
Why embedding vector search is probably one of the least objectionable use of AI for search

TL;DR Embedding‑based semantic search dodges many—but not all—criticisms aimed at ChatGPT‑style generative AI. Decoder LLMs are compute‑hungry, and legally problematic; encoder embeddings are lighter and non‑generative but still raise questions around interpretability and unknown bias
I recently gave a 30-minute talk at the Librarian Futures Virtual Summit, and for the topic of "AI-powered search," I decided to play devil's advocate. This is a technique I've used a few times in my career to critically examine developments like citation-based mapping services (e.g., Connected Papers), Institutional Repositories, and Web Scale Discovery Services (e.g., Summon).
The goal is to move beyond knee-jerk reactions to “AI” and engage with the technology on a deeper level. When librarians discuss the downsides of "AI," the concerns usually fall into four key areas:
The Environment Argument: AI is computationally expensive and harms the planet.
The Copyright Thief Argument: AI models are trained on stolen content.
The Performance Argument: These systems are biased, opaque "black boxes" that don't really work.
The Harmful to Learning Argument: AI makes students lazy and erodes critical thinking skills.
These are all valid concerns, particularly when thinking about generative Large Language Models (LLMs) like ChatGPT. However, "AI-powered search" is not a monolith. The technology often used to improve search relevance—semantic search—is fundamentally different. By understanding this difference, we can have a much more nuanced and productive conversation.
The Crucial Technical Distinction: Encoders vs. Decoders
What we typically call "semantic search" aims for retrieval based on "meaning" rather than just matching keywords. This is achieved these days using embedding models.
In simple terms, these models convert text (a document, a search query) into a string of numbers called a vector embedding. This vector represents the text's meaning in a high-dimensional space. The system then finds documents whose vectors are mathematically "closest" to your query's vector.

Of course, AI powered search is more than one technology, but here are some common ways already used in academic search engines
Use of LLMs to generate Boolean Search Queries (type of query expansion)
Use of LLMs to generate suggested terms to add
Use of LLMs to generate answer from retrieved documents (Retrieval Augmented Generation)
Use of LLMs to steer search (Deep Search or Agentic Search)
Use of LLMs to do reranking (Deep Search or Agentic Search)
These LLMs used here are the ChatGPT type models you are familiar with - you enter some text, and some text is generated in response.
Most objections to “AI” mentioned above apply to decoder LLMs e.g. they run large scale decoder LLMs that hurt the environment, decoder LLMs are trained on a lot of text without permission etc.
But it is important to realize that what is typically called “Semantic search” runs on a slightly different technology known as encoder embedding models and largely though not completely sidesteps all the arguments above.
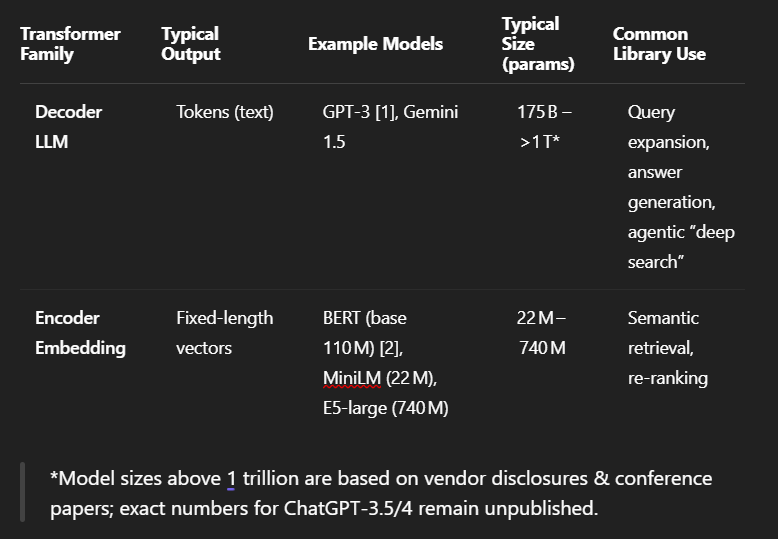
Summary from OpenAI’s o3 model
But what is the difference?
Basic Understanding of use of embeddings in retrieval
Semantic Search usually is contrasted against lexical/keyword search and the idea here is to do retrieval based on “meaning” rather than matching words or tokens.
Modern day - Semantic Search is based on running text strings via embedding models to convert them into vector embeddings to capture “meaning” in a string of numbers. You can think of these numbers expressing the text string in “n dimensional space”.
These embedding models are typically trained via self-supervised learning on predicting the sequence of text from huge amounts of text from the internet.
While several approaches exist for applying embeddings in search, the most common method uses a bi-encoder architecture. In this model, documents are passed through an embedding model during indexing to generate vector representations, which are then stored in a vector database. At query time, the input query is independently encoded into a vector using the same embedding model. Finally, a similarity function—such as cosine similarity—is used to compare the query vector against the document vectors, enabling the system to rank and retrieve the most relevant results based on their semantic similarity.
Embedding models predated Transformer neural net architecture that ChatGPT and its rivals are based on. But since 2020s, we have found the most effective embedding models are based on Transformer based encoder models. So let's discuss this next.
The encoder model vs the decoder model
Both the generative models we fear, and the embedding models used in search are built on the same groundbreaking "Transformer" architecture first introduced in the Seminal 2017 “Attention is all you need” paper.
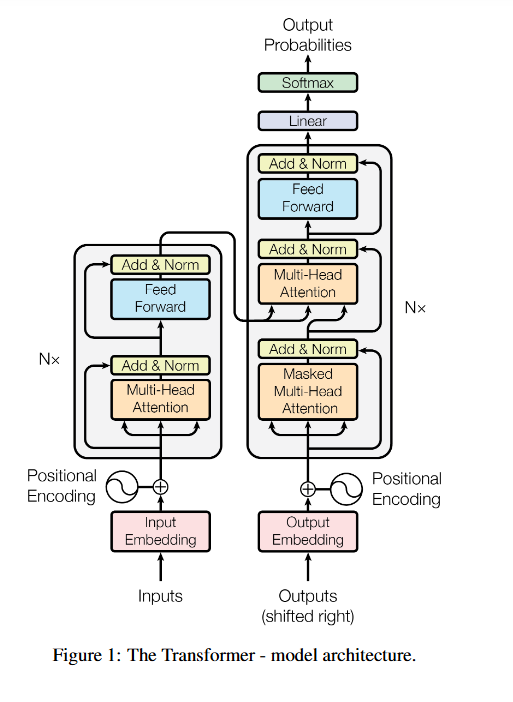
This paper introduced an encoder-decoder architecture (see figure above), with an encoder model (the module on the left) and the decoder model (the module on the right).
But here's the critical part: papers after that took two different paths.
OpenAI focused on the decoder part of the Transformer. Decoders are excellent at predicting the next word in a sequence. You give them text, and they generate new text. This is the foundation of GPT, Gemini, Claude and other generative models.
Google initially focused on the encoder part with its BERT model. Encoders are designed to understand context. You give them text, and they output a rich numerical representation—an embedding. They don't generate text. One of the major uses is to improve retrieval and Google eventually implemented BERT into their search in 2019.
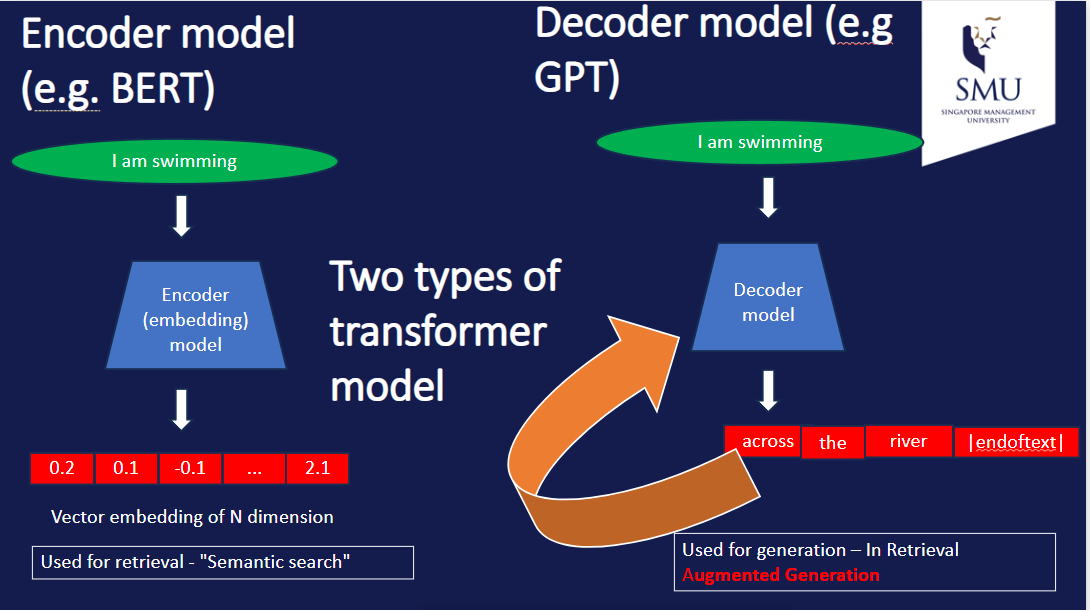
It’s important to distinguish between the two transformer architectures.
Decoder models (e.g., GPT, Gemini, Deepseek)—shown on the right—take input tokens and generate output tokens autoregressively: each new token is fed back into the model until an end-of-text token is produced.
Encoder models (also on the left in this diagram, e.g., BERT) take tokens as input and output embeddings.
These are well-suited for semantic search for two reasons: first, they process text bidirectionally, so each word’s representation incorporates context from both sides; second, they’re typically trained with a “fill in the blank” objective (cloze test), which encourages representations that capture meaning. In comparison, decoder models process left-to-right—each word only sees what came before it—and are trained to predict the next token. This makes early words’ representations impoverished, which is why decoder models require additional fine-tuning to work well for embeddings.
Historically, only encoder models were used as embedding models and while many modern embedding models (e.g., SBERT, E5, Gecko) are still based on transformer encoder architectures, recent top-performing embeddings models—like OpenAI's ada and Google's Gemini embeddings, e5 mistral etc—are derived from large decoder-based transformers. While decoder models are not naturally designed to output embeddings - they are meant to predict next token, with proper fine-tuning, decoder models can effectively generate embeddings, often excelling due to being derived from their larger base model size- think billions of parameters instead of hundreds of millions (eg BERT) and cost more energy wise (see later).
Most arguments made against “AI” are arguments against decoder models not encoder models!
Revisiting the Arguments Through a New Lens
Let's re-examine our concerns, separating the impact of generative decoders from semantic search encoders.
1. The Environment Argument
This argument holds significant weight against large-scale frontier generative models. The last known size for a model like GPT-3 was 175 billion parameters and more recent models could be as much bigger (e.g. original GPT4 was rumored to be 1 trillion parameters!) Running models of this size for every search query would be environmentally costly.
In contrast, encoder models are smaller by orders of magnitude. The original BERT model had two model sizes of 110 and 340 million parameters. The latest ModernBERT released in late 2024 is not much bigger at 395 million parameters.
In practice, for latency reasons - embedding models used are even smaller. For example, the popular all-MiniLM-L6-v2 model, used by services like JSTOR, has only 22 million parameters. While semantic search is still more computationally intensive than traditional keyword search, its environmental footprint is vastly smaller than that of generative AI, making this argument far less potent.
Technically, parameter count correlates with training cost, but for queries we care more about inference cost also depends on sequence length, batch size, and hardware utilization.
2. The Copyright Thief Argument
Here, we are on shakier ground. The original BERT was trained on BookCorpus, which contains copyrighted material. Because many of today's embedding models are often derived from these foundational models, they carry that original sin even if they disclose the data they fine-tune on such as nomic embeddings.
However, two points are crucial. First, because encoder models produce numerical representations and cannot generate text, they are likely in a stronger legal position than decoder models that can regurgitate protected works. Second, and more importantly for our profession, this presents an opportunity for advocacy. We can and should demand transparency from vendors. We need to ask: What was your embedding model trained on? We should champion vendors who use ethically sourced, transparent datasets (like AI2's OLMo, trained on the open Dolma dataset) or who train models specifically on licensed scholarly content. This shifts the librarian's role from passive consumer to active advocate for ethical AI.
3. The Performance Argument (aka They Don't Really Work)
While embedding-based semantic search has shattered performance on IR (information retrieval) benchmarks since its introduction in 2019 , its nature presents new challenges for librarianship.
Possible bias: These models likely inherit the biases present in their vast training data (e.g., gender stereotypes). They may also have unknown bias.
The "Black Box" Problem: A keyword search is interpretable (e.g. count number of term matches). A semantic search is not. The vector-space calculations are opaque as the embeddings are learnt via machine deep learning from huge amounts of text. This "black box" nature poses a significant challenge to scholarly principles.
The End of the Hit Count: A critical and concrete example of this opacity is the disappearance of the traditional hit count. A Boolean or keyword search operates on a clear principle of inclusion and exclusion; it finds the set of documents that match the criteria, giving you a precise number like "1,254 results found." Librarians and researchers rely on this number to gauge whether a search is too broad or too narrow. Semantic search obliterates this concept. It doesn't find a "set" of matching documents; it calculates a similarity score for every document relative to the query. The result is a continuous ranked list from most to least similar.
The reproducibility Problem: Compared to Boolean or keyword searching, ranking using vector embedding is much lower. Due to the need for low latencies when searching, Approximate Nearest Neighbour (ANN) methods have to be used to rank top documents by cosine similarity.
But this comes with the cost of indeterministic results when the same query may give different results. For researchers conducting systematic reviews, the lack of determinism and reproducibility of results is a major hurdle.
The out-of domain Problem: In 2021, BEIR demonstrated that embedding-based models fine-tuned on domain-specific data perform exceptionally well on in-domain tasks—outperforming lexical keyword search—yet often underperform compared to simple BM25 when applied out of domain. This is why the industry's solution is often "hybrid search" (a mix of keyword and semantic results) and advanced embedding techniques like ColBERT and learnt sparse embeddings like SPLADE.
But because they don’t generate text per se, they won’t be affected by either guardrails trained in the LLM or from content filters from Azure platform
4. The Harmful to Learning Argument
There’s a paper now colloquially referred as "LLM rots your brain" theory is concerning that shows overuse of LLMs for writing essays can cause issues.
Relying on LLMs with retrieval-augmented generation (RAG) to search and generate answers—even if the outputs were perfectly source-faithful, which they often aren't—could encourage intellectual passivity. Users might skip reading original sources altogether, potentially failing to develop essential scholarly skills or, if already skilled, allowing those abilities to atrophy.
However, embeddings are simply tools to improve result relevance. Unlike full answer generation, they don’t replace critical engagement—so it is less likely their use alone could harm learning.
Conclusion: A More Nuanced Path Forward
Playing devil's advocate reveals that most of our strongest objections to "AI" are really objections to large-scale, text-generating decoder models. The encoder models powering semantic search sidestep many of these issues but introduce a new, more subtle set of professional and pedagogical challenges.
This essay was copyedited by Gemini 2.5 pro
Aaron, thank you for your you tube talk. That is very enlightening!