
A Deep Dive into EBSCOhost's Natural Language Search and Web of Science Smart Search - Two bundled "Ai-powered"search (I)

My blog focuses on the two primary ways "AI"—or more accurately, transformer-based models—are impacting academic search. The first, and flashier application is in generating synthesized answers with citations from retrieved articles, a technique known as Retrieval Augmented Generation (RAG).
The second, which is the focus of this post, involves the rise of non-lexical or keyword search methods. Influenced by the widespread adoption of tools like ChatGPT, users are increasingly typing full questions into search engines instead of just keywords. Believing that this is the future, academic search platforms are rolling out features that are designed to translate these natural language queries into structured searches.
Personally, I am not convinced we are there yet, and I suspect most queries in academic search engines and databases are still keyword based (no stop words) though they may be longer than in the past, but I have not done log query analysis for years.
I’ve loosely termed these "Semantic Search" features, though as we'll see, that label doesn’t have a clear definition.
This post will examine EBSCOhost’s Natural Language Search (NLS) and, in the next post, Web of Science's Smart Search (not to be confused with Web of Science Research Assistant). Both are interesting because they introduce this "semantic" query translation layer without generating direct answers. They are also bundled into the core subscription, requiring no additional payment, unlike premium add-ons like Scopus AI or the Web of Science Research Assistant.
Before we proceed, this analysis builds on my previous explorations. For essential context, I recommend reading my posts on the reproducibility and interpretability of AI search engines and my comparative review of Primo Research Assistant, Scopus AI, and Web of Science Research Assistant.
Updating the image from the reproducibility and interpretability of AI search engines and focusing only on the retrieval step (ignoring the generation step), this is how EBSCO Natural Language Search (NLS) and Web of Science Smart Search stacks up against the rest.

EBSCOhost Natural Language Search (NLS)

EBSCO describes its Natural Language Search (NLS) feature as an "AI Natural Language Search Mode." It's an optional search mode that library administrators can enable for EBSCOhost databases and EBSCO Discovery Service (EDS). You can even set it as the default, though that's a decision that warrants careful consideration.
Note: I do not have access to EDS, so the testing and comments for this post, particularly with respect to the relevancy results applies only for use on the EBSCOhost platform.
How does it work? One description reads
Natural Language Search (NLS) allows users to conduct searches using conversational language, improving context understanding and retrieval accuracy. The system leverages EBSCO’s relevance ranking framework, subject query expansion via the Unified Subject Index, and linked data-controlled vocabularies to refine search results. AI-powered query expansion further enhances the interpretation of common language terms to align with researcher intent.
This is as clear as mud. What does “AI-powered query expansion” mean? The FAQ provides a more concrete explanation:
When a user initiates a search using NLS mode, the query is sent to a Large Language Model (LLM). The LLM assesses both the intent and context of the query, combining enhanced AI capabilities with EBSCO's existing search algorithm.
In short, the process is:
Your natural language query is sent to an LLM (currently Anthropic’s Claude 3 Haiku via AWS Bedrock).
The LLM, guided by a build-in prompt, converts your query into a sophisticated Boolean search string
This Boolean string is then executed by the standard EBSCOhost search engine, which applies its own relevance ranking and query expansion logic.
This workflow is nearly identical to the retrieval step in Web of Science Research Assistant. As I've noted previously, Primo Research Assistant and Scopus AI also employ a similar initial step, though they add other methods like a second stage embedding-based reranking (Primo Research Assistant) or a hybrid search employing both keyword and embedding based methods (Scopus AI).

Crucially, like its peers, EBSCOhost NLS allows you to see the exact Boolean search strategy generated by the LLM (after clicking on “show refined query”), which helps with transparency.
The NLS Boolean Strategy vs the others
The first thing that strikes me when looking at the generated Boolean strategies from NLS is how conservative they are. Compared to its competitors, NLS is far less aggressive in generating lengthy strings of synonyms.
For example, for the input
impact of climate change on biodiversity
NLS tends to produce a concise query like
((climate change OR global warming) AND (biodiversity OR ecosystem OR habitat))
This consists of two concept blocks with 2-3 synonyms each.
In stark contrast, Web of Science Research Assistant, for the same input, tends to generate a much more expansive query such as:
(climate change OR global warming OR climate variation OR climatic changes OR climate variability OR climate crisis OR climate emergency OR greenhouse gases OR anthropogenic climate change OR carbon emissions) AND (biodiversity OR species diversity OR ecosystem diversity OR biological diversity OR ecological diversity) AND (impact OR effect OR influence OR consequence)
This breaks the query into three concept blocks, with some containing as many as ten synonyms! This tendency toward overly broad queries is also common in Scopus AI (see image below) and Primo Research Assistant.

Query expansion with “AI” vs Subject Mapping
I've often found that the overly broad search strategies from other AI tools like Web of Science Research Assistant can lead to poor results if they aren't followed by a secondary reranking step. However, being too conservative isn't necessarily better.
That said, there's a compelling reason for NLS's restraint. It goes back to EBSCOhost's core search technology. EBSCO has long prided itself on its subject-controlled headings and recently completed the massive project to map and merge “hundreds of multidisciplinary controlled vocabularies”. together into the Unified Subject Index (USI).
Note: I am currently unsure if USI applies to only queries in EBSCO Discovery Service or also for normal searches on the EBSCOhost platform, either way at the very least query expansion with subject headings is a thing.

As their documentation shows, EBSCO already performs query expansion using the USI, a feature I think is activated by the "Apply equivalent subjects" option in a standard (non-NLS) search.

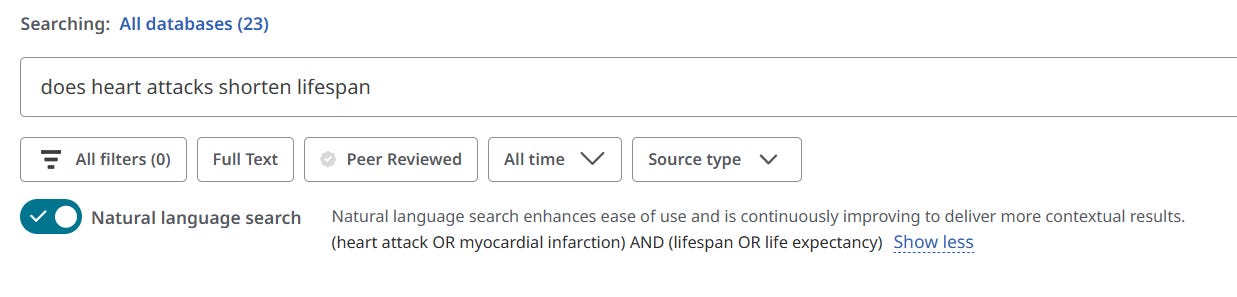
Let’s see how NLS interacts with the USI query expansion. For instance, the query
heart attack lifespan
in NLS expands to the simple Boolean
((heart attack) AND (lifespan OR life expectancy OR survival))
It notably omits the core medical term "Myocardial Infarction." However, the top result is an article that uses that exact term, likely because the USI automatically mapped "heart attack" to its corresponding subject heading behind the scenes.

This suggests the LLM isn't fine-tuned or designed somehow to pull terms from the USI lists; rather, the two systems work in sequence. The LLM creates a foundational Boolean query, and the USI enriches it.
I also notice with some query inputs, it does generate terms that are already in USI and as the image below shows the generated Boolean Search query by the LLM does use "Myocardial Infarction."
A Note on SmartText Search vs. NLS
Long-time EBSCOhost users might recall a search mode on the EBSCOhost platform called "SmartText Searching.". How is this different from NLS?
EBSCO does not consider such an approach as “AI”, choosing to reserve this terminology for NLS, which uses an LLM to understand intent and construct a Boolean query.
They are meant for two different use cases, with SmartText searching meant for scenarios where you throw in a sizable chunk of text and NLS for when you want to type your query in natural language.
Reproducibility & Interpretability
Whenever LLMs and AI are involved, questions of reproducibility and interpretability are paramount, especially for evidence synthesis experts.
On paper, NLS should be highly interpretable. It shows you the generated Boolean string, and the documentation implies it uses the standard EBSCO relevance ranking. This sounds very similar to Web of Science Research Assistant, which I found to be quite reproducible.
However, in practice, I could not consistently reproduce the NLS search results.
For example, for the query
impact of climate change on biodiversity
NLS generated a Boolean string
((climate change OR global warming) AND (biodiversity OR ecosystem OR habitat))
and returned a specific set of results.

When I took that exact Boolean string and ran it in the Advanced Search—with "Apply equivalent subjects" on and proximity mode active—I got the same number of results, but the ranking of the top 10 results was different.

Worse yet, more often than not, the number of results was completely different. For example, The NLS query,
is there an open access citation advantage
generated the following Boolean:
((open access) AND (citation advantage OR citation impact))
with 125 results

When I ran that exact string in Advanced Search, I got 708 results.
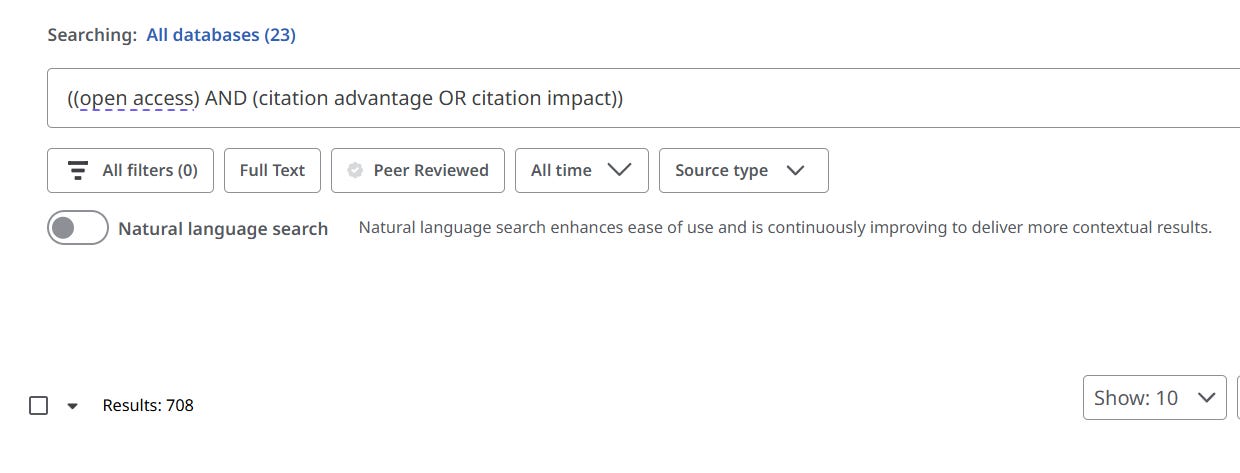
Even after turning all expanders off, I couldn't get the counts to align.

The best I could get is 628 results, with expanders all turned off, and using Proximity mode.

In short, I am unable to reproduce the search most of the time.
This leaves two possibilities: either I'm missing a key setting, or the NLS retrieval process is more complex than a simple "generate boolean with LLM and run" workflow.
EDIT 13 Feb 2026
Testing now shows that if I limit to 1 or 2 databases, I can indeed reproduce the search. I am not sure if this is due to the algo change or the fact that my initial testing is using all the databases we have (23).
What about the stability of the LLM itself?
Given their non-deterministic nature, one might expect the same query to produce slightly different Boolean strings on subsequent runs. Surprisingly, NLS is incredibly consistent.
I ran the same exact "open access" query from above more than 10 times in a row in one session, and then again even over the next two days, and it generated the exact same Boolean string every single time!
This rock-solid consistency is a stark contrast to peers like Primo Research Assistant or Web of Science Research Assistant, which often generates a difference Boolean Search Strategy at least once in 5 tries even within the same session.
It’s hard to tell what is going on, since LLM’s typically even if set with zero temperature tends to be slightly non-deterministic, but it may be caching LLM query expansions for extended periods?
Interestingly, the FAQ does suggest the Boolean Search Strategy can change in some situations, though this suggests a change due to the model.

So, in conclusion while the generated Boolean query is highly reproducible, the final results are not —a puzzling combination.
So, is NLS Mode Useful?
The million-dollar question is whether NLS delivers better results than a standard keyword search.
Based on my testing (limited to a set of institutionally subscribed EBSCOhost databases, not the full EDS which is tricky because of limited coverage), I have a few observations.
First, it usually succeeds at its primary goal: it prevents search failure when users input long, conversational sentences. A query that would return zero results in standard search can yield relevant articles in NLS mode.
For simple keyword or Boolean queries, NLS wisely steps aside and functions like a standard search.
For example, the following query fails in normal mode leading to no results.

With Natural Language Mode, it finds some relevant results

Second, it falls short of true “semantic search”.
“Semantic Search” is a loosely defined term that is defined as either everything that is not lexical/keyword based or more positively as a way for the system to “understand the meaning” of text rather than matching individual words. The current state of art way to achieve “semantic search” involves the generating and matching of embeddings (or more accurately typically dense embeddings). Using LLMs to try to interpret the query and generate a Boolean Search Strategy (a type of query rewriting) is definitely “AI powered search” or “query expansion or rewriting with LLM” but I argue isn’t really semantic search because at the end of the day you still run a keyword based Boolean search.
Take, for example, a search where you are looking for a study on the open access citation advantage that uses a randomized controlled trial (RCT)s. There are not many of such studies even after 20 years of research, but my institution has access to this paper (and the dissertation it's based on) via the EBSCOhost platform


In a tool like Elicit.com (find paper mode), which uses embedding-based search, a query like
open access citation advantage with rct
works perfectly, surfacing the exact paper and other relevant studies.

SciSpace (default search) also finds the relevant paper, but the remaining ones are not as relevant as in Elicit.

The same query in NLS mode fails (the 2 results found are not relevant) even with NLS mode.

I tried different variants of this query include longer ones, but they all failed
The problem here is that the target paper doesn't use the exact phrase "Open Access Citation Advantage." An embedding-based search engine understands that the meaning is the same, but NLS ultimately uses a strict Boolean search and here it “chooses” to make the decision to match “citation advantage” - a reasonable decision.
This is of course just one example, but my gut feel testing such systems is that one’s based on using LLMs to generate Boolean search query alone without embedding based search, tends to perform not as well as those that use embedding based search (at least as part of the retrieval method).
To be fair, Primo Research Assistant does pass this test despite using a similar method, because the LLM there generates a Boolean search variant string that drops the term “advantage”, this coupled with the additional reranking step of the top 30 helps to surface the right paper.
Moreover, the use of an LLM for what is mostly advanced query expansion in EBSCO NLS is arguably even less impactful here than in other systems.
This is because EBSCOhost's existing search technology, powered by the robust Unified Subject Index, already performs sophisticated query expansion. In essence, NLS adds an AI translation layer on top of another powerful, pre-existing expansion system, which can make its additional contribution feel less essential compared to a platform without such a strong baseline.
A more nuanced analysis is that the LLM here is used for query rewriting and unlike subject mapping, it can take into account user intent and can rewrite sentence/words and not just function as replacement or expansion at the concept level. It is also complimentary in that it can help with query expansion of emerging terms and can recognize limiters like “since 2022” (though this isn’t used in EBCSO NLS). But it still feels that adding embedding based search as a retrieval component would likely add more marginal benefit.
Conclusion
EBSCOhost NLS shares a similar blueprint with the retrieval mechanisms in Web of Science Research Assistant and Primo Research Assistant, but with key differences:
Conservative Generated Boolean Strategy: The LLM-generated Boolean queries are shorter and use fewer synonyms, strategically relying on EBSCO’s powerful Unified Subject Index (USI) for query expansion.
High Stability: The generated Boolean strategy for a given query appears to be exceptionally stable, showing no variation in my testing despite using a LLM
Reproducibility Issues: Despite the transparency of showing the Boolean query, I was unable to reproduce the search results by running the same query in the standard interface. This makes the search process less interpretable than it appears.
Marginal benefit of using LLM for expansion - Lastly, one could argue that because EBSCOhost platform already has advanced subject mapping capabilities, using LLMs as a further query expansion method does not add as much benefit as in other systems and perhaps a embedding based component might have helped more?
Stay tuned for the next part covering Web of Science Smart Search.
Thanks for this. The reproducibility thing is really interesting. My experience from spending a fair while puzzling at why certain things do not work in EDS is that normally there is something going on in the syntax / expanders that is not immediately apparent. We had to write an FAQ about the interaction between phrase searching and stemming for example. Viz our chat online - I think NLS works ok on EDS but not so much for ehost. These are different kinds of search (all be it the new interface is going to make them look rather too alike).