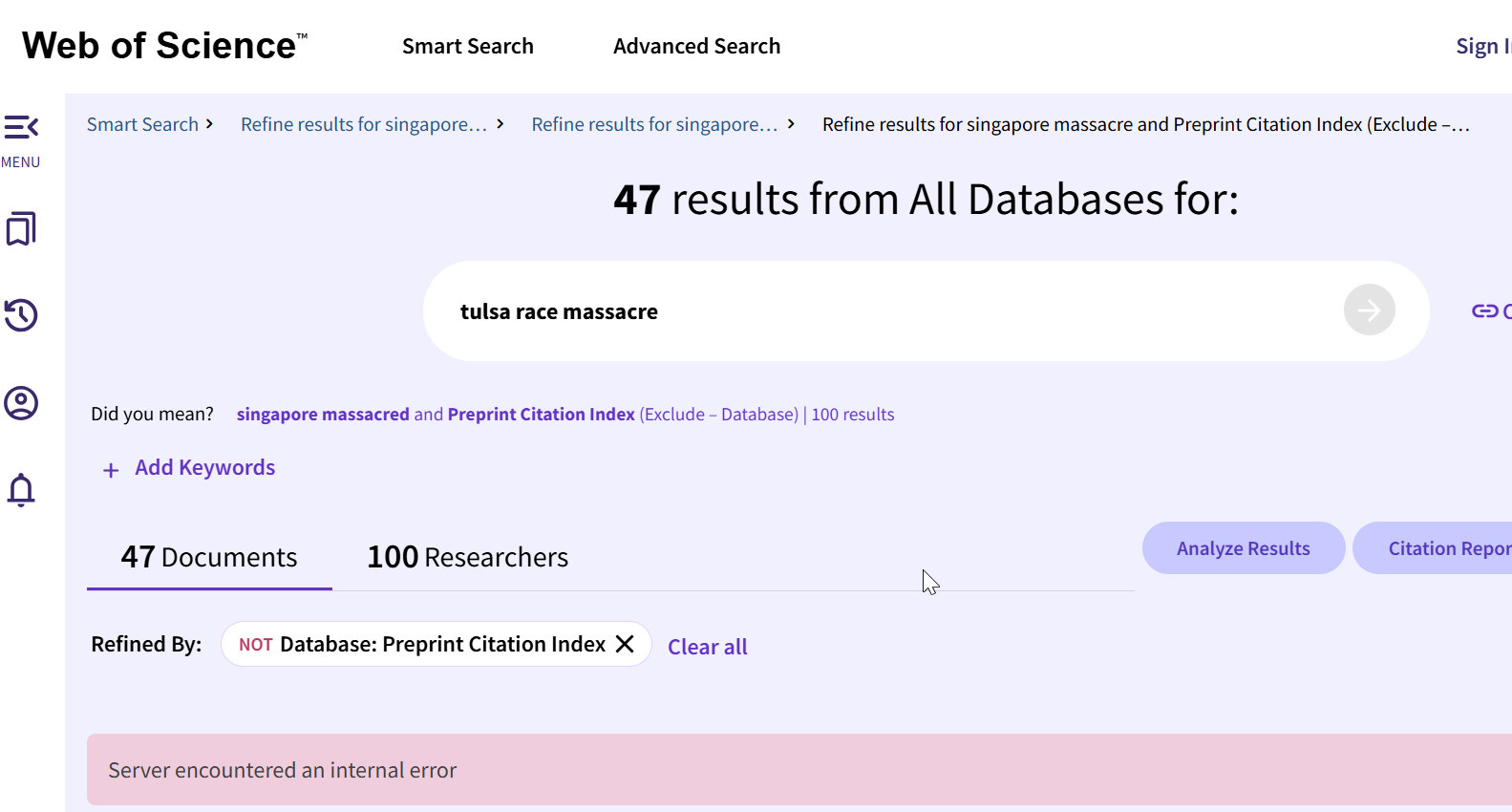
Proquest Research Assistant seems to be able to generate suggested terms using a LLM for
Tulsa race riots

Note: An earlier version said Proquest Research Assistant wasn’t able to do. That was a mistake, I was referring to Ebscohost Natural Language Search.
To be fair, Clarivate products like Ebook Central Research Assistant and ProQuest Research Assistant (on databases like PQDT) work as expected for summarization and for PQDT it will even suggest terms for sensitive topics despite claiming to use a LLM to suggest terms.
It also appears EBSCOhost Natural Language Search may have its own issues, as it does not expand “Tulsa Race Riot.” But this needs more testing.
How serious is this problem?
At first, I assumed these failures stemmed from the “guardrails” built into the LLMs themselves. However, it turns out the issue originates from an external third‑party platform—Azure OpenAI—rather than the LLM.
This dual‑layer filtering is designed to protect risk‑averse companies from generating harmful or inappropriate content, and it likely errs heavily on the side of caution. Guardrails put in place by the LLM developers themselves are likely less aggressive because an LLM that over‑censors is unpopular with end users.
But a system designed to sanitize chatbot conversations does not serve the purpose of academic search. It actively undermines it. Scholarly inquiry often requires engaging directly with precisely these sensitive topics.
Assuming the filtering can be tuned or disabled (as other products appear to demonstrate), are we out of the woods?
Guardrails in the LLM
Even before this incident, I was worried about bias in LLMs.
The issue we’ve seen here at least fails openly with zero results—someone will eventually notice, and the problem can be fixed.
Far more insidious would be a bias that isn’t obvious.
We know LLMs have guardrails that prevent them from assisting with harmful or illegal topics (e.g., nuclear, biological, or chemical weapons). But what happens when you search on those topics in an AI‑powered search engine?
If the LLM only generates a Boolean search strategy, it may fail outright (easily detected).
But if it is used to rank or classify papers, would the system silently downrank or ignore the most relevant ones? You might still get some tangentially relevant results, making the gap much harder to spot.
And if it is used in agentic search to steer the search, would it choose to avoid those papers entirely?
I have no idea really and all this pure speculation!
Note: Using LLMs for agentic search is distinct from using vector embeddings for semantic search. Some research shows that shifting from keyword based BM25 ranking to Vector embedding based search can result in some types of bias but this is a distinct issue from what we are discussing here. Parts of the retrieval pipeline that use vector embeddings (e.g. Scopus AI, SciSpace, Keenious) are unlikely to be caught by the Azure content filters except perhaps at the input side.
So, what do we do?
Honestly, this needs a lot more study and analysis by people more qualified than me. While the non-Clarivate products I tested seem to be mostly immune to the terms that trip up Primo and Summon Research Assistant, do these systems have their own “Kryptonite” that will cause them to collapse (due to built-in guardrails from the LLM itself)?
So in desperation, I fed this entire post into OpenAI’s o3 and asked it to write a conclusion, here’s what it produced:
Where does that leave us? If discovery layers are going to bolt LLMs onto the front of billion‑record indexes, then vendors owe us guardrails that are tuned for scholarship, not social‑media chatbots. As librarians we cannot accept a black‑box filter that silently deletes history—or worse, one that does so inconsistently and invisibly. At minimum we need (1) clear documentation of every moderation layer in the pipeline, (2) switch‑level controls that let libraries calibrate or disable those layers, and (3) public test suites so the community can audit whether “Tulsa race riot”‑type failures re‑emerge after every model update. Until we see that transparency, we should treat AI add‑ons as beta features—useful experiments, but never a substitute for the raw catalogue and our own critical judgment. If we don’t push for that accountability now, the next generation of discovery tools may quietly decide which topics are worth researching long before a student ever walks through our door.
[ADV] Want to Go Deeper into AI and Information Retrieval?
As I write this, I’ve just wrapped up my 3-session online workshop at FSCI 2025 – "AI-Powered Search in Libraries: A Crash Course on understanding the fundamentals for Library Professionals". Librarians and researchers (many who are regular readers of my blog!) from around the world attended—thank you for your support!
Due to limited capacity, we could only accommodate 60 participants and, unfortunately, had to turn away some who were interested.

I’m happy to share that we’ll be running the workshop again as a preconference event at the Charleston Conference Asia — the first time the conference will be held in Bangkok, Thailand. The event runs from January 26–28, 2026.
This second run of the workshop will be delivered in a hybrid format: two virtual sessions followed by a final in-person session in Bangkok on January 26.
Why attend this workshop?
Since 2021, I’ve been obsessively exploring information retrieval and the impact of AI on academic search—often “learning in the open” through a stream of blog posts written in a somewhat ad-hoc fashion.
This workshop was a rare chance for me to pause and take stock. What are the essential concepts librarians need to grasp to hold informed conversations with vendors about AI in search? What’s critical to understand, and what’s simply “nice to know”?
My goal was to equip librarians and researchers with a clear conceptual framework—one that helps them understand where and how “AI” could be applied across the search pipeline, and what different trade-offs or implications come with each type of use.
While I don’t consider myself a natural instructor, which is also why I teamed up with my co-instructor - Bella, I learned a great deal from the first run of this course—thanks to the thoughtful questions and generous feedback from participants who were genuinely eager to learn.
When Bella (my co-instructor) and I realized that some participants were logging in during the wee hours of the morning, we felt truly honored.
Bella and I will take what we learnt from our first run of the workshop to improve future runs to make it even better.
So I found the "Gaza war" error in Primo Research Assistant fascinating, but after some testing it gave the same error when I tried "dogs," "cats," "strawberries," and two-word phrases like "Imjin War," which I don't think gets many people excited anymore. Putting in "Jan 6 2021" gives the error, but so does "Dec 7 1941" ("July 4 1776" has results though). So I think there's also a problem with the system not being able to get clear results with very short strings, which is complicating some of the one-word prompts that fail.
Technical note: many academic "semantic search" uses encoder based vector embeddings for matching (eg SciSpace, Scopus Ai)
That part at least are unlikely to be subject to LLM guardrails or Azure content filters unless they are caught at the input side.
Compared to keyword based BM25 algorithm they may have biases but that's a different issue from LLM guardrails and content filters