
A 2025 Deep Dive of Consensus: Promises and Pitfalls in AI-Powered Academic Search

Academic librarians are increasingly being asked about AI-powered search tools that promise to revolutionize literature discovery.
Consensus is one of the more prominent and earliest players in this space (alongside Elicit, Perplexity), positioning itself as a tool that can not only find relevant papers but assess the “consensus” of research on a topic. Singapore Management University Libraries recently acquired institutional access to both Consensus and Undermind.ai, giving me the opportunity to evaluate these tools in depth.
This review examines Consensus’s capabilities, critically assesses some unique features offered, and as a bonus compares it with Undermind.ai.
Core Functionality: How Consensus Works
At a basic level, Consensus operates like many AI-powered academic search tools. You type a natural-language question, the system searches its index, and returns an AI-generated answer with citations. The interface is clean, and the documentation (search best-practice guide and tutorial) is clear and approachable.
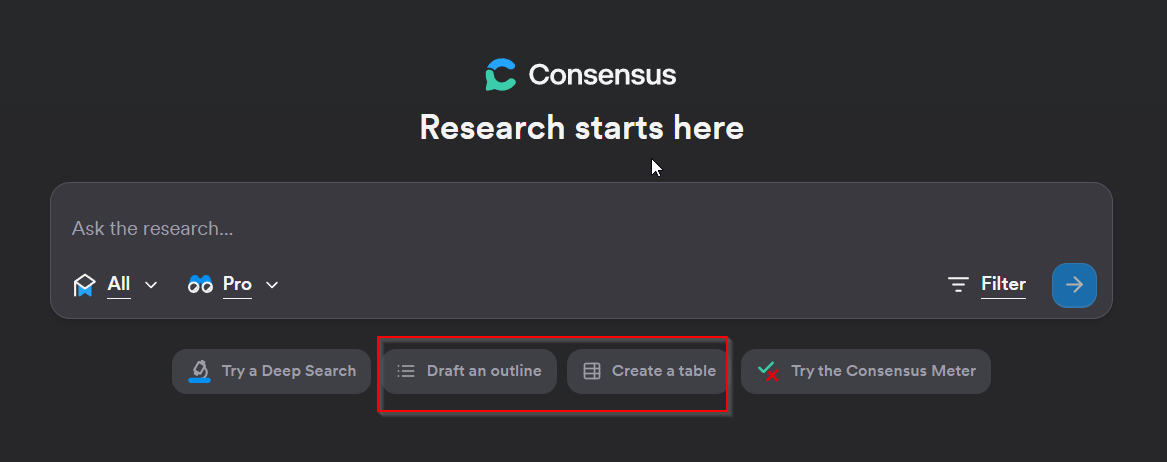
You can of course just type in your question or topic in natural language, but when using such tools, I like to look at what the interface suggests as possible inputs, which gives you a hint of what it is capable of.
I personally, think listing “Try a Deep Search” and “Try the Consensus Meter is somewhat confusing here since it doesn’t actually suggest what to input but instead turns on different modes.
“Draft an outline” and “Create a table” does give you sample inputs you can try but I suspect most people just ignore it and type naturally what they want - which works.
So far, so familiar. Where things get interesting is in the data sources, ranking architecture, and—most controversially—the “Consensus Meter.”
Data Sources and Coverage
In practice this means:
Consensus usually has abstracts for most indexed papers
It has full text only for open access articles (plus a small slice from publisher partnerships)
How does this compare with traditional databases?
Web of Science: ~100 million records
Scopus: ~90 million records
Consensus appears “bigger” mainly because it includes preprints and more open access material. But the key constraint is full-text access. For most paywalled content, it is working from titles and abstracts only.
For librarians, this matters:
In fields with strong OA penetration (e.g. computer science, high-energy physics, genomics), Consensus may have very good full-text coverage.
In fields where paywalls dominate (humanities, many social sciences), Consensus is often doing abstract-only analysis on a large proportion of the literature.
None of this is unique to Consensus, as many of its competitors like Elicit.com, Undermind.ai are in the same boat.
Search Architecture and Quality Signals
Consensus uses what is now a fairly industry standard retrieval stack:
Hybrid search combining keyword and semantic (embedding-based) search
Multi-stage ranking, including:
Initial hybrid retrieval (top ~1,500 results)
Reranking by query relevancy match and “research strength” (citation counts, recency, journal reputation)
A final pass that selects the top 20 (for pro mode).
The interesting bit is the explicit attempt to rank not only by textual relevance, but also by proxies for research quality (citations, study design, journal-level signals). This is common in traditional academic search (think Google Scholar), but still relatively rare among newer AI search tools that often optimise purely for semantic similarity.
However, these quality signals in my view come with serious caveats.
As of this writing, Consensus has announced “Scholar Agent“ in collaboration with OpenAI, deployed in “Pro” and “Deep” modes (we will discuss this later). This means Consensus now uses GPT-5 through the response API, with specialized planning, search, and reading agents working together (see post for flow diagram).
Quality Signals and Study Classification
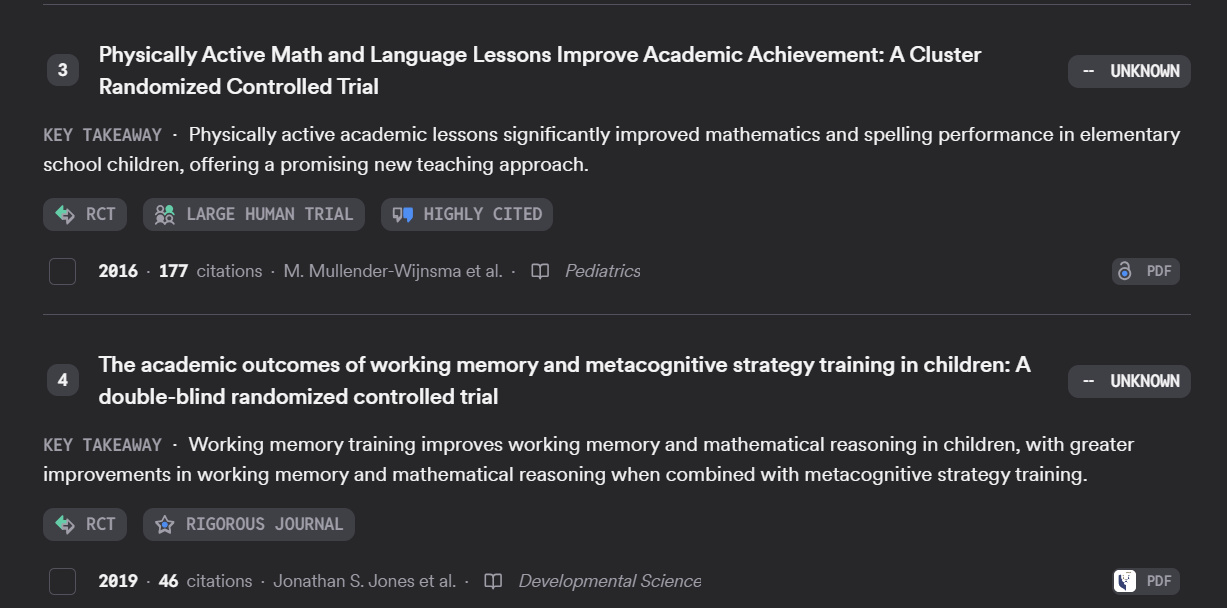
As mentioned, Consensus rankings take into account research quality signals like citation counts, method used (RCT, systematic review, meta-analysis) and the journal reputation (“rigorous journals”) and the retrieved references will often be tagged with these signals.
Of the research quality signals, the one using journal reputation is of course the most dubious, though one could even argue that judging quality by method might not be a good idea, as knowing a study is an RCT might not tell you whether the RCT is properly conducted or not… (with the added complication that the method is extracted and assigned by the LLM).
Journal Quality Metrics
In Consensus, papers are tagged based on journal reputation using SciScore, with “rigorous journals” being in the top 50th percentile and “very rigorous journals” in the top 10th percentile. This percentile ranking claims to “help users better understand the quality of their search results“
What is SciScore? SciScore is a tool that evaluates papers on research rigor criteria like whether appropriate authentication of key biological resources is reported, use of randomization and blinding, sample size calculations, and data/code availability. It produces both article-level and journal-level scores.
Some Issues
Container ≠ content. Even the most “rigorous” journals publish weak or even retracted studies. Using journal score as a shortcut for article quality is methodologically shaky (see DORA).
Perverse incentives. High-impact journals preferentially publish novel, surprising findings, which are more likely to fail replication. Prestige and reliability are not the same thing.
Field specificity. SciScore is optimised for biomedical research. How well do these criteria translate to economics, sociology, or computer science?
Citation bias. Citation counts are highly field- and document-type dependent. Reviews and methods papers accumulate citations very differently from niche empirical work. Does Consensus normalize for this?
LLM-Based Study Design and “Study Snapshots”
Consensus also uses LLMs to classify study designs (meta-analysis, RCT, systematic review, cohort study, etc.) and to extract:
Population
Methods
Sample size
Outcomes
Results
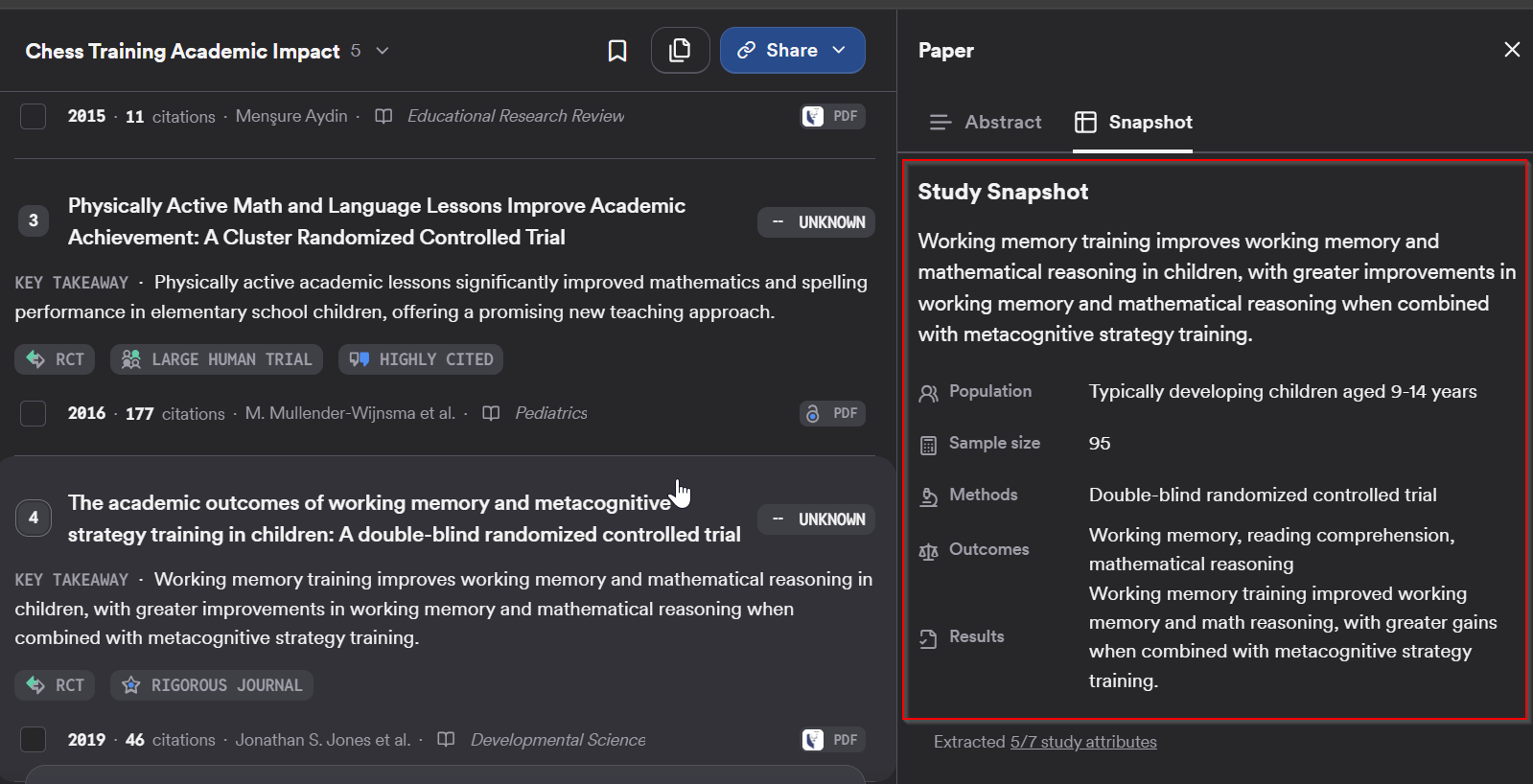
These power the “Study Snapshots” for individual papers. It’s a genuinely useful feature, especially for quick triage. But the classifications are AI-generated and can be wrong.
The Consensus Meter: Reading the Room or Miscounting Votes?

The flagship feature is the Consensus Meter, which tries to summarise what the literature “says” about a given question by categorising papers into “yes”, “no”, “mixed”, or “possibly” and then visualising the distribution.
For example, for the query:
“Do certain personality traits influence career success?”
Consensus might show something like:
94% (16 papers): Yes
6% (1 paper): Mixed
You also get context like average publication year, journal quartile, and citation counts per category.
This is intuitive and eye-catching. This informal process where you can a sense of the literature is akin to what Mike Caulfield calls “reading the room.”
This is mind for quick heuristics checks - but under the hood, it is essentially a form of vote counting—an approach evidence synthesis methodologists have spent decades warning against.
When the Meter Actually Helps

Take another example:
“Does chess training causally improve academic performance in children?”
Consensus might show something along the lines of:
41%: “Yes”
12%: “Possibly”
24%: “Mixed”
24%: “No”
So far, that looks ambiguous: some yes, some no, some mixed.
However, if you look closer, you may notice that none of the “yes” studies are tier-one evidence (RCTs, systematic reviews, meta-analyses), whereas the more negative conclusions cluster among higher-tier designs. That’s a genuinely useful pattern to surface.
Similarly in other examples, you might notice the “no” studies tend to be more recent which implies the earlier studies may have been refuted.
Still, as discussed already signals like Journal tiers, average citation counts and methods are weak quality signals that may have issues. For example, high tier journals do not always imply higher quality articles and it is common for older papers that show positive results to have higher citations vs more recent papers that refute the older papers.
Why Vote Counting Is Methodologically Weak
In fact, the Consensus Meter embodies a problematic approach to evidence synthesis that the systematic review community largely abandoned decades ago for more formalized methods of evidence synthesis. This is essentially vote-counting—tallying studies by their conclusions—which has well-documented limitations:
1. Equal Weighting Problem: A small study (n=50) counts the same as a large study (n=5,000). The chess example partially addresses this by flagging tier-one studies, but the meter itself doesn’t weight by study quality or sample size.
2. Ignores Effect Sizes: Two studies might both say “yes,” but one finds a small effect (Cohen’s d=0.1) while another finds a large effect (d=0.8). Vote-counting treats these identically.
3. Publication Bias Blindness: Published literature systematically overrepresents positive findings. Consensus search of 200M+ index including preprints helps reduce this but still it does not have the comprehensiveness of a properly done systematic review. A meter showing 80% of papers say “yes” might reflect publication bias rather than true consensus.
4. Heterogeneity of studies: Papers may address subtly different questions, use different operationalizations, or study different populations. Collapsing these into yes/no/mixed categories loses crucial nuance. Consensus may not be able to assess this distinction as well.
5. Interpretation Ambiguity: What does “possibly”, “mixed” mean? These are extracted judgments, not reported conclusions.
6. Lack of quality assessment : Proper evidence synthesis involves critical appriasal of the included studies to ensure that “consensus” is based on rigorous studies only. The fact that Consensus does an inclusive search of 200M+ index helps reduces publication bias but you run into the problem that it is more likely to include poor quality studies. While Consensus does rank studies based on “quality signals” but as discussed earlier the way Consensus does this is shaky.
To their credit, Consensus does expose some quality signals (e.g. number of “tier one” studies, average journal rank), but these are still blunt instruments.
The right way to think about the Consensus Meter is:
Not a mini meta-analysis (not that Consensus recommends it to be used this way)
More like the start of a scoping study or “conversation starter” about the literature
As such, it can actually be a nice teaching tool for undergraduates—provided we explicitly discuss its limitations.
Search Modes and Filters

Quick, Pro, and Deep Modes
Consensus offers three effort levels that determine how long it searches and of those ultimately how many it uses to summarize.
Quick: Summarizes max 10 papers
Pro: Summarizes max 20 papers
Deep: Summarizes max 50 papers (becomes Deep Search with additional features)
I mostly use Deep (enterprise tier gives me 50 runs a month), as I’m willing to trade time for more coverage. Undergraduates or casual users may gravitate to Quick or Pro. All examples in this post are based on Deep.
Filtering: Surprisingly Rich and Transparent
Consensus’s pre-filtering options are one of its standout strengths, especially compared to many AI search competitors:

Standard filters include:
Publication year
Scimago Journal Rank
Citation count
Exclude preprints
More unusual:
Study Design: Filter by meta-analysis, RCT, systematic review, case study, etc.
Sample Size: Minimum thresholds
Field of Study: 23 disciplines
Countries: 236 countries
Medical Mode: Restricts to ~8M papers from ~50,000 clinical guidelines and top 1,000 medical journals
This can be genuinely useful, but it also reinforces that Consensus is shaped around a STEM/biomedical worldview. The filters and quality markers align more naturally with clinical and experimental work than with qualitative research, theory-heavy fields, or the humanities.
Medical mode + uploading of papers
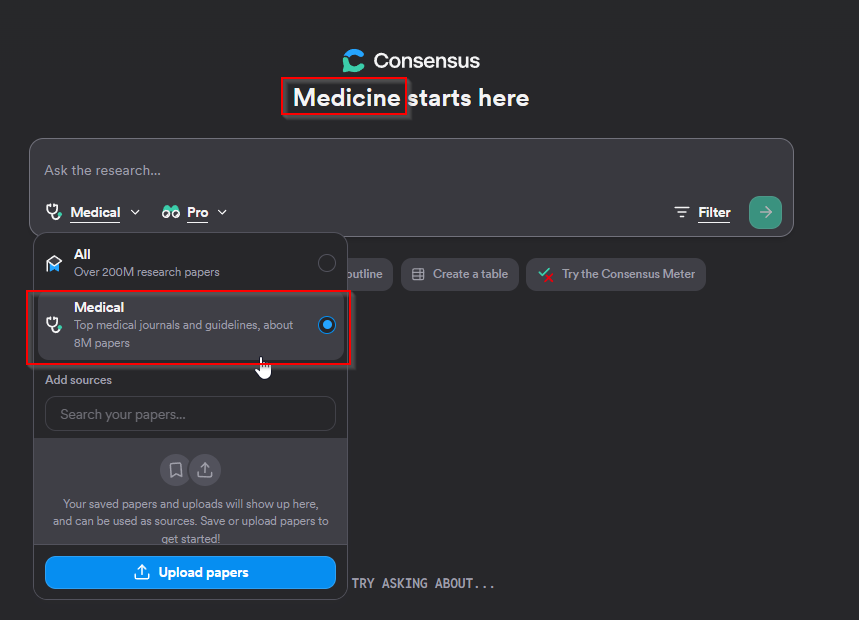
Consensus has always had a slant towards medical/life sciences but they have doubled down further with the recent “medicine mode”.
This is a special limiter that limits the search to 8 million papers and guidelines from “top 1000 medical journals and 50,000 clinical guidelines”.

This whitelist by journals no doubt removes results from lesser known or even predatory journals, but I suspect medical librarians reading this would have prefered it to correspond somehow to MEDLINE or the larger PubMed Set (which is tricky, because I understand this isn’t strictly by journal, though one could imagine using OpenAlex records with PMIDs only) rather than trying to rate journals using their own criteria.
The other feature that is quite well hidden - is that you can upload papers to your search. I increasing see this feature in tools like scite assistant, Elicit, SciSpace but speaking as a librarian, I know publishers and content owners will be very unhappy with such usage of their content.
LibKey Integration: A Small but Important Win
From a library point of view, one of the most practical features is LibKey integration.
Under Settings → Preferences, users can select their institution (e.g., “Singapore Management University”). Consensus then:
Checks whether the paper is available via your holdings
Shows a small institutional icon next to records with accessible full text
Lets users click through via LibKey to the subscribed version
Interestingly, among academic AI search tools, this kind of integration is still rarer than it should be. Consensus deserves credit here for supporting this.
Note that this doesn’t solve the full-text limitation for the AI itself—Deep Search cannot read paywalled content via LibKey—but it does significantly improve the user’s access experience.
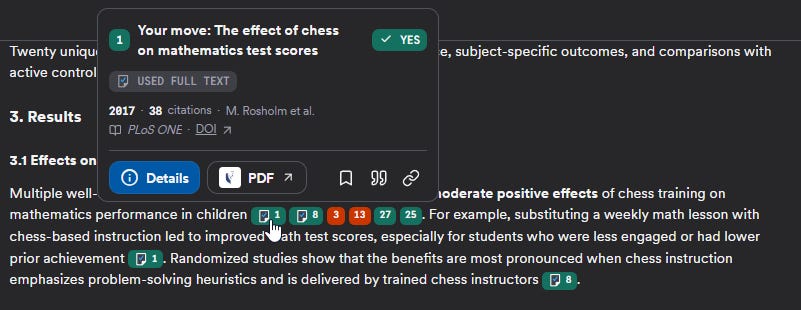
While Deep Search mode can use full-text (shown by the special document icon), this is strictly only for free papers and not related to your access via Libkey.
The only tool I know that actually uses institutional holdings directly in its own pipeline (without manual downloading/uploading) is Elicit.com, via a browser extension.
Deep Search: Consensus’s Answer to Deep Research
“Deep Research” is becoming a distinct product category: agentic AI workflows that spend 10+ minutes iterating through queries, following citations, and synthesising long-form reports. We see general-purpose versions (OpenAI Deep Research, Gemini Deep Research) and academic-specific ones (Undermind.ai, Scopus Deep Research, AI2’s ASTA and more.).

Consensus Deep Search, introduced fairly recently, is its entry in this space. It is broadly comparable to Undermind.ai and, to a lesser extent, Elicit’s “Research Report” / systematic review flows. Both Undermind and Consensus typically finish in under 10 minutes; in my experience, Consensus is slightly faster.
Why do the “deep” features of specialised tools like Undermind, Consensus, Elicit.com tend to work faster than generic Deep Research from OpenAI, Gemini etc and yet search as deeply if not more so? Part of the reason, is that the later tends to search by “computer use” - it loads up a web browser and browses the web like a human. This is of course much slower than direct access via APIs or local lookups done by Undermind, Consensus, Elicit. On the other hand, access to just indexed academic content has blind spots of course.
Key behavioural differences:
Consensus Deep Search: runs immediately, no clarifying questions
Undermind: asks several clarifying questions before searching
Some users find Undermind’s questions annoying; others (myself included) think they meaningfully improve search quality when you’re new to an area.
That said, some librarians dislike the fact that Undermind’s search process is 100% non transparent. Consensus Deep Search while not 100% transparent, at least shows more of its search process compared to Undermind.ai which is fully blackbox.
Search Process Transparency
Unlike Undermind.ai, which provides virtually no insight into its search process, Consensus Deep Search generates a PRISMA-like flow diagram:

Deep Search flow diagram showing search process
In this example, Deep Search:
Ran 20 queries → 1,004 hits
Performed citation searching → 43 additional papers
Total hits: 1,047
Removed papers without abstracts and duplicates (-333) → 714 papers
Removed papers with “low semantic relevance” (-141) → 573 papers
Selected top 50 papers (after reranking)
The sidebar provides even more detail. You can click on each section to see the actual queries executed:

You can even see the criteria used for citation searching. This level of transparency is valuable for users who need to understand and potentially document their search strategy.

Reproducibility and Explainability Concerns
However, if you put on the evidence synthesis researcher hat, even this level of transparency which is high for these types of tools is of course not enough.
1. Can searches be reproduced? The queries are displayed, but can another researcher run the exact same querie above and produce the same 1,047 hits and the same top 50 assuming no index change?
LLM-based systems are often non-deterministic, even at temperature 0. In my informal tests, repeated Deep Search runs on the same question minutes apart gave slightly different rankings, though the top 10–20 papers tended to overlap strongly.
There is an interesting hypothesis (which Undermind’s early white paper alludes to) that iterative deep search might converge on a stable set of relevant papers once enough items have been evaluated. Their modelling suggests that after ~150–300 evaluated papers, you’ve probably seen 80–98% of the relevant ones. If true (a big “if”), this implies we might not get reproducible search steps, but we might still converge on a nearly complete relevant set—similar in spirit to stopping rules in systematic reviews. This is fertile ground for empirical research.
2. Can the strategy be exported in a usable form? For systematic reviews, search strategies must be documented and shared. Can the Deep Search process be exported in a format suitable for methods sections?
3. What about the “black box” reranking? We see 573 eligible papers narrowed to 50, but the reranking algorithm that makes these selections is not transparent. What if paper #51 was actually critical to your research question?
These are not deal-breakers, but they highlight that while Consensus is more transparent than Undermind, it’s still not meeting the standards of reproducibility required for formal systematic reviews. Like Undermind and the other tools in this class, it is best thought of as a sophisticated scoping or exploratory tool rather than a replacement for systematic review methodology.
Consensus Deep Search Output and Visualizations
Like many modern Deep Research tools, Consensus Deep Search provides a long form report with many interesting visualizations. See sample report here.
Unique features:
Color-Coded Citations: In-text citations are colored
Green: “yes”
Yellow: “possibly”
Orange: “mixed”
Red: “no”
…based on Consensus Meter labels, with icons indicating whether title/abstract only or full text was used.

Claims and Evidence Table: Structured extraction of key claims and the papers supporting or disputing them.

Other more common but still useful visualizations include
Results Timeline: Shows distribution of relevant papers over time—useful for identifying emerging trends or seminal early work.

Top Contributors, Research Gaps and Open Questions
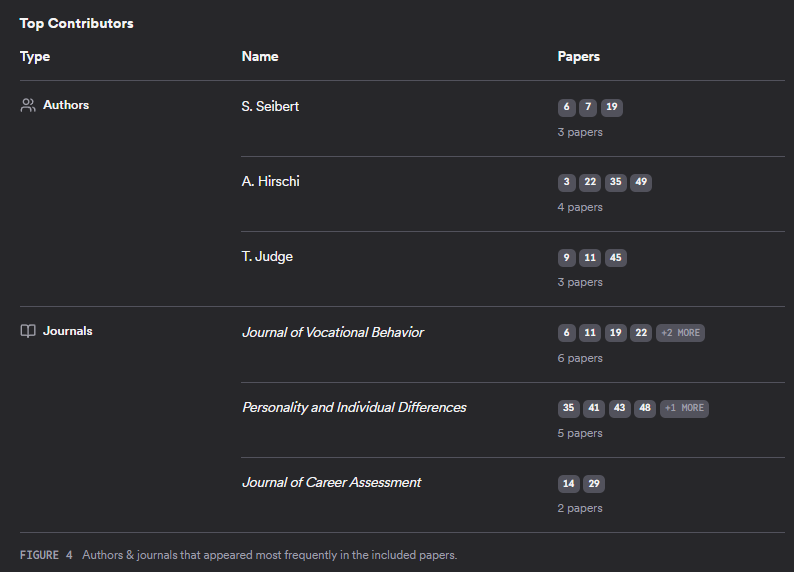


Search performance of Consensus
All this is very nice. But at the end of the day, we should care mostly about retrieval. How well does it work?
I generally run a couple of quick and dirty tests (see this to get a feel of how I test quickly) to get a feel of how well the search works and Consensus in Deep Search mode aced my “easy”, “medium” and “hard” challenges.
This is expected for Deep Search tools but it is always good to confirm.
Hallucination check
In particular, it aced my “negative rejection” test (Chen et al., 2023).
This involves posing a question where no relevant literature exists and see if the system:
sensibly refuses to answer
hallucinates an answer with fake citations.

Consensus claims to be immune to hallucinations that involve non-existent references, and not to answer from “internal memory” without sources. In my testing, it did indeed refuse where it should.
But it might still “misread sources” or what some papers call fail on “source faithfulness”.
Don’t be too impressed though; most properly implemented academic RAG systems with additional checks can easily guarantee the first (just check if generated cited references match what is in the index using non-LLM methods), and often the second. It is the third type of hallucination that is always the issue.

Deep Search tools are so good now that they easily ace my tests, but my rough estimation/vibe sense currently is that the Consensus Deep Search is at least decent (maybe in the top quartile of tools I have tried), though it is unclear how it stacks up against my favourite tool, Undermind.ai, which is generally ranked at the top of the table in many properly and not so properly done head-to-head tests and/or is praised by evidence synthesis experts I know.
Conclusion
Consensus is in my view, likely one of the top tools in its class.
First and most importantly, the recent addition of Deep Search mode, makes the retrieval capabilities of Consensus competitive with some of the most powerful search tools.
On top of that, it has in my view one of the most appealing interfaces out there, with color-coded references, and the Consensus Meter, for all its methodological faults, is likely to appeal to undergraduates and less advanced users - allowing them to get a quick scan of the literature. Add advanced pre-filters and LibKey integration to institutional full-text, and it is easy to guess this will be a hit for many users doing narrative literature reviews.
Still, I have some misgivings over how STEM centric some parts of Consensus are, for example there’s it’s use of SciScore, details extracted for study snapshots etc. While the sources are broad enough, one wonders if the tool works better (e.g. retrieval and ranking algo is tuned) for STEM subjects.
Overall, while there are perhaps more powerful and specialized tools like Undermind.ai or Elicit.com, this is a great tool, that I can recommend considering for institutions.
My Disclosure & Independence Policy
Bonus : Comparison: Consensus vs. Undermind.ai
Since SMU Libraries currently subscribes to both tools, it would be good to do a comparison. Do note that I have a lot more experience with Undermind.ai and the purpose of this piece isn’t to do a formal comparison review.
Similarities
Both search approximately the same open sources (OpenAlex, Semantic Scholar) using a mix of lexical, semantic and even citation search (in Consensus Deep mode).
Both take <10 minutes for deep research runs (Undermind takes slightly longer)
Both generate comprehensive reports and interesting visualizations with citations
Both use sophisticated LLM-based summarization and extraction
Key Differences between Consensus and Undermind
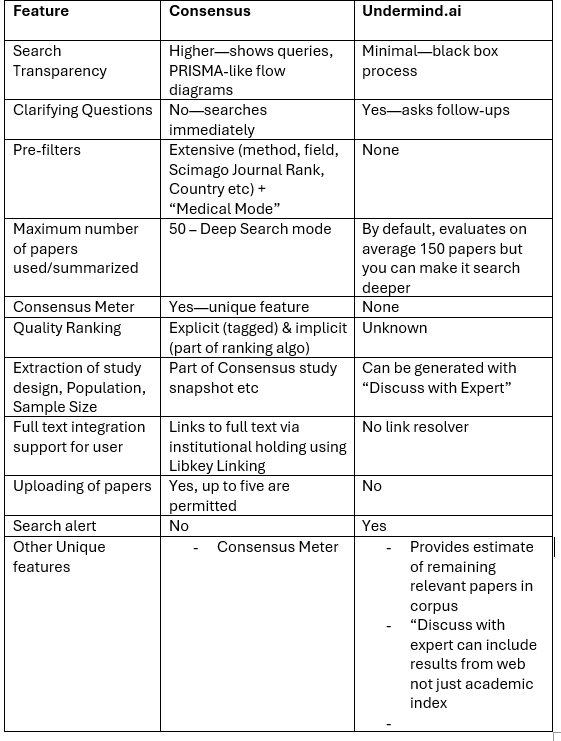
I had initially planned an in-depth comparison of Undermind vs Consensus, but it ran too long and makes little sense if you are not already familiar with Undermind.ai.
Still, here’s how I see how the two differ.
Layout Format Differences
One of the most noticeable differences between Consensus and Undermind is their report format. Consensus generates long-form prose reports with extensive tables and visualizations that can theoretically be copied directly into a document.
Undermind, by contrast, diverges from the usual Deep Research outputs and produces more informal reports organized in bullet points across standard sections.
There’s usually an initial summary section, then sections titled
Categories
Timeline
Foundational Work
Adjacent Work (work that cites foundational work a lot but Undermind determines is not semantically what you want - read to get broader view).

Here’s an example with some sections expanded.


Besides the standard sections in Undermind, the subsections under it are more variable but typically you will see coverage of areas like “research gap”, “cluster of top authors” etc, pretty much what you see in Scopus AI, Consensus Deep Search etc.
That said, Consensus provides substantially more built-in visualizations. In fact, the one major visualization you can see in Undermind is the timeline visualization and the rest are tables at best.
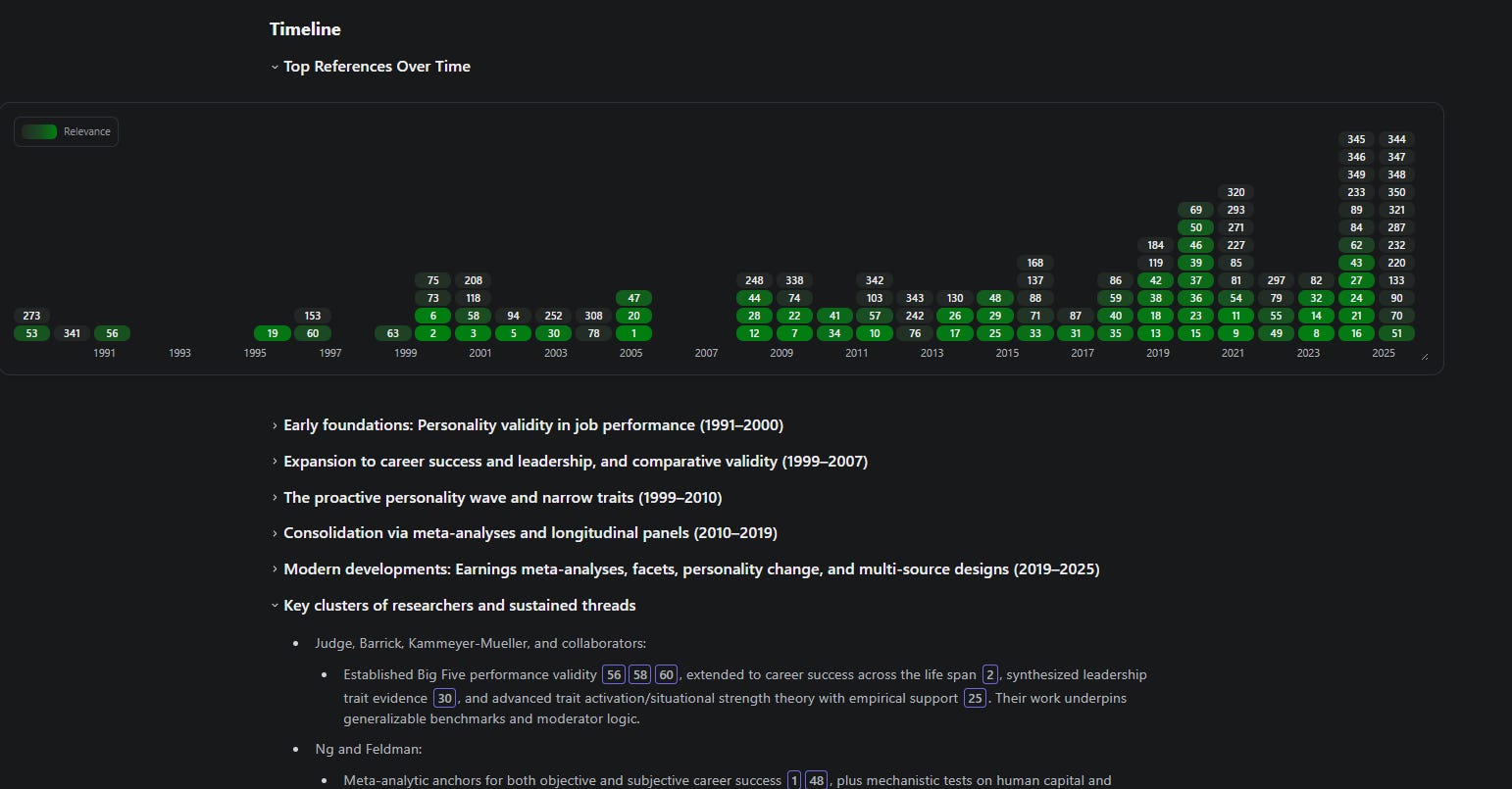
But what about sections you want but Undermind doesn’t generate? Undermind covers this with a “Chat with Expert.” feature, This functionality allows users to interact with all the papers found using a frontier thinking model (the specific LLM is not disclosed).
Most other similar tools like Consensus, SciSpace offer “chat with paper” but this only interacts with one or at best a few papers.
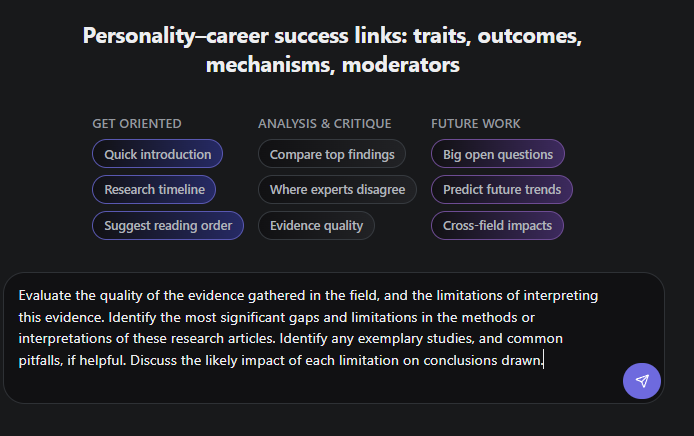
You can type in your own prompt but by default it includes nine prompts that are surely well-engineered to work effectively with Undermind, and in my experience, these prompts can generate outputs matching or exceeding what Consensus produces automatically, including equivalents to Consensus’s “Claims and Evidence Table.”
This is what you might get when you ask to compare top findings.
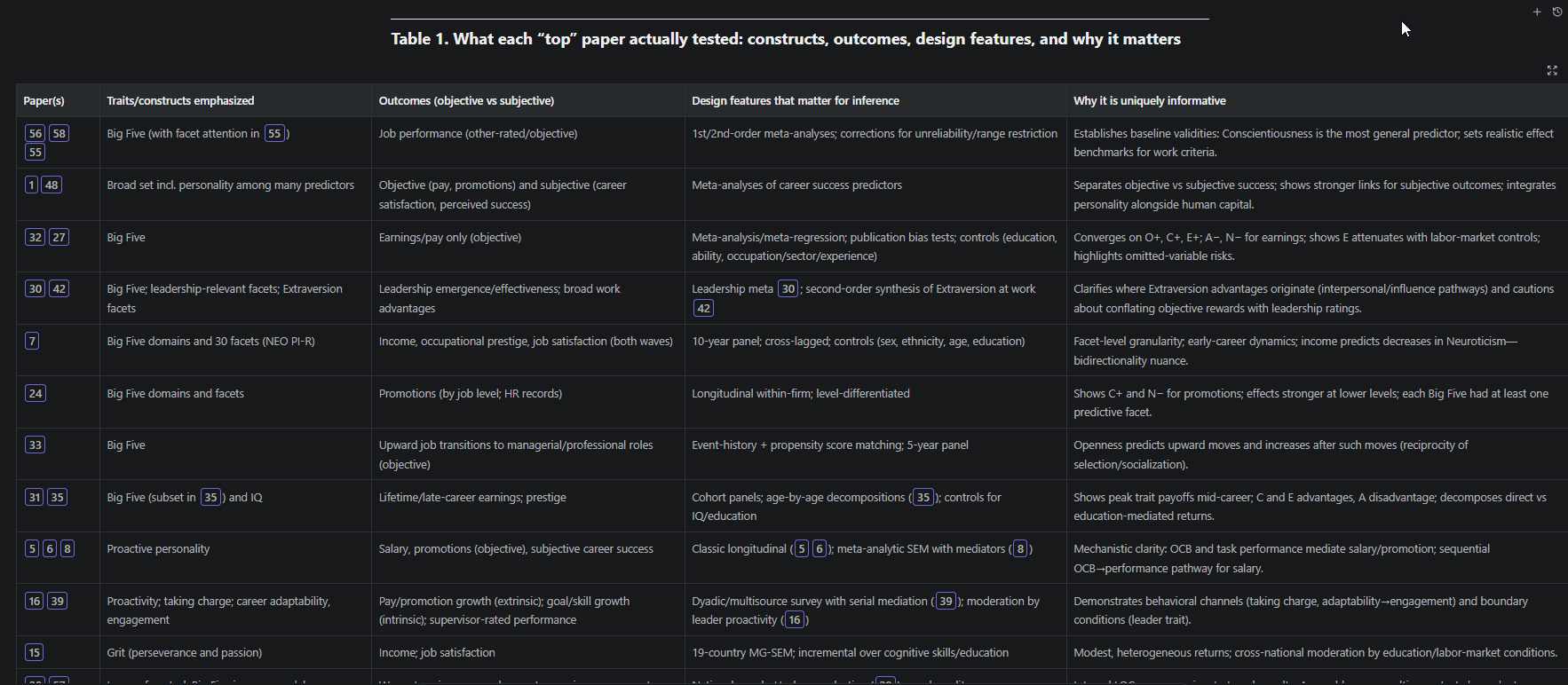
Interestingly, earlier versions of this feature would independently search the web when using default prompts to supplement academic sources with government reports and policy documents. It almost never does this now, but you can turn this on by explicitly adding “Search the web” to the default prompts. As you can see below, the LLM is searching the general web for general US policy on open access.
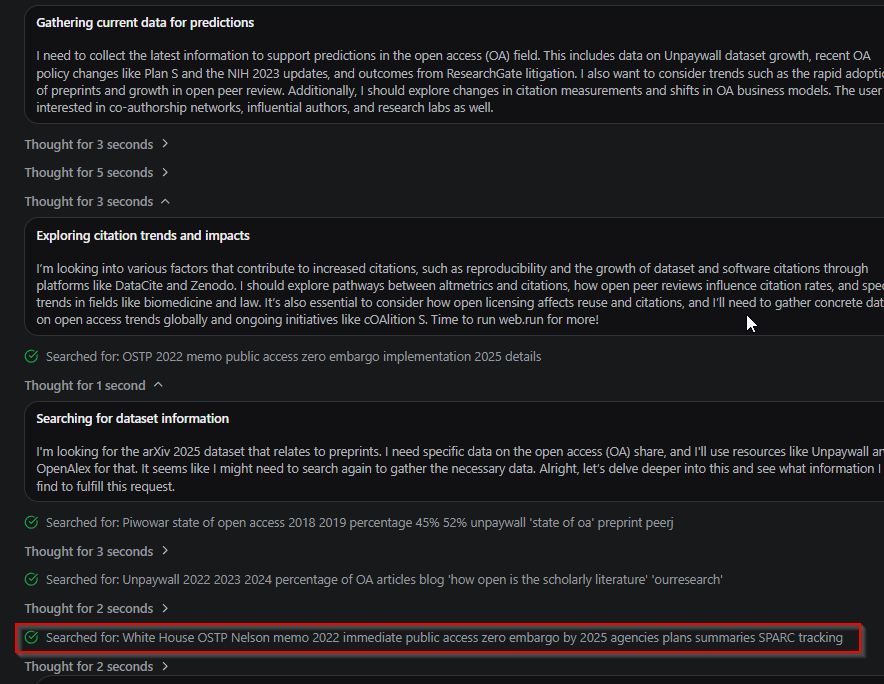
When activated, it can cite both academic references and current policy documents, providing a broader evidence base than purely academic sources.
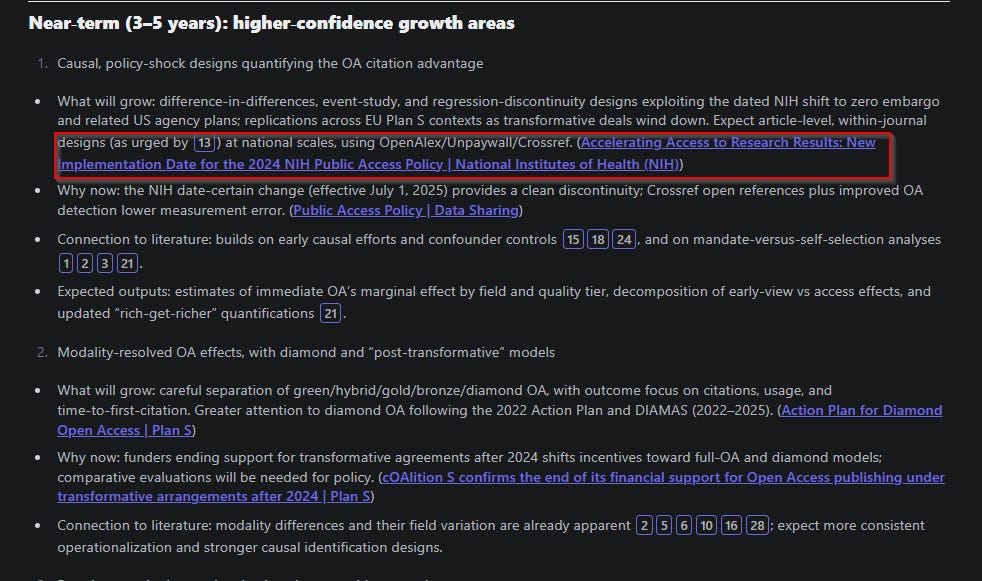
As you can see above, the output cites the latest 2025 US policy (dated March 2025) and not just the academic references found earlier.
User Visualizations and Interface
From a user experience perspective, Consensus appears more accessible to less advanced users. The Consensus Meter, despite its methodological limitations, provides an intuitive visualization that appeals to many users. The color-coding of citations makes it easy to see at a glance which papers support different conclusions, and the built-in visualizations require no additional prompting or effort. Small but practical features like LibKey integration for accessing full-text articles are particularly valuable for undergraduate students who may not have established workflows for accessing institutional subscriptions.
Undermind has more advanced search capabilities
Despite these user-friendly features, I personally prefer Undermind, primarily for its search capabilities. While Undermind’s clarifying questions before conducting searches can sometimes feel tiresome, they prove extremely helpful when exploring unfamiliar research areas—which represents the most common use case for these tools.
There are hints that Undermind employs a more sophisticated search system: it evaluates approximately 150 results on average compared to Consensus’s maximum of 50, and it can search even deeper when requested.
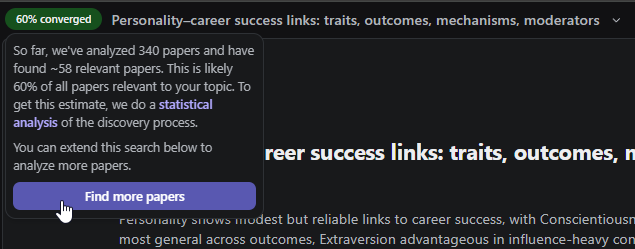
Undermind also provides a statistical analysis estimating how much relevant literature might remain undiscovered, though this feature lacks independent validation.
Another valuable feature is Undermind’s search alerts based on created reports, which the author finds extremely high-quality and useful, including “adjacent” alerts that surface related but not directly requested content—something Consensus doesn’t currently offer.
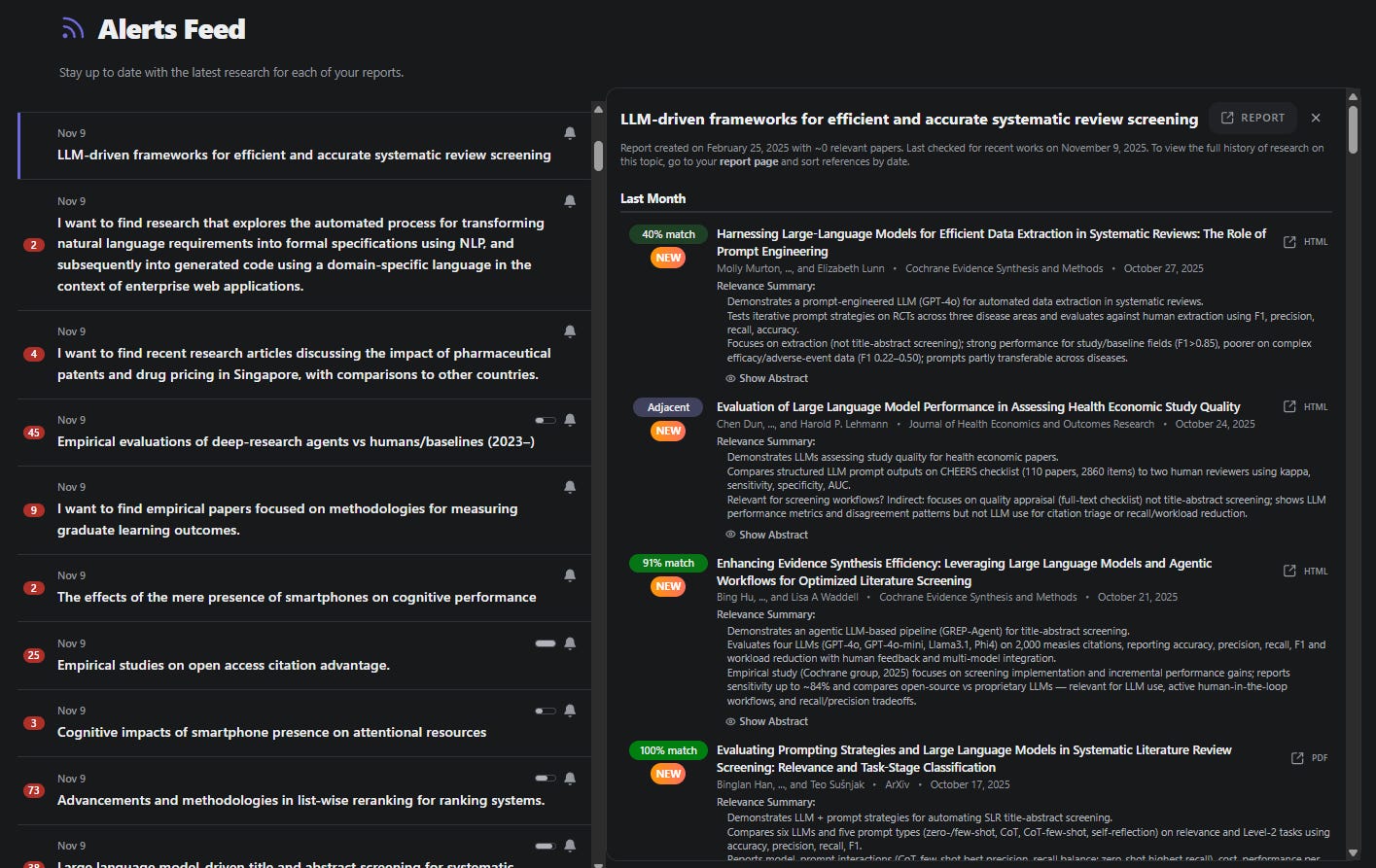
The one area regarding search where Consensus maintains a clear search advantage is its extensive pre-filtering options, allowing users to exclude preprints or filter by journal quality thresholds before conducting searches.
Conclusion
For my typical use case—quickly getting the lay of the land rather than producing ready-to-use literature review text—both tools work well, with a slight preference for Undermind’s bullet-point format for easier skimming.
Both are excellent tools - typically mentioned in the same breath as Elicit.com, I suspect the choice between tools ultimately depends on the user’s sophistication and whether one prioritizes accessible visualizations or deeper search capabilities - with Consensus being easier to appreciate for undergraduates and less advanced users, while advanced users would appreciate the deeper search capabilities of Undermind.ai.