


Why I Think Academic Deep Research — or at Least Deep Search — Will “Win”
Aaron hypes up academic deep research and explains why

Back in 2022, I was hyped about Retrieval-Augmented Generation (RAG).The novelty of seeing a search engine spit out a direct answer — with citations! — in tools like Elicit and Perplexity felt like the future. I even predicted that this “answers-with-citations” model could become the prominent paradigm for academic search.
Three years later, that prediction has partly come true. Academic databases and search engines — Primo, Web of Science, and Scopus — now have RAG features, following the lead of newcomers like Elicit, Scite Assistant, Consensus, and more.
But somewhere along the way, my excitement cooled.
For a freshman looking for a quick answer, a short AI-generated paragraph is magic. For an academic researcher, it’s usually just a teaser — you still need to dive into the original papers for context, nuance, and methodology. That “direct answer” didn’t save you much work and that’s assuming it didn’t “misinterpret” what the citation said (source faithfulness).
Today, I have changed my tune, and I predict that the future of academic search will be “Deep Search” and possibly “Deep Research.” (See part 2)
For sure, now that academic RAG systems built on Semantic Scholar Corpus etc are a dime a dozen, I likely won’t respond if contacted by a vendor to try their RAG tool, UNLESS they include Deep (Re)Search features unless there is some compelling reason since the retrieval will never be good enough. As of 2025, such features are “table stakes” to be even taken seriously, by me at least.
What Changed My Mind
In early 2024, I tried Undermind.ai. What impressed me wasn’t the length of the reports it could generate — it was the search quality. In both recall and precision, it clearly outperformed the usual “one-shot” embedding searches I’d seen in Elicit (at the time) and similar tools.
The secret was simple: Deep Search.
Instead of firing off a single query, Deep Search runs multiple iterations — blending keyword, semantic, and even citation chasing — while letting modern LLMs act as human-like relevance judges. With longer runtimes (often minutes instead of seconds), the system simply covered more ground and ranked results better.
Importantly, Academic search doesn’t have to chase the sub-second latency of Google. Researchers will happily wait minutes (or even hours) if it means the top results are measurably better.
That’s when I realized:
I care more about Deep Search than the generation. If retrieval isn’t strong, the most powerful LLM will be helpless to generate anything useful.
This makes sense in hindsight. The longer a search runs, the more ground it covers. When paired with modern GPT-4-class models for relevancy ranking — which now correlate highly with human judgment — the results beat any “one-shot” query engine, even if they use “magic” embeddings.
This is why I believe Deep Search will become the default standard in academic discovery — and why Deep Research tools that combine it with strong generation capabilities will dominate.
Terminology - Deep Research vs Deep Search
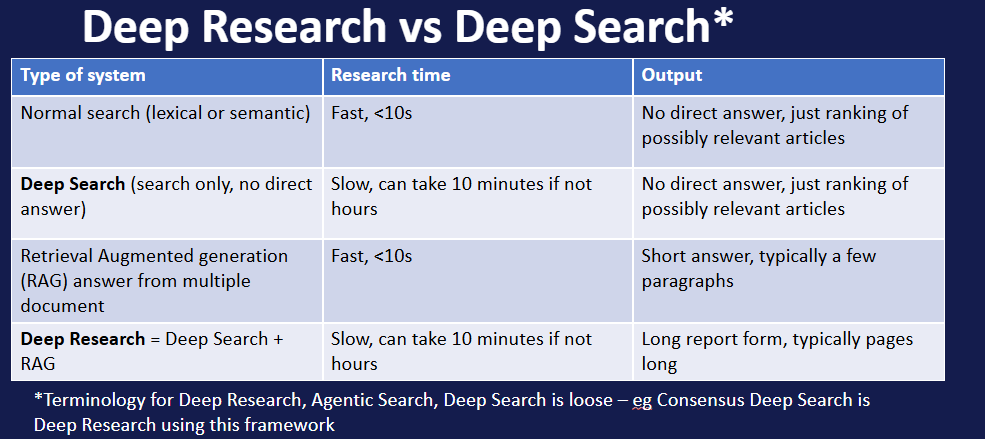
The term Deep Research went mainstream in 2025 with the launch of OpenAI Deep Research, joining Google’s Gemini Deep Research and following by others such as Perplexity’s Deep Research (now renamed under Perplexity Labs).
They solidified the idea of a new class of products called “Deep Research.” but they weren’t the first. Stanford’s STORM and academic tools like Undermind.ai and Futurehouse PaperQA2 were already exploring the space, alongside AI2 Open Scholar and AI2 ScholarQA.
I find it useful to break the concept into two layers:
Deep Search — powerful, iterative retrieval and ranking.
RAG — generating a report from the retrieved documents.
From there, we can map AI-powered search tools into four quadrants:
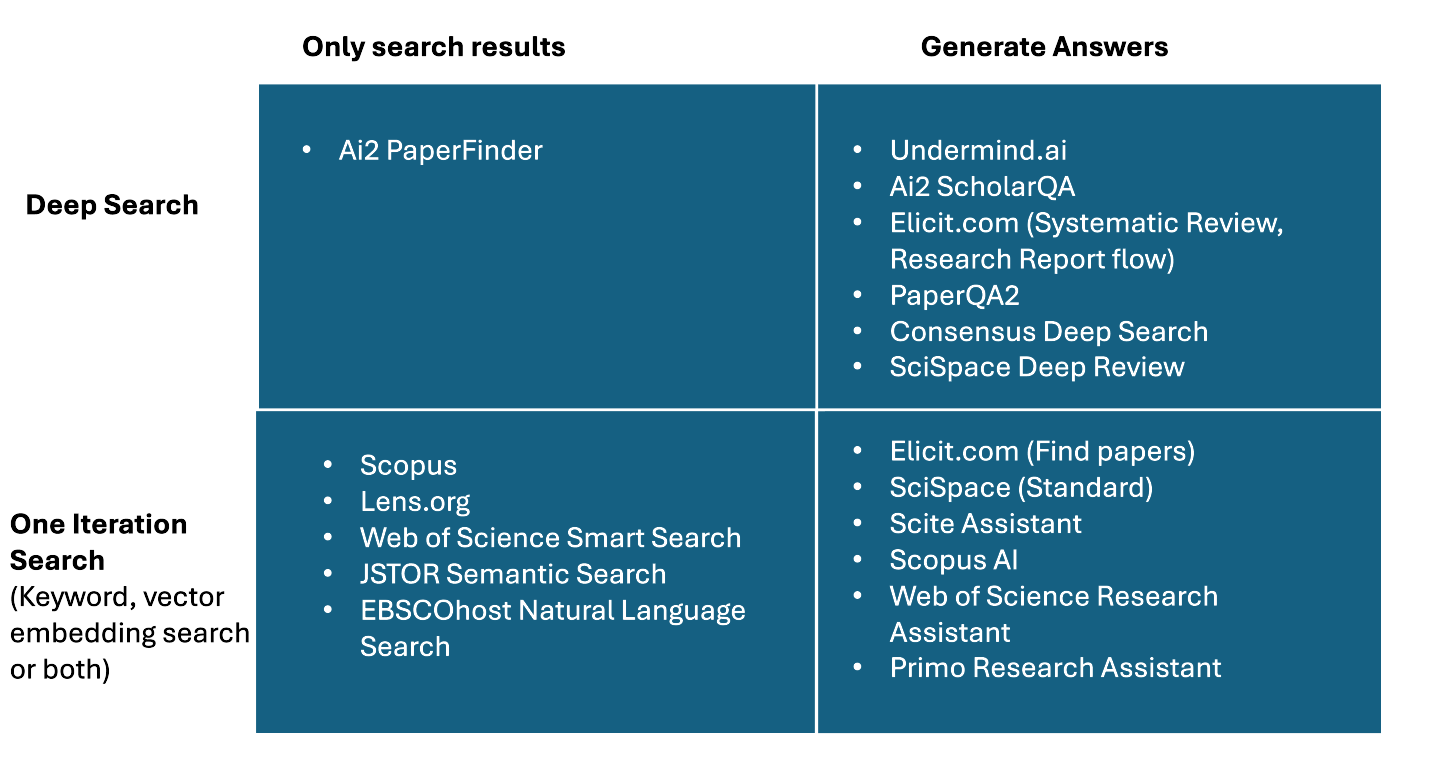
Note: Products might not follow the same terminology. For example, Consensus Deep Search is actually a type of Deep Research product using my terminology.
Bottom-left quadrant (Quick Search)
Traditional Boolean/BM25 searches (e.g., Scopus or Lens.org. ) or quick semantic searches like JSTOR Semantic Search. Also popular are AI-powered search engines that use LLMs to convert inputs into Boolean search strategies, like Web of Science Research Assistant, or even hybrid AI search engines like Scopus AI that blend both these methods.
Regardless of the search technology used, they retrieve and rank results only — there is no extraction of retrieved documents to summarize and answer the query.
Bottom-right: Quick RAG

Typical Academic RAG Search
More recently, since 2022, we have started to see search engines start to generate direct answers with citations based on the top retrieved results using retrieval-augmented generation.
Besides general web search examples like Perplexity, You.com, and Bing Chat, academic examples include Elicit’s original “Find Paper” mode, Scite Assistant, Web of Science Research Assistant, and more, which reside in the bottom-right quadrant.
As novel as traditional retrieval-augmented generation was, tools like Scite Assistant and Scopus AI tended to be limited to generating answers that were at most a few paragraphs long.
Top-right (Deep Research) & Top-left quadrant (Deep Search)
But what if you wanted to generate a long report or literature review that was, say, 10 pages long rather than a few paragraphs long? Before you can do “Deep Research”, you need a “Deep Search” to accurately and reliably find enough raw content to be used for generation of your report.
Until then, most searches, even academic RAG searches (bottom-right quadrant), were “shallow” searches; they typically ran the search for one iteration and just returned what was retrieved and ranked.
What counts as one iteration or generation of the search before it counts as Deep Search? There is no hard and fast rule, but typically, if the results take more than 10–30 seconds, it is likely a Deep (Re)Search of some kind.
A Deep Search could and would run for much longer. Some, like Undermind, would iterate and adapt the searches it did (both keyword and semantic) and also do citation searching when necessary. Deep Search, of course, took far longer than a typical search and could return results in as fast as 8 minutes to an hour.
Searching longer and covering more ground is great. But that would be pointless if it couldn’t evaluate relevancy well.
Another aspect of Deep Search is that because it was under no pressure to return results in seconds, it could use more powerful techniques for (re)ranking. Besides using cross-encoders, a very popular method is to simply feed the document title/abstract and query to a large language model (LLM) like GPT-4 and prompt it to let it decide (either a score or a classification into highly relevant, partly relevant, or not relevant).
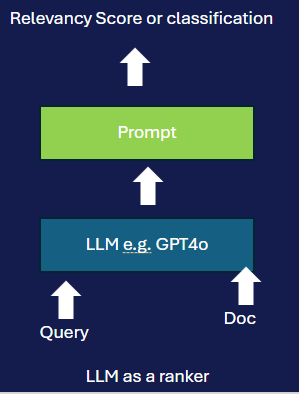
Using LLMs for relevance ranking is a fast-moving research area. Approaches include pointwise (scoring each document individually), pairwise (comparing two documents), and listwise (ranking a group at once), with listwise methods often reducing compute and latency.
Why Deep Search Is the Real Breakthrough
Better retrieval quality benefits everyone — even if you never read the generated report. It’s also objectively much measurable with recall, precision, and rank-aware metrics like NDCG.
Using LLMs this way is a very powerful relevancy judgment technique, and evidence from a number of different research strands make me moderately confident that modern LLMs’ judgment is now quite highly correlated with human judgement. These include:
The literature around the use of LLMs for title-abstract screening (scoping study shows use of LLM as screeners are mostly promising, latest study with GPT4.1 claims “superhuman performance”)
TREC 2024 results when using LLMs to provide quality judgments versus human experts
In evidence synthesis, early hopes that pure embedding search relevancy ranking alone could replace systematic review workflows were misplaced. At best, it could play a role as a supplementary search method. Real-world systematic reviews involve hours of search design, piloting, and painstaking screening — something a one-shot search can’t match. Deep Search tools like Undermind (which incidently isn’t designed for Systematic Review) and Elicit.com’s Systematic Review workflow come closer with a workflow similar to real systematic reviews.
On the academic side of search, one deep search tool exists in the top-left quadrant: AI2 PaperFinder. Like most deep research tools, it does “deep search,” but unlike deep research tools, it only ranks the results and does not try to generate an answer from the top results.
While you might be rightfully suspicious of hallucinations in long reports generated by Deep Research tools, I can’t see why anyone would be against Deep Search functionality if it results in higher retrieval quality.
I can think of maybe two things to watch out for when using Deep Search.
Firstly, there might be some unknown bias as compared to using traditional keyword search. This is particularly true when we are shifting from keyword search to both vector embedding search AND also using LLMs directly to steer the search and do evaluation. See discussion here, Then again all search tools such as Google Scholar have biases….
Secondly, for those concerned about the environment, deep search could, in theory, save energy overall by conducting searches more efficiently than humans.
Components of a Deep Research System
Finally, we come to the top-right quadrant that combines Deep Search and Retrieval-Augmented Generation to produce long reports or reviews, which is what OpenAI DeepResearch popularized.
By now, there are enough examples of Deep Research tools (both open source and proprietary) for "Deep Research Agents: A Systematic Examination and Roadmap" to be written.

The paper’s “structural overview” would not be surprising to you if you have tried a Deep Research tool.
There is typically a stage where you would be asked to clarify your intent, which is what you see in OpenAI’s Deep Research and its counterpart, Undermind.ai. A slight variant is Gemini’s Deep Research, which generates a research plan that you can disagree with.
The academic version of this is Elicit’s Systematic Review flow, where you can override the inclusion criteria generated by the system, the screening decisions, and even the extracted fields in the table for data analysis. Of course, it is not unheard of for this clarification step to be skipped as well in some Deep Research systems.
We will discuss the different retrieval methods in part 2, but suffice it to say, current Deep Research tools do not just generate text. Most have “tool use” capabilities to do coding and execute results in a code sandbox to generate visualizations and create tables. Rarer currently is for the tool to have multimedia generation capability (though many are starting to have image recognition capability e.g. useful for tables and figures)
Below, for example, Perplexity Labs uses its coding sandbox to generate a plot that is used in the final report.
AI code executor in Perplexity labs
Similarly, Deep Research tools such as Undermind and Consensus Deep Search have built in visualizations for various sections of the report. Same holds for the academic Deep Research tool - Undermind which has a special “Timeline” visualization.
Undermind.ai’s Historical Timeline
Consensus Deep Search has a “Claims and Evidence Table” among other visualizations.

Consensus Deep Search - Claims and Evidence Table
Conclusion
So far it looks like I’m singing praises of Deep Search more than Deep Research, that’s intentional.
Part 2 covers Deep Research generation, what it’s really for (orientating yourself in the literature, not copy-paste prose), how to use it critically, emerging product trends (more transparency, specialized sections, semantic + citation blending, web AND academic retrieval, light agentic steps), and why academic deep research is a very different beast from the general “deep research” tools you’ve tried.
Copyedited with help of Gemini 2.5 pro and GPT5
Aaron, thank you and am looking forward to learn from your part 2 article.
Great article. Thanks Aaron. It’ll be interesting to see if the launch of GPT-5 turbocharges these tools