
Hot take: Stop calling poor search rankings necessary friction for learning
Boundary learning, adjacent literature, and why intentional design beats accidental noise.


This post is part of a “hot takes” series in which I make sharper claims than I usually do. I do not intend to offend, and I am not trying to tar every librarian with the same brush — the patterns I describe and perceive may be a function of my own local context. In my last hot takes post, I argued that quality AI search that gives better rankings might not be fit for purpose for a librarian teaching undergraduate information literacy because “friction is pedagogically useful and one could even argue better search results removes friction!”. Here I examine this argument more carefully.

Months ago I read a review of an AI search tool that spent most of its length complaining about how poorly the tool ranked results, then made a striking turn at the end: poor relevancy ranking was supposedly a virtue, because learning needs friction.

My first reaction was that this confused good friction (the cognitive effort required to master a topic’s boundaries) with bad friction (the time wasted fighting unintutive operators, lexical noise and uninformative junk)1. But that is too easy a dismissal. Versions of the argument keep resurfacing, and underneath the crude version is a harder question that does not collapse so quickly.
Before diving in, some quick framing notes.
First, I am talking about ordinary narrative reviews and information-literacy contexts; systematic reviews have different requirements and are set aside here.
Second, if you think no AI search system currently gives materially better results than a traditional BM25 discovery layer, bracket that for now. Assume a genuinely better-ranking system and ask what follows.
Lastly, I am holding the interface constant. Much of the current anxiety about AI search is really anxiety about RAG-style answer engines and/or deep research tools: systems where the user types a question, gets back a synthesised response, and may never seriously engage with the underlying documents.
Ethan Mollick has recently documented real instances of this kind of cognitive surrender. That is a legitimate concern that deserves discussion, but in this essay I focus just on better retrieval and ranking. If better ranking alone is supposed to damage learning, we should be able to say exactly how.
The weak arguments

Before getting to the harder question, three things need to be cleared away.
The first is a reflex that often appears when new tools arrive - making it easier to do things that once was hard and required expertise. Many experts, may be tempted by the idea that struggle is inherently virtuous, and that making something easier is a bad idea. Perhaps some experts might even have an unconscious vested interest in defending their hard-won expertise, grasping at the friction argument as a justification2.
The second is a concern often raised alongside the friction argument: that LLM- and embedding-based systems encode biases that could be amplified at scale if every novice uses the same AI-ranked tool to map a field. This is real, but it is a different question. Leaving aside that there are a huge variety of AI search engines using very different techniques, traditional lexical systems are not neutral either, and people worried about the dominance of Google Scholar amplifying bias. The homogenisation worry is better understood as an argument for epistemic diversity, interface pluralism, and transparency about retrieval choices, rather than for inferior ranking3.
The third is the crude claim that poor ranking is itself mostly or even always educationally valuable. It is not, and one test disposes of it. If poor ranking were valuable as such, we ought in principle to be willing to worsen it deliberately: degrade the scoring function, shuffle the top results, inject noise. At the extreme, results should be totally random! Nobody wants that.
But no reasonable person believes that? What about a much weaker claim, such that you believe the friction from poor relevancy ranking is “sometimes valuable”? This is what the rest of the post takes up. My belief is, the educational value of poor relevancy, if any, does not lie in worse ranking itself. Rather, it is an effect that weak ranking sometimes produces by accident4.
The question worth asking

What survives, once those are set aside, is a harder question. Suppose we had a search system that ranked documents perfectly by topical relevance, by every standard IR measure: precision, recall, nDCG. Would it also be the best system for someone learning a topic5? If no, then in what way, and why?
I have always thought the answer was clearly yes, but the more I thought about it, the more I felt this question is a interesting one; the rest of this post is an attempt to answer it. I have discussed this with librarians who hold the view that a very good, or even perfect, retrieval and ranking system would be pedagogically detrimental, and this is my best attempt to steelman their argument.
The short version: great topical ranking and pedagogical value can and sometimes do diverge in particular ways, but the reasons matter. They do not automatically justify poor ranking or vindicate the friction case in a straightforward way. Instead, they argue for designing systems and pedagogy around the things straight-forward good ranking alone cannot deliver6.
The different types of irrelevance
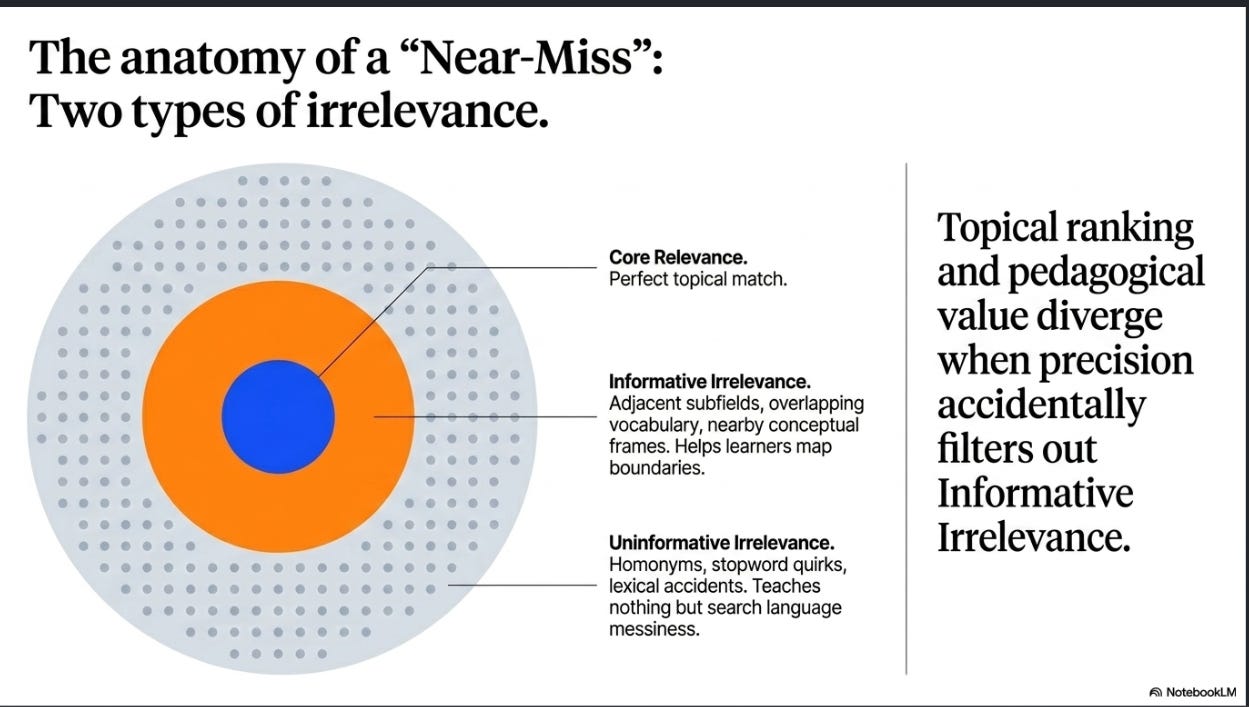
Let me suggest that not all irrelevant results are equal.
Some irrelevance in a result list is informative. An “irrelevant” result that appears because it belongs to an adjacent subfield, uses overlapping vocabulary, or reflects a nearby conceptual frame may genuinely help a learner understand where a topic begins and ends.
Other irrelevance is uninformative. A hit that appears because of a homonym, a stopword quirk, or a lexical accident teaches the novice nothing about the structure of the field. It teaches, at most, that search language can be messy7.
Poor ranking does not discriminate between these. It produces a messy mixture of both, especially for novices, who are least equipped to tell the difference. So the answer to the harder question takes a particular shape: when topical ranking and pedagogical value come apart, it is because better ranking can remove informative irrelevance along with the uninformative kind. If that is right, the response is not worse ranking. It is intentional design.
Two careful versions of the objection are worth examining through this lens.
Version one: seeing search terms in context

The first argument is that students benefit from seeing the terms from their assignment prompt used in actual scholarly contexts, and from gradually learning the vocabulary of a field through retrieval itself.
That is plausible, and it is also not undermined by better ranking. If anything, accurate ranking increases the chance that students encounter their search terms in genuinely relevant documents rather than tangential ones. The vocabulary they see on a precise hit is more likely to belong to the field than the vocabulary they would have encountered on a near-miss caused by a lexical accident.
This version survives only if novices learn vocabulary better from a noisier signal than a cleaner one. Pedagogically, I don’t see why this is the case.
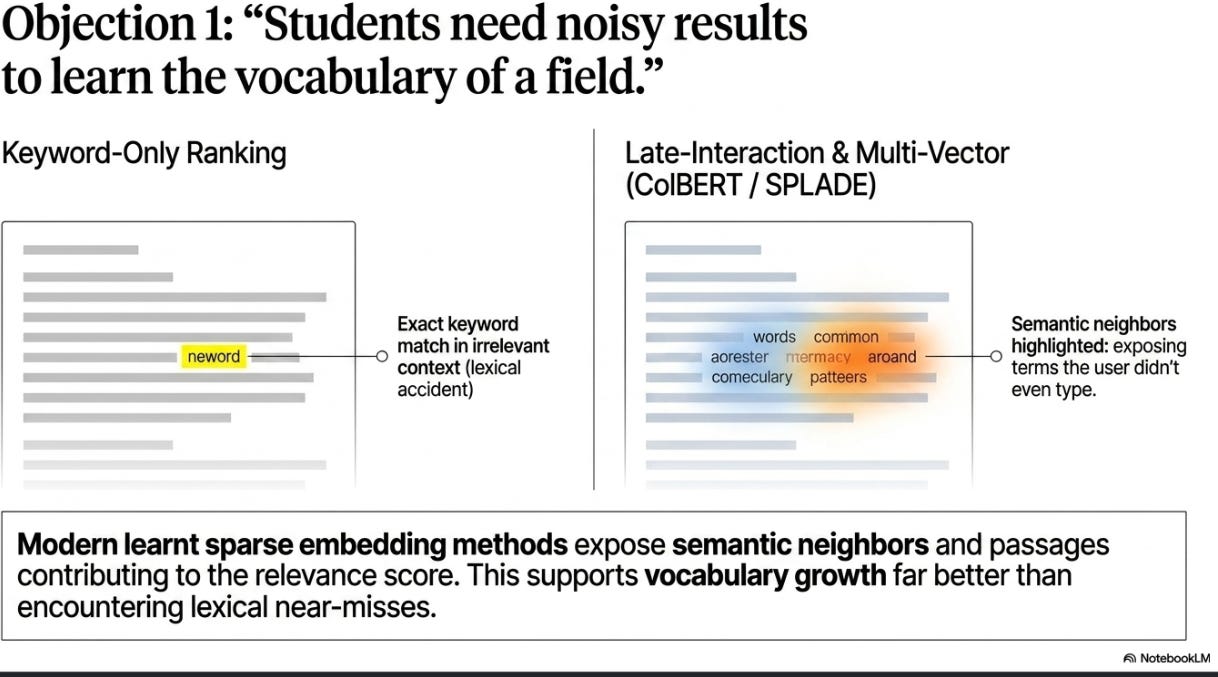
You might object: if modern search engines use semantic matching with dense embeddings, how would they perform and show the keyword-style matching in results page seen with conventional keyword engines (e.g. Google Scholar)?
Interestingly, some newer retrieval models can do something akin to, if not better than, old-style keyword highlighting. Late-interaction and multi-vector systems such as ColBERT, or learnt sparse embedding methods like SPLADE, can expose which terms or passages contributed most to the relevance score, including semantic neighbours in addition to exact lexical matches. In principle, that could support vocabulary growth better than traditional keyword-only ranking, because it can surface terminology matches the student would not have thought to search for.
Below shows how a ColBERT type search system, highlights terms (both based on exact lexical matches and semantical matches) in the document that contributes the most to the relevancy score.

Version two: boundary learning for novices
The stronger version is about something more specific than vocabulary or effort. It is about the novice’s need to learn a topic’s boundaries through exposure to meaningful near-misses and adjacent literatures.
A novice on a new topic cannot simply search broader, because they do not yet know what broader would mean. They do not know which adjacent areas matter, which terms are near-synonyms, which distinctions are important. For that learner, boundary formation has to happen partly through retrieval itself. Some of what matters may be found not in the core results but in the edge cases.
This is a fair point, and it is where the informative/uninformative distinction earns its keep.

If the case for “useful friction” rests on accidental exposure to meaningful adjacency, then the relevant question is whether poor ranking is a good mechanism for producing it. It is not. Poor ranking by definition generates adjacency mixed indiscriminately with junk. There is no reason to prefer accidental adjacency mixed with lexical noise over a system that retrieves the core accurately and exposes adjacent material deliberately.
A retrieval system that can reliably retrieve works that are not just in your topic but adjacent topics opens a wealth of possibilities to help the user learn!
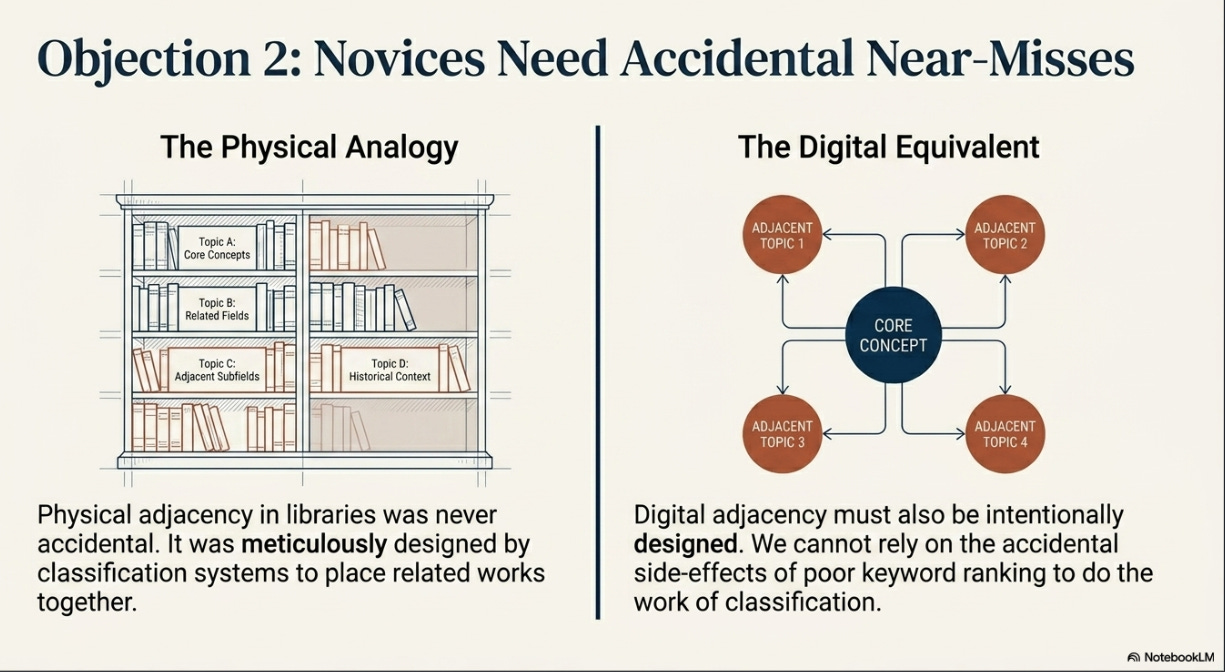
An example of what can be done is Undermind’s adjacent papers feature: a dedicated function that displays papers citing the seminal works of the topic you are researching, despite being judged as falling outside the core topic itself8.
Consider the idea of serendipity. When libraries moved physical stacks to remote storage, users complained about losing serendipitous browsing, and they were right that something real was being lost. But the adjacency they valued was not accidental. It came from classification: LC and Dewey were designed to place related works near each other. The well-handled response was not to defend physical stacks at any cost but to build virtual shelf browsing, browse-by-call-number, and related-item interfaces that replicated the function digitally. The function was real and worth preserving; the mechanism changed. The same logic applies here. Adjacency exposure for boundary learning is real and worth preserving. The mechanism should be intentional design (adjacent papers, topic maps, related-citation views), not the accidental side-effects of worse ranking.
This kind of result helps a novice see the edges of a topic and how neighbouring literatures branch from a common core. Topic maps, related-citation views, contrastive recommendations, and “nearby but different” clusters can do similar work. Don’t look now, but all this needs better retrieval and ranking not worse!
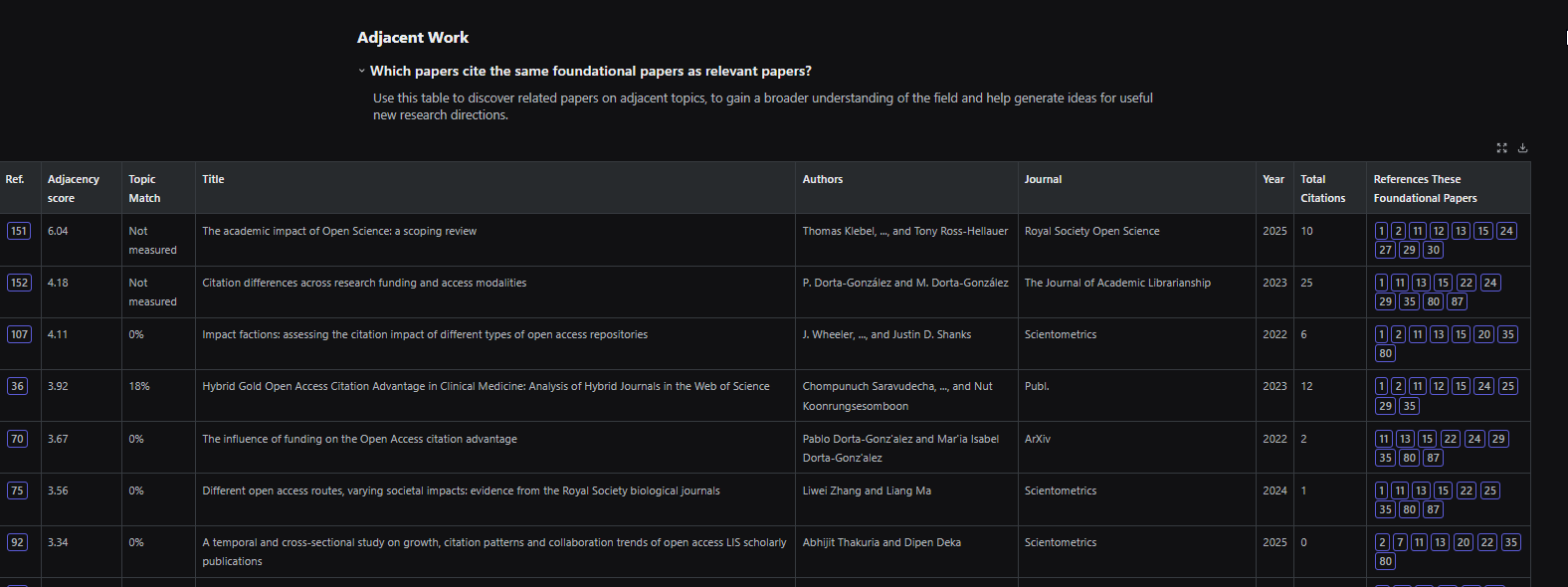
The table above shows “adjacent works” identified by Undermind that cite the foundational papers of your topic (In this case - does making papers open access lead to higher citations), but Undermind has judged to be not on your topic. You can see that while it isn’t perfect, it does show you “Adjacent” papers that focus on impact on Open Science, impact of open access on societal impact, influence of funding on open access citation advantage etc. In short, it does some of the “boundary work”.
While I know some users don’t understand why this feature exists in Undermind as a email alert because they are hyper-focused on their topic, I find many of the papers surfaced this way interesting.
As our retrieval and ranking systems get better at surfacing adjacency clusters, exploring and clustering boundaries, we should go beyond simple Chat-style replies with top-five-card summaries or even conventional list style rankings of results9. What we need are innovative, dedicated features that assist the searcher in learning about the field they are exploring.
Conclusion
The crude claim collapses on inspection. Poor relevancy ranking that is accidental is not a pedagogical good in itself.
Topical ranking and pedagogical value can perhaps come apart, particularly for novices who need exposure to topic boundaries, adjacent vocabularies, and the structure of a field. Retrieval is not just a delivery mechanism for known items. It can be part of how a learner forms the map.
But the conclusion that follows is not a defence of worse ranking. It is that we should stop treating poor ranking as a substitute for thoughtful design. If boundary learning matters, expose adjacent concepts deliberately. If vocabulary formation matters, make semantic neighbours visible. If we care about epistemic diversity, promote multiple tools and multiple ways of traversing a literature.
Poor ranking is a bad proxy for all of that. The honest response is to design for productive friction explicitly, not to hope mediocre retrieval generates it by accident or use pedagogy reasons as a poor excuse for poor relevancy!
Cognitive load theory
Looking back at how well or badly librarianship has reacted to new tools, I suspect experts worrying about the devaluation of their skills is sometimes part of the unspoken story. The other part of the story relates to a lack of appreciation of how newer tools can provide value without entirely replacing all the features of older tools. This will be covered in the third part of my hot-takes series on the history of Google Scholar.
In fact, given the explosion of modern search techniques since transformers were invented (compared to before the 2020s, when roughly the same search algorithms were used in academic search), we get extremely different retrieval and ranking results from “AI search”, even using the same index. For example, Elicit, Consensus, and Undermind yield very different results despite drawing from roughly the same sources. I will outline my findings from an upcoming presentation at FORCE2026 in a future post.
One could argue visible ranking failure can be pedagogically useful because it reveals the constructed nature of search results. In other words, bad ranking is not useful because it retrieves better learning material; it is useful because it exposes the machinery and teaches the user the concept of algorithmic awareness.
The “Search-as-Learning” literature clearly says no to this and argues that for learning, the target may not be maximum topical relevance, but optimised epistemic development: enough relevance to avoid junk, enough diversity to expose boundaries, enough friction to force reflection, and enough transparency to reveal mediation. Refer to this monograph for an introduction.
The strongest objection is not that poor ranking is good. It is that relevance ranking and learning are not the same objective. Search-as-learning research suggests that students learn through reformulation, comparison, metacognitive monitoring, and source integration, not simply through exposure to the most topically relevant documents. So the real risk is not that better ranking removes junk; it is that an overly smooth ranking experience may reduce opportunities for reflection, query experimentation, and awareness of algorithmic mediation. The answer is still not worse ranking, but neither is it ranking alone. It is ranking plus scaffolding, contestability, diversity, and explicit prompts to compare how the system has framed the topic.
To be fair, whether a irrelevant result is informative or not is highly contextual and not easy to determine sometimes. Similarly, serendipity in information seeking is partly emergent from the searcher’s context, preparedness, and interpretation, not simply as a system property.
Note that Undermind's framing — "cites the seminal works but judged off-topic" — is doing real work. The user can see why something is adjacent, not just that it is. A black-box adjacency feature would face the same trust problem as poor ranking, only worse, because users would not even see the messy mix. Legibility of the criterion is part of what makes intentional adjacency defensible.
It is no surprise, I don’t agree with Emily M. Bender style beliefs that LLMs are “stochastic parrots” and hence can never be useful for anything much including search but 2020’s Situating Search is clearly correct that there are many information seeking needs and we need diversity in search tools beyond just conversational interfaces or even ranking lists.
What about the history of the Boolean search ? All those years of that method and now poof it’s more natural language. I supposed I’m curious who on the tool side is getting search right? The 20 years of Boolean and the tools we have had …did they kill serendipity? I do miss that way of finding information. Are any tools out there figuring this out yet?